Command Palette
Search for a command to run...
체화된 세계를 위한 비디오 생성 모델의 재고찰
체화된 세계를 위한 비디오 생성 모델의 재고찰
Yufan Deng Zilin Pan Hongyu Zhang Xiaojie Li Ruoqing Hu Yufei Ding Yiming Zou Yan Zeng Daquan Zhou
초록
영상 생성 모델은 몸체지능(embodied intelligence) 분야에서 급격한 발전을 이뤄내며, 실제 세계에서의 인지, 추론 및 행동을 포착하는 다양한 로봇 데이터 생성이라는 새로운 가능성을 열어주었다. 그러나 실제 로봇 상호작용을 정확하게 반영하는 고품질 영상을 합성하는 것은 여전히 도전 과제이며, 표준화된 벤치마크의 부재는 공정한 비교와 기술 발전을 제한하고 있다. 이러한 격차를 보완하기 위해, 다섯 가지 작업 도메인과 네 가지 서로 다른 몸체 형태(embodiment)를 포함하여 로봇 중심의 영상 생성을 평가할 수 있도록 설계된 종합적인 로봇 벤치마크인 RBench를 제안한다. RBench는 재현 가능한 하위 지표(예: 구조적 일관성, 물리적 타당성, 행동 완전성)를 통해 작업 수준의 정확성과 시각적 사실성(visual fidelity)을 동시에 평가한다. 대표적인 25개 모델에 대한 평가 결과, 물리적으로 현실적인 로봇 행동을 생성하는 데 있어 심각한 부족이 드러났다. 더불어 이 벤치마크는 인간 평가와 0.96의 스피어만 상관 계수(Spearman correlation coefficient)를 기록하며, 그 유효성을 입증하였다. RBench는 이러한 결함을 식별할 수 있는 핵심 도구를 제공하지만, 물리적 현실성의 달성을 위해서는 단순한 평가를 넘어서 고품질 훈련 데이터의 근본적인 부족 문제를 해결해야 한다. 이러한 통찰에 기반하여, 개선된 4단계 데이터 처리 파이프라인을 도입하여, 400만 개의 주석이 부여된 영상 클립을 포함하고, 수천 가지 작업을 커버하며 풍부한 물리적 특성 주석을 갖춘 RoVid-X라는 세계 최대 규모의 오픈소스 로봇 데이터셋을 개발하였다. 종합적으로, 평가와 데이터의 상호보완적 생태계는 영상 모델의 엄격한 평가 및 확장 가능한 훈련을 위한 견고한 기반을 마련하며, 몸체지능의 진화가 일반지능에로의 전환을 가속화하는 데 기여할 것이다.
One-sentence Summary
Researchers from Peking University and ByteDance Seed introduce RBench, a comprehensive robotics video generation benchmark, and RoVid-X, a large-scale annotated dataset, to address physical realism gaps by evaluating 25 models and enabling scalable training for embodied AI advancement.
Key Contributions
- We introduce RBench, the first comprehensive benchmark for robotic video generation, evaluating 25 models across five task domains and four robot embodiments using reproducible metrics for task correctness and physical plausibility, with a 0.96 Spearman correlation to human judgments.
- Our evaluation reveals that current video foundation models struggle with generating physically realistic robot behaviors, exposing critical gaps in action completeness and structural consistency that hinder their use in embodied AI applications.
- We release RoVid-X, the largest open-source robotic video dataset for video generation, comprising 4 million annotated clips with physical property annotations, built via a four-stage pipeline to support scalable training and improve generalization in embodied video models.
Introduction
The authors leverage recent advances in video generation to address the growing need for realistic, task-aligned robotic video synthesis in embodied AI. While video models show promise for simulating robot behaviors and reducing reliance on costly teleoperation data, prior benchmarks fail to evaluate physical plausibility and task completion—leading to misleadingly high scores for unrealistic outputs. To fix this, they introduce RBench, a new benchmark with 650 samples across five tasks and four robot types, using automated metrics that assess structural consistency, physical plausibility, and action completeness, validated by a 0.96 Spearman correlation with human judgment. They also release RoVid-X, a 4-million-clip dataset built via a four-stage pipeline, enriched with physical annotations and diverse robot-task coverage, to tackle the scarcity of high-quality training data. Together, RBench and RoVid-X form a unified ecosystem to rigorously evaluate and train video models for embodied intelligence.
