Command Palette
Search for a command to run...
AdaExplore: 効率的なカーネル生成のための失敗駆動適応および多様性維持探索
AdaExplore: 効率的なカーネル生成のための失敗駆動適応および多様性維持探索
概要
最近の_large language model (LLM)_ エージェントは、実行フィードバックを活用したテスト時の適応において有望な成果を示している。しかし、堅牢な自己改善の実現はまだ遠く、多くのアプローチは問題インスタンスを独立して扱い、再利用可能な知識を蓄積していない。この限界は、LLMの事前学習データにおいて過小評価されている Triton といったドメイン固有言語において特に顕著である。それらの厳格な制約と非線形な最適化地形は、単純な生成や局所的な精緻化を信頼できないものとしている。本研究では、追加のファインチューニングや外部知識を用いずに、正確性と最適化パフォーマンスを同時に向上させるエージェントフレームワーク「AdaExplore」を提案する。本フレームワークは、失敗駆動型適応と多様性維持型探索という2つの補完的な段階を通じて、パフォーマンスが重要視されるカーネルコード生成における実行フィードバックの蓄積による自己改善を可能にする。適応段階では、エージェントはタスクを合成し、反復して発生する失敗を再利用可能な妥当性ルールとしてのメモリに変換し、以降の生成が実行可能領域内に留まるように支援する。探索段階では、エージェントは候補カーネルを木構造として整理し、小さな局所的な精緻化とより大規模な構造的再生成を交互に行うことで、局所最適解を超えた最適化地形の探索を実現する。
One-sentence Summary
AdaExplore is an agent framework enabling self-improvement via accumulated execution feedback for performance-critical kernel code generation in domain-specific languages such as Triton by leveraging failure-driven adaptation to convert recurring failures into reusable validity rules and diversity-preserving search to explore optimization landscapes beyond local optima, jointly improving correctness and optimization performance without additional fine-tuning or external knowledge.
Key Contributions
- AdaExplore is an agent framework that enables self-improvement for performance-critical kernel code generation through accumulated execution feedback without additional fine-tuning. The framework jointly improves correctness and optimization performance in domain-specific languages like Triton via two complementary stages.
- A failure-driven adaptation stage synthesizes tasks and converts recurring failures into a reusable memory of validity rules to ensure subsequent generations remain within the feasible set. This process distills transferable failure patterns across tasks to accumulate reusable knowledge for future generations.
- A diversity-preserving search stage organizes candidate kernels as a tree to alternate between small local refinements and larger structural regeneration. Experiments demonstrate this strategy explores the optimization landscape beyond local optima, achieving a 72× improvement on Level-3 under a 100-step budget with GPT-5-mini as the base model.
Introduction
Large language model agents are increasingly applied to performance-critical GPU kernel generation, yet domain-specific languages like Triton remain underrepresented in training data. Existing approaches often treat each problem instance independently, which prevents the accumulation of reusable knowledge and makes naive generation unreliable due to strict correctness constraints. To address this, the authors propose AdaExplore, an agent framework that enables self-improvement through failure-driven adaptation and diversity-preserving search. The adaptation stage converts recurring execution errors into a reusable memory of validity rules to ensure feasibility. Meanwhile, the search stage organizes candidate kernels as a tree to balance local refinement with structural regeneration. This combination allows the system to navigate the non-linear optimization landscape effectively without requiring additional fine-tuning or external knowledge.
Dataset
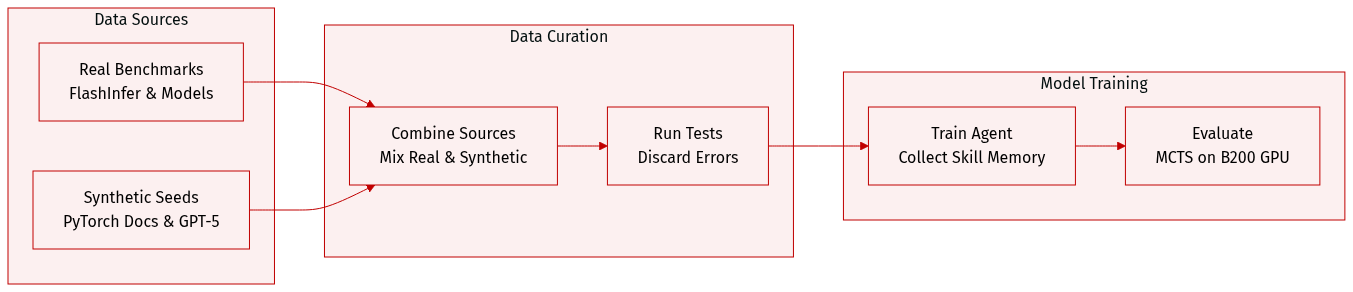
- Dataset Composition and Sources
- The authors utilize a hybrid approach combining real-world benchmarks with synthetic generation. Evaluation tasks are sourced from FlashInfer-Bench, which extracts kernel tasks from production inference pipelines involving deployed models like Llama-3.1-8B and Qwen3-30B-A3B. Training data is created through mutation-based prompting using operators from PyTorch documentation.
