Command Palette
Search for a command to run...
マスク深度モデリングによる空間認識
マスク深度モデリングによる空間認識
概要
空間的な視覚認識は、自動運転やロボット操作といった現実世界における応用において基本的な要件であり、3次元環境との相互作用を実現する必要性に支えられている。RGB-Dカメラを用いてピクセル単位でメトリックな深度情報を取得することは、最も実現可能性の高い手法であるが、ハードウェアの制約や厳しい撮影条件、特に鏡面反射やテクスチャの欠如する表面が存在する場合に大きな課題に直面する。本研究では、深度センサーからの誤差が、本質的に潜在する幾何学的曖昧性を反映する「マスクされた信号」として捉え直すことができるという洞察に基づき、視覚的文脈を活用して深度マップを精密化する「マスク深度モデリング」を導入し、スケーラブルな学習を可能にする自動データ整備パイプラインを組み込んだ深度補完モデル「LingBot-Depth」を提案する。実験の結果、本モデルはトップクラスのRGB-Dカメラと比較して、深度精度およびピクセルカバレッジの両面で優れた性能を示した。また、さまざまな下流タスクにおける実験結果から、LingBot-DepthはRGBと深度のモダリティ間で整合性のある潜在表現を提供することが示された。本研究では、コード、チェックポイント、および300万組のRGB-深度データ(うち200万組が実データ、100万組がシミュレーションデータ)を、空間認識分野の研究コミュニティに公開する。
One-sentence Summary
Robbyant researchers propose LingBot-Depth, a Vision Transformer model using Masked Depth Modeling to treat sensor failures as natural masks, enabling robust RGB-D depth completion via joint RGB-depth context; it outperforms top RGB-D cameras and enhances robotic grasping and 3D tracking with 3M curated training pairs.
Key Contributions
- LingBot-Depth introduces Masked Depth Modeling (MDM), treating sensor failures in RGB-D cameras as natural masks to guide depth reconstruction, leveraging RGB context to infer missing depth values caused by geometric and appearance ambiguities like specular surfaces.
- The model is trained on a curated dataset of 3M RGB-depth pairs (2M real, 1M synthetic) and achieves state-of-the-art depth precision and pixel coverage, outperforming commercial RGB-D sensors while enabling unified monocular depth estimation and depth completion via adaptive masking in a Transformer architecture.
- Evaluated on downstream tasks, LingBot-Depth improves 3D tracking by replacing VGGT in SpatialTrackerV2 and enables robust dexterous grasping of challenging objects like transparent or reflective items, demonstrating zero-shot generalization to video and practical robotic deployment without CAD models.
Introduction
The authors leverage the inherent failures of RGB-D sensors—such as missing depth values due to specular surfaces or textureless regions—not as noise to discard, but as natural masks that encode geometric ambiguity. Prior depth completion methods often rely on random masking or lack scalable, real-world training data, limiting their ability to generalize under real imaging conditions. Their main contribution is Masked Depth Modeling (MDM), a self-supervised framework that trains a Vision Transformer to reconstruct missing depth by fusing full RGB context with sparse valid depth tokens, using a curated dataset of 3M RGB-depth pairs from both synthetic and real-world sources. The resulting LingBot-Depth model improves depth precision and coverage beyond commercial sensors and enables robust downstream applications like 3D tracking and dexterous robotic grasping without requiring CAD models or perfect simulation.
Dataset

-
The authors use a custom-curated RGB-D dataset combining synthetic and real-world data to train a masked depth model, addressing the scarcity of naturally incomplete depth maps in existing datasets.
-
Synthetic data (LingBot-Depth-S) is generated using Blender to simulate real-world active depth cameras: 10M samples from 442 indoor scenes, each with RGB, perfect depth, stereo pairs with speckle patterns, ground-truth disparity, and sensor depth computed via SGM. Camera parameters (baseline 0.05–0.2m, focal length 16–28mm) are randomized for diversity. Sensor depth is upsampled to 960×1280 from 720×960.
-
Real-world data (LingBot-Depth-R) comes from a scalable capture system with multiple commercial RGB-D cameras mounted on custom 3D-printed fixtures. A portable PC manages streams via manufacturer SDKs. 2M captures span diverse indoor scenes (residential, commercial, public, specialized), with pseudo depth computed from stereo IR pairs using left-right consistency checks.
