Command Palette
Search for a command to run...
OCRVerse:エンドツーエンド視覚言語モデルにおける包括的なOCRへの道標
OCRVerse:エンドツーエンド視覚言語モデルにおける包括的なOCRへの道標
Yufeng Zhong Lei Chen Xuanle Zhao Wenkang Han Liming Zheng Jing Huang Deyang Jiang Yilin Cao Lin Ma Zhixiong Zeng
概要
大規模な視覚言語モデルの開発に伴い、多様なマルチモーダルデータの管理および応用ニーズが高まっている。これにより、視覚的な画像から情報を抽出する光学式文字認識(OCR)技術の重要性が増しており、その利用が急速に広がっている。しかし、従来のOCR手法は主に画像やスキャンされた文書からのテキスト要素の認識(テキスト中心型OCR)に注力しており、チャートやウェブページ、科学的プロットなど、視覚情報が豊富な画像源からの視覚的要素の識別(視覚中心型OCR)にはほとんど対応していない。実際、こうした視覚情報が濃密に凝縮された画像はインターネット上に広く存在し、データ可視化やウェブページ解析など、実世界での応用価値が非常に高い。本技術報告では、エンド・トゥ・エンドの形で、統合的なテキスト中心型OCRと視覚中心型OCRを実現する初めての包括的OCR手法「OCRVerse」を提案する。これに伴い、新聞、雑誌、書籍などテキスト中心型ドキュメントのほか、チャート、ウェブページ、科学的プロットなどの視覚中心型レンダリング合成データを網羅的にカバーするデータエンジニアリングを構築した。さらに、OCRVerse向けに、二段階のSFT-RLマルチドメイン学習手法を提案する。SFT(Supervised Fine-Tuning)では、異なるドメインのデータを直接混合して学習し、初期のドメイン知識を構築する。一方、RL(Reinforcement Learning)は、各ドメインの特性に応じたパーソナライズされた報酬戦略の設計に特化する。具体的には、異なるドメインでは出力フォーマットや期待される出力が異なり得るため、RL段階では各ドメインごとに柔軟な報酬信号をカスタマイズ可能な仕組みを提供することで、ドメイン間の統合性を高め、データの衝突を回避する。実験結果から、OCRVerseの有効性が確認され、テキスト中心型および視覚中心型の両データタイプにおいて競争力のある性能を達成しており、大規模なオープンソースおよびクローズドソースモデルと同等の結果を示した。
One-sentence Summary
Researchers from Meituan propose OCRVerse, the first end-to-end model unifying text-centric and vision-centric OCR via a two-stage SFT-RL training method, enabling flexible domain-specific rewards to handle diverse outputs from documents, charts, and web pages with performance rivaling major models.
Key Contributions
- OCRVerse introduces the first end-to-end holistic OCR framework that unifies text-centric and vision-centric recognition, addressing the gap in handling visually dense content like charts, web pages, and scientific plots that traditional OCR methods overlook.
- The method employs a two-stage SFT-RL training strategy: SFT mixes cross-domain data to build foundational knowledge, while RL customizes reward signals per domain to resolve output format conflicts and enhance domain-specific performance.
- Evaluated across diverse datasets, OCRVerse achieves competitive results on both text-centric and vision-centric tasks, matching performance of large open-source and closed-source models without domain-specific fine-tuning.
Introduction
The authors leverage the rise of vision-language models to tackle OCR as a unified, holistic task that spans both text-centric documents and vision-centric images like charts and web pages. Prior methods either focus narrowly on text extraction or handle visual elements in isolation, failing to capture semantic structures embedded in complex visuals or reconcile conflicting output formats across domains. OCRVerse addresses this by introducing a lightweight model trained via a two-stage SFT-RL method: supervised fine-tuning blends diverse data to build cross-domain foundations, while reinforcement learning applies domain-specific rewards to resolve conflicts and optimize structure-sensitive outputs like HTML or LaTeX. The result is a single end-to-end system that performs competitively across both OCR paradigms, enabling practical applications in data visualization and web analysis.
Dataset

The authors use OCRVerse, a unified dataset for holistic OCR, combining text-centric and vision-centric data types to support diverse real-world and professional scenarios.
-
Dataset Composition and Sources:
- Text-centric data covers 9 document types: natural scenes, books, magazines, papers, reports, slides, exam papers, notes, and newspapers — sourced from open datasets (LSVT, TextOCR, PDFA, DocStruct4M, DocGenome, IAM, ORAND-CAR, HME), real-world PDFs, and synthetic data (K12 to graduate exam questions, StackExchange math formulas).
