Command Palette
Search for a command to run...
潜在蒸留による大規模言語モデルの探索
潜在蒸留による大規模言語モデルの探索
Yuanhao Zeng Ao Lu Lufei Li Zheng Zhang Yexin Li Kan Ren
概要
大規模言語モデル(LLM)のテスト時スケーリングにおいて多様な応答を生成することは重要だが、標準的な確率的サンプリングは主に表層的な語彙変異しか生み出さず、意味的な探索を制限してしまう。本論文では、生成過程において意味的多様性を明示的に促進するデコーディング手法であるExploratory Sampling(ESamp)を提案する。ESampは、ニューラルネットワークが以前遭遇した入力と類似した入力に対しては低誤差の予測を行い、新規な入力に対しては予測誤差が大きくなるというよく知られた性質に着目している。この特性に基づき、LLMの浅い層の表現から深い層の隠れ表現を予測する軽量なディストラー(Distiller)をテスト時に訓練し、LLMの層方向の表現遷移をモデル化する。デコーディング中、ディストラーは現在の生成文脈が誘導するマッピングに継続的に適応する。ESampは、予測誤差を新規性信号として利用し、現在のプレフィックス条件のもとで候補のtoken延長に対する重み付けを行い、デコーディングをより探索されていない意味的パターンへバイアスする。ESampは非同期の訓練・推論パイプラインで実装されており、最悪ケースでも5%未満のオーバーヘッド(最適化版リリースでは1.2%)である。経験的な結果は、ESampが推論モデルのPass@k効率を大幅に向上させ、強力な確率的およびヒューリスティックなベースラインと同等またはそれ以上のパフォーマンスを示すことを示している。特筆すべきは、ESampが数学、科学、コード生成のベンチマーク間で堅牢な汎化を実現し、創造的なライティングにおける多様性と一貫性の間のトレードオフを打ち破ったことである。コードは https://github.com/LinesHogan/tLLM で公開されている。
One-sentence Summary
The authors propose Exploratory Sampling (ESamp), a test-time decoding approach that enhances semantic diversity by training a lightweight Distiller to predict deep-layer representations from shallow ones and using the resulting prediction error as a novelty signal to reweight candidate tokens, thereby boosting Pass@k efficiency for reasoning models across mathematics, science, and code benchmarks while breaking the diversity-coherence trade-off in creative writing.
Key Contributions
- The paper introduces Exploratory Sampling (ESamp), a decoding framework that employs a lightweight Distiller to predict deep-layer hidden representations from shallow-layer representations during generation. The Distiller’s prediction error serves as a novelty signal that reweights candidate tokens, steering sampling toward less-explored semantic patterns instead of surface-level lexical variations.
- Evaluations across mathematics, science, and code generation benchmarks demonstrate that ESamp significantly boosts Pass@k efficiency for reasoning models while outperforming or matching strong stochastic and heuristic baselines. The method also resolves the diversity-coherence trade-off in creative writing tasks without sacrificing generation quality.
- An asynchronous training-inference pipeline decouples the Distiller’s online adaptation from the primary language model’s generation process. This design limits worst-case throughput overhead to under 5%, enabling efficient integration into standard serving scenarios.
Introduction
Test-time scaling enhances large language model reasoning by aggregating multiple candidate solutions, yet standard stochastic sampling frequently produces semantically redundant outputs that share identical underlying logic despite surface-level lexical differences. This redundancy undermines selection mechanisms, and existing alternatives like structured search impose prohibitive latency while heuristic constraints fail to elicit genuinely novel reasoning strategies. The authors propose Exploratory Sampling, a decoding approach that leverages a lightweight Distiller trained online to approximate the mapping between shallow and deep layer hidden representations. By treating high prediction error as a signal of semantic novelty, the method reweights token probabilities to steer generation toward less-explored reasoning patterns. This strategy significantly improves Pass@k efficiency across diverse benchmarks with negligible throughput overhead, effectively decoupling semantic diversity from computational cost.
