Command Palette
Search for a command to run...
ARIS: 敵対的多エージェント協働による自律的研究
ARIS: 敵対的多エージェント協働による自律的研究
Ruofeng Yang Yongcan Li Shuai Li
概要
本報告書は、自律的な研究を支援するオープンソースのリサーチハ〖ネスである「ARIS(Auto-Research-in-sleep)」について記述する。本報告書では、そのアーキテクチャ、保証(アシュアランス)機構、および初期導入における経験について詳述する。大規模言語モデル(LLM)を基盤とする agent システムのパフォーマンスは、モデルの重みパラメータのみならず、それらを囲むハ〖ネスの品質にも依存する。ハ〖ネスは、モデルに対してどの情報を保存、取得、提示するかを管理する役割を担う。長期的な研究ワークフローにおいて、主要な障害モードは目に見える機能停止ではなく、「根拠の不確かな成功」である。長時間稼働する agent が、証拠に基づく支持が不完全である、誤って報告されている、あるいは実行フレームワークから無自覚に継承された主張を生み出す可能性がある。この課題に対処するため、本稿では ARIS を提唱する。ARIS は、デフォルト設定として「モデル横断的敵対的協業」を通じて機械学習の研究ワークフローを調整する研究ハ〖ネスである。具体的には、ある agent が進行を主導し、異なるモデルファミリーに属する別の agent が中間成果物に対するレビューを行い、改訂を求める構成を採用している。ARIS は三層のアーキテクチャから構成されている。実行層(Execution Layer): 65種類以上の再利用可能な Markdown 定義のスキル、MCP(Model Context Protocol)経由のモデル統合、過去の知見を反復的に再利用するための永続的な研究 Wiki、および確定的な図生成を提供する。調整層(Orchestration Layer): 調整可能な努力度合い設定と、レビューアモデルへの構成可能なルーティングを備えた、5つのエンドツーエンドのワークフローを調整する。保証層(Assurance Layer): 実験的主張が証拠によって支持されているかを確認するための三段階プロセス(完全性検証、結果から主張へのマッピング、主張の監査)を含み、監査では論文内の記述を主張台帳および生データ証拠とクロスチェックする。さらに、五段階の科学編集パイプライン、数学的証明の検証、レンダリング済み PDF の視覚的検査も備えている。また、プロトタイプとして実装された自己改善ループは、研究のトレース(履歴)を記録し、ハ〖ネスの改善案を提案する。ただし、これらの改善案はレビューアの承認を得て初めて採用される。
One-sentence Summary
Addressing the risk of plausible unsupported success in long-horizon workflows, ARIS is an open-source research harness that coordinates autonomous machine learning research through cross-model adversarial collaboration, pairing an executor model that drives progress with a reviewer from a different model family that critiques intermediate artifacts, while its execution layer supports iterative discovery via a persistent research wiki, model integrations via MCP, deterministic figure generation, and more than 65 Markdown-defined skills.
Key Contributions
- ARIS is an open-source research harness that coordinates autonomous machine learning workflows through a three-layer architecture featuring over 65 reusable Markdown-defined skills, model integrations via MCP, a persistent research wiki, and deterministic figure generation.
- The framework implements a cross-model adversarial collaboration mechanism where an executor model drives progress while a reviewer from a distinct model family critiques intermediate artifacts and requests revisions, effectively breaking self-review blind spots without the coordination overhead of larger multi-agent committees.
- The system incorporates an explicit assurance stack for integrity auditing and cross-platform portability, supporting reproducible end-to-end research workflows that span idea generation, experimentation, and manuscript preparation across multiple host environments.
Introduction
Automating the end-to-end machine learning research pipeline holds significant promise for accelerating scientific discovery, yet long-horizon autonomous tasks remain highly susceptible to hallucinations, correlated errors, and misreported results. Prior autonomous research agents typically rely on same-model self-refinement and tightly coupled workflows, which fail to catch shared inductive biases, lack modular resumption capabilities, and offer minimal system-level verification of experimental integrity. To address these gaps, the authors propose ARIS, a framework that treats single-agent execution as inherently unreliable and decomposes the research process into modular, state-preserving stages. The authors leverage an adversarial cross-family executor-reviewer pairing with explicit assurance checks at critical milestones, ensuring that each research artifact is independently validated by a distinct model family before advancing to the next workflow phase.