Dataset

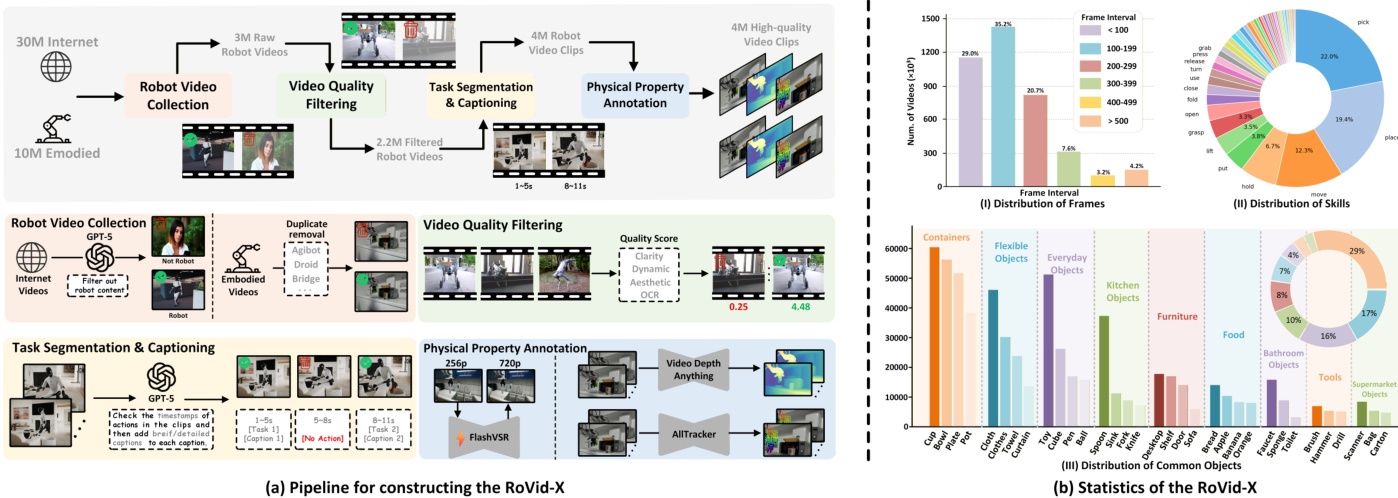
The authors use RoVid-X, a large-scale robotic video dataset of 4 million clips, to train and evaluate video generation models for embodied AI. The dataset is built from internet-sourced public videos and over 20 open-source embodied datasets, filtered and enhanced through a four-stage pipeline:
- Collection: Raw videos are gathered from public platforms and open datasets, covering diverse robots and tasks. GPT-5 filters out irrelevant or low-quality clips, leaving ~3 million candidates.
- Quality Filtering: Videos are segmented by scene, then scored for clarity, motion, aesthetics, and OCR. Only high-scoring clips are retained.
- Task Segmentation & Captioning: A video understanding model segments clips by action, labeling start/end times and generating standardized subtitles describing the subject, object, and operation (e.g., “right arm grasps box”).
- Physical Annotation: FlashVSR enhances resolution; AllTracker adds optical flow; Video Depth Anything generates depth maps — all to enforce physical realism and spatial consistency.
For evaluation, the authors construct RBench, a benchmark with 650 cases across 5 task categories (Common Manipulation, Long-horizon Planning, Multi-entity Collaboration, Spatial Relationship, Visual Reasoning) and 4 embodiment types (Dual-arm, Humanoid, Single-arm, Quadruped). Each sample includes a verified keyframe and redesigned prompt to avoid training set overlap. Metadata such as object, embodiment, and camera view (first/third person) is recorded for granular analysis.
Models are evaluated using I2V generation, with prompts derived from benchmark samples. Commercial, open-source, and robotics-specific models generate videos at standardized resolutions (mostly 720p or 1080p) and frame rates (16–30 fps), with durations typically 4–8 seconds. The authors avoid content overlap by ensuring evaluation videos are excluded from training data and use human annotators to validate prompt logic and image accuracy.
