Command Palette
Search for a command to run...
UI-Venus-1.5 技術報告
UI-Venus-1.5 技術報告
概要
GUIエージェントは、デジタル環境におけるインタラクション自動化の強力なパラダイムとして浮上しているが、広範な汎用性と一貫した優れたタスク性能の両立は依然として課題である。本報告では、実世界における堅牢な応用を目的とした統合的かつエンドツーエンド型GUIエージェント「UI-Venus-1.5」を紹介する。提案モデルファミリーは、さまざまな下流アプリケーションシーンに対応するため、2Bおよび8Bの2つの密結合型バージョンと、30B-A3Bという混合専門家型(mixture-of-experts)バージョンを含む。前バージョンと比較して、UI-Venus-1.5は以下の3つの主要な技術的進展を導入している:(1)30以上のデータセットを対象に100億トークン規模の訓練を活用した包括的な中間訓練ステージにより、基礎的なGUI意味を確立;(2)全軌道(full-trajectory)を用いたオンライン強化学習により、大規模環境における長期的・動的なナビゲーションを想定した訓練目標を実現;(3)モデル統合(Model Merging)を用いて構築された単一の統合GUIエージェントにより、ドメイン特化型モデル(グランドイング、ウェブ、モバイル)を一つの統一されたチェックポイントに統合。広範な評価結果から、UI-Venus-1.5はScreenSpot-Pro(69.6%)、VenusBench-GD(75.0%)、AndroidWorld(77.6%)といったベンチマークにおいて、新たなSOTA(最良の成果)を達成し、既存の強力なベースラインを大幅に上回ることが示された。さらに、UI-Venus-1.5は中国語モバイルアプリケーションにおいても堅牢なナビゲーション能力を示し、実世界のシナリオにおいてユーザー指示を効果的に実行できることが確認された。コード:https://github.com/inclusionAI/UI-Venus;モデル:https://huggingface.co/collections/inclusionAI/ui-venus
One-sentence Summary
Venus Team at Ant Group introduces UI-Venus-1.5, a unified GUI agent family (2B/8B/30B) that advances real-world automation via mid-training on 10B tokens, online RL with full-trajectory rollouts, and model merging—outperforming SOTA on benchmarks like ScreenSpot-Pro (69.6%) and AndroidWorld (77.6%) while excelling in Chinese mobile apps.
Key Contributions
- UI-Venus-1.5 introduces a mid-training stage using 10 billion tokens across 30+ datasets to build foundational GUI semantics, enabling strong zero-shot performance on grounding and navigation tasks before reinforcement learning begins.
- It employs scaled online reinforcement learning with full-trajectory rollouts to align training with long-horizon navigation, addressing step-trace accuracy mismatches and improving performance on dynamic benchmarks like AndroidWorld (77.6% success rate).
- The model unifies domain-specific capabilities (grounding, web, mobile) via model merging into a single end-to-end checkpoint, achieving state-of-the-art results across benchmarks including ScreenSpot-Pro (69.6%) and VenusBench-GD (75.0%) while maintaining real-world usability in Chinese mobile apps.
Introduction
The authors leverage GUI agents—systems that visually interpret and interact with digital interfaces—to automate real-world tasks across mobile and web environments. Prior approaches often rely on static datasets or rigid frameworks, leading to brittle performance in dynamic, long-horizon scenarios and a mismatch between step-level and trace-level accuracy. UI-Venus-1.5 addresses these gaps with three key innovations: a mid-training phase using 10B tokens across 30+ GUI datasets to build foundational understanding, online reinforcement learning with full-trajectory rollouts to better align training with real-world navigation, and model merging to unify grounding, web, and mobile capabilities into a single end-to-end agent. The result is a family of models (2B, 8B, and 30B MoE) that set new state-of-the-art benchmarks in grounding and navigation while demonstrating robust performance across 40+ Chinese mobile apps in practical tasks like booking and shopping.
