Command Palette
Search for a command to run...
FlashLabs Chroma 1.0: 개인화된 음성 클로닝을 지원하는 실시간 엔드투엔드 음성 대화 모델
FlashLabs Chroma 1.0: 개인화된 음성 클로닝을 지원하는 실시간 엔드투엔드 음성 대화 모델
Tanyu Chen Tairan Chen Kai Shen Zhenghua Bao Zhihui Zhang Man Yuan Yi Shi
초록
최근의 종단 간 음성 대화 시스템은 언어 모델(LLM)이 이산적 음성 표현 위에서 직접 작동할 수 있도록 음성 토크나이저와 신경망 오디오 코덱을 활용하고 있다. 그러나 이러한 모델들은 종종 발화자 정체성의 보존 능력이 제한적이어서 개인화된 음성 상호작용을 방해한다. 본 연구에서는 실시간, 종단 간 음성 대화 모델로서 세계 최초로 오픈소스화된 Chroma 1.0을 제안한다. Chroma 1.0은 낮은 지연 시간과 높은 품질의 개인화된 음성 클로닝을 동시에 달성한다. 본 모델은 텍스트-오디오 토큰 스케줄을 1:2 비율로 교차 배치하는 방식을 통해 종단 간 지연 시간을 1초 미만으로 줄이며, 다단계 대화 상황에서도 고품질의 개인화된 음성 합성을 유지한다. 실험 결과, Chroma는 인간 기준 대비 발화자 유사도에서 10.96%의 상대적 향상을 달성했으며, 실시간 요인(RTF)은 0.43을 기록하면서도 강력한 추론 능력과 대화 능력을 유지함을 입증하였다. 본 연구의 코드 및 모델은 다음과 같은 링크에서 공개되어 있다: https://github.com/FlashLabs-AI-Corp/FlashLabs-Chroma 및 https://huggingface.co/FlashLabs/Chroma-4B.
One-sentence Summary
Researchers at FlashLabs introduce Chroma 1.0, the first open-source, real-time spoken dialogue model that preserves speaker identity via a 1:2 text-audio token schedule, enabling sub-second latency and high-fidelity voice cloning while outperforming human baselines in speaker similarity and maintaining strong reasoning.
Key Contributions
- Chroma 1.0 introduces the first open-source, real-time end-to-end spoken dialogue system that preserves speaker identity across multi-turn conversations, addressing the critical limitation of prior models that sacrifice voice fidelity for latency or vice versa.
- It employs a novel 1:2 interleaved text-audio token schedule to enable sub-second latency and streaming generation while conditioning speech synthesis on short reference audio clips, achieving a 10.96% relative improvement in speaker similarity over human baselines.
- Despite its compact 4B-parameter design, Chroma maintains strong reasoning and dialogue capabilities, validated through benchmarks with a Real-Time Factor of 0.43, and is publicly released for reproducibility and further research.
Introduction
The authors leverage recent advances in speech tokenization and neural codecs to build Chroma 1.0, an open-source, real-time end-to-end spoken dialogue system that preserves personalized voice identity across multi-turn conversations. Prior end-to-end models either sacrifice speaker fidelity for low latency or lack streaming capabilities, while cascaded ASR-LLM-TTS pipelines lose paralinguistic cues and accumulate latency. Chroma overcomes these by introducing an interleaved 1:2 text-audio token schedule that enables sub-second latency and high-fidelity voice cloning from just seconds of reference audio, achieving a 10.96% relative improvement in speaker similarity over human baselines without compromising reasoning or dialogue quality.
Dataset

- The authors use a custom data generation pipeline to create high-quality speech dialogue data, since publicly available datasets fall short in meeting their model’s needs for semantic understanding and reasoning.
- The pipeline has two stages: (1) Text Generation — user questions are processed by a Reasoner-like LLM to produce textual responses; (2) Speech Synthesis — those responses are converted to speech using a TTS system that matches the timbre of reference audio.
- The synthesized speech acts as the training target for the Backbone and Decoder modules, enabling them to learn voice cloning and acoustic modeling.
- No external datasets are used; all training data is synthetically generated through this LLM-TTS collaboration.
- No cropping, metadata construction, or additional filtering rules are mentioned — the focus is on end-to-end synthetic generation tailored to the model’s architecture.
Method
The Chroma 1.0 system employs an end-to-end architecture designed for high-quality, real-time spoken dialogue, integrating speech perception and language understanding through a tightly coupled framework. As illustrated in the figure below, the system comprises two primary subsystems: the Chroma Reasoner and a speech synthesis pipeline. The Reasoner handles multimodal input comprehension and textual response generation, while the synthesis pipeline consists of the Chroma Backbone, Chroma Decoder, and Chroma Codec Decoder, responsible for acoustic modeling, codebook decoding, and waveform reconstruction, respectively.

The Chroma Reasoner, built upon the Thinker module, processes both text and audio inputs using the Qwen2-Audio encoding pipeline to generate high-level semantic representations. It employs a cross-modal attention mechanism to fuse text and audio features, which are unified into a sequence of hidden states through Time-aligned Multimodal Rotary Position Embedding (TM-RoPE). This fusion enables the model to leverage prosodic and rhythmic cues from speech alongside textual semantics, enhancing dialogue understanding and contextual modeling for subsequent synthesis.
