Command Palette
Search for a command to run...
MOSS-Audio-Tokenizer:将来のオーディオ基盤モデル向けに拡張されたオーディオトークナイザー
MOSS-Audio-Tokenizer:将来のオーディオ基盤モデル向けに拡張されたオーディオトークナイザー
概要
離散音声トークナイザーは、大規模言語モデルにネイティブな音声処理および生成能力を付与する上で基盤的な役割を果たしています。近年の進展にもかかわらず、既存の手法はしばしば事前学習済みエンコーダー、意味的蒸留(semantic distillation)、または異種のCNNベースアーキテクチャに依存しています。これらの設計は固定された誘導的バイアス(inductive biases)を導入するため、再構成の忠実度を制限し、効果的なスケーリングを阻害する要因となっています。本論文では、離散音声トークナイゼーションは、均質的かつスケーラブルなアーキテクチャを用いて完全にエンド・ツー・エンドで学習されるべきであると主張します。この目的の下、我々はまず、因果的Transformerブロックを用いた純粋にTransformerベースのアーキテクチャである「CAT(Causal Audio Tokenizer with Transformer)」を提案します。CATは、エンコーダー、量子化器(quantizer)、デコーダーを一括して、初期状態から最適化することで、高忠実度の再構成を実現します。CATアーキテクチャを基盤として、300万時間に及ぶ多様な一般音声データで事前学習された、16億パラメータを有する大規模音声トークナイザー「MOSS-Audio-Tokenizer」を構築しました。本研究では、均質的かつ因果的Transformerブロックから構成されるこのシンプルなエンド・ツー・エンドアーキテクチャが、スケーリングに応じて滑らかに性能向上を示し、音声、音響、音楽という多様な音声ドメインにおいて高忠実度の再構成を実現できることを示しました。話声、音響、音楽の各領域において、MOSS-Audio-Tokenizerは広範なビットレート範囲で従来のコーデックを一貫して上回り、モデル規模の拡大に伴い予測可能な性能向上を示しました。特に、本モデルから得られる離散トークンを活用することで、従来の非自己回帰型および段階的(cascaded)システムを上回る、初めての完全自己回帰型TTS(音声合成)モデルを構築しました。さらに、補助的なエンコーダーを用いずに、競争力のあるASR(音声認識)性能を達成できることも示しました。これらの成果により、CATアーキテクチャが次世代のネイティブ音声基盤モデルにおける統一的かつスケーラブルなインターフェースとしての可能性を示唆しています。
One-sentence Summary
MOSI.AI researchers propose CAT, a fully end-to-end, Transformer-based audio tokenizer, enabling high-fidelity reconstruction and scalable audio foundation models; their 1.6B-parameter MOSS-Audio-Tokenizer outperforms prior codecs across speech, music, and sound, and powers state-of-the-art autoregressive TTS and ASR without auxiliary encoders.
Key Contributions
- We introduce CAT, a fully end-to-end, homogeneous Transformer-based architecture for discrete audio tokenization that jointly optimizes encoder, quantizer, and decoder from scratch, eliminating reliance on pretrained components or heterogeneous CNN designs to improve reconstruction fidelity and scalability.
- We scale CAT into MOSS-Audio-Tokenizer, a 1.6B-parameter model trained on 3 million hours of diverse audio, which achieves state-of-the-art reconstruction across speech, sound, and music at all bitrates and exhibits predictable performance gains with scale.
- Leveraging MOSS-Audio-Tokenizer’s tokens, we build the first purely autoregressive TTS system that outperforms non-autoregressive and cascaded baselines, and demonstrate competitive ASR performance without auxiliary encoders, validating CAT as a unified interface for audio foundation models.
Introduction
The authors leverage a fully end-to-end, homogeneous Transformer architecture—CAT—to build MOSS-Audio-Tokenizer, a scalable 1.6B-parameter audio tokenizer trained on 3 million hours of diverse audio. Prior tokenizers often rely on pretrained encoders, hybrid CNN-Transformer designs, or multi-stage training, which introduce fixed inductive biases that limit reconstruction fidelity and hinder scaling. MOSS-Audio-Tokenizer overcomes these by jointly optimizing encoder, quantizer, and decoder from scratch under a causal, streaming-friendly framework, achieving state-of-the-art reconstruction across speech, sound, and music at all bitrates. Its discrete tokens enable the first purely autoregressive TTS system to outperform non-autoregressive and cascaded baselines, and support competitive ASR without auxiliary encoders—positioning CAT as a unified foundation for scalable, native audio language models.