- Key Details for Each Subset
- FlashInfer-Bench: Contains three specific kernel definitions including Fused Add RMSNorm, GEMM from the Qwen3 MoE gate, and GQA Paged Decode from Llama-3.1. Performance baselines include expert-written FlashInfer CUDA kernels used in production frameworks such as SGLang.
- Synthetic Training Set: Generated by sampling three seed task examples and operators. GPT-5 produces new PyTorch modules by mutating and recombining existing patterns to maintain complexity similar to seed examples.
- Model Usage and Processing
- The synthetic tasks enable the agent to collect cross-task skill memory from kernel implementation attempts.
- FlashInfer-Bench serves exclusively for evaluation to assess performance on real-world LLM serving workloads.
- Baseline comparisons are drawn against PyTorch eager references and cuBLAS where available.
- Filtering and Configuration
- Generated code is executed on synthesized test tensors, and any samples causing errors are discarded.
- The mutation strategy introduces low-level variation to force the agent into edge cases for better memory storage.
- Evaluation runs follow a specific MCTS configuration with 50 steps on an NVIDIA B200 GPU.
Method
The authors formulate kernel runtime optimization as a program rewriting problem where the goal is to transform a high-level implementation into a low-level kernel that preserves functionality while maximizing performance. To navigate the complex search space involving both correctness and performance constraints, the proposed AdaExplore framework operates through two distinct phases: Adapt and Explore.
Refer to the framework diagram for the overall architecture of the AdaExplore Agent. The system is divided into the Adapt module on the left, which focuses on learning skills from failures, and the Explore module on the right, which performs diversity-preserving search.
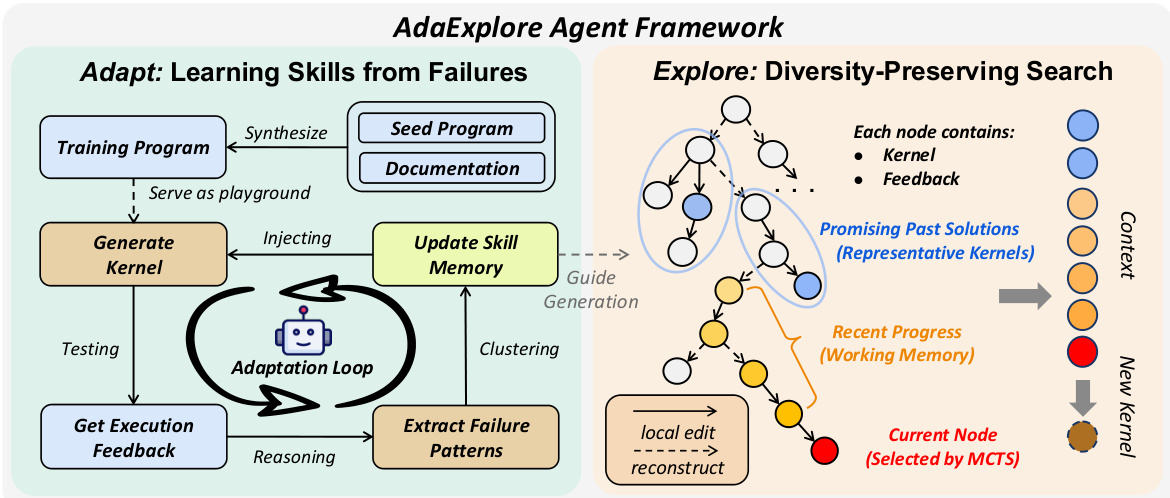
The Adapt component addresses the feasibility bottleneck by learning reusable constraints. Empirically, kernel generation failures often stem from a small set of recurring grammar errors or structural constraints. Rather than relying on additional model training, the authors adapt the agent's knowledge through self-exploration on synthesized tasks. The pipeline generates diverse training tasks by recombining operators from reference implementations. The agent attempts to generate kernels for these tasks, and execution failures are collected. These failures are summarized into concise constraint rules, which are then clustered and filtered based on frequency to build a compact cross-task skill memory, retaining only rules with frequency above a threshold O. This memory is exposed to subsequent tasks, allowing the method to transfer experience and avoid previously observed failure modes.
