Command Palette
Search for a command to run...
HERMES: 효율적인 스트리밍 비디오 이해를 위한 계층적 메모리로서의 KV 캐시
HERMES: 효율적인 스트리밍 비디오 이해를 위한 계층적 메모리로서의 KV 캐시
Haowei Zhang Shudong Yang Jinlan Fu See-Kiong Ng Xipeng Qiu
초록
최근 다중모달 대규모 언어 모델(Multimodal Large Language Models, MLLMs)의 발전은 오프라인 영상 이해 능력에서 큰 진전을 보였다. 그러나 이러한 기능을 스트리밍 영상 입력에 확장하는 것은 여전히 도전 과제이며, 기존 모델들은 안정적인 이해 성능, 실시간 응답, 낮은 GPU 메모리 오버헤드를 동시에 유지하는 데 어려움을 겪고 있다. 이 문제를 해결하기 위해 우리는 실시간且 정확한 영상 스트림 이해를 위한 새로운 학습 불필요 아키텍처인 HERMES를 제안한다. 기계적 주의 메커니즘 분석을 기반으로, 우리는 KV 캐시를 다양한 세부성 수준에서 영상 정보를 포함하는 계층적 메모리 프레임워크로 재구성한다. 추론 과정에서 HERMES는 컴팩트한 KV 캐시를 재사용함으로써 자원 제약 하에서도 효율적인 스트리밍 이해를 가능하게 한다. 특히 HERMES는 사용자 쿼리 도착 시 추가적인 보조 계산이 필요하지 않으며, 지속적인 영상 스트림 상호작용에 대해 실시간 응답을 보장한다. 이로 인해 기존 최고 성능(SOTA) 모델 대비 TTFT(Time To First Token)이 최대 10배 빠르게 구현된다. 또한 균일 샘플링 대비 영상 토큰을 최대 68%까지 줄여도 모든 벤치마크에서 우수하거나 유사한 정확도를 달성하였으며, 스트리밍 데이터셋에서는 최대 11.4%의 성능 향상을 기록했다.
One-sentence Summary
Hawei Zhang et al. from Fudan University, Shanghai Innovation Institute, and National University of Singapore propose HERMES, a training-free architecture that enables real-time, memory-efficient video stream understanding via hierarchical KV cache reuse, achieving 10× faster TTFT and up to 11.4% accuracy gains over prior methods.
Key Contributions
- HERMES introduces a training-free architecture for streaming video understanding by reinterpreting the KV cache as a hierarchical memory system that organizes video content across sensory, working, and long-term granularities, enabling stable inference under resource constraints.
- By reusing a compact, hierarchically managed KV cache, HERMES reduces video tokens by up to 68% compared to uniform sampling while achieving superior or comparable accuracy, including up to 11.4% gains on streaming benchmarks.
- HERMES guarantees real-time responses with no auxiliary computation at query time, achieving 10× faster time-to-first-token than prior training-free methods and maintaining constant GPU memory usage across long video streams.
Introduction
The authors leverage the inherent structure of transformer key-value (KV) caches to treat them as hierarchical memory systems—sensory, working, and long-term—for streaming video understanding, enabling real-time, memory-efficient inference without retraining. Prior methods either rely on external memory systems that introduce latency or lack granular, interpretable cache management, making them unsuitable for unpredictable streaming inputs. HERMES’s main contribution is a training-free, plug-and-play framework that reuses a compact, hierarchically managed KV cache during inference, achieving up to 10× faster time-to-first-token and 68% token reduction with no auxiliary computation, while matching or exceeding accuracy on streaming benchmarks.
Dataset

The authors use a combination of streaming and offline video understanding benchmarks to evaluate their model’s temporal and real-time reasoning capabilities. Here’s how the datasets are composed and used:
-
Streaming Benchmarks (evaluated for real-time and backward-tracing tasks):
- StreamingBench (Real-Time Visual Understanding subset): 500 videos, 2,500 multiple-choice questions across 10 tasks (e.g., object perception, causal reasoning). Only this subset is used.
- OVO-Bench: 644 videos, ~2,800 fine-grained multiple-choice QA pairs across 12 tasks. Authors use only real-time perception and backward tracing subsets, excluding forward active responding.
- RVS-Ego & RVS-Movie: 10 ego-centric videos (from Ego4D) + 22 movie clips (from MovieNet), totaling 21+ hours of continuous video. Designed for real-time streaming evaluation.