-
The authors supplement their 3.2M self-curated data with 7 open-source RGB-D datasets (totaling 10M training samples). For synthetic open-source data (no missing depth), they apply random patch-based masking (60–90% mask ratio). For real-world open-source data (mostly complete depth), they use random masking as well.
-
During training, all depth maps — whether synthetic, real, or from open-source — are corrupted with Gaussian noise and masked. The original depth maps serve as reconstruction targets, with valid-pixel masks excluding missing measurements. The final training mix includes 3.2M self-curated + 6.8M open-source samples, ensuring broad scene and depth variation.
Method
The authors leverage a masked depth modeling framework built upon a Vision Transformer (ViT) encoder-decoder architecture, designed specifically for depth map prediction from RGB-D inputs. The overall framework operates by jointly processing RGB and depth modalities through a series of structured modules that enable effective cross-modal learning. Refer to the framework diagram 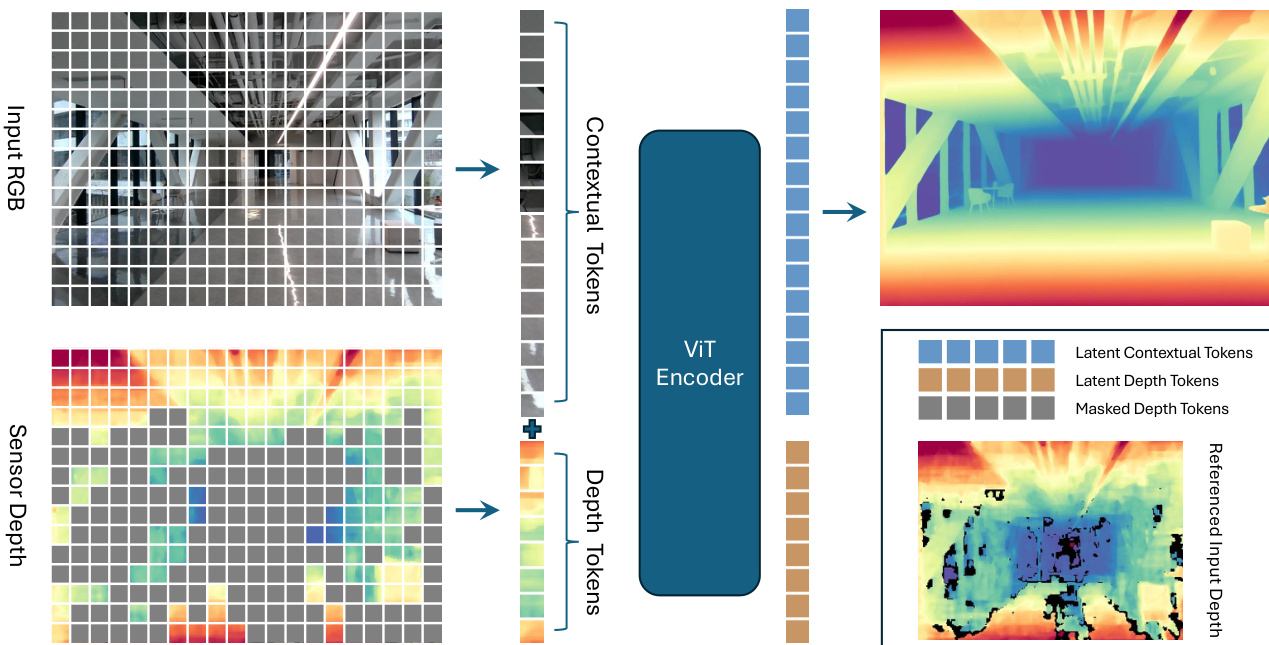 to understand the high-level flow.
to understand the high-level flow.
The process begins with separate patch embedding layers for the RGB and depth inputs. Each modality is independently projected into a sequence of patch tokens, with the RGB image processed as a 3-channel input and the depth map as a single-channel input. These embeddings are spatially aligned on a 2D grid, ensuring that each token corresponds to the same spatial location across both modalities. The patch size is set to 14, consistent with DINOv2, resulting in N=HW/142 tokens per modality, where H and W are the spatial dimensions of the input. The i-th RGB token is denoted as ci∈Rn and the i-th depth token as di∈Rn, where n is the embedding dimension.