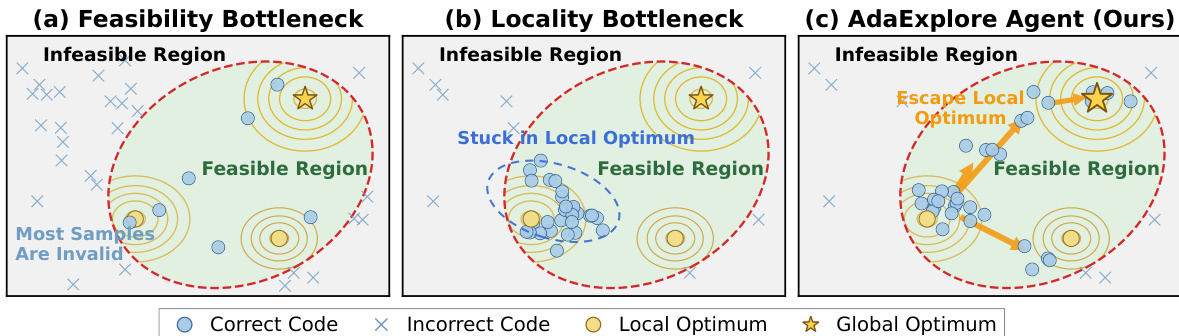
As shown in the figure below, the AdaExplore Agent is designed to overcome both feasibility and locality bottlenecks. While standard approaches may struggle with a high rate of invalid samples or get stuck in local optima within the feasible region, the AdaExplore Agent leverages the learned skills to maintain validity and uses the search strategy to escape local optima towards the global optimum.
The Explore component facilitates the search for high-performing kernels by maintaining a tree of candidates rather than a single refinement chain. This structure allows the preservation of multiple promising directions simultaneously. At each step, the agent selects a node to expand using a UCT-style rule that balances exploration and exploitation. The expansion involves one of two update operators.
The Small Step operator performs localized patch-based refinement. It preserves the overall kernel structure while correcting errors or tuning local choices. The agent is prompted to identify concrete modifications and output code patches in an old_str/new_str format. Refer to the Small-Step Tuning Prompt for the specific instructions provided to the model during this phase.

The Large Step operator regenerates the kernel at a structural level to encourage alternative strategies and broader exploration. For this action, the working memory is cleared to help the agent break away from the current refinement chain. The model is tasked with generating a kernel that potentially outperforms the best existing kernel in the pool. Refer to the Large-Step Reconstruction Prompt for the objective and constraints given to the agent.

Context management is critical for balancing local refinement with global exploration. When expanding a node, the model conditions on a working memory containing recent edits and feedback, as well as a pool of representative kernels extracted from earlier search stages. For small steps, the model relies on the local working memory to stay grounded in the current branch. For large steps, the representative kernels provide high-performing signals without the bias of the immediate history. This dual-memory design ensures that the search remains diverse while effectively utilizing past progress.
Experiment
The experiments evaluate AdaExplore against representative baselines on kernel optimization benchmarks to assess correctness and runtime efficiency across tasks of varying complexity. Findings indicate that combining tree-structured search with cross-task skill memory enables the model to achieve superior performance by balancing structural exploration with iterative refinement. Ablation studies confirm the necessity of specific components like dual-action updates and memory retention, while case studies demonstrate the system's ability to generate kernels that can surpass expert-written implementations on specific workloads.
The authors evaluate kernel generation on FlashInfer-Bench tasks, comparing performance against PyTorch and expert CUDA baselines. The results indicate that while the agent can surpass expert performance on specific memory-bound workloads like RMSNorm, it struggles to match highly optimized vendor libraries for operations like GEMM. The agent generated an RMSNorm kernel that outperformed the expert CUDA baseline. GEMM kernels underperformed relative to both PyTorch and expert baselines. GQA kernels achieved high speedups over PyTorch but lagged behind expert implementations.

The authors specify the hyperparameter configuration for the ADAPT and EXPLORE phases of their method. The ADAPT phase involves synthesizing a set of tasks to collect experiences, while the EXPLORE phase utilizes a tree search strategy with defined context windows and kernel pools. The expansion coefficient is adjusted based on task difficulty, with a higher value used for easier tasks to promote exploration and a lower value for harder tasks to focus on the current branch. The ADAPT phase collects raw experiences from a synthesized set of training tasks. The EXPLORE phase uses a representative kernel pool and a recent context window to guide the search. The expansion coefficient is set higher for easier tasks and lower for harder tasks to balance exploration and focus.