Dataset

-
The authors use a 10B-token Mid-Training corpus built from over 30 diverse sources—including Mind2Web, ShowUI, and AITW—to bridge the gap between general vision-language understanding and fine-grained GUI structural modeling. This corpus is stratified to cover four functional areas: semantic perception (20.8%), GUI-VQA (22.1%), grounding (24.8%), and hybrid navigation-reasoning (32.3%).
-
Each subset supports distinct supervision objectives: Navigation & Grounding aligns language instructions with executable actions; Sequential Reasoning generates Chain-of-Thought traces; GUI-VQA interprets component semantics and layout logic; Fine-Grained Perception captures icon states, widget attributes, and OCR-free dense captions.
-
To improve data quality, the authors implement an iterative refinement pipeline: Qwen3-VL-235B scores samples (0–10) based on action-visual alignment and task reachability. High-quality traces (score ≥7) are kept; mid-quality (4–6) are rewritten; low-quality (0–3) are reconstructed or discarded. This raises high-fidelity sample proportion from 69.7% to 89.7%, followed by manual verification.
-
A real-device data generation loop further augments the corpus: seed prompts are expanded via MLLM, verified for semantic uniqueness, executed on cloud devices, and scraped for trajectories. Verified traces are fed back as in-context examples, boosting generation success from 17.9% to over 70%. This yields 30,000+ verified interaction trajectories.
-
All actions from source datasets are mapped to a unified action space defined in Table 8, ensuring consistency across training. The Mid-Training phase serves as foundational representation building, preparing the model for subsequent RL stages by encoding GUI layouts and interaction logic.
Method
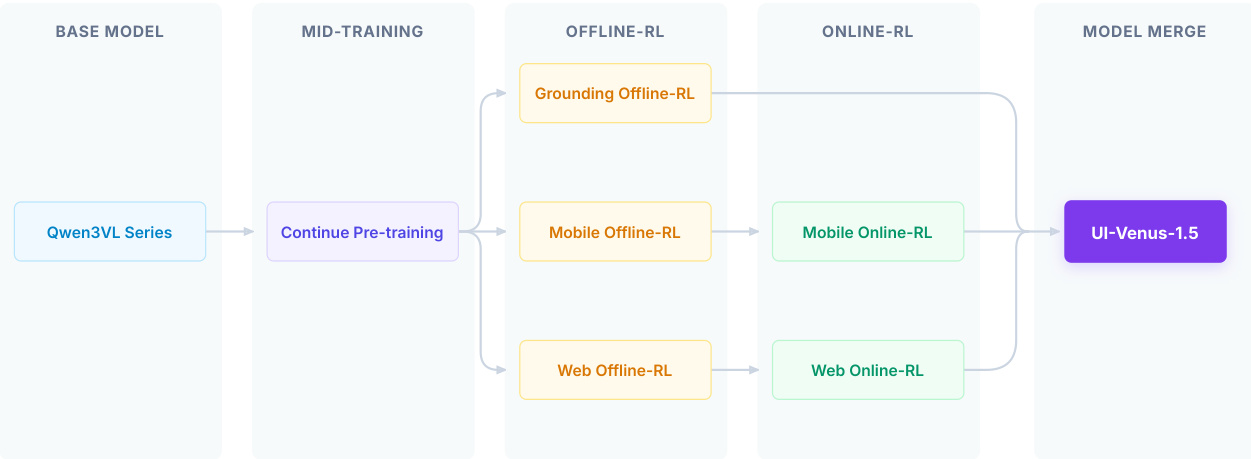
The authors leverage a unified, end-to-end multimodal agent architecture, UI-Venus-1.5, designed to translate natural language instructions into executable GUI interactions across mobile and web environments. The system operates via a closed-loop perception-action mechanism: it ingests a user task, interprets the current interface state from a screenshot, grounds the semantic intent into a concrete action, and iteratively executes interactions until task completion. This design eliminates the need for handcrafted intermediate representations or platform-specific APIs, enabling seamless deployment across heterogeneous interfaces. As shown in the framework diagram, the agent interfaces with both mobile and web GUI environments through a unified action space, which includes primitives such as Click, Drag, Scroll, Type, and newly introduced web-specific actions like Hover, DoubleClick, and Hotkey.