Dataset
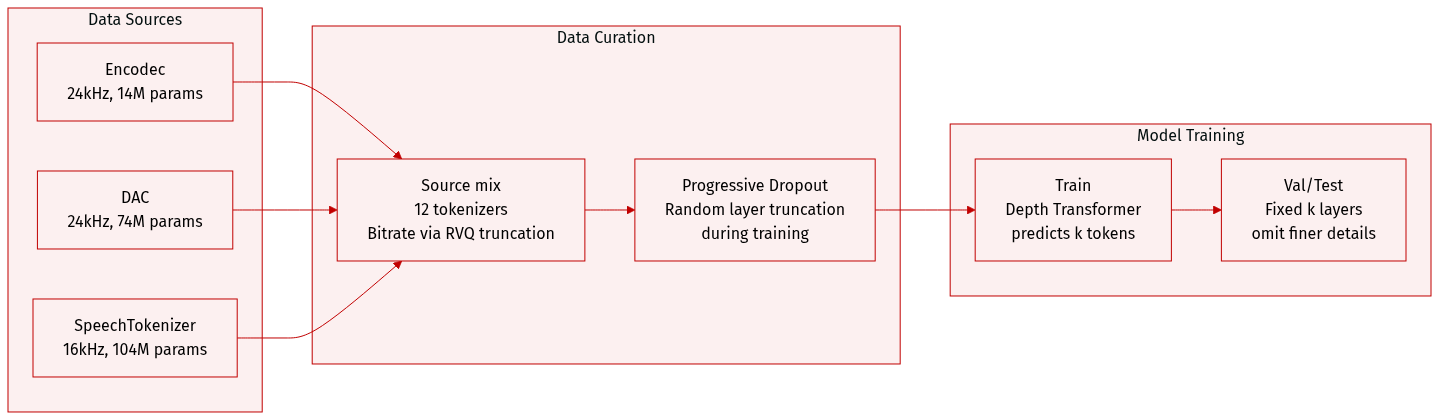
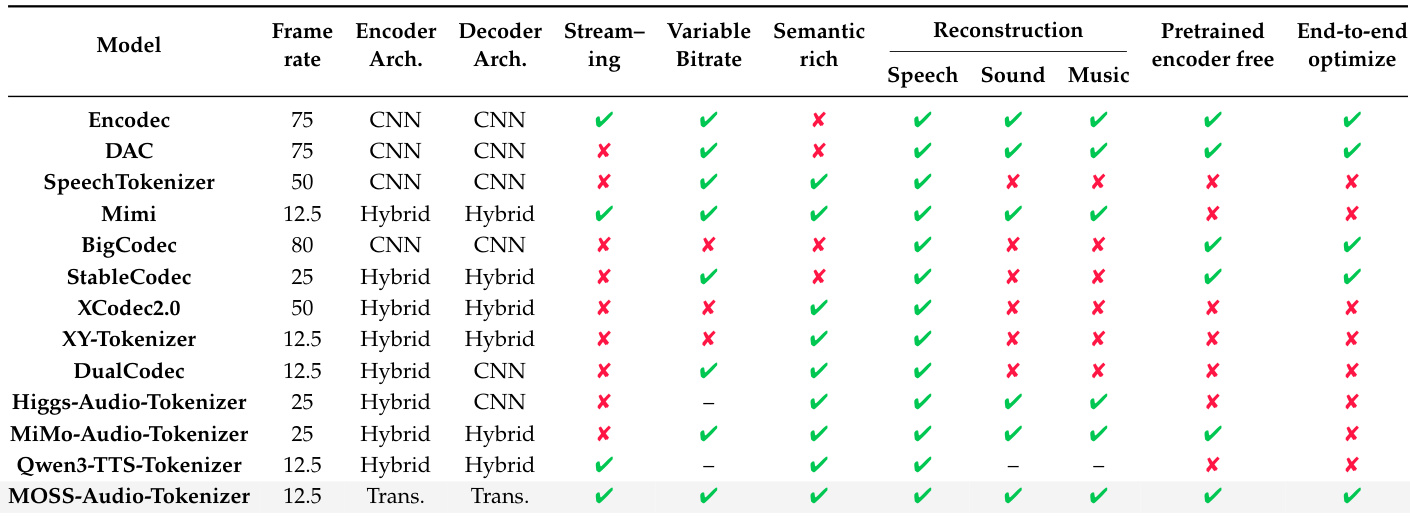
The authors use a collection of 12 baseline audio tokenizers for evaluation, each sourced from official releases and configured for monophonic audio at either 16 kHz or 24 kHz. Key details:
- Encodec: Official causal model at 24 kHz; ~14M parameters. Bitrate controlled by truncating RVQ layers during eval.
