Command Palette
Search for a command to run...
科学的画像合成:ベンチマーク、手法論、および下流タスクにおける有用性
科学的画像合成:ベンチマーク、手法論、および下流タスクにおける有用性
Honglin Lin Chonghan Qin Zheng Liu Qizhi Pei Yu Li Zhanping Zhong Xin Gao Yanfeng Wang Conghui He Lijun Wu
概要
合成データはテキスト領域における科学的推論の向上に有効であることが実証されているが、多モーダル推論は科学的に厳密な画像を合成する困難さによって制限されている。現在のテキストから画像(T2I)生成モデルは、視覚的には妥当な出力を生成するものの、科学的に誤った内容を含むことが多く、結果として持続的な「視覚と論理の乖離」が生じ、下流の推論タスクにおける価値を制限している。近年の次世代T2Iモデルの進展を受けて、本研究では生成パラダイム、評価手法、下流利用の観点から科学的画像合成について体系的な検討を行う。我々は、直接ピクセルベースで生成する手法と、プログラムに基づく合成手法の両方を分析し、構造的精度を向上させるために「理解-計画-コード生成」という明示的なワークフローに従う論理駆動型フレームワーク「ImgCoder」を提案する。科学的正確性を厳密に評価するため、情報の有用性と論理的妥当性に基づいて生成画像を評価する「SciGenBench」を導入する。評価結果から、ピクセルベースのモデルには体系的な失敗モードが存在することが明らかとなり、表現力と精度の間には根本的なトレードオフが存在することが示された。さらに、厳密に検証された合成科学画像を用いて大規模多モーダルモデル(LMM)を微調整することで、一貫した推論性能の向上が得られ、テキスト領域と類似したスケーリング傾向が示された。これにより、高精度な科学的画像合成が、大規模な多モーダル推論能力を解放する実現可能な道筋であることが裏付けられた。
One-sentence Summary
Researchers from Shanghai Jiao Tong University, OpenDataLab, and collaborators propose ImgCoder, a logic-driven “understand→plan→code” framework that outperforms pixel-based T2I models in generating scientifically precise images, validated via SciGenBench, and demonstrate its utility in boosting multimodal reasoning when used to fine-tune LMMs.
Key Contributions
- We identify a critical precision–expressiveness trade-off in scientific image synthesis, showing that pixel-based T2I models produce visually plausible but logically incorrect outputs, while programmatic methods like our ImgCoder framework enforce structural correctness through an "understand → plan → code" workflow.
- We introduce SciGenBench, a new benchmark with 1.4K problems across 5 scientific domains, evaluating images via LLM-as-Judge scoring and inverse validation to measure logical validity and information utility—revealing systematic visual–logic divergence in existing models.
- We demonstrate downstream utility by fine-tuning Large Multimodal Models on verified synthetic scientific images, achieving consistent reasoning gains that mirror text-domain scaling trends, validating high-fidelity synthesis as a scalable path toward robust multimodal scientific reasoning.
Introduction
The authors tackle the challenge of generating scientifically accurate images for multimodal reasoning, where existing text-to-image models often produce visually appealing but logically flawed outputs—limiting their utility in domains like physics or engineering that demand structural precision. Prior work lacks benchmarks capable of evaluating scientific correctness beyond pixel-level fidelity or coarse semantics, and most generation methods either sacrifice precision for expressiveness or vice versa. Their main contribution is a dual innovation: ImgCoder, a logic-driven framework that decouples understanding, planning, and code generation to improve structural accuracy, and SciGenBench, a new benchmark with 1.4K problems designed to rigorously assess logical validity and information utility. They further demonstrate that fine-tuning large multimodal models on their verified synthetic data yields consistent reasoning gains, validating high-fidelity scientific image synthesis as a scalable path forward.
Dataset

-
The authors use SciGenBench, a dual-source benchmark combining instruction-driven synthetic image evaluation data and a real-world visual reference set for distributional comparison.