The training pipeline is structured into four distinct stages. It begins with a base Qwen3VL Series model, which undergoes mid-training via continue pre-training on large-scale GUI data to inject domain-specific knowledge. This is followed by three parallel Offline-RL phases—Grounding, Mobile, and Web—each optimized for a specific objective using a decoupled reward system. The grounding phase employs a reward composed of format correctness Rformat and point-in-box localization precision Rpoint-in-box, weighted by w1 and w2 respectively. A key innovation is the incorporation of refusal capability: when an instruction references a non-existent UI element, the model is trained to output [−1,−1], mitigating hallucinations. For navigation tasks, the reward system is extended to include an action reward Raction, which decomposes into action-type accuracy Rtype and either content-based F1-score Rcontent or hierarchical coordinate tolerance Rcoord. The total reward is then R=w1⋅Rformat+w2⋅Raction.
To address the limitation of Offline-RL—where step-level rewards fail to optimize for full trace success—the authors introduce an Online-RL stage. This stage explicitly optimizes for trace-level rewards using the Group Relative Policy Optimization (GRPO) algorithm. GRPO bypasses the need for a value function by estimating relative advantages from a group of sampled trajectories. For a task q, the agent generates G trajectories {τi} under the current policy πθold. The trajectory-level advantage A^i is computed by normalizing the composite reward R(τi,q)—which includes task completion, invalid action penalties, and a trace length decay—relative to the group mean and standard deviation. The GRPO loss is then defined as:
LGRPO(θ)=−G1i=1∑G∣τi∣1t=1∑∣τi∣min(ri,t(θ)A^i,clip(ri,t(θ),1−ϵ,1+ϵ)A^i),where ri,t(θ) is the importance sampling ratio. To ensure stability, the authors incorporate an adaptive KL constraint against a reference policy πref, which is updated when the current policy outperforms it, and an annealed entropy regularization term to balance exploration and exploitation. The final optimization objective is J(θ)=LGRPO(θ)−LKL(θ)+Lentropy(θ).
