Command Palette
Search for a command to run...
TwinBrainVLA: 비대칭 트랜스포머 믹스를 통한 일반화된 VLM의 잠재력 발휘: 신체적 임무를 위한 접근
TwinBrainVLA: 비대칭 트랜스포머 믹스를 통한 일반화된 VLM의 잠재력 발휘: 신체적 임무를 위한 접근
초록
표준 시각-언어-행동(VLA) 모델은 일반적으로 로봇 제어를 위해 단일화된 시각-언어 모델(VLM) 백본을 명시적으로 미세조정한다. 그러나 이러한 접근 방식은 고수준의 일반적 의미 이해 능력 유지와 저수준의 세밀한 센서모터 기술 학습 사이에 근본적인 갈등을 초래하며, 모델의 오픈월드 능력에 대한 '비극적 망각(catastrophic forgetting)'을 유발하는 경우가 많다. 이 갈등을 해결하기 위해 우리는 일반적 VLM(일반화된 시각적 이해 능력을 유지)과 몸체적 본체감각(embodied proprioception)에 특화된 전문 VLM(전문적 인식)을 함께 활용하여 공동 로봇 제어를 수행하는 새로운 아키텍처인 TwinBrainVLA를 제안한다. TwinBrainVLA는 고정된 '좌뇌(Left Brain)'와 훈련 가능한 '우뇌(Right Brain)'를 협력시키는 새로운 비대칭 트랜스포머 혼합기법(Asymmetric Mixture-of-Transformers, AsyMoT)을 통해, 좌뇌는 견고한 일반적 시각적 추론 능력을 유지하고, 우뇌는 몸체적 인식에 특화되어 동작을 제어한다. 이 설계는 우뇌가 고정된 좌뇌로부터 동적으로 의미 지식을 질의하고, 이를 본체감각 상태와 융합함으로써, 흐름 매칭 기반 동작 전문가(Flow-Matching Action Expert)가 정밀한 연속적 제어를 생성할 수 있도록 풍부한 조건을 제공한다. SimplerEnv 및 RoboCasa 벤치마크에서 수행한 광범위한 실험 결과는 TwinBrainVLA가 최신 기준 모델보다 우수한 조작 성능을 달성하면서도, 사전 학습된 VLM의 포괄적인 시각적 이해 능력을 명시적으로 유지함을 입증하였으며, 고수준의 의미 이해와 저수준의 물리적 민첩성을 동시에 달성할 수 있는 일반 목적 로봇 구축을 위한 유망한 방향성을 제시한다.
One-sentence Summary
Researchers from HIT, ZGCA, and collaborators propose TwinBrainVLA, a dual-brain VLA architecture using AsyMoT to fuse frozen semantic understanding with trainable proprioception, enabling robots to master precise control without forgetting open-world vision, validated on SimplerEnv and RoboCasa.
Key Contributions
- TwinBrainVLA introduces a dual-stream VLA architecture that decouples general semantic understanding (frozen Left Brain) from embodied perception (trainable Right Brain), resolving the catastrophic forgetting caused by fine-tuning monolithic VLMs for robotic control.
- It employs an Asymmetric Mixture-of-Transformers (AsyMoT) mechanism to enable dynamic cross-stream attention between the two VLM pathways, allowing the Right Brain to fuse proprioceptive states with semantic knowledge from the Left Brain for precise action generation.
- Evaluated on SimplerEnv and RoboCasa, TwinBrainVLA outperforms state-of-the-art baselines in manipulation tasks while preserving the pre-trained VLM’s open-world visual understanding, validating its effectiveness for general-purpose robotic control.
Introduction
The authors leverage a dual-brain architecture to resolve the core conflict in Vision-Language-Action (VLA) models: the trade-off between preserving general semantic understanding and acquiring precise sensorimotor control. Prior VLA approaches fine-tune a single VLM backbone for robotics, which often causes catastrophic forgetting of open-world capabilities—undermining the very generalization they aim to exploit. TwinBrainVLA introduces an asymmetric design with a frozen “Left Brain” for semantic reasoning and a trainable “Right Brain” for embodied perception, fused via a novel Asymmetric Mixture-of-Transformers (AsyMoT) mechanism. This enables the system to generate accurate continuous actions while explicitly retaining the pre-trained VLM’s broad visual and linguistic understanding, validated across SimplerEnv and RoboCasa benchmarks.