-
Offline Benchmarks (evaluated for temporal understanding and multimodal reasoning):
- MVBench: 20 temporal tasks (e.g., action sequence, moving direction) derived from static-to-dynamic conversion. Sources include NTU RGB+D and Perception datasets.
- Egoschema: 5,000+ multiple-choice QA pairs from Ego4D egocentric videos, designed for long-form video understanding.
- VideoMME: 900 videos across 6 domains, 2,700 QA pairs requiring multimodal input (video, subtitles, audio).
-
Processing & Usage:
- The model processes video via sliding windows (e.g., 10,000 video tokens) to manage long sequences.
- Token compression is guided by local and global prompts, depending on whether conversation history exists.
- For streaming tasks, the model focuses on real-time perception and backward tracing; proactive responding is excluded.
- All benchmarks are used for evaluation only — no training data is derived from them.
- Metadata includes task type (MC/OE), video source, and subset designation (e.g., rt/bw) for structured analysis.
Method
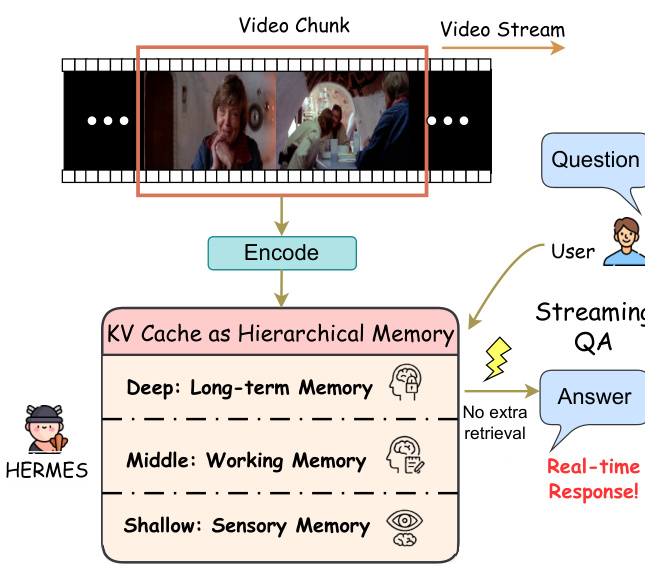
The authors propose HERMES, a training-free framework designed to enhance the memory efficiency of multimodal large language models (MLLMs) in streaming video understanding scenarios. The core of HERMES is a hierarchical KV cache architecture that organizes memory across different layers of the model to reflect distinct cognitive functions. As shown in the figure below, the KV cache is structured into three distinct layers: shallow layers act as sensory memory, middle layers serve as working memory, and deep layers function as long-term memory. This layered organization enables the model to maintain a compact yet semantically rich representation of the video stream.
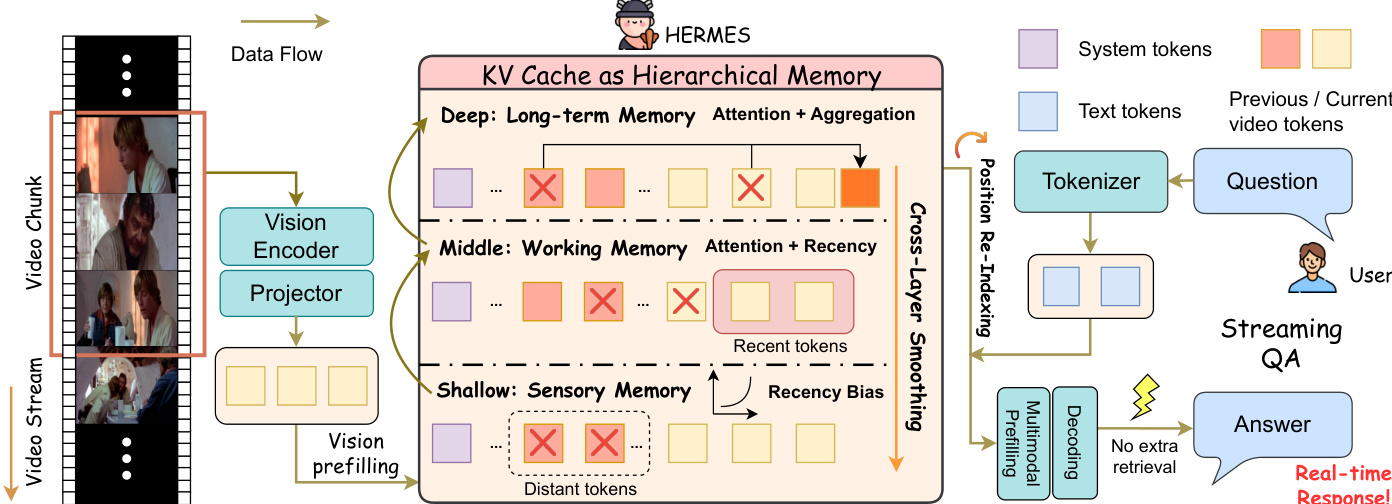
The hierarchical KV cache management strategy computes token importance scores differently across these layers to reflect their distinct roles. In shallow layers, which exhibit strong recency bias, token importance is modeled using an exponential forgetting curve based on temporal distance from the current position, capturing the sensory memory characteristic. In deep layers, which function as long-term memory, token importance is derived directly from attention weights with respect to a query, using a generic guidance prompt as a pseudo-query to handle streaming scenarios. For middle layers, which bridge the gap between recency and long-term focus, importance is computed by interpolating the recency score and attention weight using a layer-dependent interpolation weight.