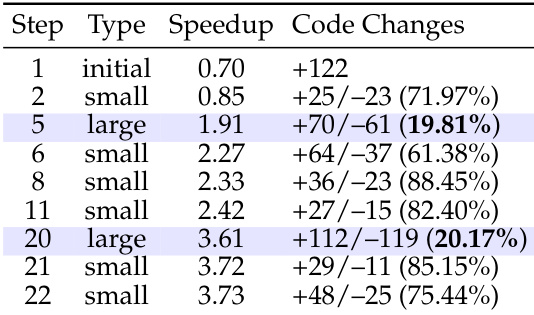
The the the table depicts an optimization trajectory where the agent alternates between localized refinements and major structural updates. Large steps introduce significant code changes with low similarity to previous versions, driving substantial performance jumps. In contrast, small steps preserve high code similarity and facilitate steady, incremental speedup improvements. Large steps correspond to structural overhauls that yield major speedup gains. Small steps involve minor code edits that provide gradual performance refinements. Alternating between these step types allows for both breakthrough optimizations and stable incremental progress.
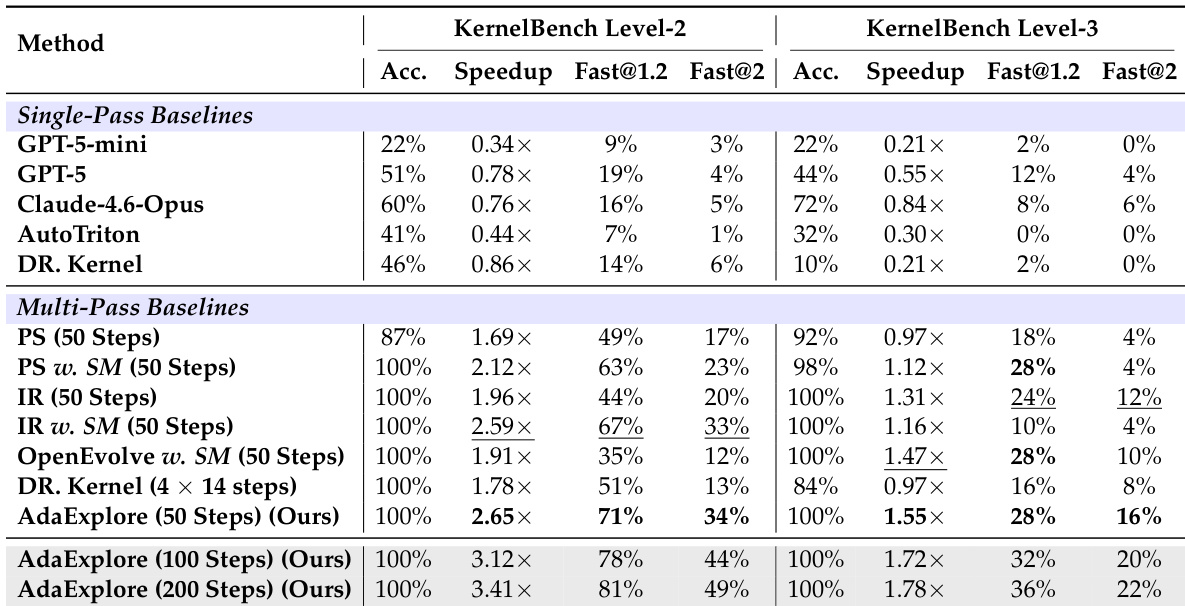
The authors compare their proposed AdaExplore method against various single-pass and multi-pass baselines on KernelBench Level-2 and Level-3 tasks. While multi-pass strategies generally achieve higher accuracy than single-pass models, AdaExplore consistently delivers the highest speedup and the greatest proportion of kernels with significant performance gains. Additionally, the results show that increasing the search budget allows AdaExplore to further improve its optimization performance. AdaExplore achieves the best overall performance in speedup and optimization success rates across both difficulty levels. Multi-pass baselines recover high accuracy but lag behind AdaExplore in maximizing kernel execution speed. Test-time scaling leads to consistent performance gains as the computational budget increases.
The authors assess the generalization of their method across different GPU generations using a fixed cross-task skill memory. The evaluation indicates that the method achieves high correctness and significant speedups on L40S, A100, and GB200 architectures without retraining. Correctness is maintained at near-perfect levels across all tested architectures. Significant speedup is achieved on both older and newer GPU generations. Performance on the Blackwell architecture is comparable to the Ampere generation.

The study evaluates kernel generation on FlashInfer-Bench and KernelBench by comparing the proposed approach against PyTorch, expert CUDA baselines, and various search strategies. While the agent surpasses expert performance on memory-bound workloads like RMSNorm, it generally lags behind optimized vendor libraries for GEMM operations despite delivering the highest speedups over multi-pass baselines. Furthermore, the optimization trajectory alternates between structural overhauls and incremental refinements to maximize gains, and the method maintains high correctness and speedups across diverse GPU generations without retraining.