Method
The authors leverage a dual-stream architecture to disentangle high-level semantic reasoning from fine-grained sensorimotor control, addressing the challenge of catastrophic forgetting in vision-language models for embodied tasks. The framework, named TwinBrainVLA, consists of two distinct pathways: a frozen "Left Brain" and a trainable "Right Brain," which interact through a novel Asymmetric Mixture-of-Transformers (AsyMoT) mechanism. The Left Brain functions as a generalist, preserving open-world visual-linguistic knowledge, while the Right Brain specializes in embodied motor control, integrating visual, textual, and proprioceptive inputs. This separation enables the model to maintain general semantic capabilities while allowing the control stream to adapt to specific robotic tasks without interference.
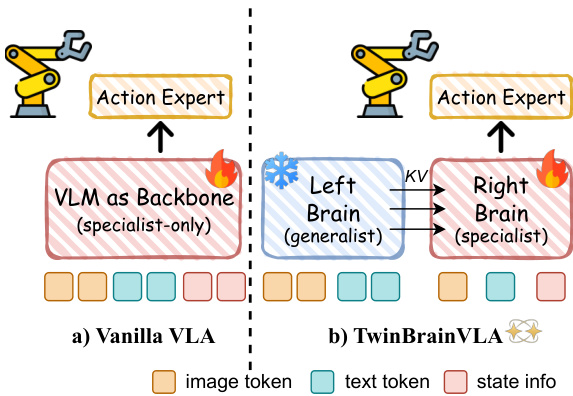
As shown in the figure below, the overall architecture of TwinBrainVLA features an asymmetric dual-stream design. The Left Brain processes only visual and textual inputs, receiving a sequence of image and text tokens derived from the vision encoder V(I) and text tokenizer T(T). This stream remains frozen during training, ensuring that its pre-trained semantic knowledge is preserved. In contrast, the Right Brain processes a multimodal input sequence that includes visual tokens, text tokens, and a projection of the robot's proprioceptive state s, encoded by a lightweight MLP state encoder ϕ. This design allows the Right Brain to ground its reasoning in the robot's physical configuration, a critical requirement for closed-loop control.
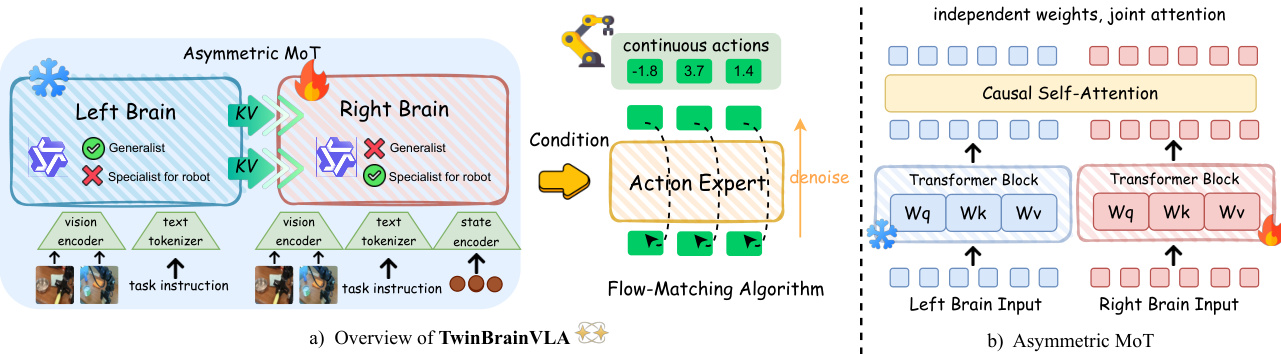
The core innovation lies in the AsyMoT mechanism, which enables the Right Brain to attend to the frozen key-value (KV) pairs of the Left Brain while maintaining its own trainable parameters. At each layer, the Left Brain computes its hidden states independently using its frozen self-attention mechanism. The Right Brain, however, employs an asymmetric joint attention mechanism where its query QR attends to a concatenated key and value set formed by the Left Brain's KV pairs (with stop-gradient applied) and its own KV pairs. This asymmetric flow ensures that the Right Brain can leverage high-level semantic features from the Left Brain without corrupting them, establishing a strict hierarchy where the Left Brain acts as a stable semantic anchor.
The final hidden states of the Right Brain, HRfinal, are passed to an Action Expert, which generates continuous robotic actions. The Action Expert is a Diffusion Transformer (DiT) architecture trained via a flow-matching objective. It operates as a conditional decoder that denoises a noisy action trajectory, conditioned on the Right Brain's representations. The flow-matching loss is defined as the expected squared error between the DiT's predicted vector field and the straight-line target vector field from a standard Gaussian prior to the ground-truth action distribution. During inference, actions are synthesized by solving the corresponding ordinary differential equation.