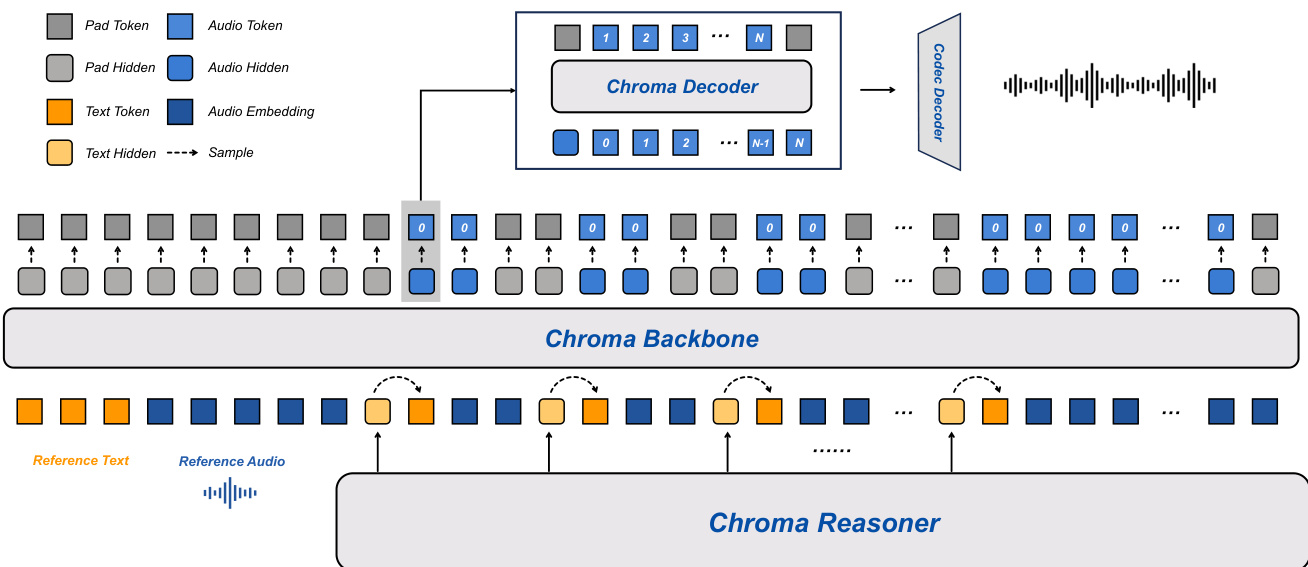
The Chroma Backbone, a 1B-parameter variant of the LLaMA architecture, generates speech that matches the timbre of a given reference audio. It encodes the reference audio and its corresponding transcript into embedding prompts using CSM-1B and prepends them to the input sequence, explicitly conditioning the model on the target speaker's acoustic characteristics. To ensure strict alignment between the audio output and the Reasoner's text modality while maintaining a low parameter count, a shared token embedding strategy is applied: the Reasoner's token embeddings and hidden states are fed into the Backbone as unified textual context. To support efficient streaming generation, the Backbone interleaves text tokens with audio code tokens c0 at a fixed ratio of 1:2, enabling autoregressive generation of audio sequences in parallel with the Reasoner's incremental text generation, thereby reducing the Time-to-First-Token (TTFT).
The Chroma Decoder, a lightweight module with approximately 100M parameters, is responsible for generating the remaining acoustic codes (ct1,…,ctN−1) rather than having the Backbone produce all codebooks directly. This module performs frame-synchronous inference conditioned only on the Backbone outputs at the current time step, significantly reducing computational overhead. At each time step t, the Chroma Decoder takes as input the hidden-state features ht and the initial audio codebook ct0 produced by the Backbone, and autoregressively generates the remaining RVQ codebooks cti (i=1,…,N−1) within each frame using level-specific projection heads conditioned on previously generated levels. This decoupled design reduces inference latency and enables the Chroma Decoder to enrich fine-grained acoustic attributes such as prosody and articulation details.
The Chroma Codec Decoder serves as the final acoustic reconstruction module, mapping the discrete codebook sequence into a continuous, high-fidelity speech waveform. At each time step, it concatenates the coarse codebook (c0) and the refined acoustic codebooks (c1,…,cN−1) generated by the Chroma Decoder to form the complete discrete acoustic representation. Architecturally, this module follows the decoder design of the Mimi vocoder and employs a causal convolutional neural network (Causal CNN), ensuring strict temporal causality during waveform reconstruction to support streaming generation. To meet real-time interaction requirements, the system uses 8 codebooks (N=8), which significantly reduces the autoregressive refinement steps required by the Chroma Decoder, improving inference efficiency.