- DAC: 24 kHz monophonic model; ~74M parameters. Uses engineered discriminators and improved VQ.
- SpeechTokenizer: Trained on 16 kHz speech; ~103.67M parameters. Distills HuBERT via first RVQ layer for speech disentanglement.
- Mimi: 24 kHz; outputs tokens at 12.5 Hz. Supports streaming encoding/decoding.
- BigCodec: 16 kHz; single VQ codebook (size 8,192); 80 Hz frame rate; ~159M parameters.
- Stable Codec: 16 kHz speech; uses RFSQ bottleneck; ~953M parameters. Eval uses 1x46656_400bps and 2x15625_700bps presets.
- XCodec2.0: 16 kHz; integrates pre-trained speech encoder; 50 Hz frame rate; ~822M parameters.
- XY-Tokenizer: 16 kHz; jointly models semantic/acoustic info via dual encoders; 12.5 Hz, 8-layer RVQ (codebook 1,024); ~519M parameters. Quantizer dropout disabled.
- Higgs Audio Tokenizer: 24 kHz; ~201M parameters.
- MiMo Audio Tokenizer: Trained on >11M hours; supports waveform reconstruction and language modeling; ~1.2B parameters.
- Qwen3 TTS Tokenizer: 24 kHz; 12.5 Hz frame rate; ~170M parameters. Designed for streaming TTS.
For bitrate control during training, the authors apply Progressive Sequence Dropout to randomly truncate active RVQ layers. At inference, decoding uses only the first k RVQ tokens per timestep, and the Depth Transformer autoregressively predicts only those k tokens, omitting finer layers. All models are evaluated under their default or recommended configurations without further filtering or dataset composition beyond their original training data.
Method
The authors leverage a purely Transformer-based architecture, CAT (Causal Audio Tokenizer with Transformer), to achieve scalable, high-fidelity discrete audio tokenization without relying on convolutional inductive biases. The framework operates directly on raw waveforms and is designed for end-to-end training, supporting both semantic alignment and acoustic reconstruction. Refer to the framework diagram for an overview of the encoder-decoder structure and auxiliary components.
