Command Palette
Search for a command to run...
MMDeepResearch-Bench: 다중모달 심층 연구 에이전트를 위한 벤치마크
MMDeepResearch-Bench: 다중모달 심층 연구 에이전트를 위한 벤치마크
초록
딥 리서치 에이전트(DRAs)는 다단계 검색과 통합을 통해 인용문이 풍부한 보고서를 생성하지만, 기존 벤치마크는 주로 텍스트 중심 환경이나 단순한 다모달 질의응답(QA)에 초점이 맞춰져 있어, 종단간(end-to-end) 다모달 증거 사용을 반영하지 못하고 있다. 이를 보완하기 위해 우리는 21개의 도메인에 걸쳐 전문가가 구성한 총 140개의 과제를 포함하는 MMDeepResearch-Bench(MMDR-Bench)를 제안한다. 각 과제는 이미지-텍스트 복합 패키지를 제공하여, 다모달 이해 능력과 인용 기반 보고서 생성 능력을 평가할 수 있도록 한다. 기존 설정과 달리 MMDR-Bench는 명시적인 증거 활용을 강조하는 보고서 형식의 통합을 중시하며, 모델이 시각적 자료를 출처가 명시된 주장과 연결하고, 서사적 흐름, 인용문, 시각적 참조 간의 일관성을 유지해야 한다. 또한, 보고서 품질 평가를 위한 통합적이고 해석 가능한 평가 파이프라인을 제안한다. 이는 보고서 품질 평가를 위한 Formula-LLM 적응형 평가(FLAE), 인용 기반 증거 일치도 평가를 위한 신뢰성 있는 검색-일치 인용 평가(TRACE), 텍스트-시각 일관성 검증을 위한 다모달 지원-일치 정합성 검사(MOSAIC)로 구성되며, 각각 세부적인 신호를 생성하여 단일 종합 점수를 넘어서 오류 진단을 가능하게 한다. 전 세계 25개 최첨단 모델을 대상으로 한 실험 결과, 생성 품질, 인용 규범, 다모달 기반성 사이에 체계적인 트레이드오프가 존재함을 확인했으며, 풍부한 서사적 표현만으로는 충실한 증거 활용이 보장되지 않으며, 다모달 정합성은 딥 리서치 에이전트의 핵심 과제로 남아 있음을 시사한다.
One-sentence Summary
Researchers from OSU, Amazon, UMich, and others introduce MMDeepResearch-Bench, a multimodal benchmark with 140 expert tasks evaluating citation-grounded report synthesis, and propose FLAE, TRACE, and MOSAIC for granular evaluation, revealing critical gaps in evidence fidelity and multimodal alignment for deep research agents.
Key Contributions
- We introduce MMDR-Bench, a first-of-its-kind benchmark with 140 expert-curated, multimodal tasks across 21 domains, designed to evaluate Deep Research Agents’ ability to synthesize long-form reports that integrate visual artifacts with citation-grounded claims, addressing the lack of end-to-end multimodal evaluation in prior work.
- We propose a three-component evaluation pipeline—FLAE for report quality, TRACE for citation alignment, and MOSAIC for text-visual consistency—each delivering interpretable, fine-grained signals to diagnose failures beyond aggregate scores, enabling precise assessment of multimodal grounding and evidence fidelity.
- Experiments across 25 state-of-the-art models reveal persistent trade-offs between prose quality, citation discipline, and multimodal integrity, with results showing that strong narrative output does not imply faithful evidence use, and visual grounding remains a critical bottleneck for current research agents.
Introduction
The authors leverage recent advances in large multimodal models to address the growing need for agents that can perform deep, evidence-based research across both text and visual data. Prior benchmarks either focus on text-only report generation or short-form multimodal QA, failing to evaluate how well systems integrate visual evidence into long-form, citation-rich synthesis — a critical gap for real-world research workflows. Their main contribution is MMDeepResearch-Bench (MMDR-Bench), a 140-task benchmark with expert-crafted image-text bundles spanning 21 domains, paired with a three-part evaluation framework: FLAE for report quality, TRACE for citation fidelity, and MOSAIC for text-visual consistency — together enabling granular diagnosis of agent failures beyond single scores.
Dataset

-
The authors define MMDR-Bench as a multimodal deep research benchmark consisting of 140 expert-crafted tasks across 21 domains, split into two regimes: Daily (40 tasks across 11 domains) and Research (100 tasks across 10 domains). Daily tasks use casual visuals like screenshots and UI captures, while Research tasks use structured visuals like charts and tables requiring deeper synthesis.
