HyperAI
Command Palette
Search for a command to run...
Papers
최신 AI 트렌드를 파악할 수 있도록 매일 업데이트되는 최첨단 AI 연구 논문

보안화된 출력에 대한 피니트uning을 통한 유해한 능력 유도

Memory-V2V: 메모리로 증강된 비디오 투 비디오 확산 모델






















보안화된 출력에 대한 피니트uning을 통한 유해한 능력 유도
Memory-V2V: 메모리로 증강된 비디오 투 비디오 확산 모델
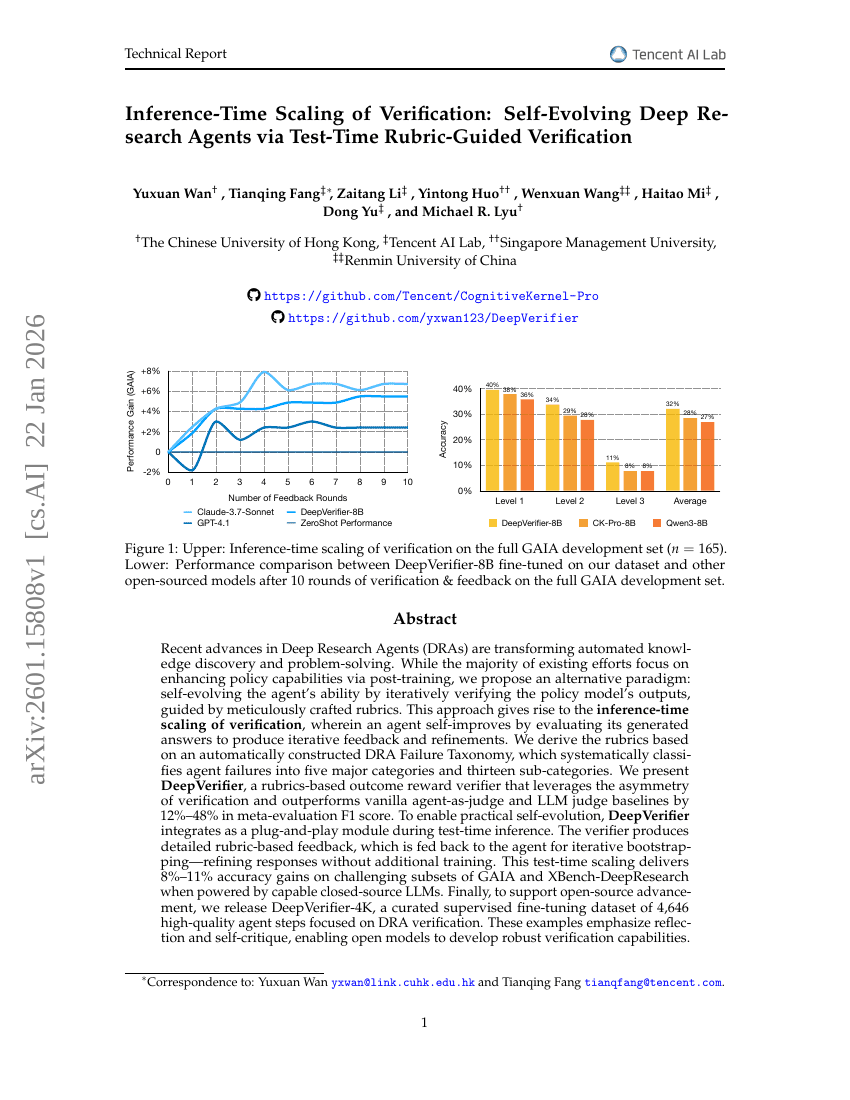
추론 시스템 스케일링: 테스트 시 루브릭 기반 검증을 통한 자가진화형 딥 리서치 에이전트