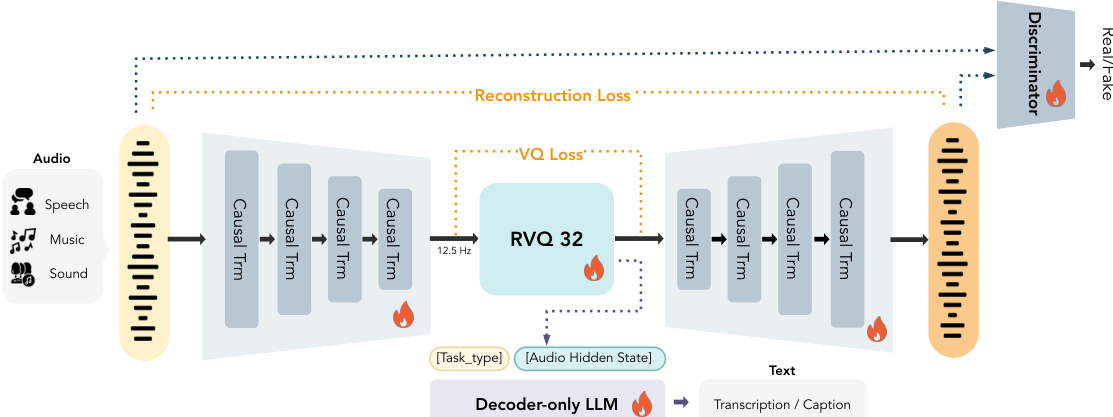
The encoder processes raw 24 kHz audio by first patchifying the waveform into fixed-dimensional vectors and then applying a stack of causal Transformer blocks. To progressively compress the temporal resolution, patchify operations are inserted after specific Transformer layers, reducing the sequence length and ultimately mapping the input to a discrete token sequence at 12.5 Hz. The decoder mirrors this structure in reverse, reconstructing the waveform from discrete tokens in a fully causal manner. Discretization is handled by a 32-layer residual vector quantizer (RVQ), which supports variable-bitrate tokenization via quantizer dropout during training. Each quantization layer employs factorized vector quantization with L2-normalized codebooks, and the codebook entries are optimized directly via gradient descent.
To encourage semantically rich representations, the authors attach a 0.5B-parameter decoder-only causal language model (LLM) that conditions on the quantizer’s hidden states. The LLM is trained on diverse audio-to-text tasks—including ASR, multi-speaker ASR, and audio captioning—using a task-specific prompt token prepended to the input. The semantic loss is computed as:
Lsem=−t=1∑∣s∣logpθLLM(st∣T,q,s<t),where s is the target text sequence, q is the quantized audio representation, and T is the task tag.
Acoustic fidelity is ensured through a multi-scale mel-spectrogram loss:
Lrec=i=5∑11∥S2i(x)−S2i(x^)∥1,where S2i(⋅) denotes the mel-spectrogram computed with window size 2i and hop size 2i−2. Adversarial training with multiple discriminators further enhances perceptual quality, following the loss formulations from XY-Tokenizer. The overall generator objective combines semantic, reconstruction, commitment, codebook, adversarial, and feature matching losses with learnable weights:
LG=λsemLsem+λrecLrec+λcmtLcmt+λcodeLcode+λadvLadv+λfeatLfeat.All components—encoder, quantizer, decoder, LLM, and discriminators—are optimized jointly in an end-to-end fashion.
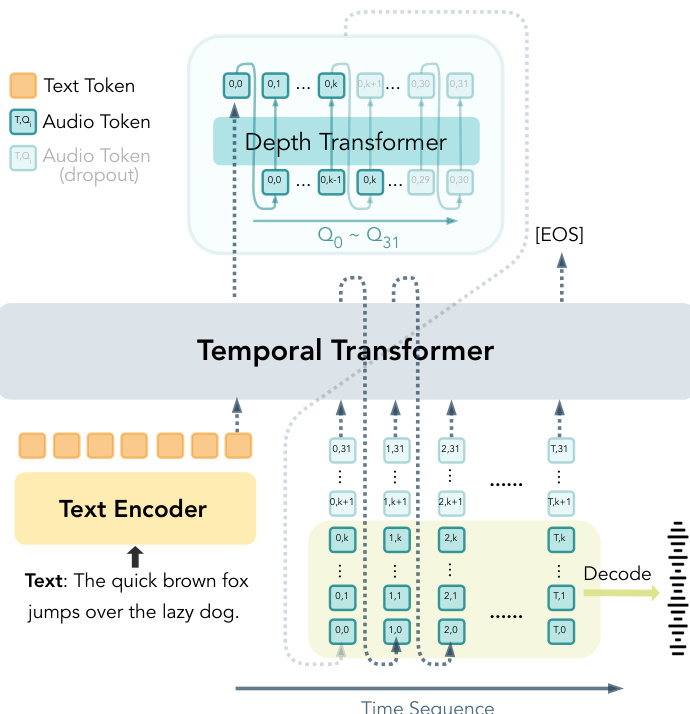
For end-to-end autoregressive speech generation, the authors build CAT-TTS, which directly predicts CAT’s RVQ tokens from text and speaker prompts. The model employs a Temporal Transformer to capture long-range dependencies across time and a Depth Transformer to model the coarse-to-fine structure within each time step. The Depth Transformer autoregressively predicts RVQ tokens conditioned only on previous time steps and preceding layers at the current step, preserving strict causality.