-
Each task is an image-text bundle: a textual query paired with a variable number of images that must be interpreted and cited in a generated report. Tasks are curated by domain experts and refined through checks for clarity, multimodal necessity (images must be essential), and evidence grounding (reports must be verifiable via citations).
-
The benchmark is multilingual, primarily in English and Chinese, with additional languages in the long tail. Tasks are annotated for difficulty (easy, hard, complex) and packaged with metadata including language and visual modality type.
-
The authors use the full 140-task set as an evaluation benchmark — not for training. No training split or mixture ratios are applied; the dataset serves as a fixed test suite to evaluate multimodal understanding and evidence-grounded report generation with citations. No cropping or preprocessing is mentioned beyond the expert curation and annotation steps.
Method
The evaluation framework for long-form deep research reports is structured around three primary modules: FLAE (Formula-LLM Adaptive Evaluation), TRACE (Trustworthy Retrieval-Aligned Citation Evaluation), and MOSAIC (Multimodal Support-Aligned Integrity Check). These modules operate in parallel on the generated report, each assessing distinct aspects of quality, and are integrated through a gating mechanism to produce a final score. The overall pipeline begins with a multimodal deep research report generated by an agent, which is then processed by each of the three evaluators. The outputs from FLAE, TRACE, and MOSAIC are passed through a multimodal gate that determines whether the report meets a minimum threshold for each module, with the final score being computed only if all gates are activated.
FLAE evaluates the report on three task-agnostic dimensions: Readability (READ.), Insightfulness (INSH.), and Structural Completeness (STRU.). This evaluation is conducted through a dual-channel approach. The formula-based channel computes per-dimension scores using a set of lightweight, directly observable text features ϕ(R), such as lexical diversity, sentence-length distribution, and compliance indicators like the presence of a references section. These features are mapped to scores via fixed, auditable transforms defined by linear models with sigmoid activation and clipping, ensuring reproducibility. The LLM judge channel uses a calibrated prompt to generate per-dimension scores based on the task and report. To combine these channels, FLAE employs an adaptive fusion mechanism. A judge LLM calculates a fusion coefficient α(t,R) that controls the mix between the formula and judge scores, with the coefficient constrained to depend only on model-agnostic signals like report length and formatting compliance. This adaptive fusion is designed to mitigate bias and ensure the final score is a balanced combination of objective metrics and expert judgment. The final FLAE score is a weighted sum of the fused per-dimension scores, where the weights are task-adaptive and determined by a separate judge LLM prompt.
TRACE assesses the report's grounding in cited sources and its faithfulness to the task. It first parses the report to extract claim-URL pairs, mapping each citation to its corresponding source. For accessible sources, a judge LLM verifies the support for each claim, accounting for evidence consistency, coverage, and textual fidelity. This process yields three citation-fidelity metrics: Consistency (Con.), Coverage (Cov.), and Textual Fidelity (FID.). Additionally, TRACE includes a strict visual evidence fidelity (VEF.) check to ensure the report correctly interprets and answers the task's visual requirements. The VEF. score is a discrete value from 0 to 10, and a PASS/FAIL verdict is enforced by a fixed threshold of 6, making this component auditable and consistent across different judge models. The final TRACE score is a weighted combination of the VEF. score and the other three metrics, with the weights being task-adaptive.
MOSAIC evaluates the integrity of the report's multimodal content by verifying that image-referenced statements are faithful to the underlying visuals. It begins by parsing the report to extract multimodal items (MM-items), which include text that references images and the images themselves. These items are then routed to a type-specific evaluator based on their visual modality—photo, data chart, or diagram—using a lightweight router. Each item is scored on three dimensions: Visual-Semantic Alignment (SEM.), Visual Data Interpretation Accuracy (ACC.), and Complex Visual Question Answering Quality (vQA). The item-level score is computed by a weighted aggregation of these dimension scores. The final MOSAIC score is derived from the item-level scores, and the module's activation is gated by the performance of the other two evaluators.
Experiment
- Evaluated multimodal Deep Research agents via MMDR-Bench, combining FLAE (20%), TRACE (50%), and MOSAIC (30%) with gated activation; Gemini-2.5-Pro served as judge LLM.
