Command Palette
Search for a command to run...
自律的数学研究へ向かって
自律的数学研究へ向かって
概要
近年の基礎モデルの進展により、国際数学オリンピックで金メダルレベルの成績を達成できる推論システムが登場した。しかし、コンペティションレベルの問題解決から専門的数学研究へと移行するには、膨大な文献を把握し、長期にわたる証明を構築する能力が求められる。本研究では、自然言語でエンドツーエンドに解法を反復生成・検証・修正する数学研究エージェント「Aletheia」を紹介する。具体的には、Aletheiaは以下の3つの主要な要素によって駆動されている:(i) 挑戦的な推論問題に対応する高度なGemini Deep Thinkの改良版、(ii) 数学オリンピックレベルを越える問題にまで拡張可能な、新たな推論時スケーリング則、(iii) 数学研究の複雑性に対応するための積極的なツール活用。本研究では、Aletheiaが数学オリンピック問題から博士課程レベルの演習問題まで対応できることを実証するとともに、特にAI支援数学研究における以下の3つの重要なマイルストーンを達成した:(a) 数学的幾何学における「固有重み(eigenweights)」と呼ばれる特定の構造定数の計算を完全にAIが独自に処理した研究論文(Feng26)の生成;(b) 相互作用粒子系である「独立集合(independent sets)」に関する上限の証明において、人間とAIの協働を実証した研究論文(LeeSeo26);(c) BloomのErdős予想データベースに掲載された700件の未解決問題に対する広範な半自律的評価(Fengら、2026a)において、4件の未解決問題を自律的に解決した。AIと数学の進展を一般に理解しやすくするため、本研究では、AI支援成果の「自律性の標準レベル」と「新規性」を定量的に評価することの重要性を提言するとともに、透明性を高めるための新しい概念として「人間-AI協働カード(human-AI interaction cards)」を提案する。最後に、数学における人間とAIの協働についての考察を述べる。
One-sentence Summary
Google DeepMind researchers introduce Aletheia, an autonomous mathematical research agent powered by an advanced Gemini Deep Think model, a novel inference-time scaling law, and tool-augmented reasoning with web search and Python, which achieves state-of-the-art performance on IMO-ProofBench (95.1%) and FutureMath Basic, and delivers three landmark milestones: a fully AI-generated paper on eigenweights in arithmetic geometry (Feng26), a human-AI collaborative proof on independent sets (LeeSeo26), and autonomous solutions to four open Erdős conjectures—distinguishing itself from formal-methods systems by operating end-to-end in natural language with iterative generation, verification, and revision.
Key Contributions
- The paper introduces specialized math reasoning agents that integrate informal natural language verification to bridge the gap between unreliable LLM reasoning and underdeveloped formal systems in mathematical research.
- It establishes a framework for human-AI collaboration in mathematics by demonstrating a strategy that guarantees success with at most two penalty points in a 3002-row, 3001-column adversarial grid with 3000 traps.
- The work confirms that AI can augment, not replace, mathematicians—showing that human oversight remains essential for correcting hallucinations and guiding problem formulation in current systems.
Introduction
The authors leverage advanced language models to bridge the gap between competition-level mathematical reasoning and autonomous research, where solving open problems requires synthesizing vast, specialized literature rather than answering self-contained contest questions. Prior systems, even those achieving gold-medal performance at the International Mathematical Olympiad, struggle with hallucinations and shallow understanding due to limited exposure to research-grade mathematical content. To overcome these limitations, the authors introduce Aletheia, a math research agent that combines an enhanced reasoning model, a novel inference-time scaling law, and intensive tool use—including web browsing and search—to iteratively generate, verify, and revise proofs in natural language. Aletheia achieves milestone results: autonomously deriving eigenweights in arithmetic geometry, enabling human-AI collaboration on bounds for independent sets, and solving four long-open Erdős problems, while the team proposes a taxonomy of autonomy levels and human-AI interaction cards to standardize transparency and evaluation in AI-assisted mathematics.
Method
The Aletheia agent, powered by Gemini Deep Think, employs a multi-agent iterative framework designed to solve research-level mathematical problems through a structured cycle of generation, verification, and revision. The overall architecture consists of three primary subagents: a Generator, a Verifier, and a Reviser, which operate in a closed-loop process until a solution is validated or a maximum number of attempts is reached. The framework begins with a problem input, which is processed by the Generator to produce a candidate solution. This solution is then evaluated by the Verifier, which assesses its correctness. If the solution is deemed correct, it is finalized as the output. Otherwise, if minor fixes are required, the solution is passed to the Reviser, which modifies the candidate solution before returning it to the Generator for re-evaluation. This iterative refinement continues until the Verifier approves the solution or the attempt limit is exhausted.
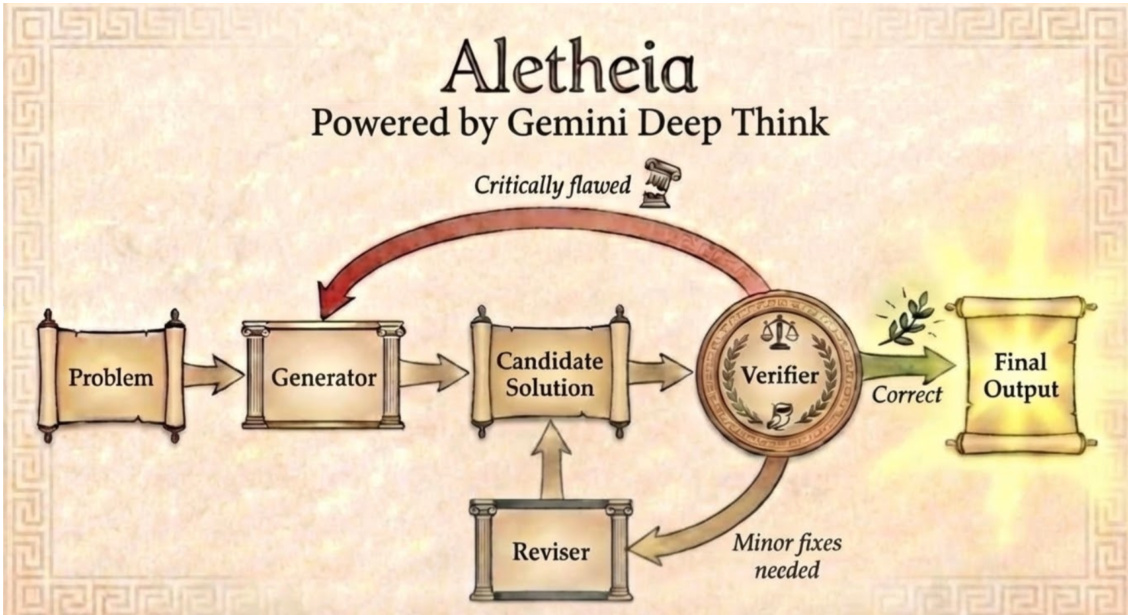
Each subagent in the system is internally orchestrated through calls to the Gemini base model, enabling the agent to leverage advanced language understanding and reasoning capabilities. The Generator is responsible for producing initial or revised candidate solutions, while the Verifier evaluates the logical consistency and correctness of these solutions. The Reviser handles the refinement of solutions based on feedback from the Verifier, ensuring that the generated content is progressively improved. This modular design allows Aletheia to address the challenges of research-level mathematics, where solutions often require deep domain knowledge and sophisticated reasoning beyond standard high school curricula. The system operates end-to-end in natural language, distinguishing it from formal language-based approaches such as AlphaGeometry and AlphaProof. The iterative nature of the framework enables Aletheia to iteratively generate, verify, and revise solutions, ultimately producing high-quality outputs that meet the rigorous standards of mathematical research.
Experiment
Experiments evaluated the scaling of inference compute on Olympiad- and PhD-level math problems, revealing that while increased compute improves accuracy on competition problems, it plateaus and fails to resolve the hallucinations and misinterpretations prevalent in research-grade reasoning. The introduction of Aletheia, an agentic framework with explicit verification and tool use, significantly outperformed prior models by reducing erroneous outputs and admitting failure when uncertain, though it still struggled with subtle citation errors and misinterpretations of open-ended problems. Case studies on Erdős conjectures showed that while AI can produce technically correct solutions, most are mathematically trivial or misaligned with problem intent, highlighting that current systems excel at retrieval and manipulation rather than genuine creativity or deep understanding.
The authors conducted ablation studies to compare the performance of Gemini Deep Think against Aletheia on research problems. Results show that Deep Think successfully reproduced some solutions but failed on others, particularly on more complex prompts, despite using similar compute. The comparison highlights Aletheia's superior performance in solving research-level problems. Gemini Deep Think successfully reproduced some solutions but failed on others, especially on complex prompts. Deep Think used similar compute but performed worse than Aletheia on most research problems. Aletheia demonstrated superior performance in solving research-level problems compared to Deep Think.