The training strategy is designed to preserve the generalist capabilities of the Left Brain. The total loss is solely the flow-matching loss, minimizing the discrepancy between the generated and ground-truth actions. The optimization is constrained by an asymmetric update rule: gradients are blocked at the AsyMoT fusion layer, preventing any backpropagation into the Left Brain's parameters. This ensures that the Right Brain and the state encoder can specialize in control dynamics, while the frozen Left Brain implicitly safeguards the model's general semantic priors.
Experiment
- Evaluated TwinBrainVLA on SimplerEnv and RoboCasa simulation benchmarks using 16× H100 GPUs under starVLA framework; training followed default protocols for fair comparison.
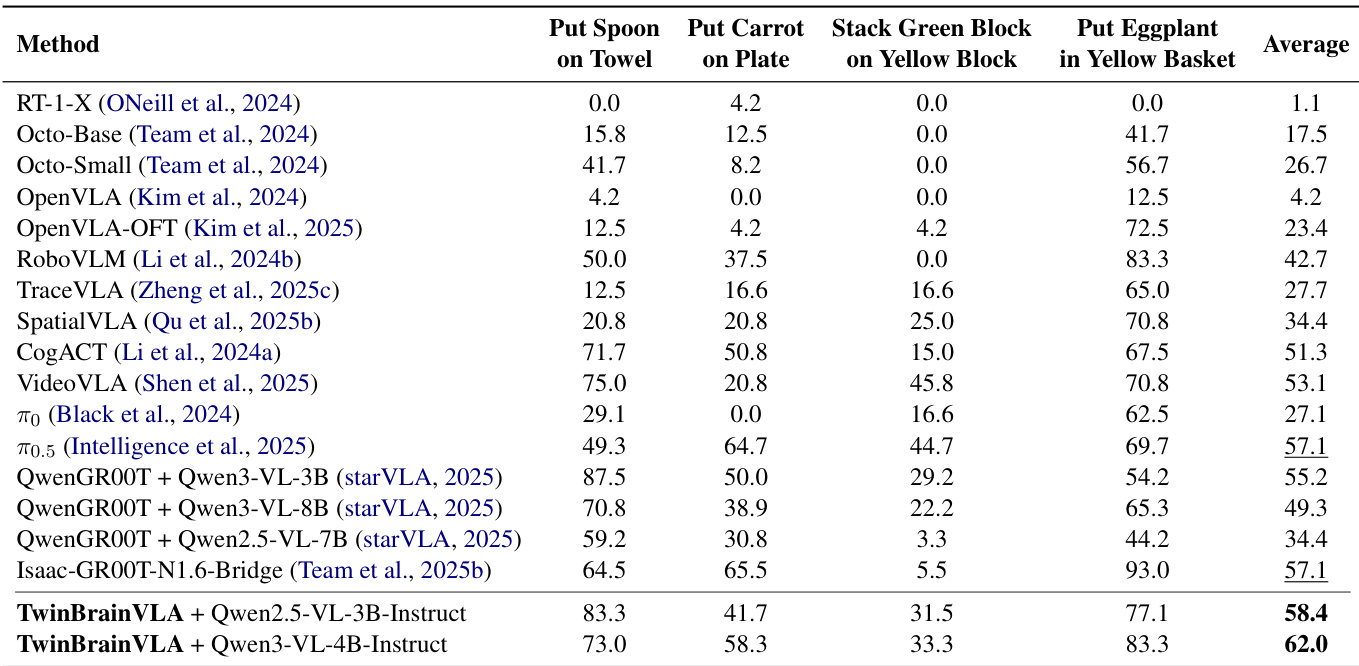
- On SimplerEnv with WidowX robot, TwinBrainVLA (Qwen3-VL-4B-Instruct) achieved 62.0% success rate across 4 tasks, surpassing Isaac-GR00T-N1.6 (57.1%) by +4.9%, validating asymmetric dual-brain design.