- Vision-centric data covers 6 specialized domains: charts, webpages, icons, geometry, circuits, and molecules — sourced from MCD, MSRL, Web2M, Web2Code, UniSVG, DaTikZ-v3, Cosyn-400k, and text-to-mermaid datasets.
-
Key Details by Subset:
- Text-centric: Cleaned via quality checks, page splitting, regex extraction, and complexity categorization; annotated using VLMs (Qwen2.5-VL-72B, GOT), OCR tools, and synthetic HTML templates with MathJax/CSS rendering.
- Vision-centric: Cleaned by removing corrupted images and embedded visuals; self-annotated via bootstrapped domain-specific models (chart-to-code, webpage-to-HTML, image-to-SVG, image-to-LaTeX) to scale coverage.
-
Usage in Training:
- Training data is constructed via a multi-stage pipeline integrating both data types.
- For RL training, samples are selected via entropy-based filtering (text-centric) or quality refinement (vision-centric) to focus on challenging, high-complexity cases.
- Final training mix balances both data types to support holistic OCR capabilities.
-
Processing and Metadata:
- Text-centric annotations include bounding boxes, color-guided region parsing, LaTeX formulas, and HTML tables.
- Vision-centric annotations generate domain-specific code (SVG, HTML, LaTeX, mermaid) via rendering and structure extraction.
- No explicit cropping strategy is mentioned; focus is on full-page or element-level processing with structured output formats.
- Evaluated on OmniDocBench v1.5 (1,355 pages, bilingual, 9 document types) using Edit Distance, CDM, and TEDS metrics, aggregated into an Overall Score.
Method
The authors leverage a two-stage training methodology for OCRVerse, designed to first establish broad cross-domain knowledge and then refine domain-specific performance through personalized optimization. The overall framework, as illustrated in the figure below, consists of a Supervised Fine-Tuning (SFT) stage followed by a Reinforcement Learning (RL) stage, each addressing distinct aspects of the model's learning process.
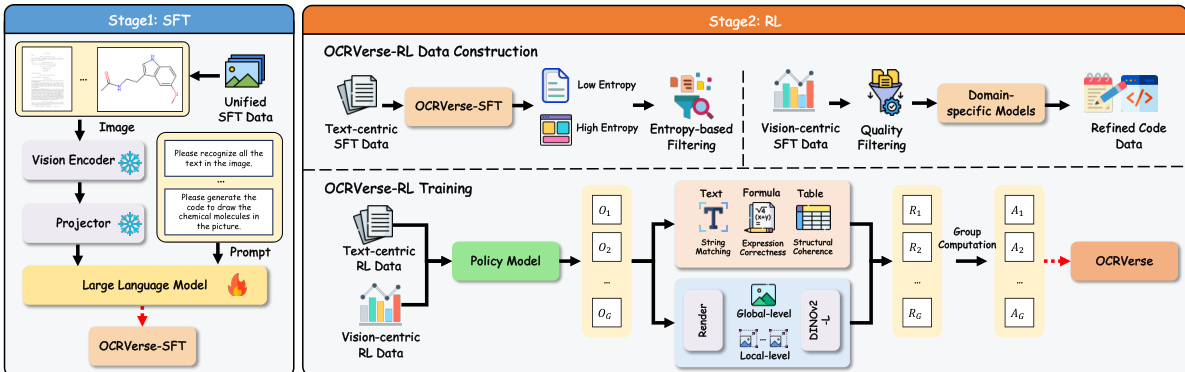
During the SFT stage, the model is fine-tuned on a unified dataset that combines data from all eight domains, including both text-centric (e.g., documents, tables, formulas) and vision-centric (e.g., charts, web pages, scientific plots) sources. This cross-domain data mixing enables the model to learn shared visual-semantic patterns across diverse data types while preserving domain-specific output capabilities. The training objective is formulated as standard autoregressive language modeling, where the model learns to predict the next token in the output sequence given the input image and previous tokens. The authors fine-tune the pre-trained Qwen3-VL-4B model, freezing the visual encoder and vision-language adapter to preserve strong visual representations, while updating only the language model parameters to focus on improving text generation and format compliance.