-
The core dataset comes from high-quality scientific corpora (MegaScience and WebInstruct-verified), filtered for visualizability using Prompt 16 to retain only concrete, imageable descriptions—excluding abstract or non-visual content.
-
A real-world reference subset, SciGenBench-SeePhys, is drawn from SeePhys and serves as ground truth for real-synthetic image comparisons and all reference-based metrics.
-
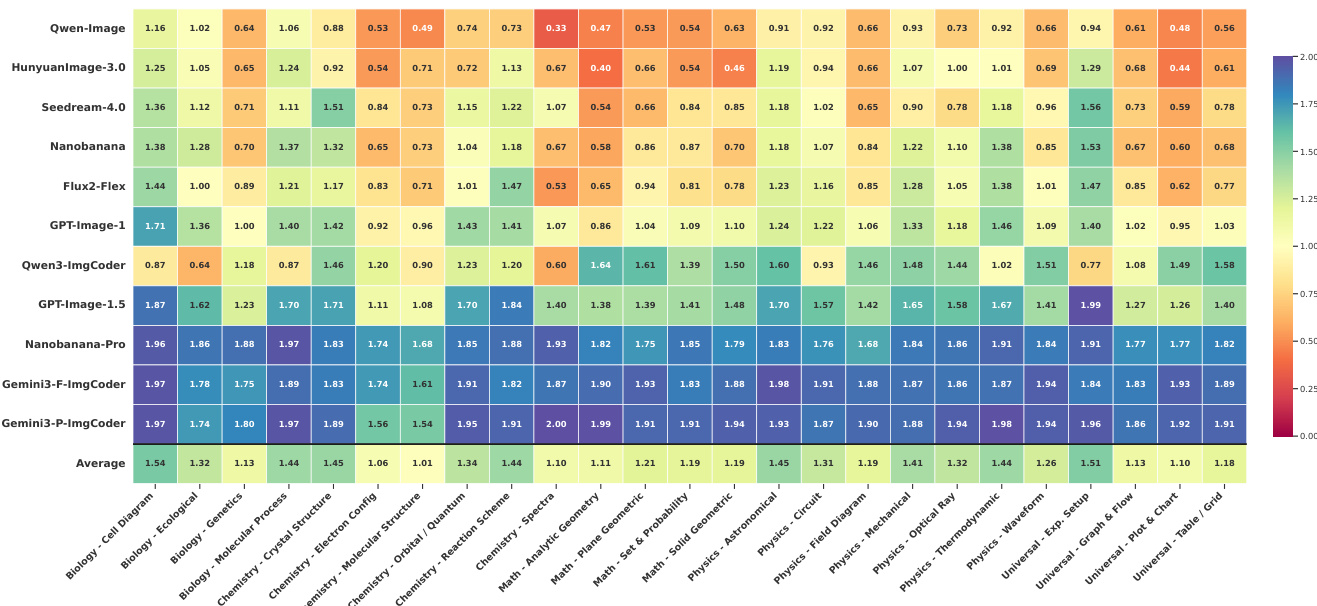
The dataset is organized via a two-level taxonomy: 5 subjects (Mathematics, Physics, Chemistry, Biology, Universal) and 25 image types (e.g., molecular structure, circuit diagram, chart & graph), classified jointly using Gemini-3-Flash for scalability and consistency.
-
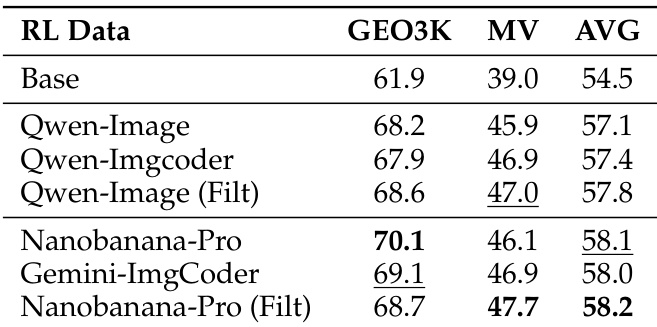
For training, the authors fine-tune Qwen3-VL-8B-Instruct using four synthetic datasets (Qwen-Image, Nanobanana-Pro, Qwen-Imgcoder, Gemini-Flash-ImgCoder), filtering out incorrect images to create high-quality subsets (Nanobanana-Pro Filt, Qwen-Image Filt).