To address potential inconsistencies arising from independent token eviction across layers, HERMES employs cross-layer memory smoothing. This mechanism propagates and smooths importance signals from deeper to shallower layers, ensuring that tokens at the same physical cache index are more consistently retained. The smoothed importance scores are then used to perform Top-K selection, maintaining a fixed memory budget per layer. Evicted tokens are aggregated into a single summary token per layer, which compactly encodes long-term information and is retained in the KV cache.
Position re-indexing is applied to stabilize inference as the continuous accumulation of streaming inputs can cause positional indices to exceed the model's maximum supported range. This process remaps positional indices to a contiguous range within the memory budget. Two strategies are implemented: lazy re-indexing, which is triggered only when indices approach the limit, and eager re-indexing, which is performed at each compression step. The details of re-indexing for 1D RoPE and 3D M-RoPE are illustrated in the figure below, showing how retained video tokens are re-indexed in a left-compact manner after a fixed system prefix, with a delta-based rotary correction applied to cached key states to preserve attention correctness.
Experiment
- HERMES achieves state-of-the-art on StreamingBench (79.44%) and OVO-Bench (59.21%) using Qwen2.5-VL-7B with 4K tokens, outperforming base models by 6.13–6.93% and all 7B-scale open-source models.
- On open-ended RVS benchmarks, HERMES improves accuracy by up to 11.4% over base models, demonstrating superior fine-grained temporal and spatial comprehension via GPT-3.5-turbo evaluation.
- For offline tasks, HERMES on LLaVA-OV-7B surpasses base models on Egoschema (60.29%) and VideoMME (58.85%), matching performance on MVBench (56.92% vs 57.02%).
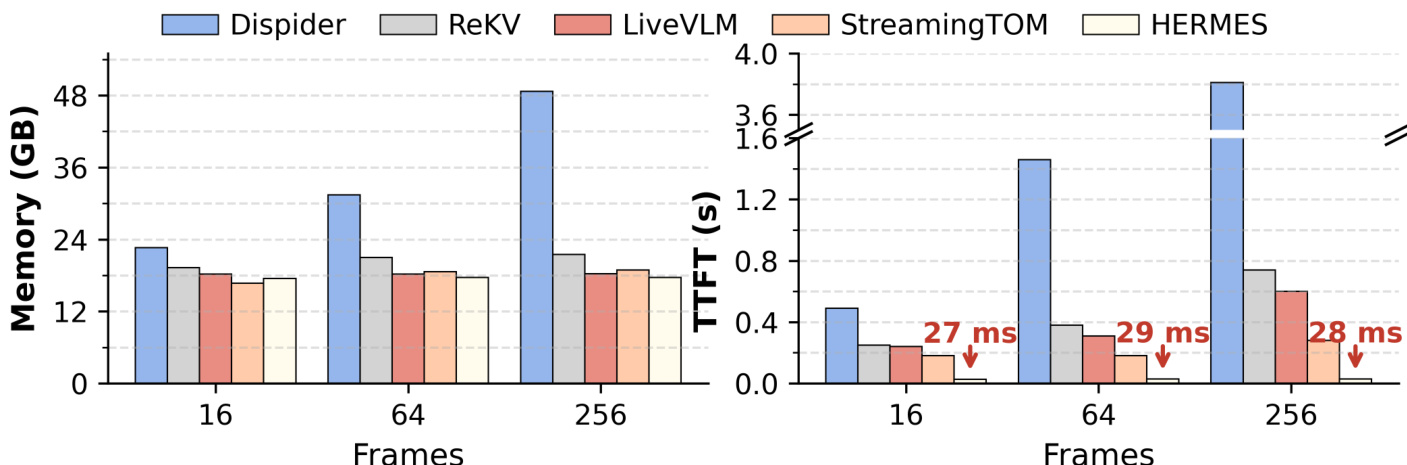
- Efficiency tests show HERMES maintains stable memory and latency, achieving 10× faster TTFT than prior SOTA and 1.04× lower peak memory than LiveVLM at 256 frames.
