Command Palette
Search for a command to run...
SWE-Pruner: 코드 에이전트를 위한 자기적응형 컨텍스트 프루닝
SWE-Pruner: 코드 에이전트를 위한 자기적응형 컨텍스트 프루닝
Yuhang Wang Yuling Shi Mo Yang Rongrui Zhang Shilin He Heng Lian Yuting Chen Siyu Ye Kai Cai Xiaodong Gu
초록
LLM 에이전트는 소프트웨어 개발 분야에서 놀라운 능력을 보여주고 있으나, 긴 상호작용 컨텍스트로 인해 높은 API 비용과 지연 시간이 발생하여 성능이 저하되는 문제가 있다. 다양한 컨텍스트 압축 기법(예: LongLLMLingua)이 이 문제를 해결하기 위해 등장했지만, 대부분 PPL과 같은 고정된 메트릭에 의존하며 코드 이해의 작업 특수성은 무시한다. 그 결과, 문법적 및 논리적 구조가 자주 파손되고 중요한 구현 세부 정보를 유지하지 못하는 경우가 많다. 본 논문에서는 코딩 에이전트에 특화된 자가 적응형 컨텍스트 프루닝 프레임워크인 SWE-Pruner을 제안한다. 개발 및 디버깅 과정에서 인간 프로그래머가 소스 코드를 '선택적으로 스크린'하는 방식에서 영감을 얻어, SWE-Pruner은 긴 컨텍스트에 대해 작업 인식형 적응적 프루닝을 수행한다. 현재 작업을 기반으로 에이전트는 '에러 처리에 집중한다'와 같이 명시적인 목표를 설정하여 프루닝 대상을 안내한다. 이 목표를 바탕으로, 가벼운 신경 스크리머(0.6B 파라미터)가 동적으로 관련 있는 코드 줄을 주변 컨텍스트에서 선택한다. 네 가지 벤치마크와 다양한 모델을 대상으로 한 평가를 통해 SWE-Pruner의 효과성을 검증하였으며, SWE-Bench Verified과 같은 에이전트 작업에서는 토큰 수를 23~54%까지 줄였고, LongCodeQA와 같은 단일턴 작업에서는 최대 14.84배의 압축을 달성하면서 성능 저하를 최소화하였다.
One-sentence Summary
Researchers from Shanghai Jiao Tong University, Sun Yat-sen University, and Douyin Group propose SWE-Pruner, a task-aware context pruning framework for coding agents that uses a lightweight neural skimmer to retain critical code details, reducing tokens by 23–54% with minimal performance loss across benchmarks like SWE-Bench Verified.
Key Contributions
- SWE-Pruner introduces a task-aware, line-level context pruning framework for coding agents, addressing the "context wall" by dynamically preserving syntactically and logically critical code based on explicit natural language goals like “focus on error handling”.
- It employs a lightweight 0.6B-parameter neural skimmer trained on 61K synthetic examples to adaptively select relevant lines, enabling efficient, goal-conditioned compression without repository-specific tuning or structural degradation.
- Evaluated across four benchmarks including SWE-Bench Verified and LongCodeQA, it achieves 23–54% token reduction on multi-turn agent tasks and up to 14.84× compression on single-turn tasks with minimal performance loss, while also reducing agent interaction rounds by up to 26%.
Introduction
The authors leverage the growing use of LLM agents in software engineering, where long context windows create costly and noisy interactions that degrade performance. Prior context compression methods—designed for natural language or static code tasks—fail to preserve syntax, ignore task-specific goals, and lack adaptability across multi-turn agent workflows. SWE-Pruner addresses this by introducing a lightweight, goal-conditioned pruning model that dynamically selects relevant code lines based on the agent’s current objective, preserving structure while achieving 23–54% token reduction on agent tasks and up to 14.8x compression on single-turn tasks with minimal performance loss.
Dataset

-
The authors use GitHub Code 2025 — a curated corpus of 1.5M+ repositories — as the base source, selecting both high-star (established) and 2025-era (emerging) repos to balance quality and novelty. Binary files, build artifacts, and minified code are stripped to retain clean, polyglot source code.
-
From this, they sample 200,000 code snippets across 195,370 files and 5,945 repos, generating queries and line-level retention masks using Qwen3-Coder-30B-A3B-Instruct (temperature 0.7, top-p 0.9). Tasks are balanced across 9 agentic types (e.g., code summarize, debug, optimize), 3 snippet lengths, and 3 relevance levels.