The the the table summarizes the outcomes of Aletheia's performance on a set of Erdős problems, indicating which problems were correctly solved and which were not. The results show a mix of successful and failed attempts, with some problems marked as correctly solved and others as incorrect or ambiguous. Aletheia successfully solved several Erdős problems, as indicated by the checkmarks in the the the table. Some problems were marked as incorrect, with red X's indicating failed attempts. The the the table includes a range of problems, with varying outcomes, reflecting the model's performance across different challenges.

The the the table summarizes the evaluation of 200 AI-generated solutions to Erdős problems, categorizing them into fundamentally flawed, technically correct, and meaningfully correct. Results show that the majority of solutions were flawed, with only a small fraction being both technically and meaningfully correct. Most AI-generated solutions were fundamentally flawed, making up the majority of the evaluated candidates. A minority of solutions were technically correct, but only a small subset addressed the intended problem correctly. The evaluation highlights significant challenges in achieving meaningful correctness in AI-generated mathematical solutions.

Ablation studies compared Gemini Deep Think and Aletheia on research-level problems, revealing that Aletheia consistently outperformed Deep Think, especially on complex prompts, despite similar computational resources. Evaluation of AI-generated solutions to Erdős problems showed that most were fundamentally flawed, with only a small fraction achieving both technical and meaningful correctness, underscoring persistent challenges in generating reliable mathematical reasoning.