Command Palette
Search for a command to run...
ClawGym:効果的なClawエージェントを構築するためのスケーラブルなフレームワーク
ClawGym:効果的なClawエージェントを構築するためのスケーラブルなフレームワーク
概要
Clawスタイルの環境は、ローカルファイル、ツール、および永続的なワークスペース状態にわたるマルチステップワークフローをサポートします。しかし、これらの環境をスケーラブルに開発するには、検証可能なトレーニングデータの合成や、それをエージェントのトレーニングや診断的評価と統合するための体系的なフレームワークが欠如しているという制約があります。この課題に対処するため、Clawスタイルのパーソナルエージェントの開発ライフサイクル全体をサポートするスケーラブルなフレームワーク「ClawGym」を提案します。具体的には、ペルソナ駆動の意図とスキル基盤の操作から合成された13.5K件のフィルタリング済みタスクで構成される多様なデータセット「ClawGym-SynData」を構築します。これには、現実的なモックワークスペースとハイブリッド検証機構が組み合わされています。さらに、ブラックボックスでのロールアウト軌跡による教師ありファインチューニングを通じて、能力の高いClawスタイルモデル「ClawGym-Agents」のファミリーを訓練します。また、タスクごとのサンドボックス間でロールアウトを並列化する軽量パイプラインによる強化学習も検討します。信頼性の高い評価をサポートするため、自動フィルタリングと人間・LLMのレビューを通じてキャリブレーションされた200件のインスタンスからなるベンチマーク「ClawGym-Bench」も構築します。関連するリソースは、https://github.com/ClawGym で近日公開されます。
One-sentence Summary
ClawGym is a scalable framework for Claw-style personal agents that integrates ClawGym-SynData, a 13.5K task dataset synthesized from persona-driven intents and skill-grounded operations, with supervised fine-tuning and lightweight reinforcement learning to train ClawGym-Agents, alongside ClawGym-Bench, a 200-instance benchmark calibrated through automated filtering and human-LLM review.
Key Contributions
- ClawGym-SynData provides a dataset of 13.5K executable tasks synthesized through an automated pipeline that combines persona-driven intents with skill-grounded operations and hybrid verification mechanisms. This dataset enables scalable training for personal agents operating in local file and tool environments.
- ClawGym-Agents trains a family of models via supervised fine-tuning on high-fidelity interaction trajectories collected through black-box rollouts, supplemented by a lightweight reinforcement learning pipeline that parallelizes execution across per-task sandboxes. This methodology delivers consistent performance gains across varying model scales.
- ClawGym-Bench establishes a diagnostic benchmark of 200 curated instances filtered through automated difficulty calibration and human-LLM review to ensure evaluation reliability. Empirical results demonstrate that agents trained on this framework achieve substantial improvements, including a 43.46% gain for Qwen3-8B on the benchmark and a 38.90% increase on PinchBench.
Introduction
Claw-style environments empower autonomous agents to execute multi-step workflows across local files, tools, and persistent workspaces, effectively bridging the gap between generative AI and practical digital execution. Despite this potential, the ecosystem lacks systematic frameworks for scalable agent development, as prior efforts struggle to synthesize verifiable training data that captures personalized intents, handles long-horizon dependencies, and grounds tasks in realistic workspace states. The authors leverage a dual-route synthesis strategy to overcome these barriers by introducing ClawGym, a unified framework that streamlines the entire lifecycle of Claw-style agent development. Their approach delivers ClawGym-SynData with 13.5K curated tasks, trains a family of capable agents via supervised fine-tuning and reinforcement learning, and establishes ClawGym-Bench to provide reliable diagnostic evaluation.