The task pool for Online-RL is constructed via a hybrid strategy: static tasks are generated using LLMs for predefined applications, while dynamic tasks are inferred from offline trajectories using MLLMs and filtered for uniqueness via a semantic similarity threshold ϵ. Tasks are stratified by difficulty (Easy, Medium, Hard) based on expected step count to enable curriculum learning. Success is verified via a dual-track mechanism: rule-based checks for system-side outcomes and MLLM-as-a-Judge for semantically ambiguous tasks.
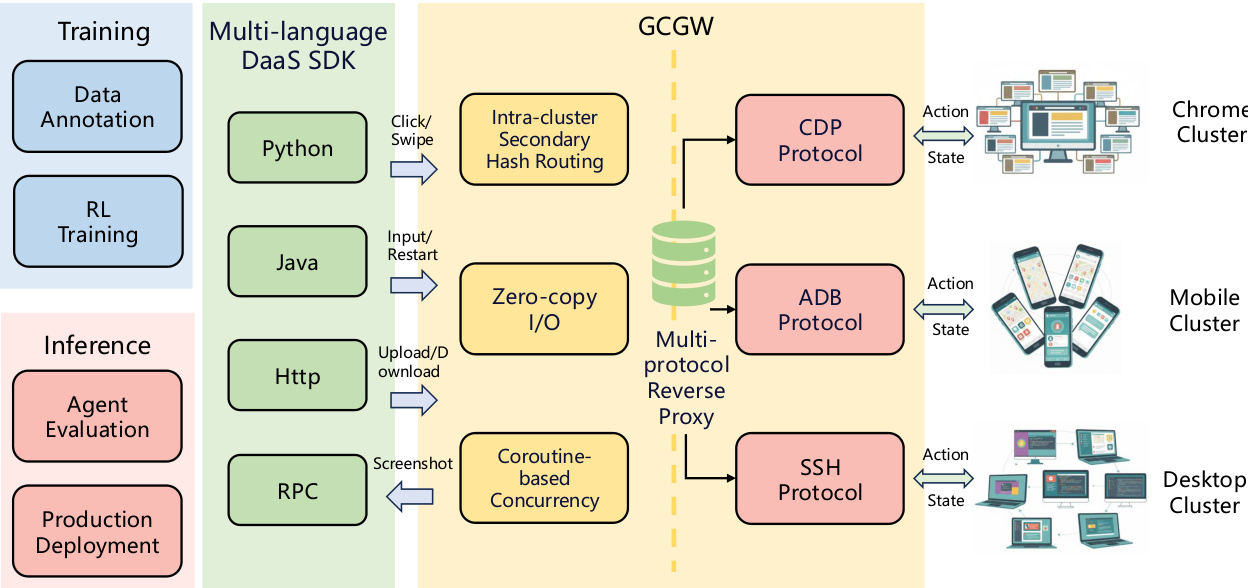
To support large-scale training and deployment across heterogeneous devices, the authors implement a Device-as-a-Service (DaaS) layer. This architecture consists of a Group Control Gateway (GCGW) and a Unified Client SDK. The GCGW acts as a multi-protocol reverse proxy, abstracting control protocols like ADB, CDP, and SSH. It employs a secondary hash routing algorithm to prevent connection explosion, zero-copy I/O for low-latency forwarding, and a coroutine-based model for high-concurrency support. The Unified Client SDK provides a multi-language API that automates device lifecycle management and standardizes interaction semantics, shielding users from protocol complexities.

Finally, after Offline-RL and Online-RL, the authors merge the specialized models (grounding, mobile, web) into a single unified agent. They compare Linear Merge, which performs a weighted interpolation of model weights θlinear=∑i=13wi⋅θi, with TIES-Merge, which prunes low-magnitude updates and resolves sign conflicts to reduce parameter interference. TIES-Merge consistently outperforms Linear Merge, achieving a harmonious balance across domains without the overhead of training a multi-task model from scratch.
Experiment
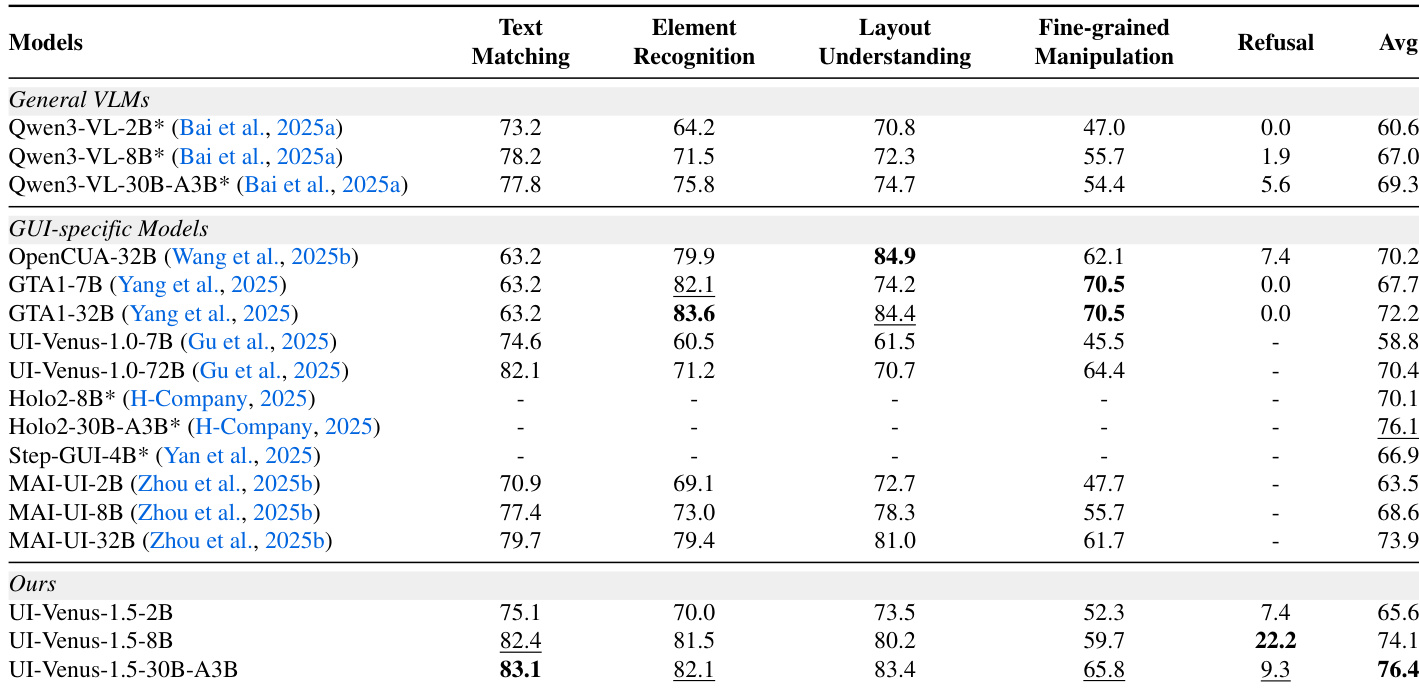