- Gemini Deep Research ranked first overall, excelling in evidence quality (TRACE) and maintaining strong multimodal alignment (MOSAIC); Gemini 3 Pro (Preview) led non-agent web-enabled models.
- Vision improves performance only when reliably grounded; adding vision to Qwen 3 models increased fine-grained extraction errors (e.g., misreading numerals, labels), revealing prompt-fidelity bottlenecks.
- Multimodal alignment and citation grounding can diverge: Gemini Deep Research improved evidence coverage but saw increased entity misattribution during multi-step synthesis.
- Tool use amplifies strong backbones but doesn’t replace them; Tongyi Deep Research (30B) underperformed larger models, while Gemini Deep Research (Gemini 3 Pro) combined high coverage and overall strength.
- On Research tasks, Gemini Deep Research and Gemini 3 Flash led broadly; GPT-5.2 excelled in Computer & Data Science; Qwen 3 VL dominated Environment & Energy via chart/diagram grounding.
- Human evaluation (12 experts, 140 tasks) confirmed evaluator alignment: full system outperformed vanilla judges; VEF. and MOSAIC improved human consistency (PAR/OPC metrics).
- Cross-judge tests (GPT-5.2 vs Gemini-2.5-Pro) showed stable overall scores (±0.30 points) despite per-module variance; MOSAIC remained highly consistent across judges.
- VEF. uses strict task-specific visual ground truth (PASS/FAIL at score ≥6); identity errors force immediate FAIL; pass-rate reported as % over tasks (e.g., 38.57% = 38.57% pass rate).
- Failure analysis revealed: vision-enabled models increase DTE (detail extraction errors); agentic systems increase EMI (entity misidentification) due to drift across multi-step synthesis.
The authors use a multimodal evaluation framework to assess Deep Research agents, with results showing that Gemini-2.5-Pro achieves higher scores than GPT-5.2 across most metrics, particularly in AVG FLAE and AVG MMDR with VEF. inclusion. GPT-5.2 performs better in AVG TRACE and AVG MMDR without VEF., indicating stronger evidence quality but lower visual fidelity, while Gemini-2.5-Pro maintains more consistent multimodal alignment and overall performance.
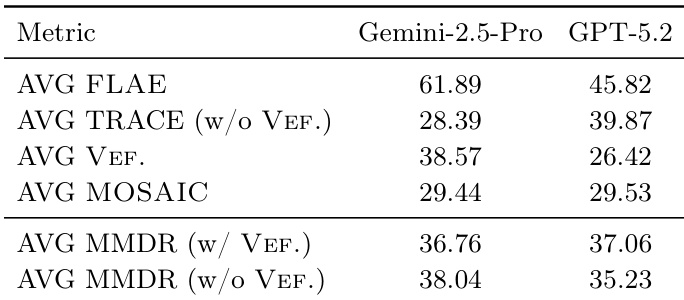
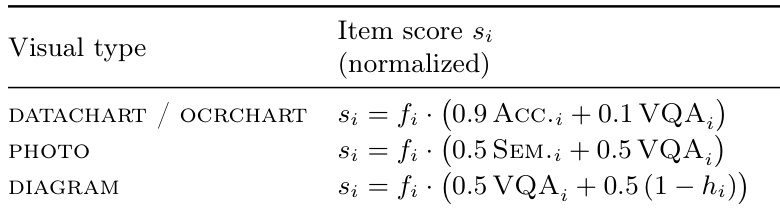
The authors use a normalized scoring system for visual items in the MOSAIC evaluation, where the score for each visual type is computed as a weighted combination of a feature score and a quality metric. For datacharts and ocrcharts, the score is based on accuracy and visual quality, while for photos it combines semantic and visual quality, and for diagrams it balances visual quality with a binary indicator of structural correctness.
The authors evaluate the alignment between their automated evaluator and expert judgments by comparing pairwise preferences and score correlations across 140 tasks. Results show that the full evaluator, which uses a fusion coefficient derived from judge outputs, achieves higher agreement with experts (PAR 73.5, OPC 96.4) than a formula-only or judge-only baseline, indicating that the fusion approach better captures human preferences.

The authors use a human consistency check to evaluate alignment between their automated evaluator and expert judgments on multimodal reports. Results show that the full MMDR-Bench-Eval system achieves higher pairwise agreement (PAR) and score correlation (OPC) with experts compared to a vanilla prompt-based judge, indicating improved human-aligned scoring. Removing MOSAIC reduces performance, while omitting VEF. has a smaller impact, suggesting both components contribute to more accurate evaluation.