To enable variable-bitrate synthesis within a single model, the authors introduce Progressive Sequence Dropout. During training, with probability p, a random prefix length K∈{1,…,Nq−1} is sampled, and RVQ tokens from layers K+1 to Nq are dropped. The effective number of active layers is defined as:
K^=(1−z)Na+zK,where z∼Bernoulli(p). The Temporal Transformer receives aggregated embeddings from the first K^ layers at each time step:
e~t=k=1∑K^Embk(qt,k).The training loss is computed only over the retained prefix:
L=−t=1∑Tk=1∑K^logpθ(qt,k∣x,q<t,qt,<k).At inference, the synthesis bitrate is controlled by selecting an inference depth Kinfer. The Temporal Transformer processes the first Kinfer RVQ streams, and the Depth Transformer predicts only those layers. The resulting tokens are decoded into waveforms using the CAT decoder, which is inherently robust to varying bitrates due to quantizer dropout during training.
As shown in the figure below, the Temporal Transformer processes text and aggregated audio token embeddings over time, while the Depth Transformer autoregressively predicts RVQ tokens across layers, with dropout enabling variable-depth generation.
Experiment
- MOSS-Audio-Tokenizer excels in speech reconstruction across all bitrates, outperforming prior methods at low bitrates and achieving state-of-the-art results at medium and high bitrates; it maintains competitive performance on general audio and music, with quality improving as bitrate increases.
- Progressive Sequence Dropout significantly enhances robustness of the TTS system under reduced bitrates, enabling stable performance across varying dropout rates while reducing training memory usage; p=1.0 is adopted for optimal efficiency without quality loss.
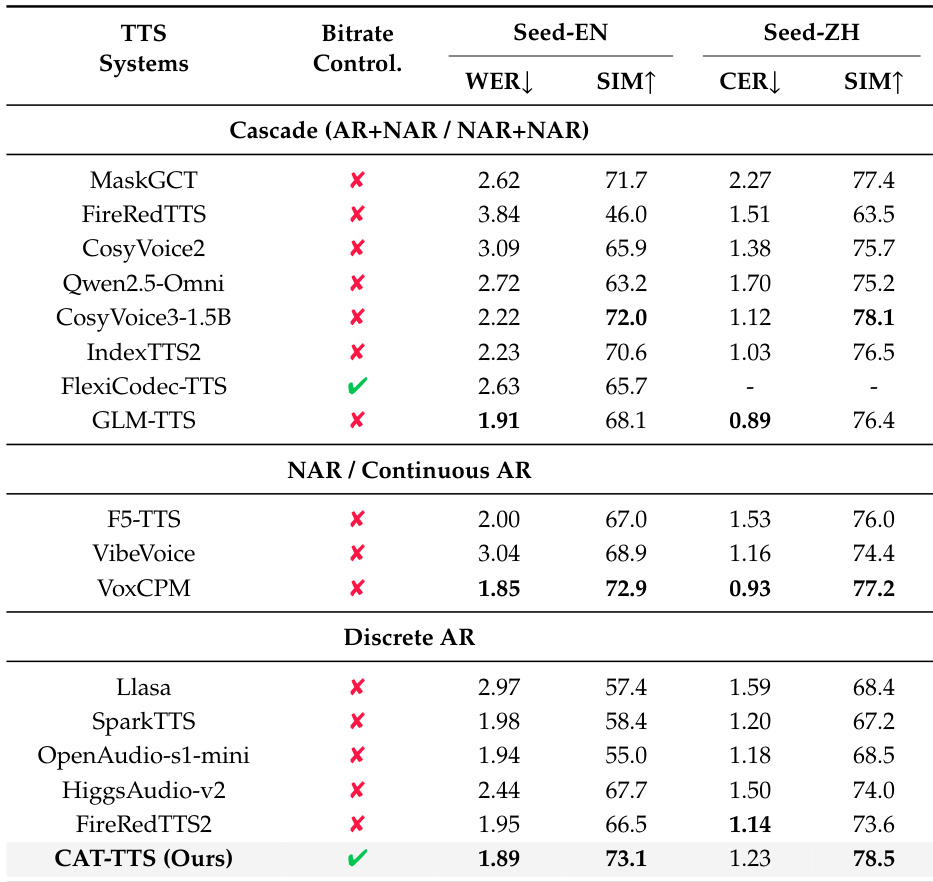
- CAT-TTS surpasses prior discrete autoregressive TTS models in speaker similarity and matches top systems like IndexTTS2 and VoxCPM in word error rate, achieving the highest speaker similarity scores on Seed-TTS-Eval for both English and Chinese, validating its effectiveness for zero-shot generation.