Dataset
-
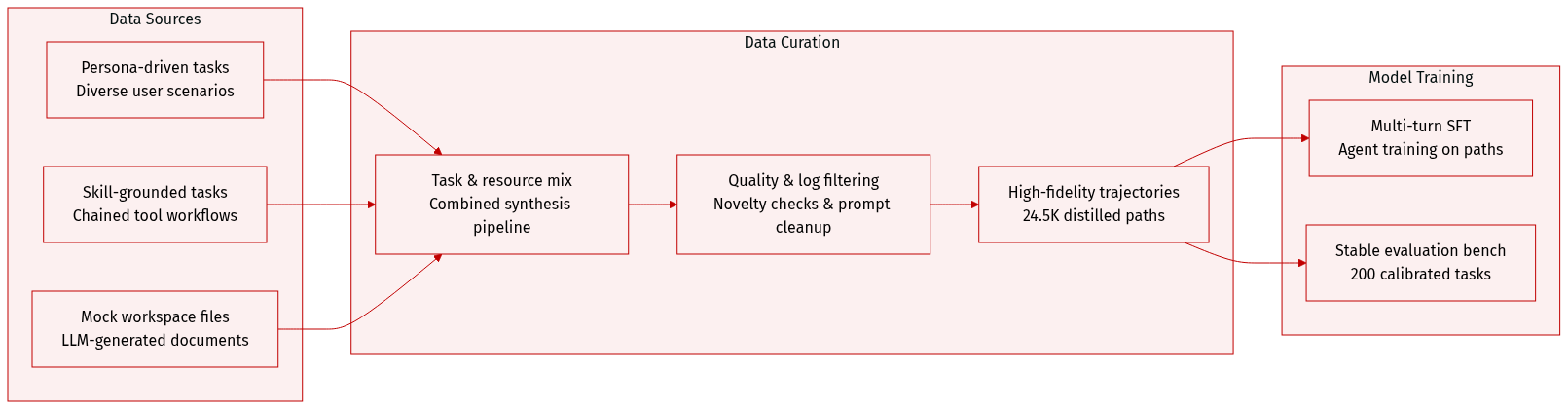
Dataset Composition and Sources
- The authors generate training data through the ClawGym-SynData framework, which combines persona-driven top-down synthesis for diverse user scenarios with skill-grounded bottom-up synthesis that chains OpenClaw capabilities into realistic workflows.
- To establish reproducible workspace states, the pipeline uses an LLM to generate lightweight, task-specific mock resources, including documents, tables, and structured files with explicit schemas, completely avoiding privacy risks from real user data.
-
Key Details for Each Subset
- Training Corpus (ClawGym-Agents): Contains 24.5K high-fidelity trajectories distilled from MiniMax-M2.5 and GLM-5.1 teacher models. The dataset maintains a mixed distribution of both models and averages roughly 13 interaction rounds, 18.7K tokens, and 15.8 tool calls per trajectory.
- Evaluation Benchmark (ClawGym-Bench): Comprises 200 carefully curated tasks split into 156 code-verified and 44 hybrid-verified instances. It spans six operational categories, including file manipulation, data analysis, and script execution, with strict difficulty calibration to ensure discriminative power.
-
Data Processing and Filtering
- The authors apply a multi-stage quality assessment that filters tasks based on novelty thresholds, LLM-based plausibility checks, and complexity balancing.
- Raw interaction logs are reconstructed by grouping requests with matching message prefixes and concatenating turns. The pipeline automatically crops out non-essential system prompts like heartbeat messages and removes trajectories that trigger unsupported tools to prevent training noise.
- Final trajectory selection relies on a continuous reward-threshold filter applied to hybrid verifier scores, retaining only samples that demonstrate high task completion quality.
-
Usage and Training Strategy
- The filtered 24.5K trajectory dataset is used for multi-turn supervised fine-tuning, enabling agents to learn authentic tool-use patterns and workspace navigation.
- The 200-task benchmark serves as a stable evaluation suite where each task is initialized with its mock resources and scored via a unified verification formula, ensuring reliable model comparison without excessive repeated runs.
Method
The ClawGym framework is designed to support the development and evaluation of environment-grounded instruction-execution agents, with a focus on synthesizing high-quality training data and training robust agent models. The core methodology consists of a multi-stage data synthesis pipeline that generates diverse, realistic tasks, followed by supervised fine-tuning and reinforcement learning to train agent models. The overall architecture begins with task generation, proceeds through verification design and quality assessment, and culminates in a curated dataset and benchmark for agent evaluation.
The data synthesis pipeline is structured into four distinct stages. In Stage 1, task generation, two complementary approaches are employed: a persona-driven top-down synthesis and a skill-grounded bottom-up synthesis. The top-down method starts with high-level user contexts, combining a personalized user persona, a scenario category, and a set of atomic operations to create a task seed. This seed is then used to condition a large language model to generate a concrete user-facing instruction, ensuring the task is grounded in realistic user needs and operational constraints. The bottom-up method, in contrast, starts with existing capabilities, or skills, from an open-source repository. These skills are annotated and filtered to identify those suitable for synthesis, then composed into tasks by selecting a primary skill and optional supporting skills. This approach ensures that generated tasks are grounded in executable operations and encourages multi-step coordination across capabilities. The outputs from both synthesis strategies are combined in Stage 2, Resource Preparation, where task-specific resources such as input files and configuration data are generated.