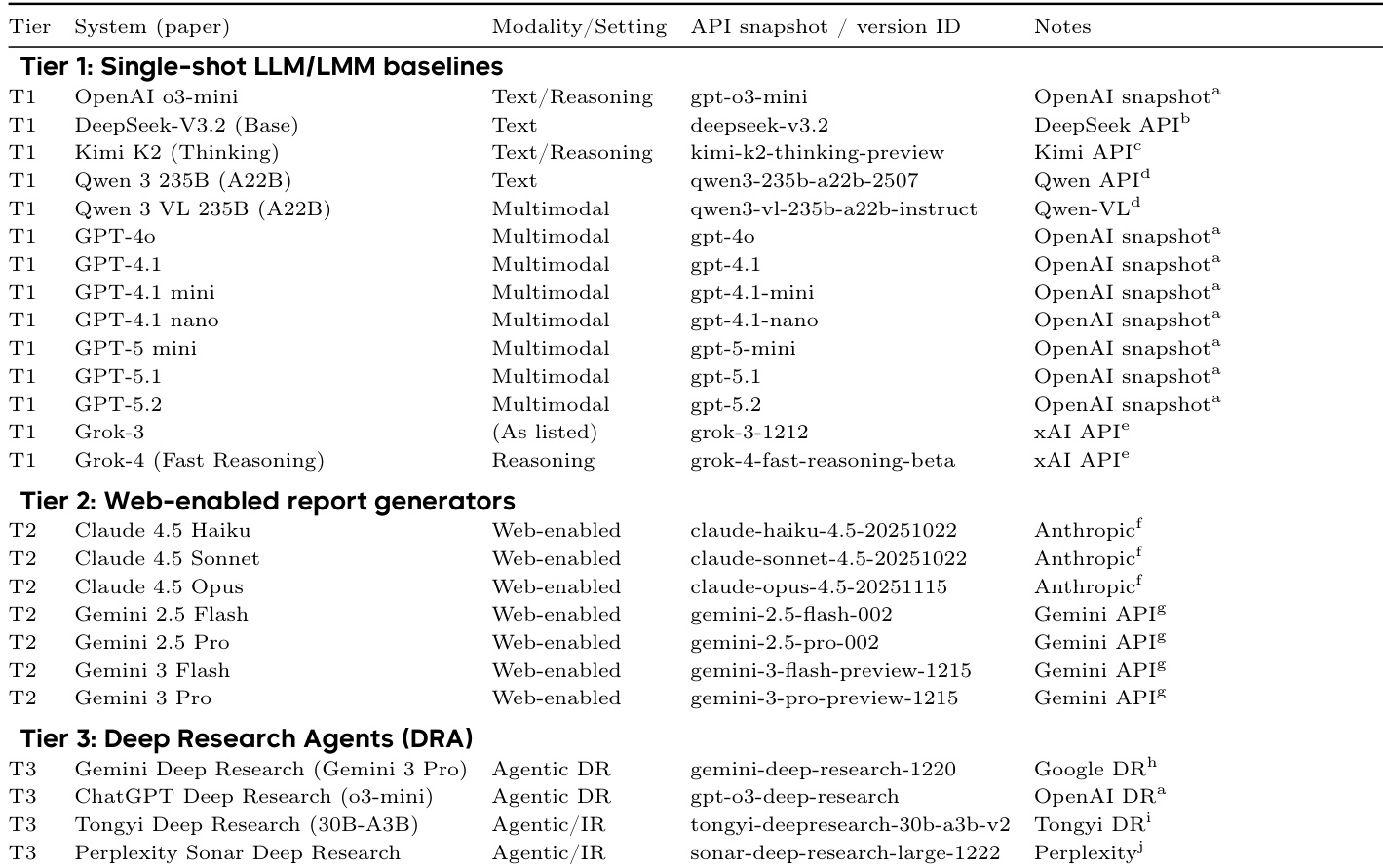
The authors use a three-tier evaluation framework to assess multimodal deep research agents, with Tier 1 consisting of single-shot LLM/LMM baselines, Tier 2 of web-enabled report generators, and Tier 3 of dedicated deep research agents. Results show that Gemini Deep Research (Gemini 3 Pro) achieves the highest overall score, driven by strong evidence quality and multimodal alignment, while also demonstrating that vision and tool use provide benefits only when reliable and well-integrated into the system.