- UI-Venus-1.5 achieves state-of-the-art or top-tier grounding performance across diverse benchmarks, excelling in high-level reasoning (VenusBench-GD), fine-grained professional UIs (ScreenSpot-Pro), and complex desktop tasks (OSWorld-G, UI-Vision), while remaining highly competitive on broad cross-platform benchmarks (ScreenSpot-V2, MMBench-GUI L2).
- The model demonstrates strong scaling behavior, with consistent performance gains as parameter count increases, particularly evident in challenging domains like ScreenSpot-Pro and Android navigation tasks.
- UI-Venus-1.5 outperforms both GUI-specialized and general-purpose VLMs in end-to-end navigation across mobile (AndroidWorld, AndroidLab, VenusBench-Mobile) and web (WebVoyager) environments, even when using only visual inputs without XML metadata.
- Mid-Training enhances GUI-specific representation learning, improving cluster separability and feature discriminability in latent space without compromising global stability, providing a stronger foundation for downstream RL stages.
- Ablation studies confirm that Offline-RL builds foundational grounding and navigation capabilities, Online-RL delivers the most significant gains in complex, dynamic navigation, and Model Merge balances specialization with generalization, slightly trading off fine-grained grounding for improved navigation robustness.
The authors evaluate UI-Venus-1.5 across multiple grounding benchmarks and find it consistently outperforms both general-purpose VLMs and prior GUI-specific models, particularly in fine-grained professional UI tasks like ScreenSpot-Pro and complex reasoning benchmarks like OSWorld-G. Results show clear performance gains with increasing model scale, and the 30B-A3B variant achieves state-of-the-art or near-state-of-the-art scores across most categories, demonstrating strong generalization across diverse UI domains and input types. The model’s architecture and training pipeline, including Mid-Training and reinforcement learning stages, contribute to its superior discriminative power and robust cross-platform adaptability.