Dataset

- Dataset composition and sources: The authors compile a skill inventory that catalogs core framework skills from a current release, as outlined in Table 5.
- Subset details: The provided excerpt does not define distinct subsets, so specific sizes, origins, or filtering criteria are not documented.
- Usage and training configuration: The authors reference the inventory to establish a baseline skill framework. The text does not outline training splits, mixture ratios, or data blending strategies.
- Processing and metadata: No cropping methods, metadata generation steps, or additional preprocessing pipelines are described in the available content.
Method
The ARIS framework is structured around three primary architectural layers—execution, orchestration, and assurance—that collectively address the challenges of long-horizon, autonomous machine learning research. The execution layer provides a modular foundation through more than 65 reusable skills, each defined as a plain-text Markdown file (SKILL.md) that specifies inputs, outputs, procedural steps, and quality gates. These skills are coordinated via versionable artifact contracts, enabling checkpoint-based recovery and auditability. The orchestration layer manages five end-to-end workflows—idea discovery, experiment bridge, auto-review loop, paper writing, and rebuttal—chained through these contracts and grouped into four research phases: Discovery, Experimentation, Manuscript, and Post-Submission. This layer supports adjustable effort settings and configurable routing to reviewer models, allowing users to scale depth and breadth while maintaining core review invariants. The assurance layer implements a multi-stage