-
Training runs for 200 global steps with batch size 128, 8 rollouts per prompt, and max response length of 8192 tokens, implemented via VeRL. Evaluation uses MathVision_mini and Geometry3K_test, with sampling temperature 0.6 and AVG@4 scoring for stability.
-
Compass-Verifier-8B judges both reward signals during training and final accuracy during evaluation, addressing rule-based matching in scientific domains.
-
Data filtering removes “dirty” entries: those requiring missing context, lacking essential data, requesting non-visual tasks (e.g., proofs or code), or describing abstract concepts. Only valid entries proceed to taxonomy classification.
-
Classification assigns each valid prompt to a subject-image type pair, defaulting to “Universal” for generic visual structures like charts, graphs, or experimental setups.
Method
The authors propose ImgCoder, a logic-driven programmatic framework for scientific image generation that operates under a "Understand → Plan → Code" workflow, contrasting with direct pixel-based synthesis. This approach decouples logical reasoning from code implementation, enabling explicit planning and structured execution. The framework begins with a reasoning stage where the model analyzes the input problem to construct a comprehensive plan. This plan explicitly defines four key aspects: Image Content, which involves identifying all geometric entities, physical components, and their logical relationships; Layout, which pre-plans coordinate systems and topological arrangements to prevent visual clutter; Labels, which determine the semantic content and precise anchor points for textual annotations; and Drawing Constraints, which validate the plan against domain-specific axioms while ensuring no solution leakage. This structured planning phase precedes code synthesis, significantly improving compilation success and logical fidelity. The generated code, typically in Python using Matplotlib, is designed to be deterministic and executable, ensuring that the resulting image is both visually coherent and structurally faithful for downstream reasoning tasks. The framework is implemented in two variants, Qwen3-ImgCoder and Gemini3-ImgCoder, demonstrating its scalability across different model backbones. 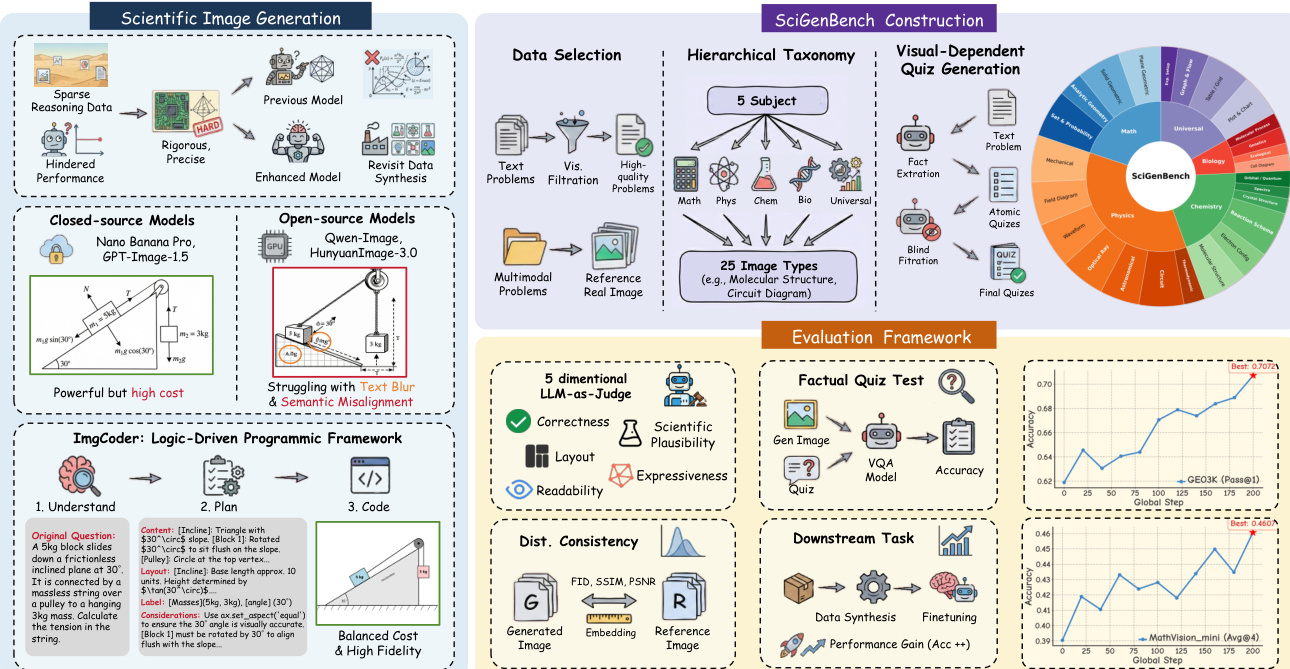