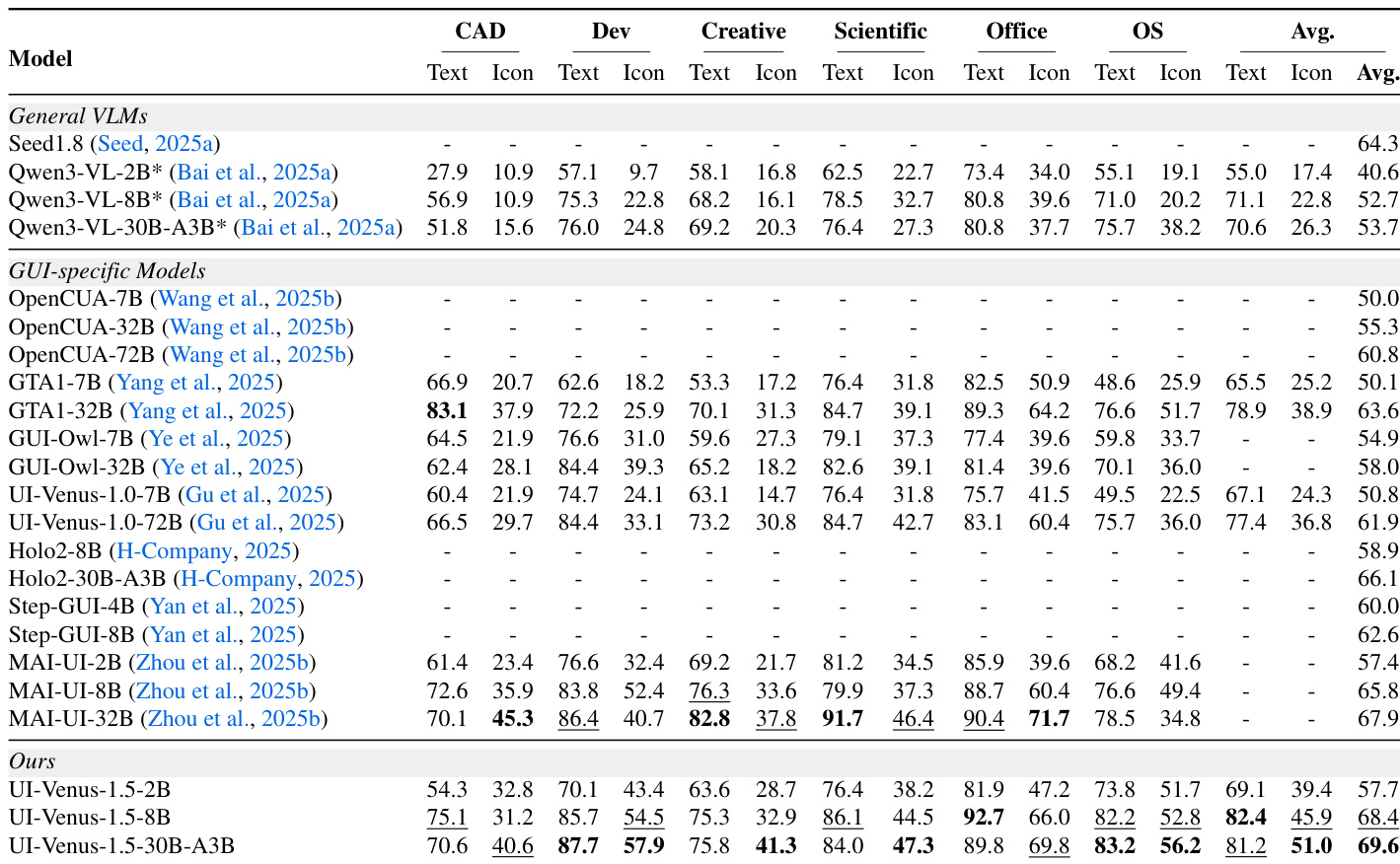
The authors evaluate UI-Venus-1.5 across multiple operating systems and task types, showing consistent improvements over both general VLMs and GUI-specific models. Results indicate strong cross-platform generalization, with the 30B-A3B variant achieving top or near-top performance in most categories, particularly excelling in advanced Android and iOS tasks. Model scaling correlates with steady gains, reinforcing the effectiveness of their training pipeline in enhancing GUI understanding across diverse environments.