To encode positional information, two types of embeddings are introduced: a shared learnable 2D spatial positional embedding that captures the location of each token within the image plane, and a modality-specific embedding that distinguishes RGB tokens from depth tokens at the same spatial position. The modality embedding is set to 1 for RGB tokens and 2 for depth tokens. The final positional encoding for each token is the sum of its spatial and modality embeddings, which are added to the respective token before being fed into the attention blocks.
The model employs a masking strategy grounded in the natural occurrence of missing depth measurements in RGB-D data. Depth patches with entirely missing values are always masked, while patches with mixed valid and invalid values are masked with a higher probability (e.g., 0.75). If the total number of masked tokens does not meet the target ratio, additional fully valid depth tokens are randomly sampled to complete the masking set. This strategy ensures that informative depth tokens remain unmasked, enabling meaningful interaction with contextual RGB tokens. The overall masking ratio for depth maps ranges from 60% to 90%.
After masking, the unmasked depth tokens are concatenated with all RGB tokens to form the input for the ViT-Large encoder. A [cls] token is retained to capture global context across modalities. The encoder consists of 24 self-attention blocks, and only the output tokens from the final layer are retained for subsequent processing. Unlike conventional approaches that aggregate features from multiple intermediate layers, this design simplifies the architecture by focusing on the final encoder output.
For depth reconstruction, a ConvStack decoder is employed, adapted from MoGe. This decoder is better suited for dense geometric prediction compared to the shallow Transformer decoder used in vanilla MAE. After the encoder, latent depth tokens are discarded, while the latent contextual tokens are retained. The [cls] token is broadcast and element-wise added to each contextual token to inject global scene context. These enhanced tokens serve as input queries to a hierarchical convolutional decoder.
The decoder follows a pyramid structure with a shared convolutional neck and multiple task-specific heads. The neck progressively upsamples features through stacked residual blocks and transposed convolutions, doubling the spatial resolution at each stage until reaching (16h,16w). At each scale, UV positional encodings derived from a circular mapping of image coordinates are injected to preserve spatial layout and aspect ratio. The resulting multi-scale feature pyramid is shared across all task heads, enabling efficient feature reuse. The final depth prediction is bilinearly upsampled to match the original input resolution.
Training is conducted using a 24-layer ViT-Large encoder initialized with a DINOv2 pretrained checkpoint, while the decoder is randomly initialized. A differential learning rate strategy is employed, with the encoder backbone optimized at 1×10−5 and the decoder at 1×10−4. The optimizer is AdamW with momentum parameters β1=0.9, β2=0.999, and a weight decay of 0.05. A composite learning rate schedule includes a linear warm-up for the encoder over 2,000 iterations and step decay for both learning rates every 25,000 iterations. Training runs for 250,000 iterations with a global batch size of 1,024, using 128 GPUs and a per-GPU batch size of 8. Data augmentation includes random resized cropping, horizontal flipping, and synthetic degradations such as color jittering, JPEG compression, motion blur, and shot noise. Gradient clipping with a maximum norm of 1.0 and mixed-precision training using BF16 are applied. The predicted depth map is supervised using an L1 loss on valid ground-truth depth pixels.
Experiment
- Validated MDM pretraining via depth completion on iBims, NYUv2, and DIODE under block-wise masking: LingBot-Depth reduced RMSE by >40% vs. PromptDA in extreme settings, and by 47% (indoor) and 38% (outdoor) on ETH-SfM under sparse SfM inputs.