Method
The authors present a comprehensive evaluation framework for robotic video generation, structured around a dual-axis assessment of task completion and visual quality. The overall architecture, as illustrated in the framework diagram, integrates both automated metrics and multimodal large language model (MLLM)-based evaluation to assess generated videos across robotic-specific criteria. The evaluation pipeline begins with the construction of the RoVid-X dataset, which is derived from internet videos through a multi-stage process involving robot video collection, quality filtering, and physical property annotation. This dataset serves as the foundation for evaluating video generation models.
The evaluation framework is divided into two primary components: task completion and visual quality. For task completion, the authors employ MLLMs to assess physical-semantic plausibility and task adherence. The process involves providing the MLLM with contextual information—such as the video viewpoint, a high-level content description, and the identities of the robotic manipulator and manipulated object—alongside a sequence of binary verification questions generated from the original instruction. These questions, structured to reflect causal and temporal dependencies, are derived using a question-chain constructor. The MLLM then evaluates the video frames, which are presented in a 3×2 grid of chronologically ordered frames, to determine the success of each reasoning step and assess the stability, consistency, and physical plausibility of the robot and objects throughout the sequence. This two-part prompt design ensures a structured and interpretable evaluation process.
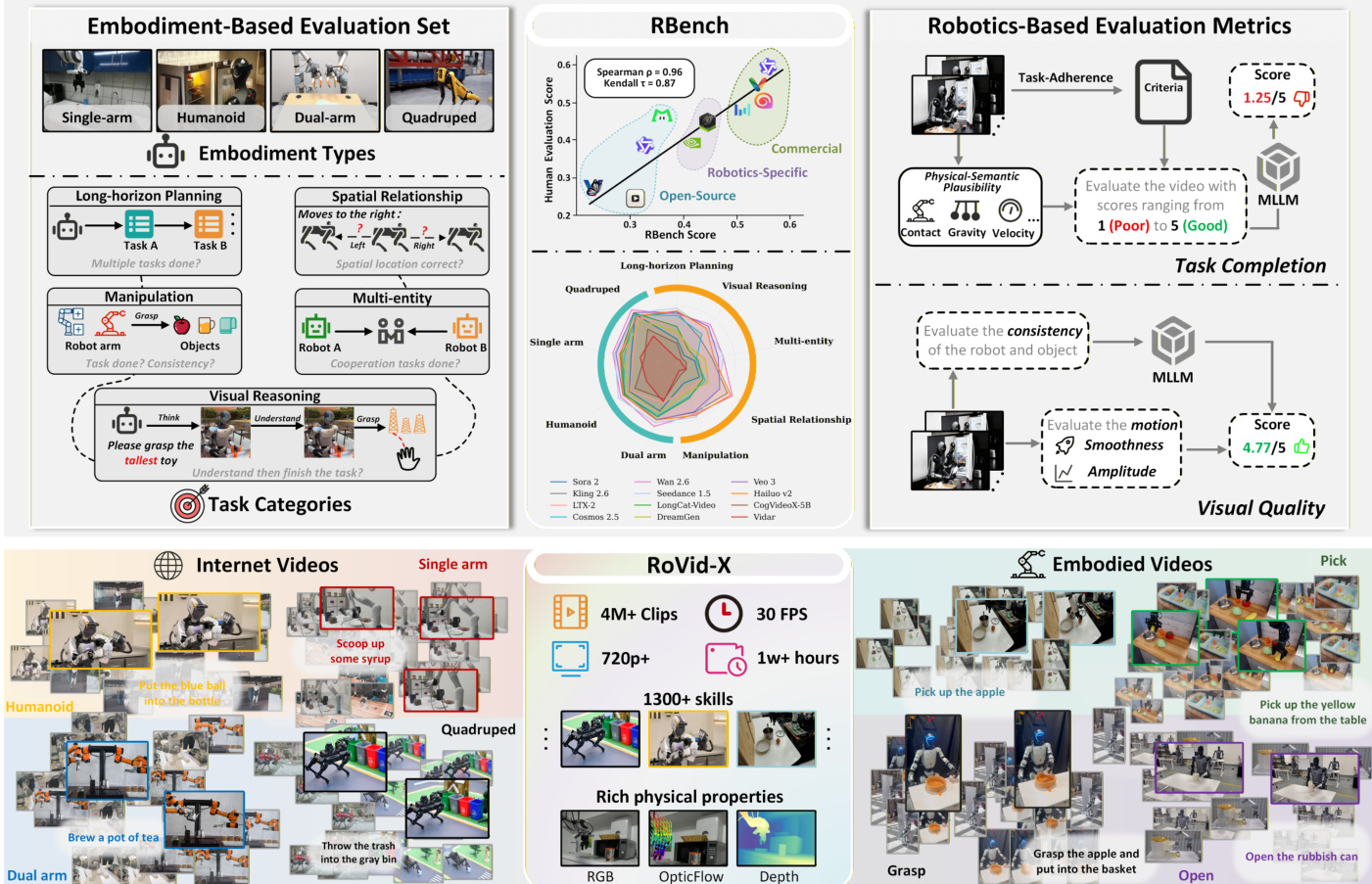
For visual quality, the framework incorporates a suite of automated metrics designed to capture both motion amplitude and motion smoothness. The motion amplitude score (MAS) is computed to measure the perceptible dynamic behavior of the robot while compensating for camera motion. This involves localizing the robot using GroundingDINO, obtaining temporally stable segmentation masks via SAM2, and tracking a dense grid of keypoints within the robot mask using CoTracker. The frame-level displacement of these tracked points is calculated and normalized by the video diagonal. To account for camera-induced movement, a background motion estimate is obtained by applying the same tracking procedure to the inverted robot mask. A soft-zero strategy is then applied to ensure that only motion exceeding background drift is considered, resulting in a compensated displacement that is clipped and averaged to produce the final MAS.