-
A quality filter using Qwen3-Next-80B-A3B-Thinking as an LLM judge retains only ~1/6 of samples (61,184 final training samples) based on reasoning quality, annotation consistency, and task alignment. Average query length is 39.98 words (median 24), with 291.69 characters per query (median 169).
-
The dataset trains a neural skimmer to prune code contextually; during inference, the model processes code snippets with line-level retention masks aligned to task-specific queries. No cropping is applied during training, but inference may involve chunking with 50-token overlap and 500-char minimum, using a 0.5 threshold via a local pruner service.
-
Metadata includes task type, snippet length, relevance level, and line-level retention labels. The pipeline ensures diverse, realistic supervision for agentic coding tasks, with generation and filtering prompts detailed in the paper’s appendix.
Method
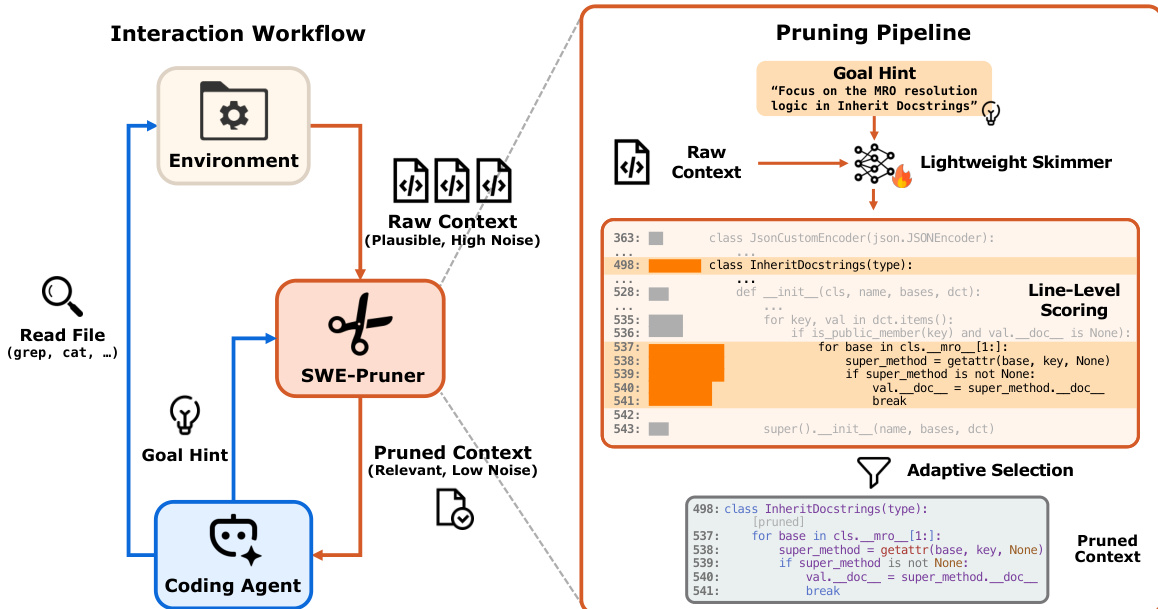
The SWE-Pruner framework operates as middleware between a coding agent and its environment, intercepting raw context from file operations and delivering a pruned, relevant subset to the agent. The interaction workflow begins when the coding agent issues a file-reading command, such as grep or cat, to the environment. The raw context, often extensive and noisy, is captured by SWE-Pruner. Concurrently, the agent generates a Goal Hint—a natural language description of its current information need, such as "Focus on the MRO resolution logic in InheritDocstrings." This hint, along with the raw context, is fed into the lightweight skimmer for processing. The skimmer evaluates the context and returns a pruned context, which is then passed back to the agent for further reasoning. This process enables the agent to focus on relevant code segments while minimizing noise and computational overhead.
The core of SWE-Pruner is the lightweight skimmer, which is built upon the Qwen3-Reranker-0.6B backbone. The skimmer processes the raw context and the goal hint to compute relevance scores for each token. The model architecture is designed to perform two tasks simultaneously: line-level pruning and document-level reranking. For pruning, the model computes a relevance score si for each token xi using a neural scoring function F(q,xi∣C;θ), where q is the goal hint and C is the full context. These token scores are aggregated to the line level by averaging the scores of all tokens within a line, resulting in a line-level relevance score sˉj. This aggregation ensures that lines are evaluated based on their overall relevance rather than being dominated by a few high-scoring tokens, maintaining semantic coherence.