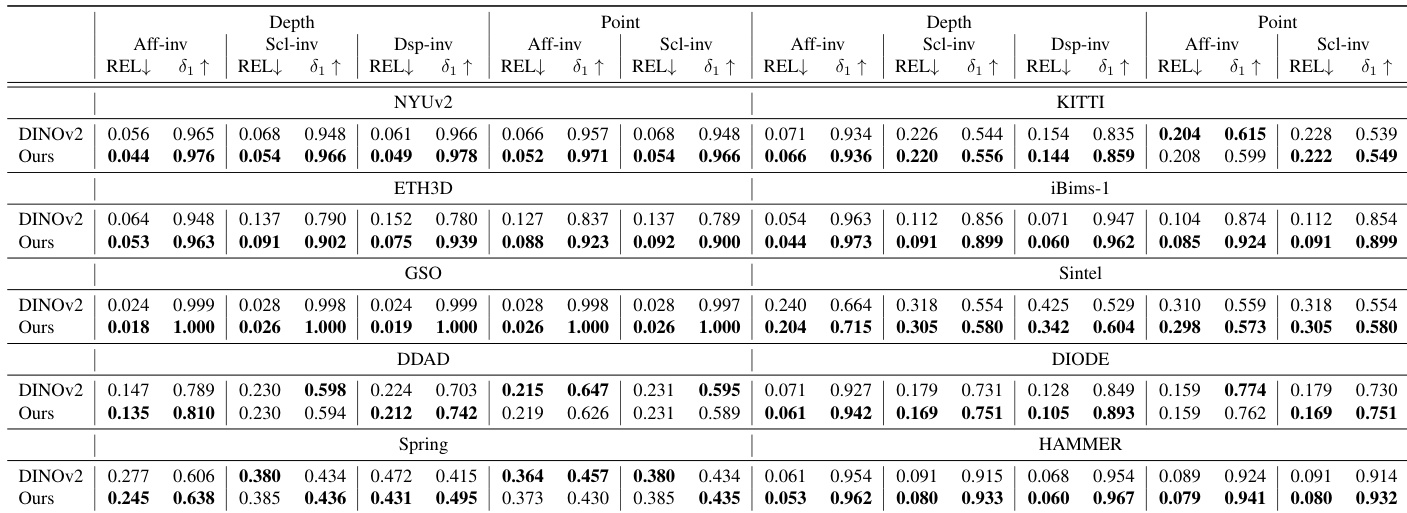
- For monocular depth estimation, MoGe initialized with LingBot-Depth outperformed DINOv2-based models across 10 benchmarks (NYUv2, KITTI, DIODE, etc.), demonstrating stronger spatial reasoning from RGB alone.
- In FoundationStereo, MDM pretraining accelerated convergence (e.g., HAMMER EPE 0.27 vs. 0.46 at epoch 5) and improved final performance (e.g., HAMMER EPE 0.17 at epoch 15), while outperforming DepthAnythingV2-based variants in stability and accuracy.
- Applied to video depth completion, LingBot-Depth filled large missing regions on transparent/reflective surfaces (glass, mirrors, aquariums) with temporal consistency, surpassing ZED stereo depth in challenging real-world sequences.
- Enabled robust online 3D point tracking via SpatialTrackerV2: refined depth reduced camera drift and enabled coherent motion tracking of dynamic objects in glass-rich environments.
- Boosted robotic dexterous grasping: on 4 challenging objects (including transparent storage box), LingBot-Depth enabled 50% success rate where raw depth failed entirely, proving critical for real-world manipulation.
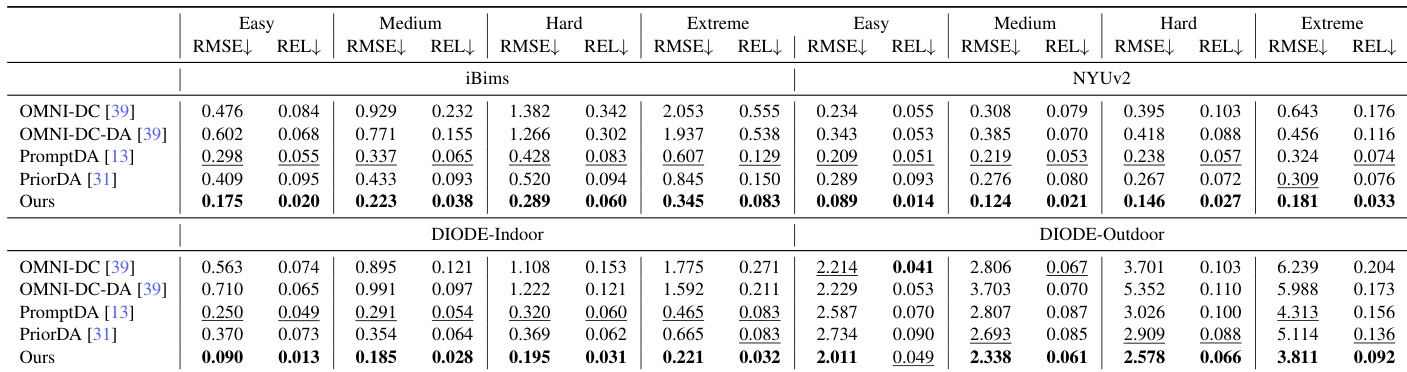
Results show that the proposed method consistently outperforms all baseline approaches across all difficulty levels on iBims, NYUv2, and DIODE under the block-wise depth masking protocol, achieving the lowest RMSE values in both indoor and outdoor settings. The model demonstrates strong robustness to structural incompleteness and measurement noise, with significant improvements over the best competitors, particularly in extreme conditions.