VisGym: 다각적이고 사용자 정의 가능하며 확장 가능한 다모달 에이전트를 위한 환경
TwinBrainVLA: 비대칭 트랜스포머 믹스를 통한 일반화된 VLM의 잠재력 발휘: 신체적 임무를 위한 접근
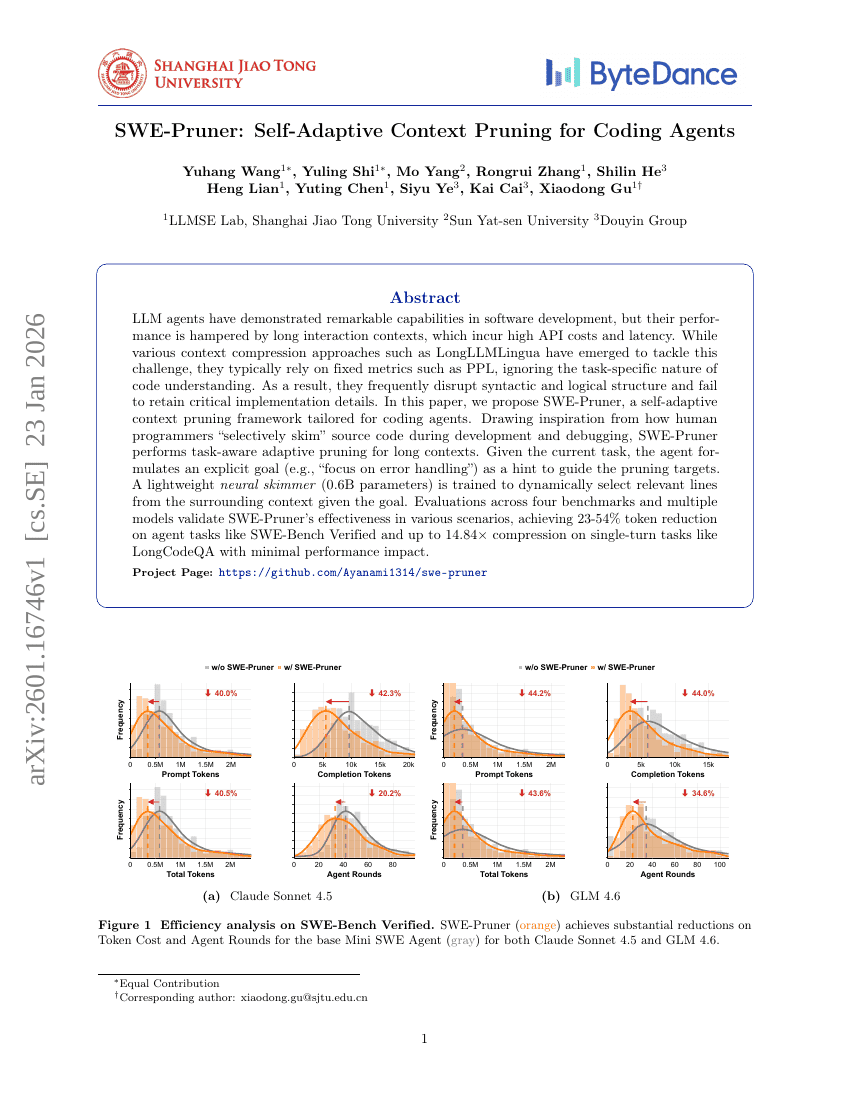
SWE-Pruner: 코드 에이전트를 위한 자기적응형 컨텍스트 프루닝
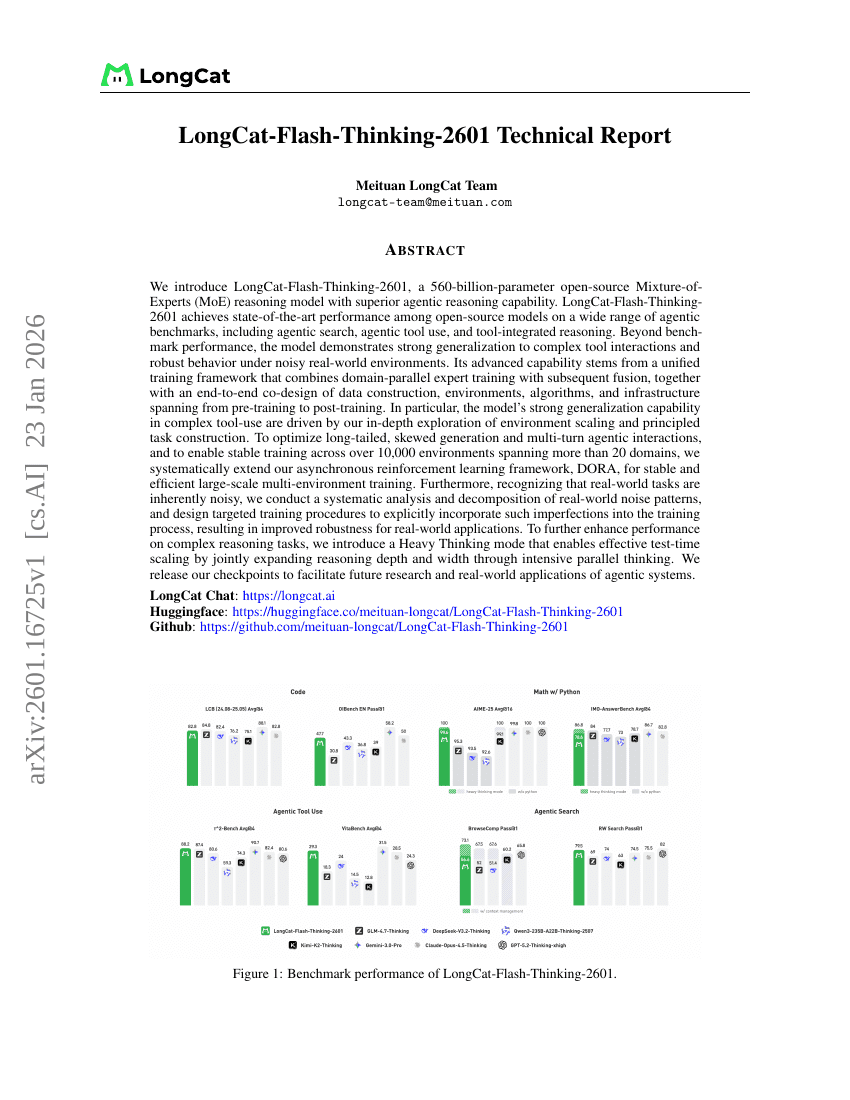
LongCat-Flash-Thinking-2601 기술 보고서
언어 모델이 스케일링 법칙을 발견할 수 있는가?
코스모스 정책: 시각운동 제어 및 계획을 위한 비디오 모델의 미세 조정
Triton-distributed: Triton 컴파일러를 사용하여 분산 AI 시스템에서 겹치는 커널 프로그래밍하기