Dataset
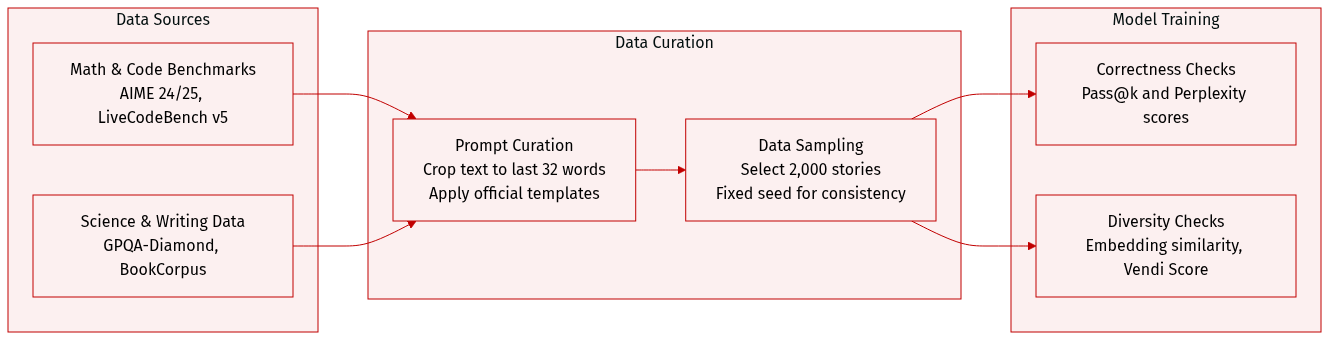
- Dataset Composition and Sources: The authors use four distinct benchmarks to evaluate model performance across mathematics, coding, scientific reasoning, and creative writing. Mathematical evaluation relies on the official AIME 2024 and AIME 2025 datasets. Code generation testing draws from LiveCodeBench v5, which aggregates time-sensitive competitive programming problems from LeetCode, AtCoder, and Codeforces. Scientific reasoning is assessed via the GPQA-Diamond subset, featuring expert-verified questions in biology, physics, and chemistry. Creative writing diversity is measured using a cleaned BookCorpus collection hosted on HuggingFace.
- Subset Details and Sizing: The mathematical and coding benchmarks utilize official releases without size modifications, while the scientific benchmark focuses exclusively on the highest quality Diamond tier. The BookCorpus subset contains approximately 51,442 classic literary works. Due to computational constraints, the authors sample exactly 2,000 stories from this collection using a fixed random seed of 42 for all generation and evaluation steps.
- Usage and Processing Strategy: The data is exclusively reserved for evaluation rather than training or fine-tuning, and no mixture ratios or training splits are applied. All benchmark prompts follow the official templates provided by the lighteval framework, which also handles the evaluation scripts. Model outputs are scored using Pass@k for correctness, embedding similarity and Vendi Score for semantic diversity, and perplexity for linguistic fluency.
- Cropping and Metadata Handling: Because the BookCorpus version lacks source text delimiters or standard metadata, the authors implement a specific cropping strategy. Each text is split in half, and the final 32 words of the first half are extracted to serve as generation prompts. This approach avoids non-narrative outputs and is applied without a chat template to preserve story continuity.
Method
The authors propose Exploratory Sampling (ESamp), a decoding method designed to promote semantic exploration during language model generation. The core of the approach is the Latent Distiller (LD), a lightweight module trained online to model the transformation of hidden representations from early to late layers of the language model. This enables the system to detect and penalize semantically redundant generations, even when surface-level text varies.
The overall framework operates by integrating the LD into the generation pipeline in a manner that avoids significant computational overhead. At each generation step, the model processes the input through its transformer layers. The first layer's output, ht1, is used by the LD to predict the corresponding deep-layer representation, h^tL. This prediction is computed asynchronously, allowing it to run in parallel with the main model's forward pass. The true deep-layer representation, htL, is then used to compute the standard language modeling logits, πref. The LD's predicted logits, qdist, are derived by projecting h^tL through the frozen language model head.