The motion smoothness score (MSS) evaluates the temporal continuity and naturalness of motion, aiming to detect frame-level discontinuities and motion blur artifacts. This metric is based on the motion-smoothness principle from VMBench, using Q-Align aesthetic quality scores to estimate temporal consistency. For each video, a sliding window of frames is processed to obtain a per-frame quality score sequence, and the magnitude of adjacent-frame differences is measured. An adaptive threshold function, determined by the motion amplitude value, is used to detect abnormal temporal variations, ensuring that the threshold is sensitive to the motion intensity of the video. Frames exceeding this threshold are flagged as temporally abnormal, and the final MSS is computed as the proportion of "normal" frames in the sequence. This approach effectively captures both low-level temporal artifacts and high-level motion blur, providing a robust measure of motion quality.
Experiment
- Evaluated 25 state-of-the-art video generation models (closed-source and open-source) on robotic task video generation using RBench, which integrates five fine-grained metrics: Physical-Semantic Plausibility, Task-Adherence Consistency, Motion Amplitude, Robot-Subject Stability, and Motion Smoothness.
- Closed-source models dominate: Wan 2.6 ranks #1 (0.607) and Seedance 1.5 Pro ranks #2, outperforming open-source models like Wan 2.2, highlighting a capability gap in physically grounded generation.
- Models like Sora v2 Pro rank low (17th, 0.362), revealing a media-simulation gap: visually smooth models lack physical fidelity and precise motion control for embodied tasks.
- Iterative scaling improves physical reasoning: Wan 2.1 (0.399) to Wan 2.6 (0.607) and Seedance 1.0 to 1.5 Pro show significant gains, indicating scaling enhances physics understanding.
- Robotics-specific model Cosmos 2.5 outperforms larger open-source models, proving domain data improves resilience, while overly specialized models (Vidar, UnifoLM) rank lowest, underscoring the need for generalizable world knowledge.
- Cognitive and manipulation gaps persist: top models (e.g., Wan 2.6) score lower on Visual Reasoning (0.531) and fine-grained manipulation vs. coarse locomotion tasks.
- RoVid-X dataset finetuning (using Wan2.1/2.2) improves performance across five task domains and four embodiments, validating its effectiveness.
- Qualitative analysis (Figure 5) shows models like Wan 2.5 excel in long-horizon planning, while others fail on task sequence, object identity, or physical plausibility (e.g., LongCat-Video introduces unrealistic human intervention).
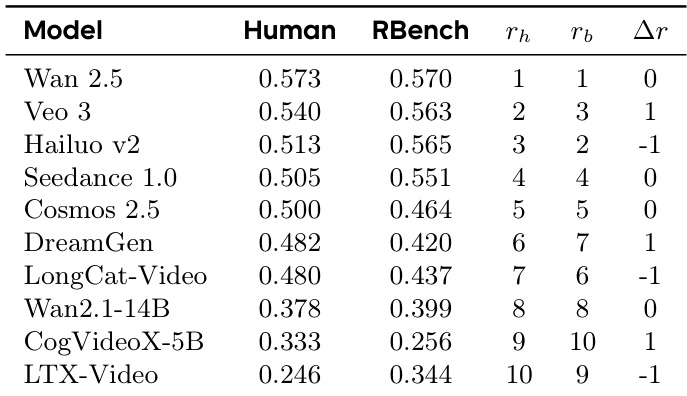
- Human preference scores correlate strongly with RBench scores, confirming metric validity.