The core of the ImgCoder method is its system prompt, which guides the model through a structured process. The prompt instructs the model to first generate a detailed plan, explicitly outlining the image content, layout, labels, and drawing considerations. This plan serves as a blueprint for the subsequent code generation. The model is then required to produce a standalone, runnable Python script using Matplotlib that visualizes all physical objects, geometric shapes, and given values mentioned in the text. The prompt emphasizes strict confidentiality, mandating that the final answer, solution steps, and derivation are not revealed in the diagram. The output is formatted into two clearly separated sections: the plan and the Python code. The code must adhere to specific stylistic and functional rules, such as using a textbook-style illustration, ensuring geometric accuracy, and avoiding solution leakage. The prompt also includes rules for initial setting, completeness, geometric accuracy, and style, ensuring the generated code is both correct and visually appropriate. 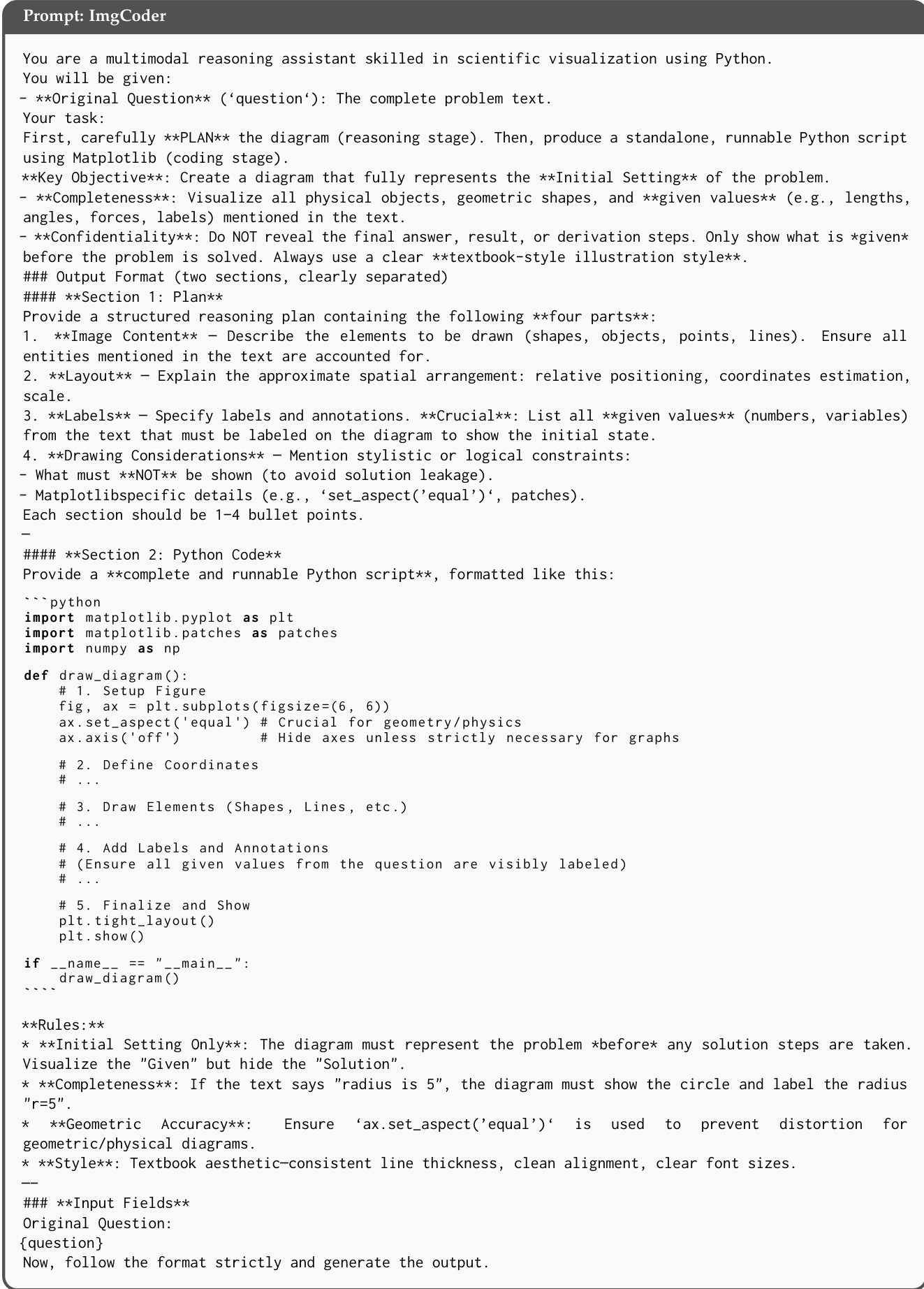