Refer to the framework diagram below for a visual representation of the process.
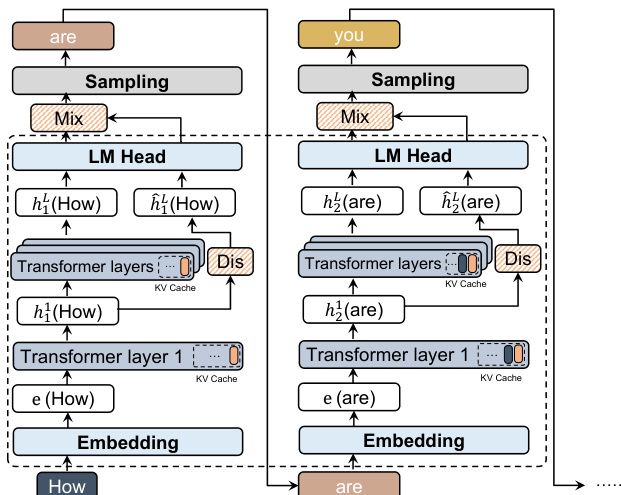
The method then computes a novel sampling distribution that encourages exploration. This is achieved by defining an intrinsic reward, r(s,z), as the log-likelihood ratio between the reference and distiller-predicted distributions for a candidate token z. This reward is incorporated into a KL-regularized policy, resulting in a new sampling distribution proportional to πref(z∣s)⋅exp(β⋅r(s,z)). This formulation can be interpreted geometrically as a linear combination of the reference and distilled logits in the logit space, where the change in logits is directly proportional to the latent error vector, et=htL−h^tL. The magnitude of this error vector, ∥et∥2, quantifies the novelty of the current context, while the cosine similarity between the error vector and the token's embedding, wz, acts as a directional guide to promote semantically distinct trajectories.

A key feature of ESamp is its collaborative exploration capability in parallel generation. The LD is updated online using hidden representations from all sequences in a batch, serving as a shared communication channel. When one sequence explores a new semantic region, the LD learns the corresponding representation mapping, causing the novelty reward for that region to diminish for all subsequent sequences. This creates an implicit "first-come, first-served" mechanism that suppresses redundant exploration and forces the collective generation to diverge and cover the semantic space efficiently. This coordination is implemented through an asynchronous pipeline. The Distiller's forward pass is initiated immediately after the LLM's first layer, overlapping with the memory-bandwidth-bound middle layers. The Distiller's training step, involving backpropagation and weight updates, is deferred to the post-processing interval, which is CPU-bound and often underutilized, allowing it to run without blocking the critical path of token generation.
Experiment
The experiments evaluate ESamp across mathematics, science, code generation, and creative writing benchmarks to assess its ability to guide LLM decoding toward under-explored semantic regions. Validation across multiple model architectures demonstrates that the method effectively scales test-time exploration, consistently matching or surpassing baselines while successfully breaking the traditional trade-off between generation quality and meaningful semantic diversity. Analysis of decoding dynamics confirms that parallel sequences maintain continuous divergence throughout generation, and efficiency evaluations reveal that the asynchronous pipeline introduces negligible computational overhead. Overall, the findings establish ESamp as a robust and practical solution for enhancing candidate coverage and reasoning path variety without compromising linguistic coherence or deployment efficiency.
The authors compare two sets of generated mathematical solutions, one produced by ESamp and the other by vanilla sampling, focusing on the diversity of problem-solving approaches. The results show that ESamp generates responses with significantly higher diversity across modeling, heuristics, unit handling, and logical pathways, while maintaining a high quality score. In contrast, vanilla sampling produces more uniform and less varied solutions, often converging on a single standard approach. ESamp generates more diverse mathematical solutions in terms of modeling, heuristics, and logical pathways compared to vanilla sampling. Vanilla sampling produces more uniform solutions, often relying on a single standardized approach. ESamp maintains high solution quality while achieving significantly higher diversity in problem-solving strategies.