The RL stage addresses the limitations of SFT in handling domain-specific requirements and format-intensive content by introducing personalized reward mechanisms. The framework begins with domain-specific data construction, where data is filtered based on entropy to ensure high-quality inputs. For text-centric domains, rule-based reward functions are employed to evaluate different content types: one minus normalized edit distance for plain text, BLEU score for formulas after LaTeX normalization, and TEDS-S for tables after structural normalization. The overall text-centric reward is computed as a weighted average of these type-specific rewards. For vision-centric domains, visual fidelity rewards are designed to measure perceptual similarity between rendered outputs and ground truth images. This is achieved using a pre-trained DINOv2 encoder to extract visual features, with a multi-scale reward mechanism combining global-level similarity from downsampled thumbnails and local-level similarity from image patches. Additionally, format alignment rewards ensure generated code matches the expected programming language.
Policy optimization is performed using Group Relative Policy Optimization (GRPO). For each input, a group of responses is sampled from the current policy, and their rewards are computed. The group-normalized advantage for each response is calculated, and the policy is optimized by maximizing a clipped objective function that ensures training stability. This two-stage approach enables OCRVerse to effectively establish cross-domain knowledge during SFT and refine domain-specific capabilities during RL, achieving seamless fusion across diverse data types while avoiding conflicts that arise from naive multi-task learning.
Experiment
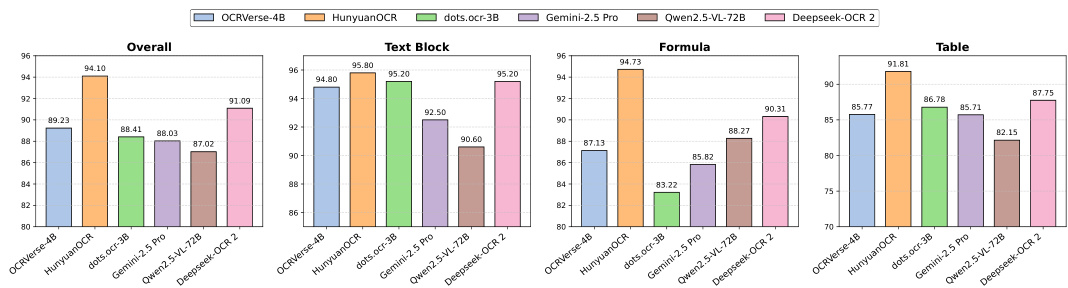
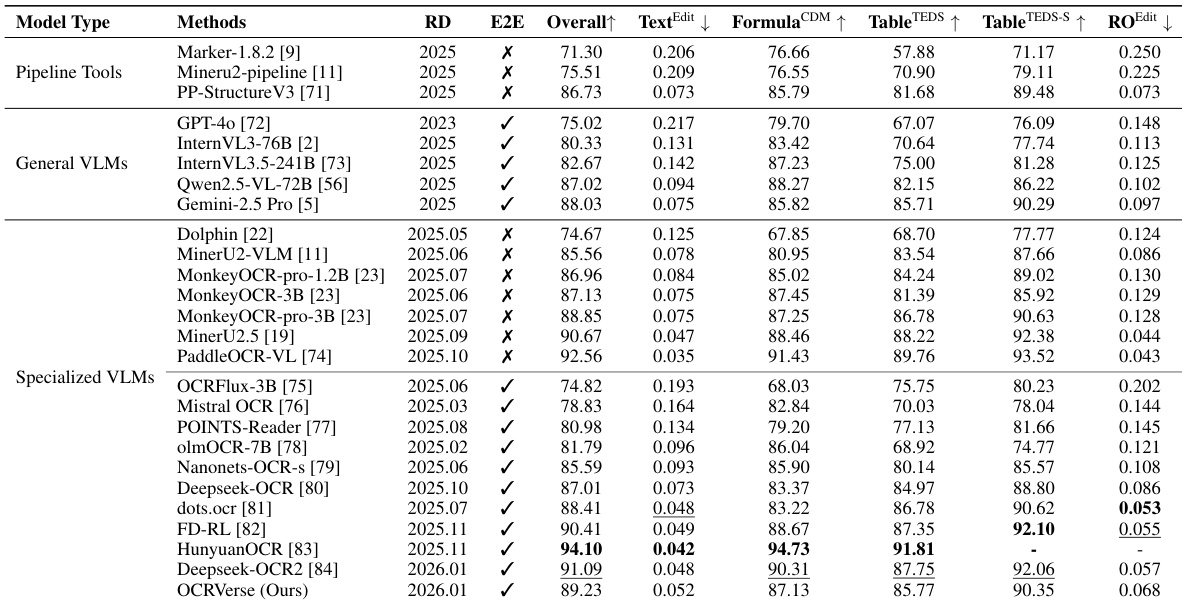
- OCRVerse evaluated on OmniDocBench v1.5 achieves 89.23 overall, outperforming Gemini-2.5 Pro (88.03) and Qwen2.5-VL-72B (87.02) despite fewer parameters, validating its holistic training approach.