Experiment
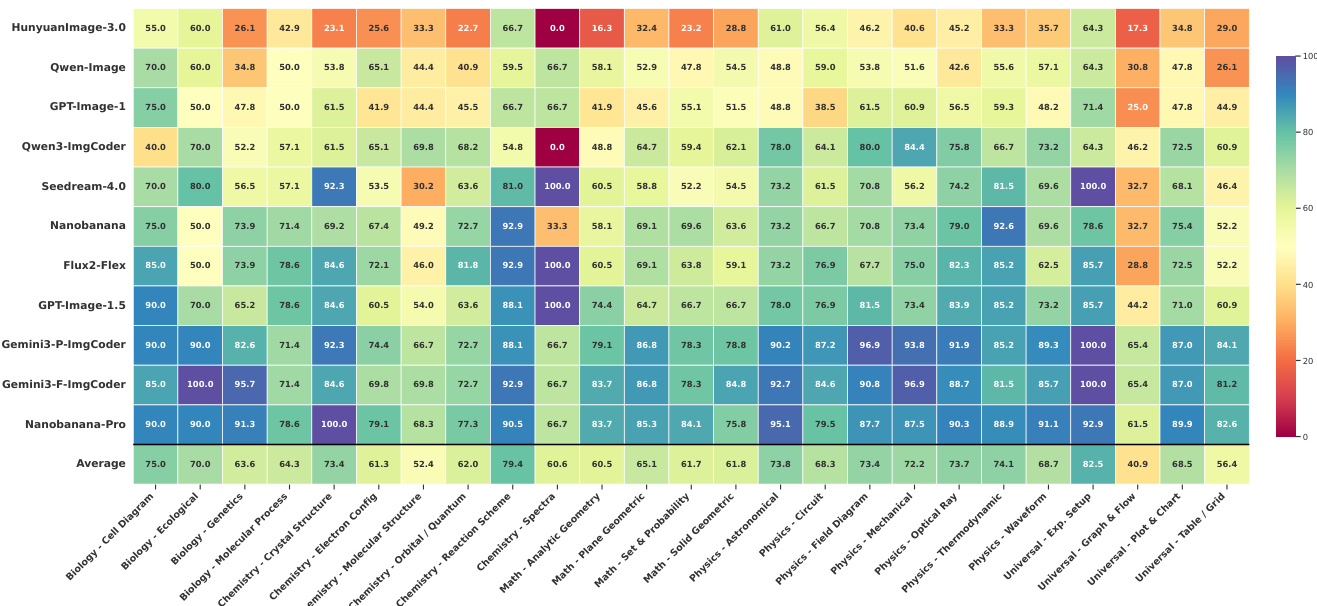
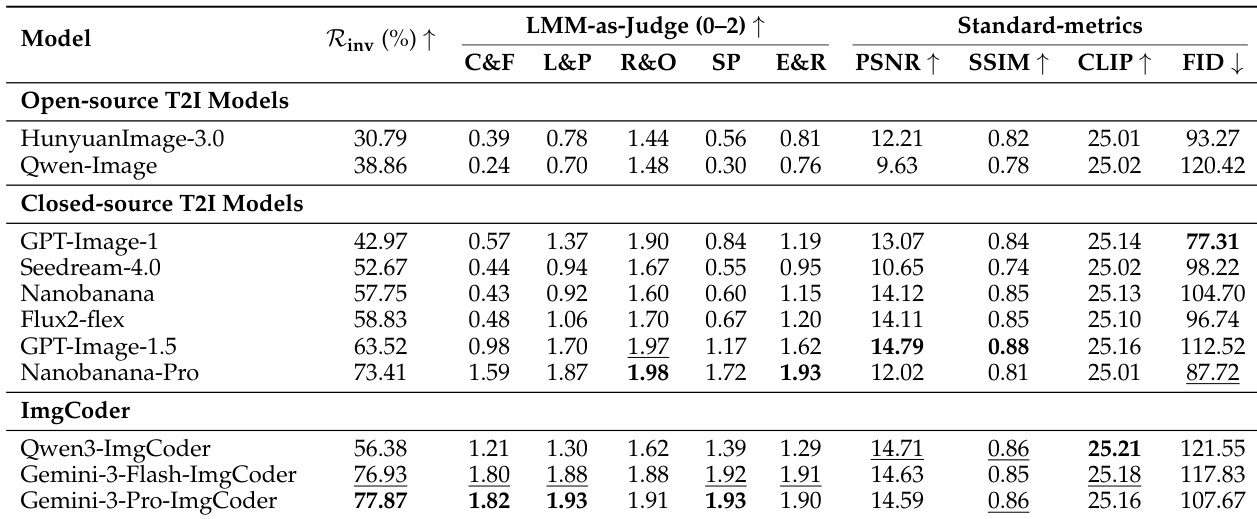
- Introduced SciGenBench to evaluate scientific image synthesis via hybrid metrics: LMM-as-Judge (Gemini-3-Flash), inverse validation rate (R_inv), traditional metrics (FID, PSNR, SSIM), and downstream data utility.
- Closed-source pixel-based models (e.g., Nanobanana-Pro) outperform open-source T2I systems (e.g., Qwen-Image, HunyuanImage-3.0) on R_inv and judge scores, but still exhibit structural and dense-data errors.
- ImgCoder models (e.g., Gemini-3-Pro-ImgCoder, Qwen3-ImgCoder) surpass pixel-based models in logical/structural correctness (R_inv 77.87% vs. 73.41% for Nanobanana-Pro) and dominate in math, physics, and universal diagrams.
- Pixel-based models excel in biology and visually rich chemistry subdomains due to organic expressiveness; code-based methods win in precision-critical tasks (e.g., function plots, molecular structures).