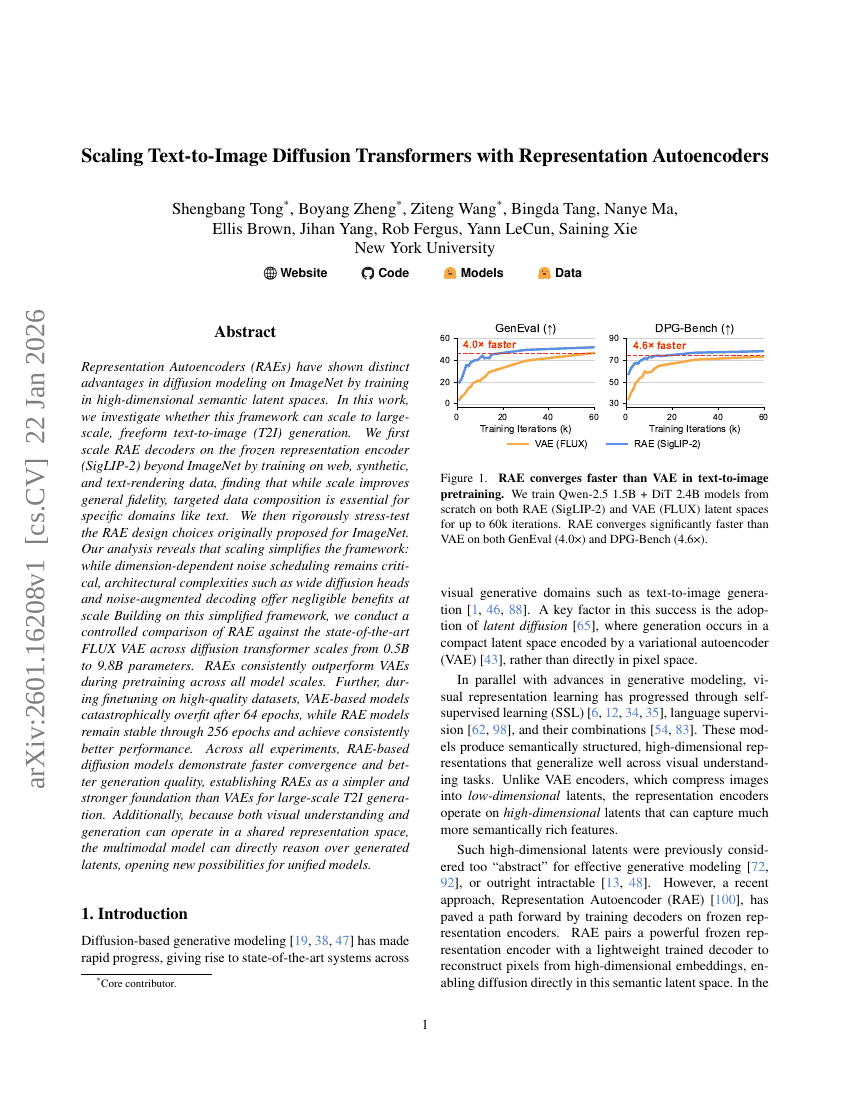
표현 오토인코더를 활용한 텍스트-to-이미지 확산 트랜스포머의 스케일링
베이지안VLA: 잠재적 액션 쿼리를 통한 시각-언어-액션 모델의 베이지안 분해
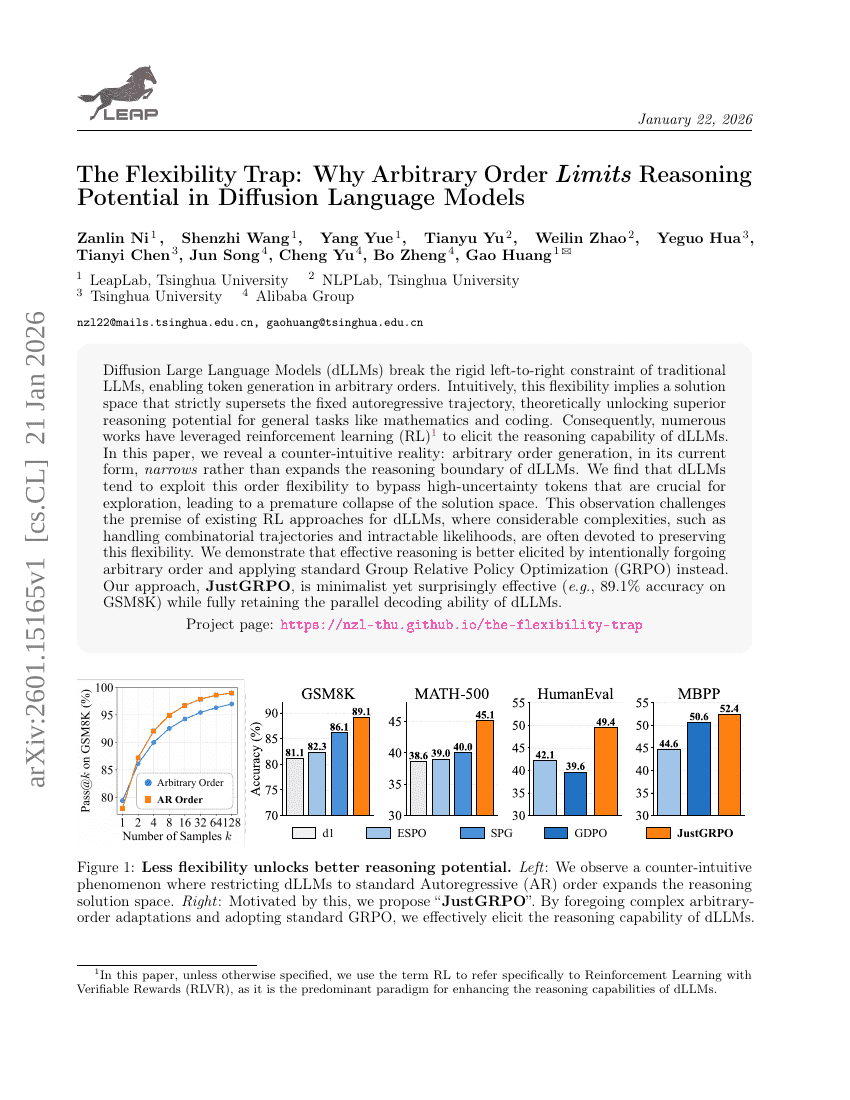
유연성의 함정: 확산 언어 모델에서 임의의 순서 제한이 추론 가능성을 어떻게 제한하는가
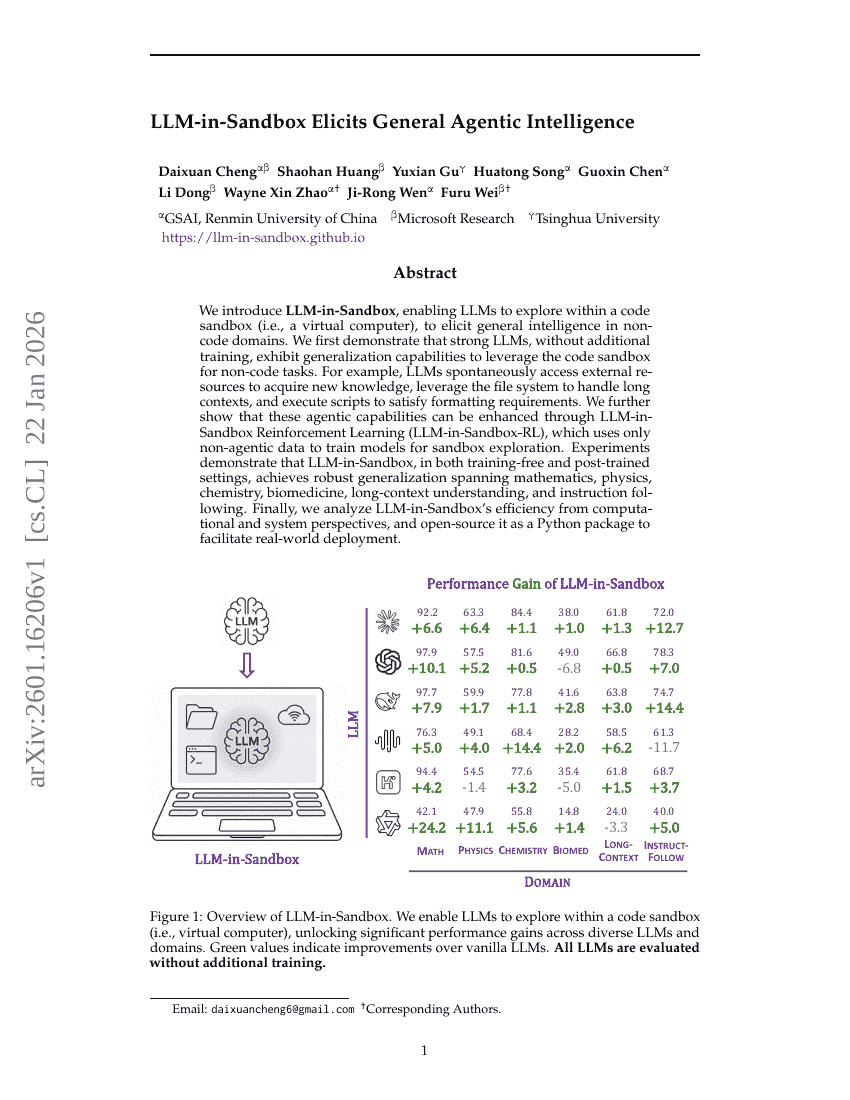
LLM-in-Sandbox를 통한 일반적인 에이전트 지능 유도
HERMES: 효율적인 스트리밍 비디오 이해를 위한 계층적 메모리로서의 KV 캐시
EvoCUA: 확장 가능한 합성 경험에서 학습을 통해 진화하는 컴퓨터 사용 에이전트