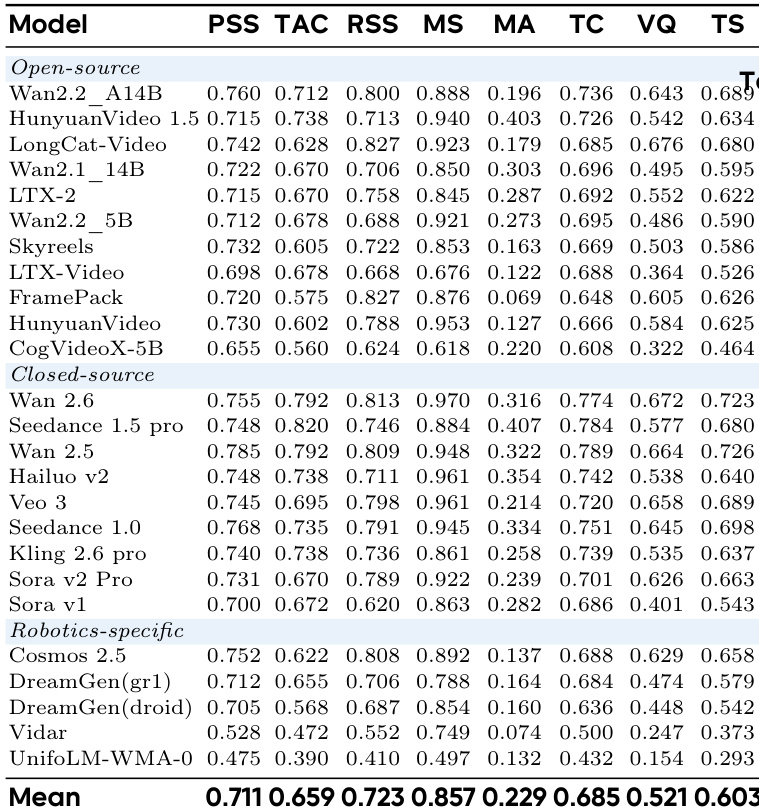
The authors use a quantitative evaluation framework to assess video generation models on physical plausibility and task adherence, with results showing that models like Hailuo and Wan2.5 achieve high mean scores, indicating strong performance in generating physically consistent and task-compliant videos. The analysis reveals that while some models exhibit high mean scores, their performance varies significantly across different metrics, highlighting disparities in their ability to handle complex robotic tasks.
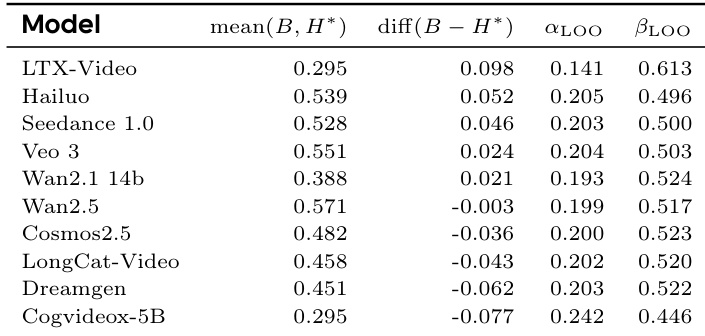
The authors use a comprehensive benchmark to evaluate video generation models on robotic tasks, focusing on task completion and visual quality through metrics like Physical-Semantic Plausibility, Task-Adherence Consistency, and Motion Smoothness. Results show that closed-source models, particularly Wan 2.6, outperform open-source and robotics-specific models, with Wan 2.6 achieving the highest scores across most metrics, indicating a significant performance gap in physical reasoning and task execution.