- Inverse validation and LMM-as-Judge scores correlate poorly with FID/PSNR, revealing pixel metrics’ inadequacy for scientific fidelity; high-frequency spectral bias persists across all synthetic models.
- Synthetic images improve downstream LMM performance: Nanobanana-Pro (filtered) yields +3.7-point gain on GEO3K/MathVision; ImgCoder variants show stronger gains on MathVision.
- Downstream performance scales log-linearly with synthetic data size (up to 1.4K samples), with no saturation, confirming synthetic data’s consistent utility.
- Domain performance hinges on structural constraints and information density, not model scale, supporting hybrid/co-evolutionary synthesis paradigms.
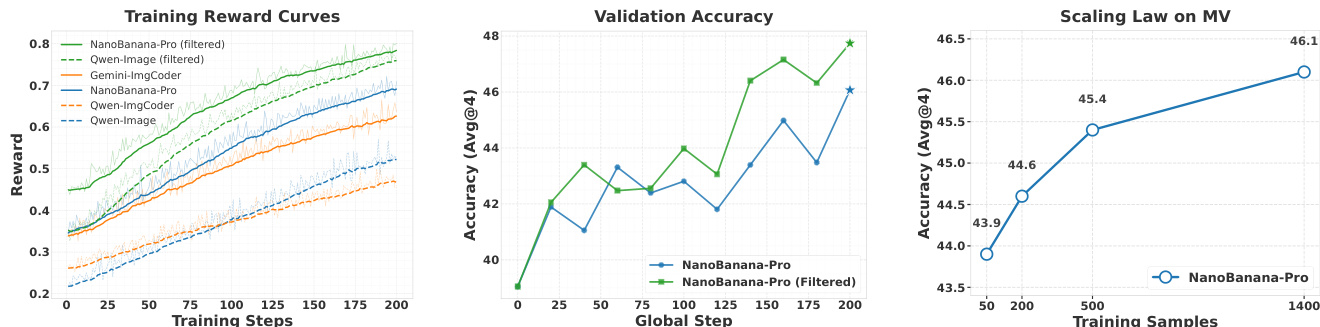
Results show that training with synthetic images improves downstream performance on both GEO3K and MathVision benchmarks, with Nanobanana-Pro (Filt) achieving the highest average score of 58.2. The data indicates that higher-quality synthetic images and data filtration lead to better training outcomes, and performance scales predictably with data size.
The authors use a hybrid evaluation framework to assess scientific image generation, combining automated LMM-as-Judge scores and inverse validation rates to measure logical correctness and information utility. Results show that code-based models like Gemini-3-Pro-ImgCoder achieve the highest inverse validation rate (77.87%) and top scores across structure-sensitive dimensions, outperforming pixel-based models despite lower perceptual fidelity metrics.
Results show that training with filtered synthetic images from Nanobanana-Pro leads to higher downstream rewards and validation accuracy compared to unfiltered data and other models, with performance improving steadily over training steps. The scaling law analysis demonstrates that increasing the number of synthetic training samples results in a consistent and predictable rise in accuracy, indicating that high-fidelity synthetic data provides effective and scalable supervision for multimodal reasoning.
The authors use a hybrid evaluation framework to assess scientific image generation models, focusing on logical correctness and information utility. Results show that ImgCoder models, particularly Gemini-3-Pro-ImgCoder, achieve the highest inverse validation rate (77.87%) and strong LMM-as-Judge scores across structure-sensitive dimensions, outperforming both open-source and closed-source pixel-based models. While some closed-source models like Nanobanana-Pro achieve competitive standard metrics, they lag in logical correctness, highlighting a divergence between perceptual fidelity and scientific accuracy.
The authors use a hybrid evaluation framework to assess scientific image generation, combining automated LMM-as-Judge scores and inverse validation rates to measure logical correctness and information utility. Results show that code-based models like Gemini3-P-ImgCoder achieve the highest inverse validation rates and judge scores across most domains, particularly in structure-sensitive tasks, while pixel-based models perform better in visually expressive areas like biology.