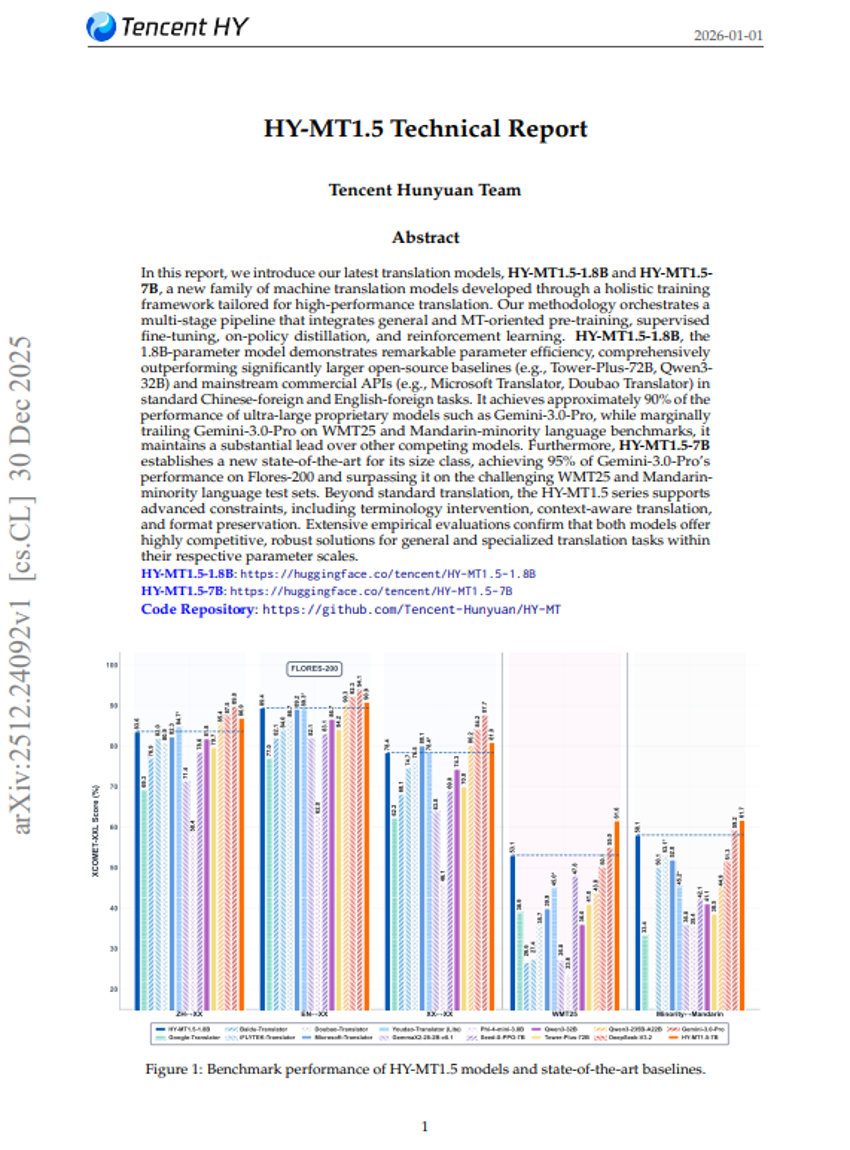
HY-MT1.5 기술 보고서
코드를 위한 스케일링 법칙: 모든 프로그래밍 언어가 중요하다
Qwen3-TTS 기술 보고서
작은 모델, 큰 결과: 분해를 통한 우수한 의도 추출 달성
FinVault: 실행 기반 환경에서 금융 에이전트의 안전성 평가
MMDeepResearch-Bench: 다중모달 심층 연구 에이전트를 위한 벤치마크
DARC: LLM 진화를 위한 비대칭 추론 커리큘럼의 분리
체화된 세계를 위한 비디오 생성 모델의 재고찰
Paper2Rebuttal: 투명한 저자 반응 지원을 위한 멀티에이전트 프레임워크
대규모 언어 모델을 위한 에이전트형 추론