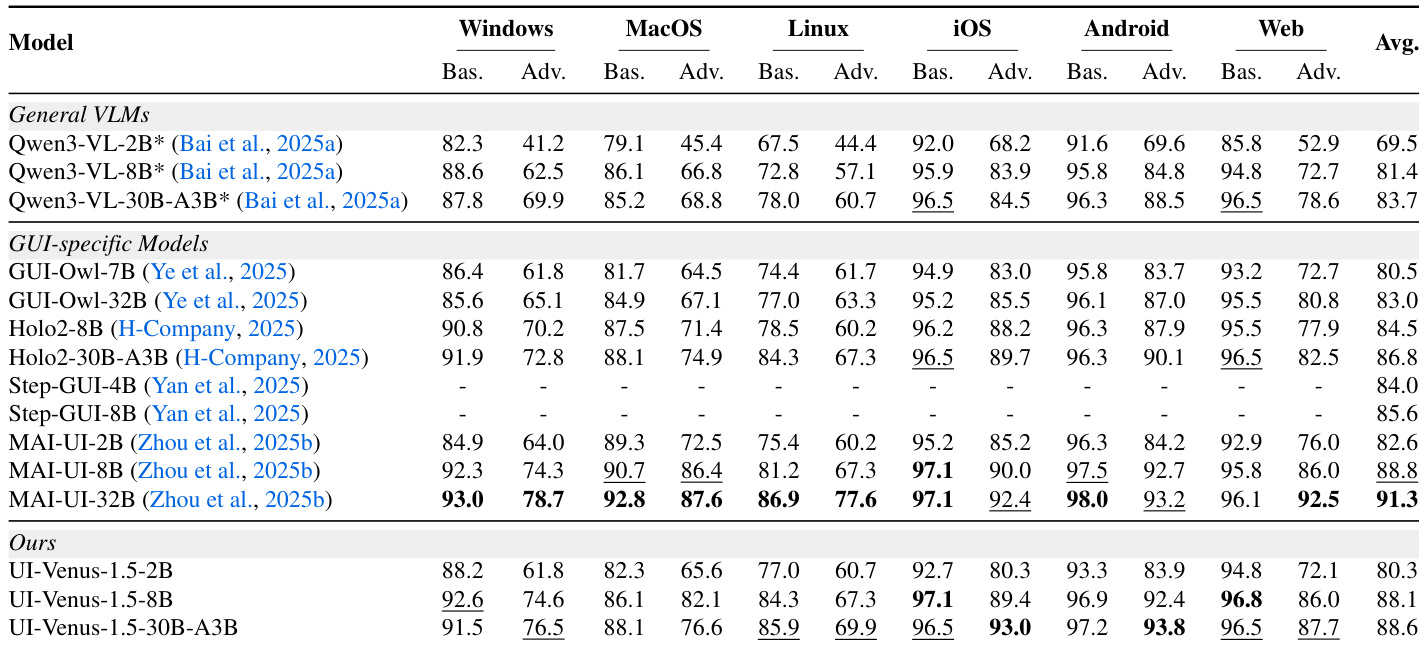
The authors evaluate UI-Venus-1.5 across multiple navigation benchmarks and find that it consistently outperforms both general-purpose VLMs and GUI-specific models, achieving state-of-the-art results on AndroidWorld, VenusBench-Mobile, and WebVoyager. Results show clear scaling benefits, with larger variants delivering higher success rates, and the 8B model already surpassing prior 72B baselines. The model also demonstrates strong visual-only reasoning, excelling in dynamic environments without relying on auxiliary inputs like XML.
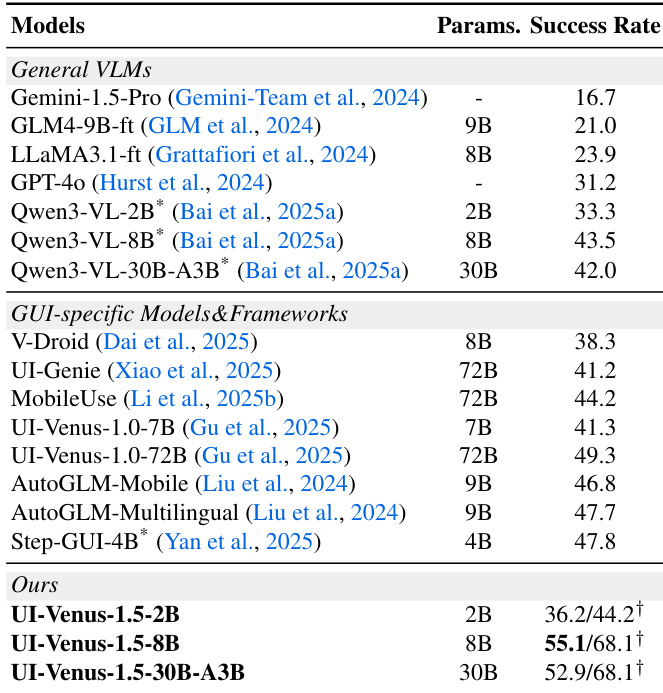
The authors evaluate UI-Venus-1.5 across multiple grounding and navigation benchmarks, showing consistent performance gains with increased model scale. Results indicate that UI-Venus-1.5-30B-A3B achieves state-of-the-art or near-state-of-the-art performance on most tasks, outperforming both general-purpose VLMs and specialized GUI models. The model demonstrates strong generalization across diverse interfaces, including mobile, desktop, and web environments, while relying solely on visual input without auxiliary structural data.