process to detect and mitigate plausible unsupported success, including evidence integrity verification, result-to-claim mapping, and claim auditing against raw evidence and a claim ledger. It also includes a five-pass scientific-editing pipeline, mathematical-proof checks, and visual inspection of rendered PDFs. A prototype meta-optimization loop records research traces and proposes harness improvements that are only adopted after reviewer approval, enabling iterative refinement of the system itself. The overall architecture is designed to enforce independent assurance by default, leveraging cross-model adversarial collaboration between an executor and a reviewer drawn from different model families, thereby reducing shared inductive biases and enhancing critical evaluation.



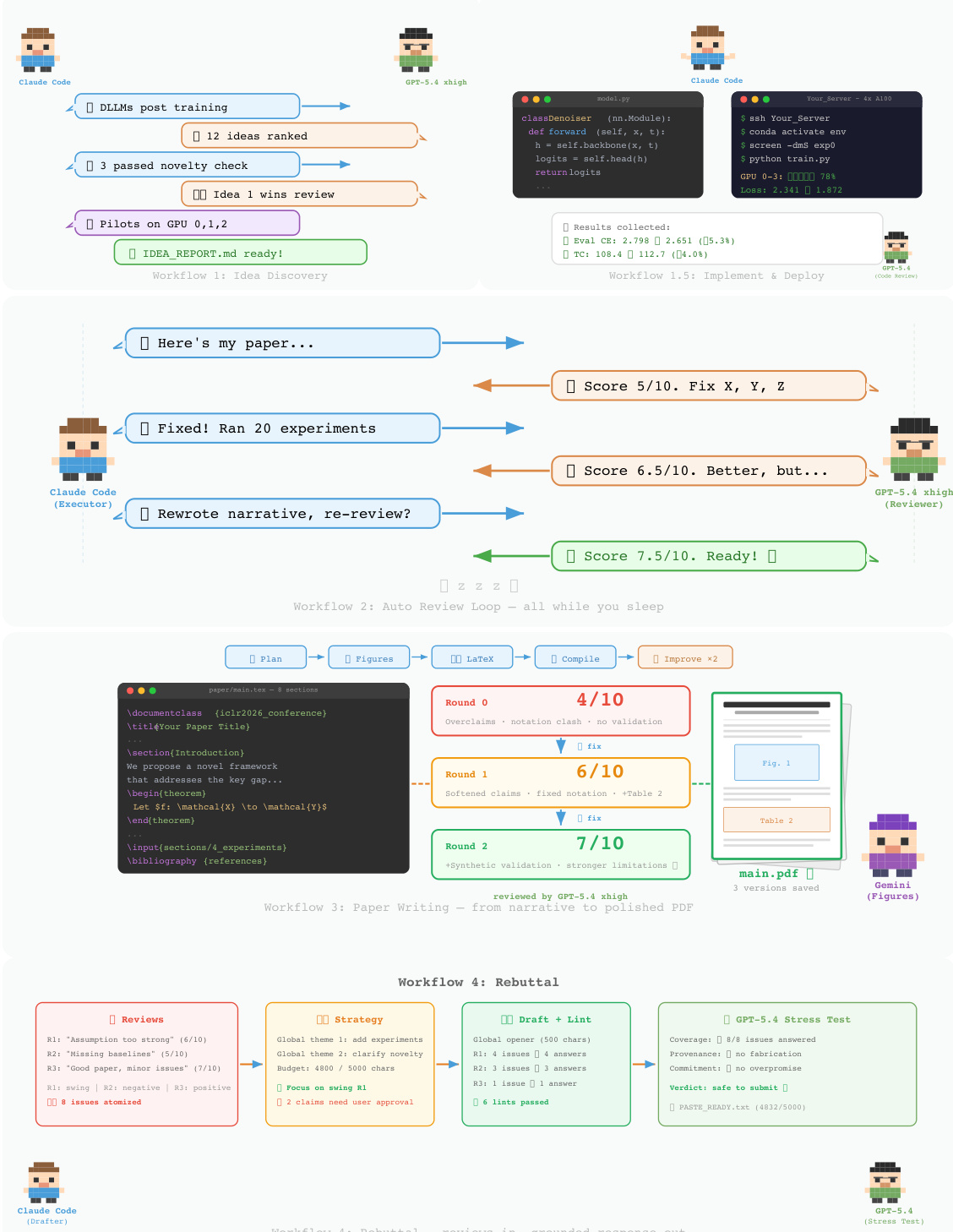
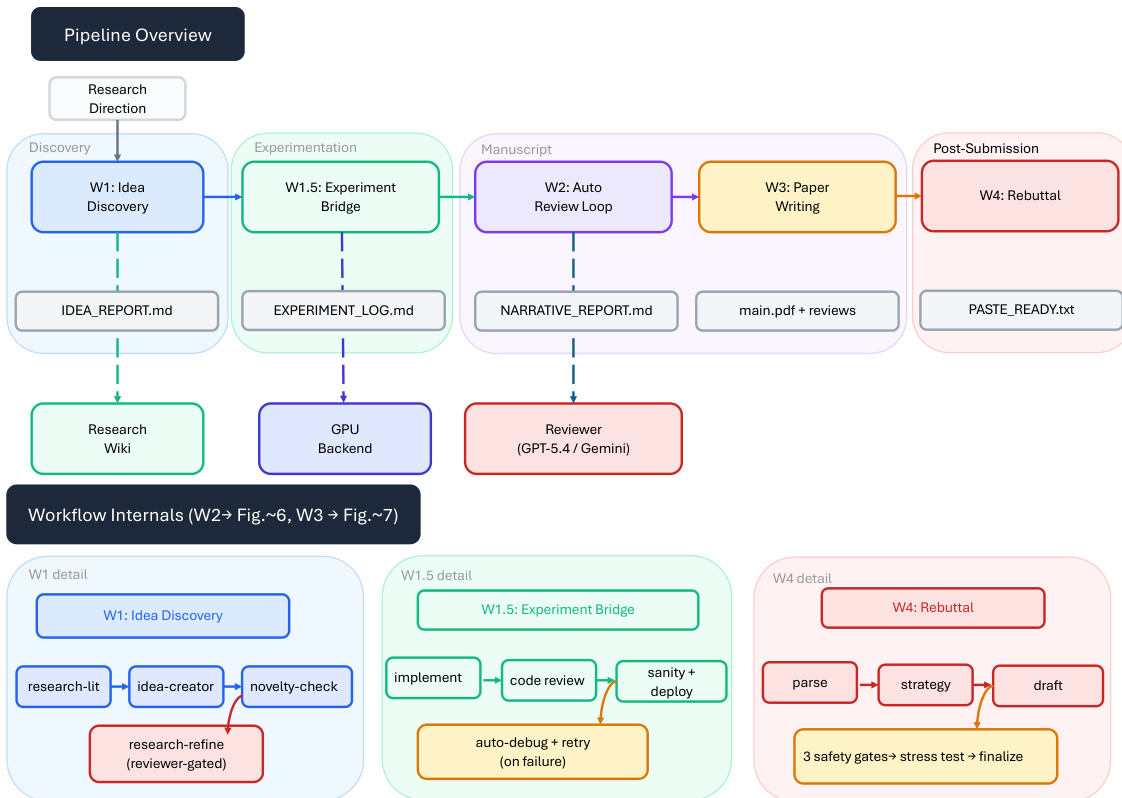