PERSONAPLEX: 전체 이중 방향 대화 음성 모델을 위한 음성 및 역할 제어
FlashLabs Chroma 1.0: 개인화된 음성 클로닝을 지원하는 실시간 엔드투엔드 음성 대화 모델
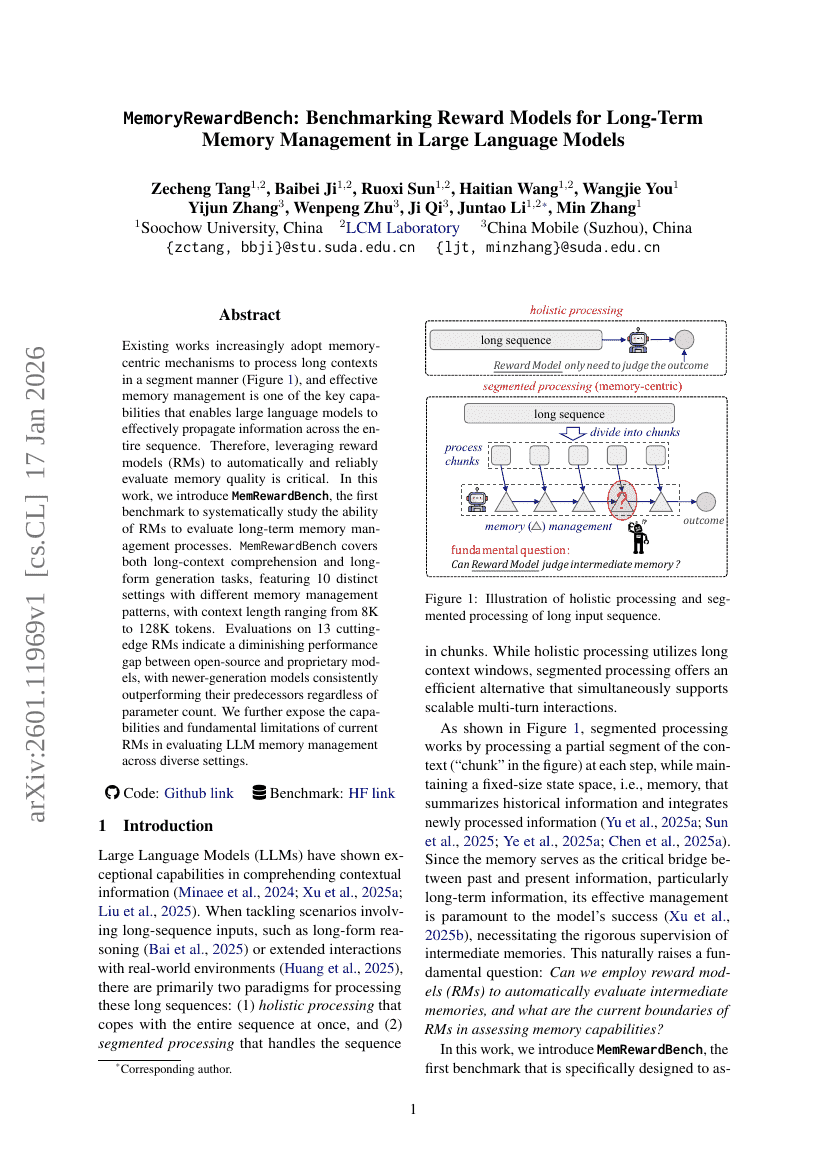
MemoryRewardBench: 대규모 언어 모델에서 장기 기억 관리에 대한 보상 모델 평가를 위한 벤치마크
오미트랜스퍼: 시공간 비디오 전이를 위한 통합 프레임워크
효율적인 에이전트를 향해: 메모리, 도구 학습, 그리고 계획
FutureOmni: 다중 모달 LLMs를 위한 옴니모달 컨텍스트에서의 미래 예측 평가
추론 시스템 스케일링: 테스트 시 루브릭 기반 검증을 통한 자가진화형 딥 리서치 에이전트
VisGym: 다각적이고 사용자 정의 가능하며 확장 가능한 다모달 에이전트를 위한 환경