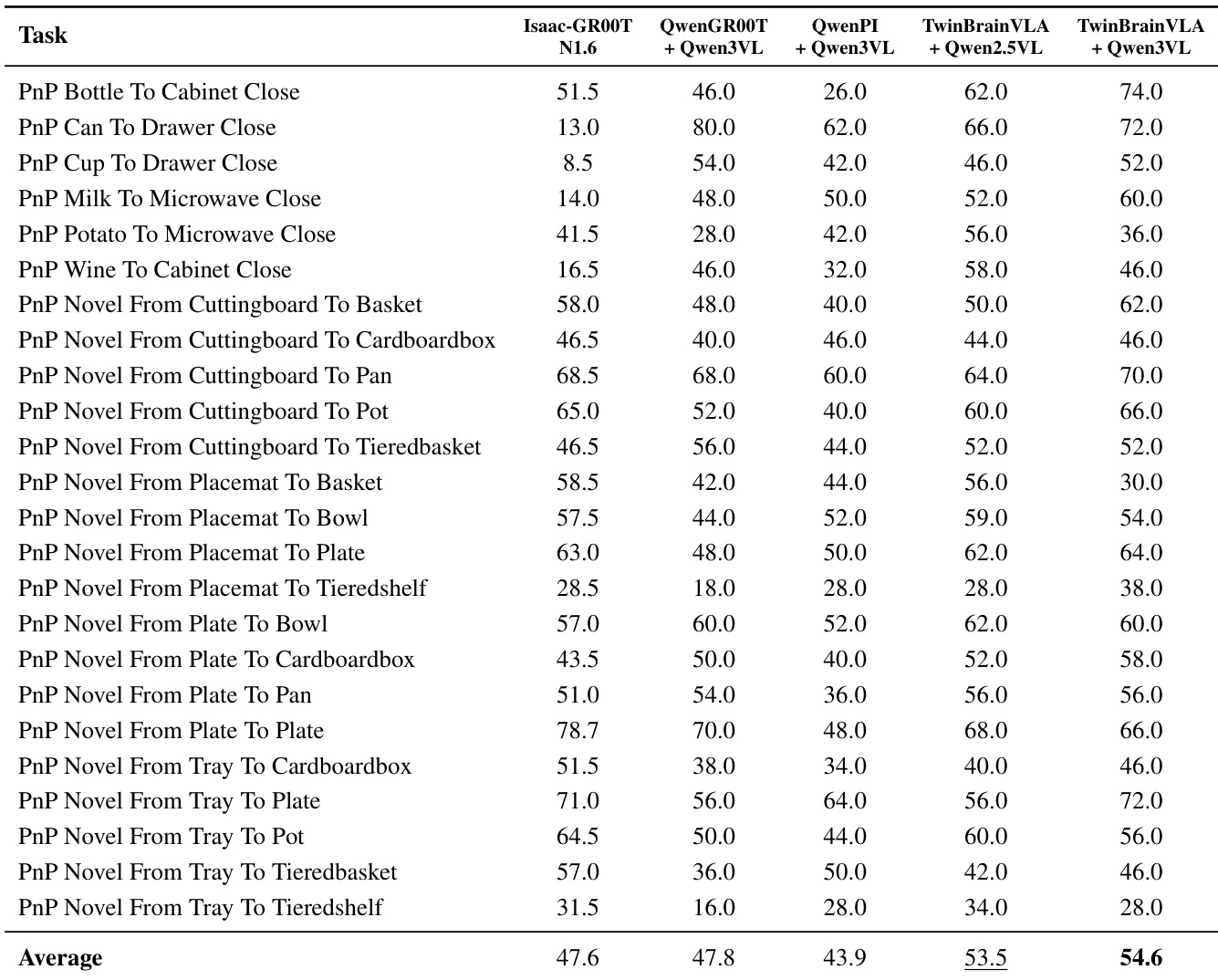
- On RoboCasa GR1 Tabletop Benchmark (24 tasks), TwinBrainVLA (Qwen3-VL-4B-Instruct) reached 54.6% Avg@50 success rate, outperforming Isaac-GR00T-N1.6 (47.6%) by +7.0%, QwenGR00T (47.8%) by +6.8%, and QwenPI (43.9%) by +10.7%.
- Model trained on Bridge-V2 and Fractal subsets of OXE dataset; uses AdamW, 40k steps, 1e-5 LR, DeepSpeed ZeRO-2, and gradient clipping; supports Qwen2.5-VL-3B and Qwen3-VL-4B backbones.
The authors use TwinBrainVLA with Qwen3-VL-4B-Instruct to achieve the highest average success rate of 54.6% on the RoboCasa GR1 Tabletop Benchmark, outperforming all baselines including Isaac-GR00T-N1.6 by 7.0 percentage points. Results show that the asymmetric dual-brain architecture enables superior performance in complex tabletop manipulation tasks compared to models trained with the same dataset and backbone.
The authors use TwinBrainVLA with Qwen2.5-VL-3B-Instruct and Qwen3-VL-4B-Instruct backbones to evaluate performance on SimplerEnv, achieving state-of-the-art results with success rates of 58.4% and 62.0% respectively. Results show that TwinBrainVLA surpasses the strongest baseline, Isaac-GR00T-N1.6, by +4.9% on average, demonstrating the effectiveness of its asymmetric dual-brain architecture in combining high-level semantic understanding with low-level robotic control.