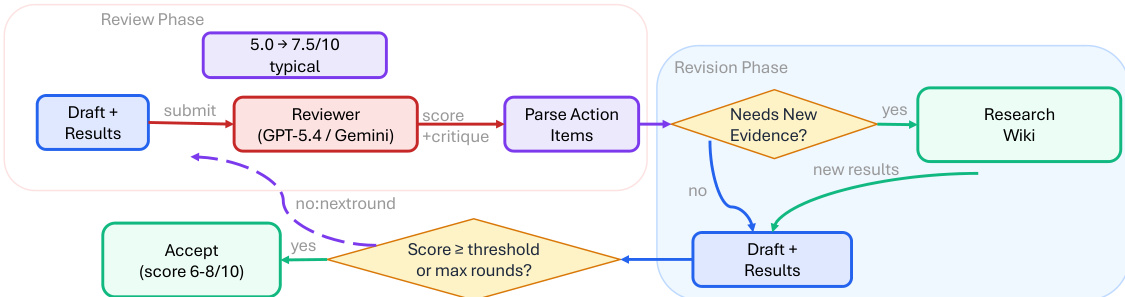
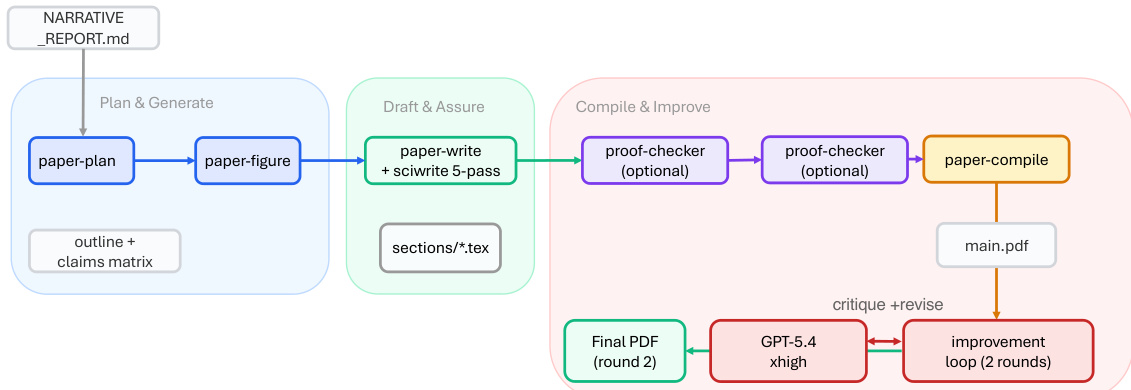
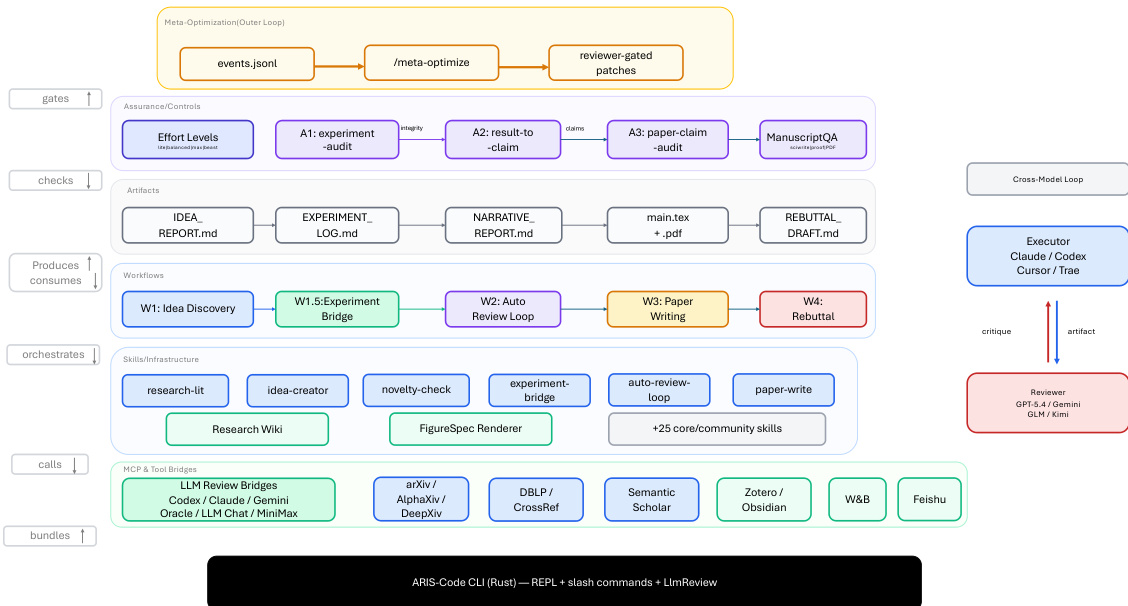
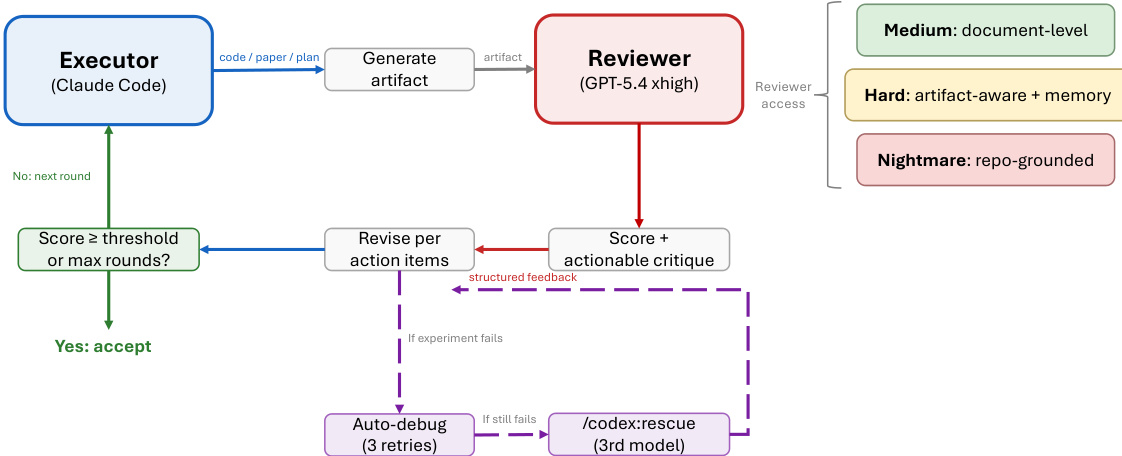
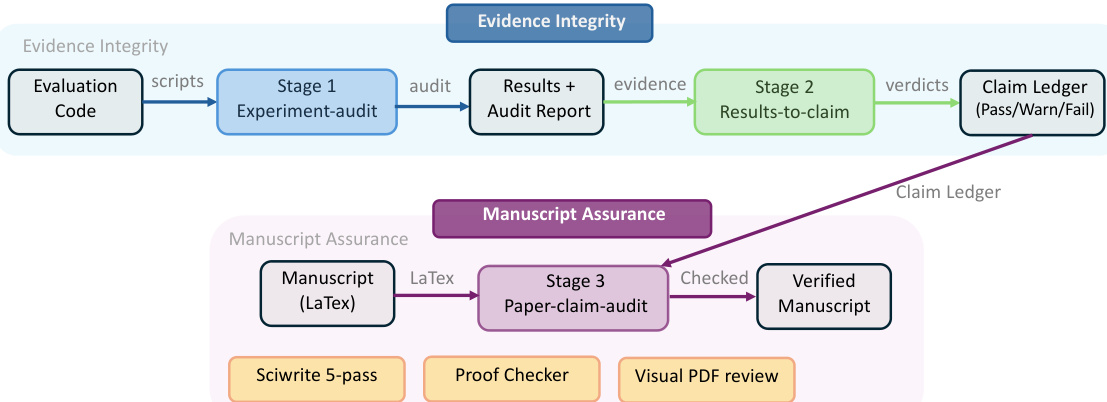
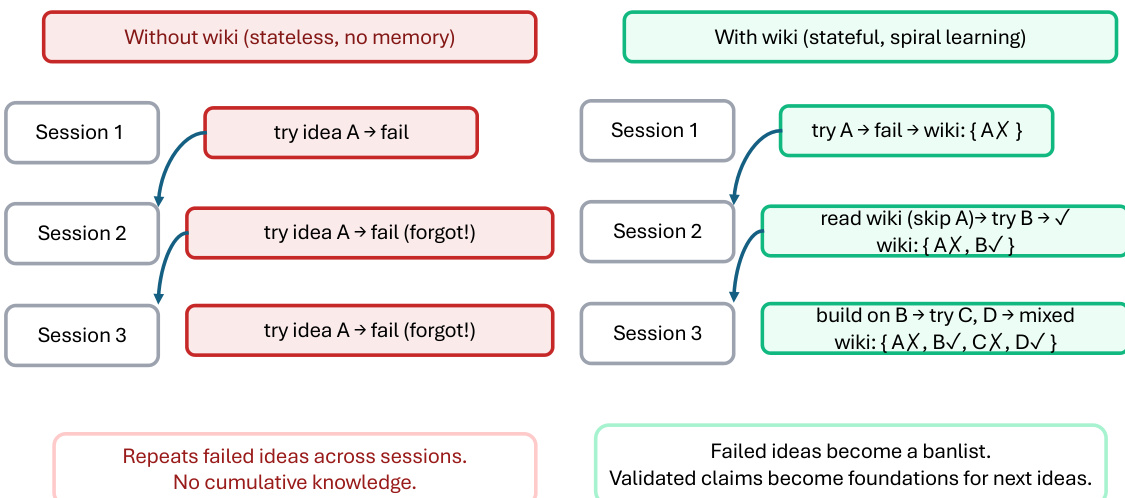

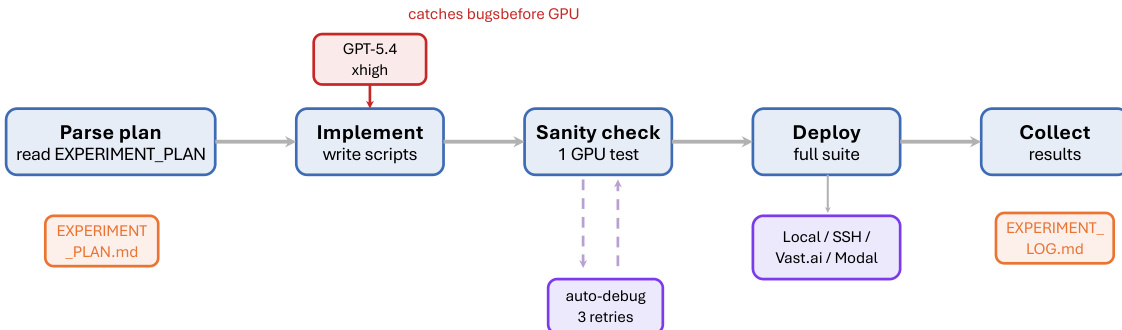
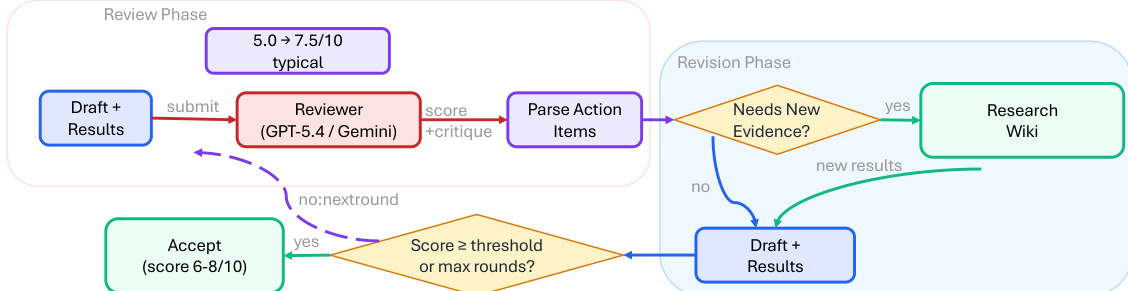
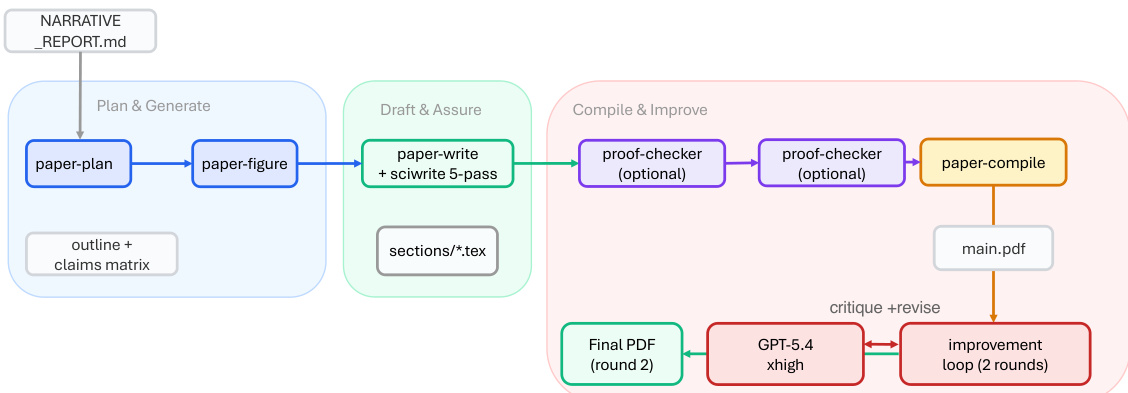

Experiment
The evaluation relies on observational deployment tracking and a single overnight operational run to assess ARIS under realistic conditions. These experiments validate the system's practical capability to autonomously prune unsupported claims and iteratively refine manuscripts through automated review cycles, alongside demonstrating substantial ecosystem expansion across multiple technical domains. Because the reported outcomes remain observational, they confirm operational feasibility rather than establishing causal advantages for specific reviewer architectures or model configurations. A future controlled benchmark protocol will be required to isolate the impact of algorithmic design from external variables like researcher expertise and task difficulty.
The authors present a comparison of different systems, including their own, across several capabilities such as cross-family review, adversarial review, composability, E2E research workflows, assurance stack, and cross-platform portability. The system developed by the authors, ARIS, demonstrates a comprehensive set of features, particularly in composability and E2E research workflows, and supports cross-platform portability. ARIS supports cross-platform portability and E2E research workflows, which are not supported by other systems. ARIS includes composable skills and an assurance stack, features absent in most compared systems. ARIS implements a default cross-family policy, whereas other systems either lack this capability or use partial or none policies.
The evaluation compares ARIS against existing systems across multiple capability dimensions, validating its performance in cross-family and adversarial reviews, composability, end-to-end research workflows, assurance stacks, and cross-platform portability. ARIS demonstrates superior integration by uniquely supporting full end-to-end workflows and cross-platform deployment while introducing composable skills and a dedicated assurance stack absent in competing tools. Additionally, it establishes a comprehensive default cross-family policy that addresses the partial or missing coverage found in alternative approaches.