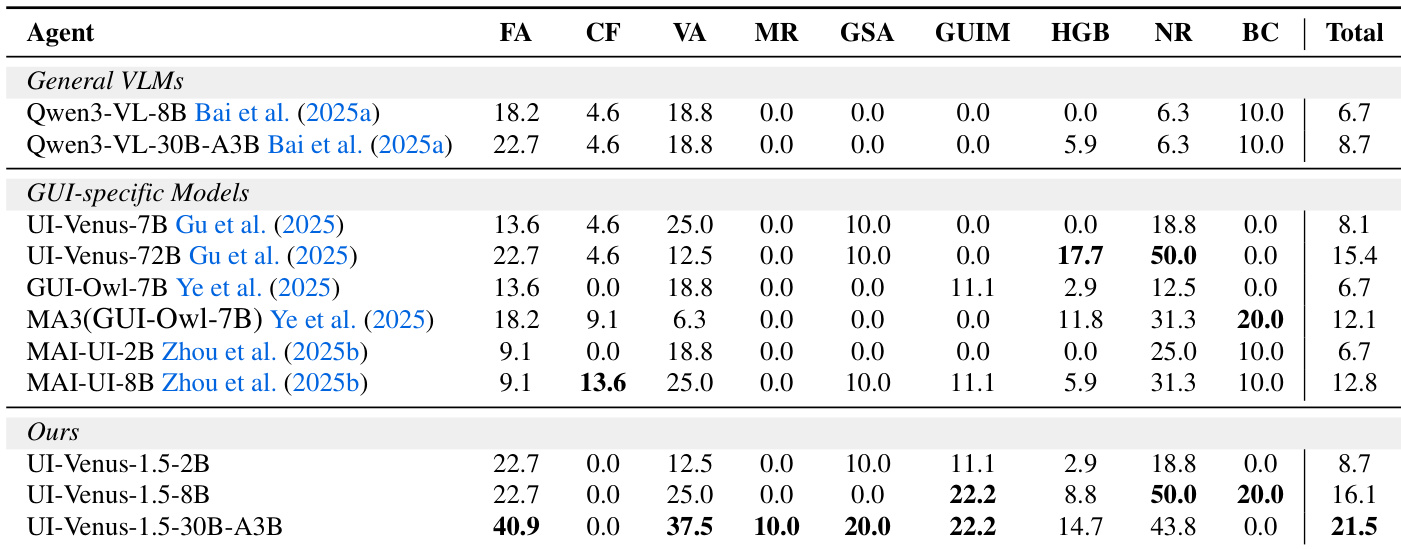
The authors evaluate UI-Venus-1.5 across multiple grounding benchmarks and find it consistently outperforms both general-purpose VLMs and prior GUI-specific models, particularly in fine-grained manipulation and refusal handling. Results show clear performance gains with increasing model scale, and the 30B-A3B variant achieves the highest average score, demonstrating strong generalization across diverse UI tasks. The model’s architecture and training pipeline, including Mid-Training and reinforcement learning stages, contribute to its superior discriminative power and task alignment.