In Stage 3, Verification Design, a hybrid verification scheme is implemented to assess task completion. This involves generating both code-based and rubric-based verification components. Code-based verification decomposes the task into a set of deterministic atomic checks, such as verifying the existence of output files or the correctness of data transformations, which are executed as executable scripts. Rubric-based verification, on the other hand, evaluates qualitative aspects like clarity, completeness, and faithfulness using a set of predefined criteria scored by a large language model. The final task score is a weighted combination of these two scores, with a default weight of 0.7 for the code-based component, prioritizing objective, reproducible outcomes. This verification process is critical for generating reliable training signals for agent models.
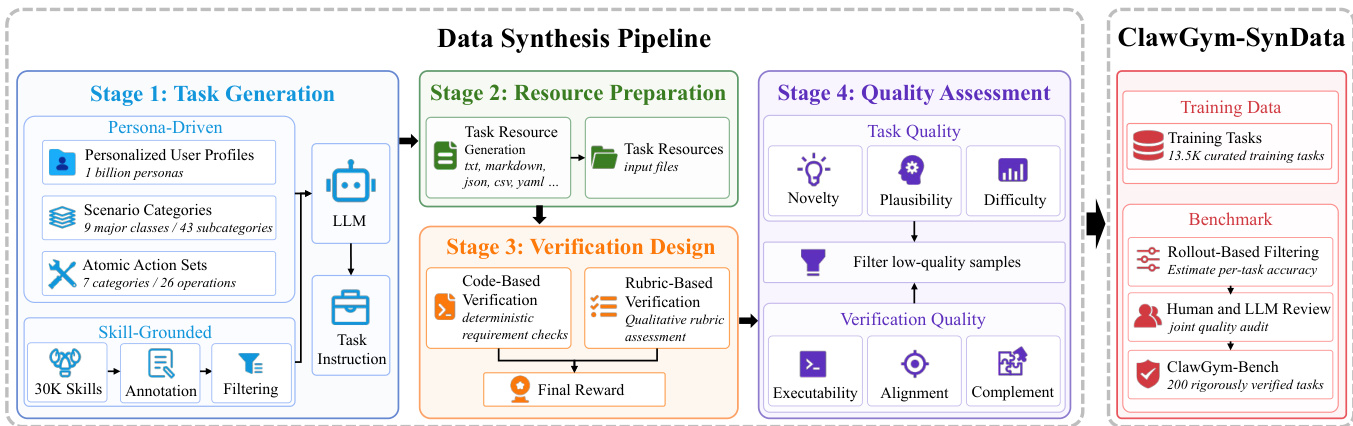
Stage 4, Quality Assessment, applies automated filters to the synthesized data to ensure high quality. This stage evaluates both the task's plausibility and the reliability of its verification artifacts. Tasks are assessed for novelty, plausibility, and difficulty, while verification components are checked for executability, alignment with the task, and complementarity. This process filters out ambiguous or poorly specified tasks and misaligned verifiers, ensuring that the final training data consists of high-quality, reliable examples.

The resulting dataset, ClawGym-SynData, contains 13.5K curated training tasks and is used to train a family of agents. Training is performed via supervised fine-tuning on the Qwen3-series models, including Qwen3-4B, Qwen3-8B, and Qwen3-30B. To handle the long-horizon nature of agent interactions, the context length is extended using YaRN, and a multi-turn loss masking strategy is employed to focus the optimization on the model's reasoning and action generation, excluding deterministic environment feedback. Additionally, a reinforcement learning pipeline is explored using a lightweight sandbox-parallel rollout system, where each task runs in an isolated environment, and the reward is provided directly by the code-based verifier. This approach enables concurrent training and avoids the need for auxiliary reward models.

Experiment
The evaluation assesses proprietary and open-weight models on the ClawGym-Bench and PinchBench benchmarks using a hybrid verification protocol that pairs executable code checks with qualitative LLM-based rubrics. Experiments validate that training on synthesized interaction data significantly enhances compact models, narrows their gap with larger systems, and transfers effectively to external benchmarks without overfitting. Qualitative behavioral analyses further demonstrate that reliable agents excel through coherent tool orchestration, resilient error recovery during long-horizon execution, and strict adherence to fine-grained constraints across generated artifacts. Overall, the study confirms that the synthesized data pipeline and benchmark framework successfully cultivate and measure robust, transferable agentic capabilities for complex computer-use tasks.