- Ablations confirm 4K memory budget is optimal, cross-layer smoothing is critical, and summary tokens in deep layers enhance long-term retention on VideoMME.
- Case studies validate HERMES’s superior temporal and spatial reasoning over LLaVA-OV-7B in streaming video scenarios.
The authors use HERMES to enhance the performance of LLaVA-OV-7B on offline video understanding tasks, particularly on long videos. Results show that HERMES achieves a 58.44% average accuracy on VideoMME, outperforming the base model by 1.77% and demonstrating improved performance on long video segments compared to the base model.
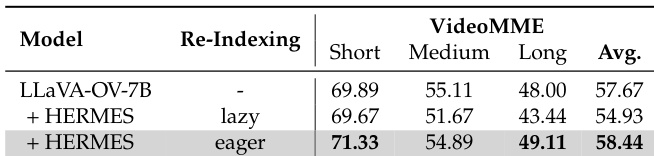
The authors use HERMES to enhance the performance of LLaVA-OV-7B on offline video benchmarks, achieving a significant improvement in accuracy on long videos with a 49.11% score compared to the base model's 48.00%. Results show that HERMES consistently outperforms the base model across all video length categories, with the largest gain observed in long videos, demonstrating its effectiveness in preserving and utilizing long-term visual information.
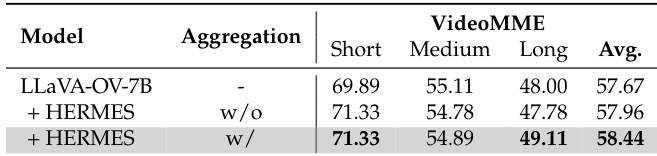
The authors use HERMES to evaluate its performance on offline video benchmarks, including MVBench, Egoschema, and VideoMME, which are characterized by varying durations, numbers of videos, and question-answer pairs. Results show that HERMES achieves competitive performance on these datasets, with accuracy on MVBench comparable to the base model and significant improvements on long video datasets Egoschema and VideoMME.

Results show that HERMES maintains stable GPU memory usage and Time to First Token across increasing numbers of input frames, while other methods like All Frames and ReKV experience significant memory growth and latency spikes, with All Frames triggering offloading to CPU at high frame counts. HERMES achieves a 10× speedup in Time to First Token compared to prior SOTA methods, demonstrating superior efficiency in real-time streaming scenarios.
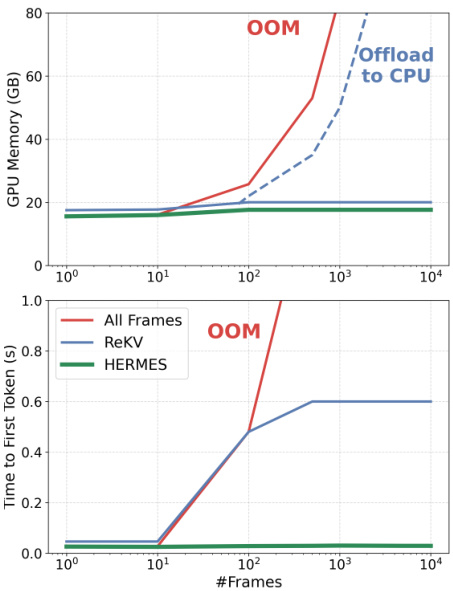
The authors use the provided efficiency analysis to compare HERMES with other streaming methods, showing that HERMES maintains stable memory usage and significantly reduces time to first token (TTFT) as input frames increase. Results show that HERMES achieves a 10× speedup in TTFT compared to StreamingTOM and reduces peak memory usage by 1.04× compared to LiveVLM under the 256-frame setting.