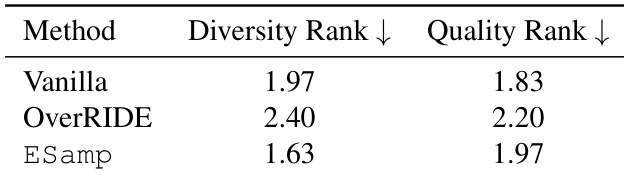
The authors evaluate the diversity and quality of generated responses using LLM-as-judge rankings, comparing methods across creative writing tasks. Results show that ESamp achieves a higher diversity rank while maintaining quality comparable to Vanilla, indicating that it promotes meaningful variation without sacrificing coherence. OverRIDE, in contrast, results in lower diversity and reduced quality relative to ESamp. ESamp achieves higher diversity and better quality ranks compared to Vanilla and OverRIDE. ESamp promotes meaningful variation in generated responses without degrading coherence. OverRIDE leads to lower diversity and quality rankings than ESamp and Vanilla.
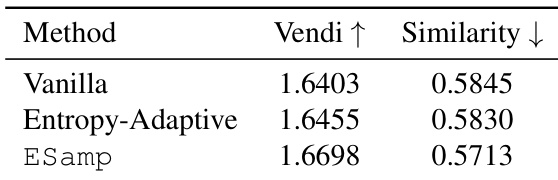
The authors evaluate the diversity and quality of generated responses using a the the table that compares different decoding methods. Results show that ESamp achieves higher semantic diversity, as indicated by a higher Vendi score, while maintaining low semantic similarity, suggesting that the generated responses are both varied and distinct. The the the table supports the claim that ESamp promotes meaningful semantic exploration without compromising generation quality. ESamp achieves higher semantic diversity compared to vanilla and entropy-adaptive methods. ESamp maintains lower semantic similarity, indicating more distinct generated responses. ESamp improves diversity while preserving generation quality, breaking the typical quality-diversity trade-off.
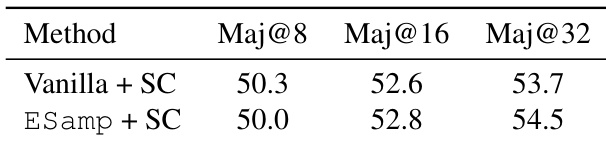
The authors evaluate the performance of ESamp in combination with Self-Consistency on a reasoning task, comparing it against Vanilla sampling with Self-Consistency. Results show that ESamp achieves comparable or slightly lower performance at smaller sampling budgets but demonstrates a consistent improvement at larger budgets, indicating its effectiveness in enhancing solution coverage when multiple candidates are considered. The method maintains a competitive balance between diversity and quality, particularly in high-budget scenarios. ESamp with Self-Consistency achieves comparable performance to Vanilla with Self-Consistency at smaller sampling budgets. ESamp shows a consistent improvement over Vanilla at larger sampling budgets, particularly in Maj@32. The combination of ESamp and Self-Consistency enhances solution coverage without significantly compromising quality.
The authors compare the throughput of ESamp against an optimized vLLM baseline under identical conditions, showing that ESamp maintains nearly equivalent performance with minimal overhead. The results indicate that the asynchronous implementation of ESamp preserves high efficiency, achieving a throughput ratio close to 1.0, which suggests negligible computational cost compared to the baseline. This demonstrates that ESamp can be deployed efficiently without significant performance degradation. ESamp achieves nearly equivalent throughput to an optimized vLLM baseline, with a ratio close to 1.0. The asynchronous design of ESamp results in minimal computational overhead, preserving high efficiency. The method maintains high performance even under demanding workloads, indicating practical scalability.

The experiments evaluate ESamp against standard baselines across mathematical reasoning, creative writing, and semantic generation tasks to validate its capacity to break the traditional diversity-quality trade-off. Results indicate that the method consistently produces more varied and distinct outputs while preserving coherence, outperforming competing approaches in both novelty and reliability. When paired with self-consistency, it further enhances solution coverage at larger sampling budgets, and its asynchronous implementation ensures negligible computational overhead for practical deployment.