- End-to-end optimization is critical for CAT’s scalability, enabling continuous improvement in reconstruction quality with increased training, unlike partial optimization which plateaus early due to frozen components.
- Model parameters and quantization capacity must scale together; larger models benefit at high bitrates but underperform at low bitrates, revealing bitrate as the primary bottleneck—optimal scaling requires synchronized expansion of both.
- Reconstruction fidelity consistently improves with increased training batch size, showing predictable scaling behavior where higher throughput directly translates to higher quality within the same training steps.
- Subjective evaluations confirm MOSS-Audio-Tokenizer delivers high perceptual quality across bitrates, outperforming variable-bitrate tokenizers at low bitrates and matching specialized tokenizers at their target bitrates.
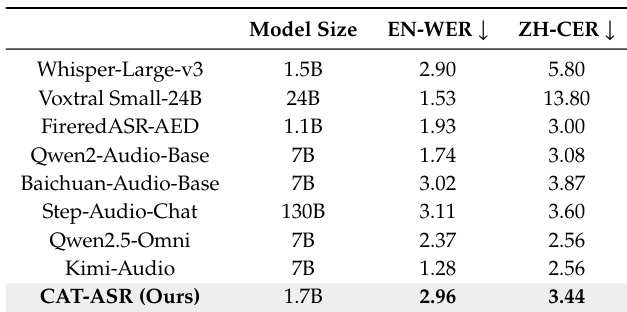
- CAT tokens support effective speech understanding: CAT-ASR achieves competitive WER and CER on English and Chinese benchmarks when fed directly into an LLM, demonstrating strong alignment with text and sufficient linguistic content preservation.
The authors use CAT-TTS, a fully autoregressive discrete token-based system, to achieve state-of-the-art speaker similarity scores on both English and Chinese benchmarks while maintaining low word error rates. Results show that CAT-TTS outperforms prior discrete autoregressive models and matches or exceeds performance of recent cascaded and non-autoregressive systems, demonstrating the effectiveness of its unified discrete interface for high-quality zero-shot speech generation. The system also supports variable bitrate control, enabling flexible synthesis without compromising fidelity.
The authors use MOSS-Audio-Tokenizer to achieve strong reconstruction across speech, sound, and music at multiple bitrates, outperforming prior methods especially at low and medium bitrates while maintaining scalability through end-to-end optimization. Results show that its transformer-based architecture, variable bitrate support, and semantic richness contribute to consistent high-quality reconstruction without relying on pretrained encoders. The model’s design enables robust performance across domains and bitrates, distinguishing it from other tokenizers that either lack end-to-end training or fail to scale effectively.
The authors use CAT tokens as direct inputs to a large language model for automatic speech recognition, achieving competitive word and character error rates on English and Chinese benchmarks. Results show that CAT tokens preserve sufficient linguistic content and align well with text, enabling effective speech understanding without additional alignment or auxiliary supervision.
MOSS-Audio-Tokenizer consistently outperforms or matches other open-source audio tokenizers across speech, general audio, and music benchmarks at low, medium, and high bitrates, with performance improving as bitrate increases. The model demonstrates strong scalability through end-to-end optimization, maintaining high reconstruction fidelity even under variable bitrate conditions. Its design enables robust performance across diverse audio types without requiring separate models for different bitrates or domains.