- In formula recognition, OCRVerse scores 87.13 CDM, surpassing Deepseek-OCR (83.37) and olmOCR-7B (86.04), attributed to its synthetic formula data strategy spanning multiple disciplines and difficulty levels.
- For text and reading order, OCRVerse attains edit distances of 0.052 and 0.068, slightly behind layout-aware models like dots.ocr, indicating room for improvement via region-level OCR data integration.
- In table recognition, OCRVerse achieves TEDS 85.77 and TEDS-S 90.35, lagging behind Deepseek-OCR2 and HunyuanOCR; future work targets enriched table data for complex structures.
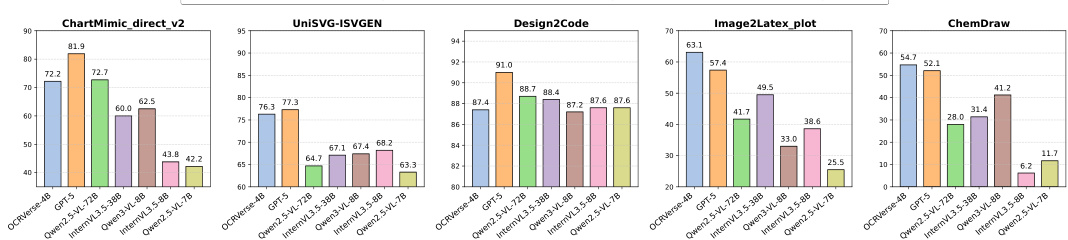
- On vision-centric tasks, OCRVerse (4B) outperforms larger models: 84.8% execution success on ChartMimic (vs. Qwen3-VL-8B’s 78.3%), ranks second on UniSVG (76.3, behind GPT-5’s 77.3), and leads Image2LaTeX-plot (88.7% rendering success, vs. GPT-5’s 78.7%) and ChemDraw (89.1% execution success).
- OCRVerse demonstrates strong parameter efficiency, matching or exceeding 70B models in multiple vision-to-code benchmarks, validating its multi-domain training and holistic OCR paradigm.
Results show that OCRVerse-4B achieves strong performance across multiple document parsing tasks, outperforming larger models like Gemini-2.5 Pro and Qwen2.5-VL-72B on OmniDocBench v1.5 with an overall score of 89.23, demonstrating its parameter efficiency and effectiveness in text-centric OCR. In vision-centric tasks, OCRVerse-4B surpasses significantly larger models on key benchmarks, achieving 84.8% execution success on ChartMimic and 88.7% rendering success on Image2LaTeX-plot, highlighting its superior fine-grained visual understanding and capability in structured code generation.
Results show that OCRVerse achieves competitive performance across vision-centric OCR tasks, outperforming larger models in several benchmarks. On ChartMimic, OCRVerse surpasses Qwen2.5-VL-72B in low-level and high-level scores despite being 18 times smaller, and on Image2LaTeX-plot, it significantly exceeds all baselines with a 88.7% rendering success rate. The model also achieves strong results on UniSVG and ChemDraw, demonstrating its ability to generate accurate code representations from complex visual inputs.
Results show that OCRVerse achieves an overall score of 89.23 on OmniDocBench v1.5, outperforming general-purpose models like Gemini-2.5 Pro and Qwen2.5-VL-72B despite having significantly fewer parameters. It demonstrates strong performance in formula recognition with a CDM score of 87.13 and competitive results in text and reading order tasks, though it lags behind layout-aware models in fine-grained spatial understanding.
Results show that OCRVerse achieves competitive performance across vision-centric OCR benchmarks, outperforming larger open-source models in several metrics. On ChartMimic, it surpasses Qwen2.5-VL-72B despite being 18 times smaller, and on Image2LaTeX-plot, it significantly exceeds all baselines with a 88.7% rendering success rate. The model also achieves strong results on UniSVG and ChemDraw, demonstrating its ability to generate accurate code representations from complex visual inputs.