The training strategy optimizes the Backbone and the Decoder while keeping the Reasoner frozen as a feature extractor. For each audio-text pair, the Reasoner provides fixed text embeddings and multimodal hidden states that serve as semantic and prosodic conditioning. The Backbone is trained to autoregressively predict the first layer of coarse acoustic codes (c0), attending only to the prefix of the acoustic codes and the corresponding Reasoner representations to ensure causal alignment. The Decoder refines the coarse acoustic representation by predicting the remaining Residual Vector Quantization (RVQ) levels (c1:N−1), conditioned on the Backbone's coarse code and hidden state, operating via an intra-frame autoregressive process. This factorization allows the Decoder to progressively enhance acoustic fidelity while maintaining consistency with the coarse trajectory established by the Backbone.
Experiment
- Evaluated on CommonVoice for general speech quality and URO-Bench for reasoning; used subjective CMOS and objective SIM/TTFT/RTF metrics.
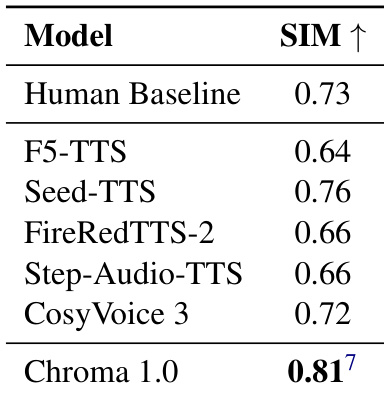
- Achieved 10.96% relative improvement over human baseline in speaker similarity (SIM) on zero-shot voice cloning, outperforming all SOTA models.
- In subjective tests vs ElevenLabs: ElevenLabs led in naturalness (NCMOS: 57.2% vs 24.4%), but Chroma matched closely in speaker fidelity (SCMOS: 40.6% vs 42.4%), suggesting stronger preservation of paralinguistic traits.
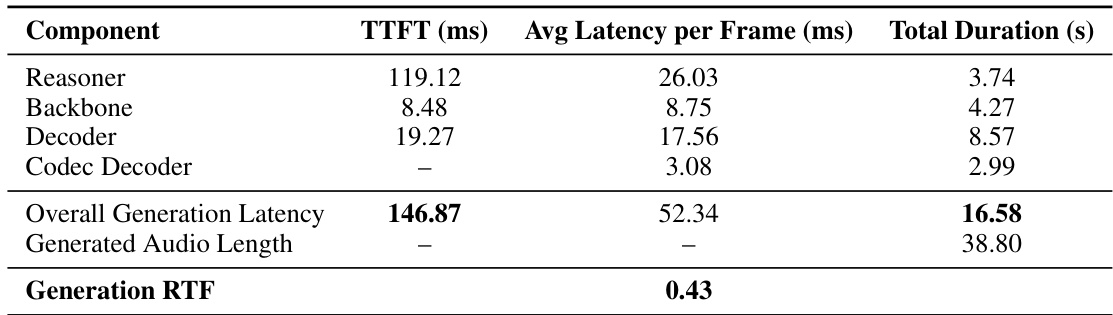
- Latency: TTFT of 146.87ms and RTF of 0.43 (2.3x faster than real-time), enabling responsive, streaming-capable interaction.
- On URO-Bench reasoning tasks, ranked second overall (e.g., 71.14% on Storal) despite using only 4B parameters; led in oral conversation metrics (MLC 60.26%, CommonVoice 62.07%) and was the only model with voice cloning capability.
The authors use the table to analyze the latency breakdown of the Chroma system during speech generation. Results show that the overall system achieves a Time-to-First-Token (TTFT) of 146.87ms, with the Reasoner component contributing the largest portion at 119.12ms. The system generates audio with a Real-Time Factor (RTF) of 0.43, indicating it produces speech significantly faster than real-time playback.
Results show that ElevenLabs outperforms Chroma in naturalness with a 57.2% preference in NCMOS, while Chroma achieves a slightly lower score of 24.4%. In speaker similarity, Chroma and ElevenLabs are nearly tied, with Chroma receiving 40.6% of preferences compared to ElevenLabs' 42.4%, indicating comparable voice cloning performance despite differences in system design.

The authors use the Speaker Similarity (SIM) metric to evaluate voice cloning performance, with higher values indicating better speaker identity preservation. Results show that Chroma 1.0 achieves a SIM score of 0.81, outperforming all compared models and exceeding the human baseline of 0.73 by 10.96%, demonstrating its superior ability to capture fine-grained paralinguistic features for high-fidelity voice cloning.
The authors evaluate Chroma's dialogue capabilities by comparing it against other end-to-end spoken dialogue models on the URO-Bench dataset, measuring performance across understanding, reasoning, and oral conversation. Despite being optimized for voice cloning, Chroma achieves competitive results across all dimensions, ranking second in reasoning and understanding tasks and first in oral conversation, while maintaining a significantly smaller model size of 4B parameters.

The authors use a comparative mean opinion score (CMOS) evaluation to assess the naturalness of synthesized speech, comparing ElevenLabs outputs against reference audio. Results show that evaluators overwhelmingly preferred ElevenLabs-generated audio, with 92.0% of preferences, compared to only 8.0% for the reference recordings, indicating a strong bias toward synthesized speech perceived as more natural.