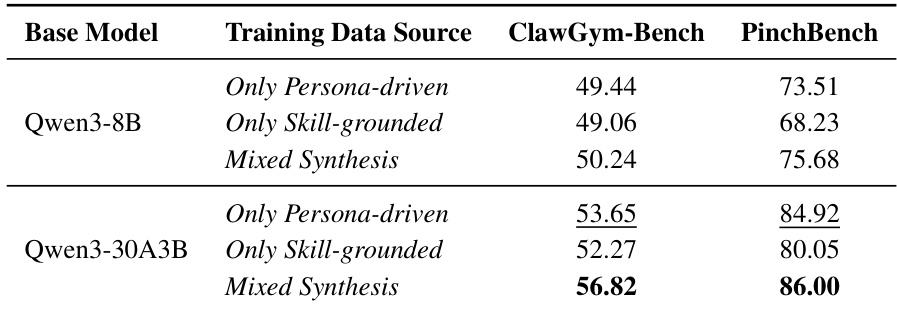
The authors evaluate the impact of different training data sources on model performance using two benchmarks, ClawGym-Bench and PinchBench. Results show that models trained with mixed synthesis data achieve higher scores compared to those trained with persona-driven or skill-grounded data, with the improvement being more pronounced on PinchBench. Models trained with mixed synthesis data outperform those trained with persona-driven or skill-grounded data on both benchmarks. The performance gain from mixed synthesis is more significant on PinchBench than on ClawGym-Bench. Qwen3-30A3B shows the highest scores across all training data sources on both benchmarks.
The authors compare the performance of two models on a benchmark, showing that one model achieves a higher mean score than the other. The results indicate a clear difference in average performance between the two models, with the second model demonstrating greater consistency in its outcomes. One model achieves a higher mean score than the other on the benchmark. The second model shows greater consistency in its performance across runs. The results highlight a performance gap between the two models in the evaluated task.
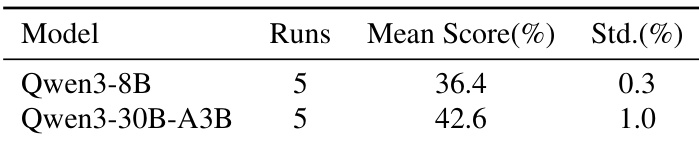
{"summary": "The the the table presents aggregate metrics from agent trajectories, showing the average number of rounds, tokens, tool calls, and tool types used across tasks. These metrics reflect the complexity and interaction patterns of agent behavior in the evaluated environment.", "highlights": ["Agents typically require around 13 rounds to complete tasks on average.", "The average trajectory involves approximately 18,670 tokens and 15.82 tool calls.", "Agents use an average of 3.25 distinct tool types per task."]

The the the table presents a distribution of annotated skills across various categories, highlighting the proportion of each category in terms of count and percentage. The data shows that the majority of skills fall under the Data & APIs category, followed by Dev Tools and Workflows, with smaller proportions in other categories such as MCP Tools and Security. The Data & APIs category represents the largest portion of the annotated skills, followed by Dev Tools and Workflows. MCP Tools and Security constitute smaller proportions of the overall skill distribution. The distribution emphasizes the diversity of skills across different functional areas, with significant emphasis on data and development tools.

The authors evaluate the quality of verification artifacts in their framework by assessing metrics such as task reasonableness, execution feasibility, resource consistency, and verification quality. The results show that the overall verification quality is moderately high, with task reasonableness and resource consistency scoring above average, while execution feasibility is lower, indicating potential challenges in ensuring robust and feasible execution workflows. Task reasonableness and resource consistency are the highest-rated metrics, indicating strong alignment with task requirements and consistent resource handling. Execution feasibility scores lower than other metrics, suggesting that ensuring robust and reliable execution workflows remains a challenge. Verification quality is moderate, reflecting a balance between objective and qualitative assessment but with room for improvement in aligning verification with task correctness.
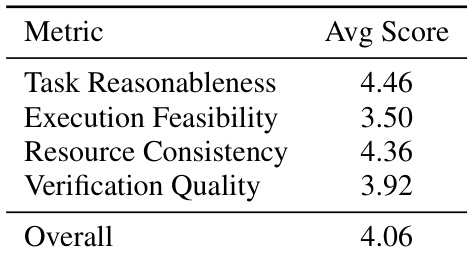
The evaluation setup assesses model performance across different training data configurations and benchmark tasks, validating that mixed synthesis data consistently outperforms specialized alternatives. Complementary experiments analyze agent interaction complexity, skill distribution across functional domains, and the reliability of verification artifacts. Overall findings demonstrate clear performance advantages with mixed training approaches, highlight the diversity of operational skills, and identify execution feasibility as a primary area for improving verification quality.