TwinBrainVLA: 비대칭 트랜스포머 믹스를 통한 일반화된 VLM의 잠재력 발휘: 신체적 임무를 위한 접근
SWE-Pruner: 코드 에이전트를 위한 자기적응형 컨텍스트 프루닝
LongCat-Flash-Thinking-2601 기술 보고서
언어 모델이 스케일링 법칙을 발견할 수 있는가?
코스모스 정책: 시각운동 제어 및 계획을 위한 비디오 모델의 미세 조정
Triton-distributed: Triton 컴파일러를 사용하여 분산 AI 시스템에서 겹치는 커널 프로그래밍하기
표현 오토인코더를 활용한 텍스트-to-이미지 확산 트랜스포머의 스케일링
베이지안VLA: 잠재적 액션 쿼리를 통한 시각-언어-액션 모델의 베이지안 분해
유연성의 함정: 확산 언어 모델에서 임의의 순서 제한이 추론 가능성을 어떻게 제한하는가
LLM-in-Sandbox를 통한 일반적인 에이전트 지능 유도
HERMES: 효율적인 스트리밍 비디오 이해를 위한 계층적 메모리로서의 KV 캐시
EvoCUA: 확장 가능한 합성 경험에서 학습을 통해 진화하는 컴퓨터 사용 에이전트
HY-MT1.5 기술 보고서
코드를 위한 스케일링 법칙: 모든 프로그래밍 언어가 중요하다
Qwen3-TTS 기술 보고서
작은 모델, 큰 결과: 분해를 통한 우수한 의도 추출 달성
FinVault: 실행 기반 환경에서 금융 에이전트의 안전성 평가
MMDeepResearch-Bench: 다중모달 심층 연구 에이전트를 위한 벤치마크
DARC: LLM 진화를 위한 비대칭 추론 커리큘럼의 분리
체화된 세계를 위한 비디오 생성 모델의 재고찰
Paper2Rebuttal: 투명한 저자 반응 지원을 위한 멀티에이전트 프레임워크
대규모 언어 모델을 위한 에이전트형 추론
PERSONAPLEX: 전체 이중 방향 대화 음성 모델을 위한 음성 및 역할 제어
FlashLabs Chroma 1.0: 개인화된 음성 클로닝을 지원하는 실시간 엔드투엔드 음성 대화 모델
MemoryRewardBench: 대규모 언어 모델에서 장기 기억 관리에 대한 보상 모델 평가를 위한 벤치마크
오미트랜스퍼: 시공간 비디오 전이를 위한 통합 프레임워크
효율적인 에이전트를 향해: 메모리, 도구 학습, 그리고 계획
FutureOmni: 다중 모달 LLMs를 위한 옴니모달 컨텍스트에서의 미래 예측 평가