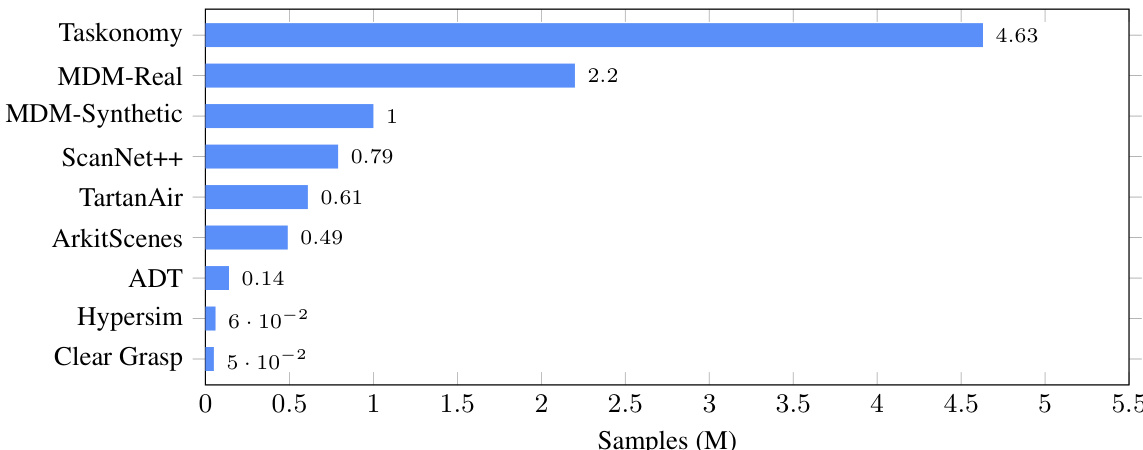
The authors use a bar chart to compare the number of samples (in millions) required by different methods for training, with Taskonomy requiring the most at 4.63 million and Clear Grasp requiring the least at 5 × 10⁻² million. The results show that MDM-Real requires 2.2 million samples, significantly fewer than Taskonomy but more than all other methods listed, indicating a trade-off between data efficiency and performance.
Results show that the proposed method outperforms all baseline approaches across all difficulty levels on indoor and outdoor datasets under the block-wise depth masking protocol. On indoor benchmarks, it reduces RMSE by over 40% compared to the best competitor in the extreme setting, and on outdoor datasets, it achieves the lowest errors across all levels, demonstrating strong robustness to both structural incompleteness and measurement noise.
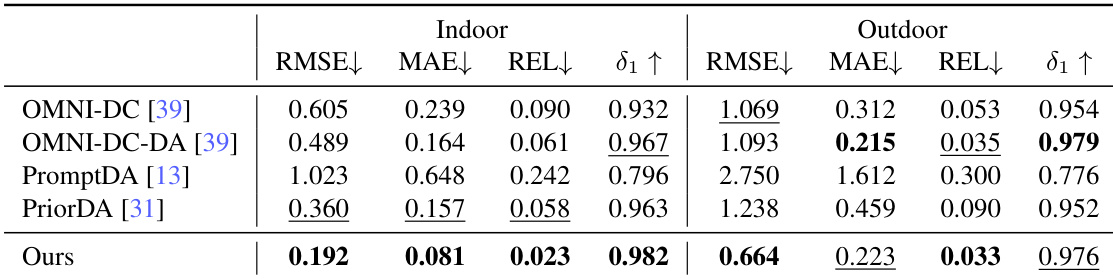
The authors use the LingBot-Depth model pretrained with MDM to evaluate monocular depth estimation on multiple benchmarks, comparing it against DINOv2 as a backbone. Results show that models initialized with LingBot-Depth achieve consistent and significant improvements across all datasets, demonstrating stronger generalization and enhanced spatial understanding.
The authors evaluate grasping success rates using LingBot-Depth and raw sensor depth on four challenging objects, including transparent and reflective items. Results show that LingBot-Depth consistently improves success rates, achieving a 50% success rate on the transparent storage box where raw depth fails entirely.