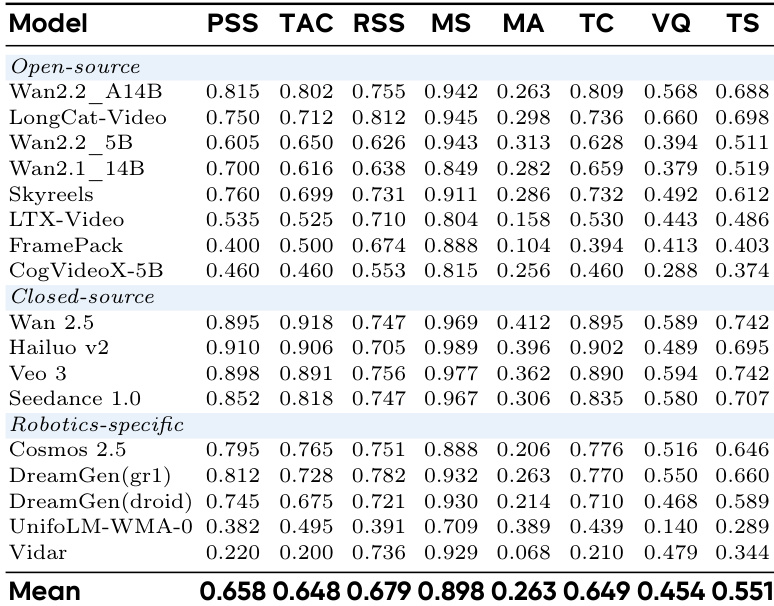
The authors use a comprehensive benchmark to evaluate video generation models on robotic tasks, focusing on task completion and visual quality through metrics like Physical-Semantic Plausibility, Task-Adherence Consistency, and Motion Smoothness. Results show that closed-source models generally outperform open-source and robotics-specific models, with Wan 2.5 achieving the highest scores across most metrics, indicating a strong correlation between model iteration and physical reasoning capabilities.
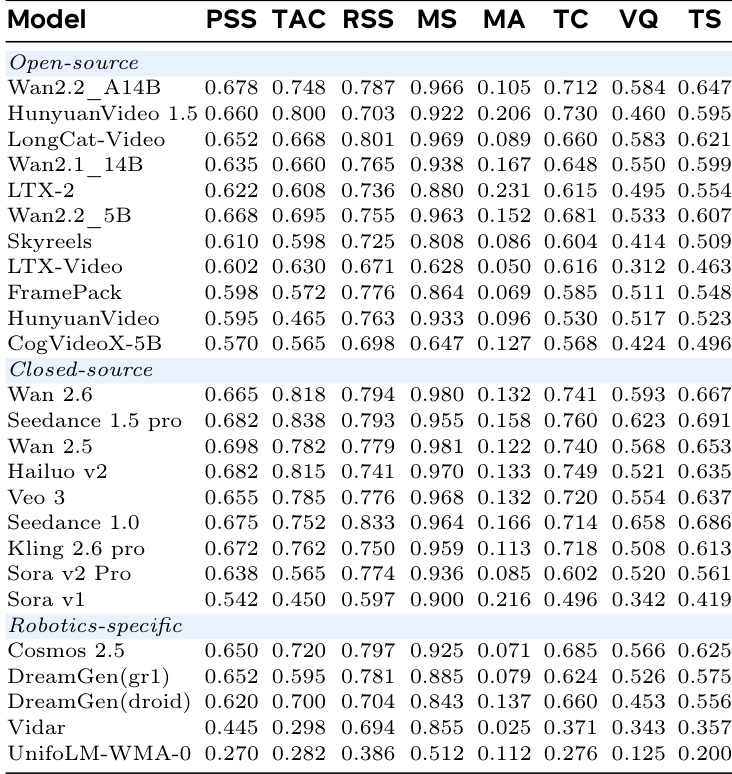
The authors use a comprehensive benchmark to evaluate video generation models on robotic tasks, focusing on both task completion and visual quality. Results show that closed-source models, particularly Wan 2.6, outperform open-source and robotics-specific models across all metrics, with Wan 2.6 achieving the highest scores in Task Completion and Visual Quality, indicating a significant performance gap in physical reasoning and motion fidelity.
The authors use a human evaluation and an automated benchmark (RBench) to assess model performance, with results showing that Wan 2.5 achieves the highest scores in both evaluations, closely followed by Veo 3 and Hailuo v2. The rankings from both human and RBench evaluations are largely consistent, with minor discrepancies in the relative ordering of models, indicating a strong correlation between the two assessment methods.