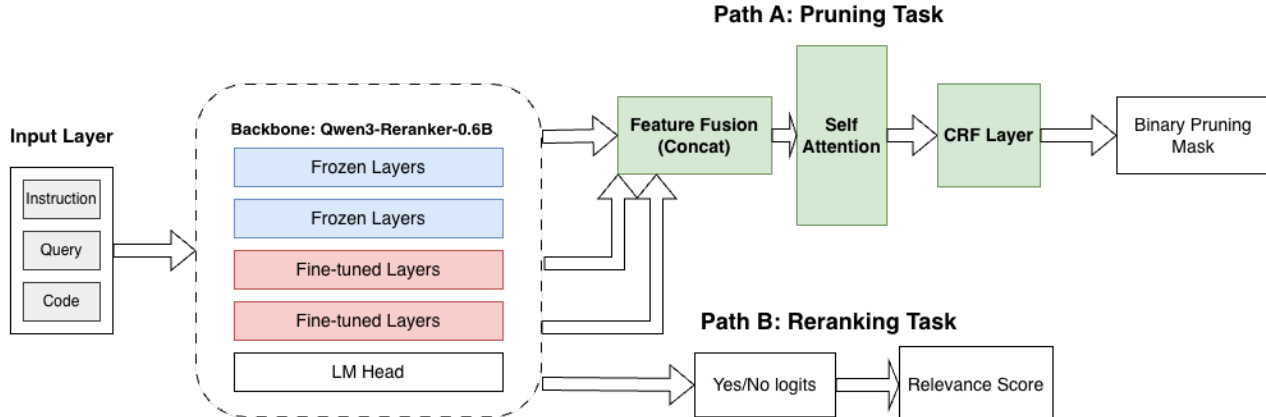
The pruning task is formulated as a structured sequence labeling problem using a Conditional Random Field (CRF). The CRF layer computes emission and transition potentials to model the dependencies between adjacent line-level decisions. Emissions represent the local confidence for each token, while transitions capture the dependencies between adjacent decisions. This structured formulation encourages coherent pruning patterns that respect syntactic boundaries. The reranking task, on the other hand, reuses the original language modeling head from Qwen3-Reranker to produce a scalar relevance score for the entire document. The final objective combines both tasks with a balancing weight λ, ensuring that the model can perform both granular pruning and coarse-grained relevance assessment in a single forward pass. The model is trained using a teacher-student paradigm, where a teacher LLM synthesizes task-oriented queries and line-level annotations, enabling the skimmer to learn from high-quality, diverse training data.
Experiment
- Evaluated SWE-Pruner on SWE-Bench Verified (500 GitHub issues) and SWE-QA (3 repos), integrated with Mini SWE Agent and OpenHands using Claude Sonnet 4.5 and GLM-4.6; achieved 23–38% token reduction on SWE-Bench and 29–54% on SWE-QA with <1% success rate drop.
- On SWE-Bench Verified, SWE-Pruner reduced interaction rounds by 18–26% (e.g., 44.2% token reduction and 34.6% fewer rounds for GLM-4.6), enabling faster task completion and lower API costs.
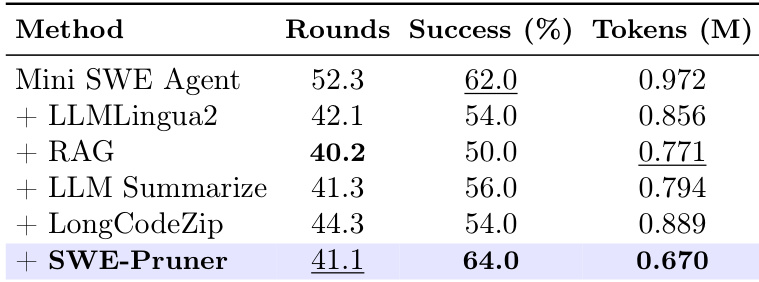
- Outperformed baselines (LLMLingua-2, RAG, LLM Summarize) on SWE-Bench: achieved 64% success rate with 31% fewer tokens vs. 62% baseline; token-level methods degraded performance due to syntax disruption.
- On single-turn tasks (Long Code Completion/QA), SWE-Pruner achieved up to 14.84× compression under 8x constraint while maintaining 58.71% accuracy (QA) and 57.58 ES (completion), outperforming Selective-Context and LongCodeZip.
- Maintained 87.3% AST correctness vs. near-zero for token-level methods, preserving syntactic structure through line-level, query-aware pruning.
- Introduced negligible latency (<100ms TTFT at 8K tokens), amortized by 23–54% token savings and reduced rounds; case studies showed 83.3% token reduction in failure-to-success scenarios and 30.2% peak prompt length reduction in successful trajectories.
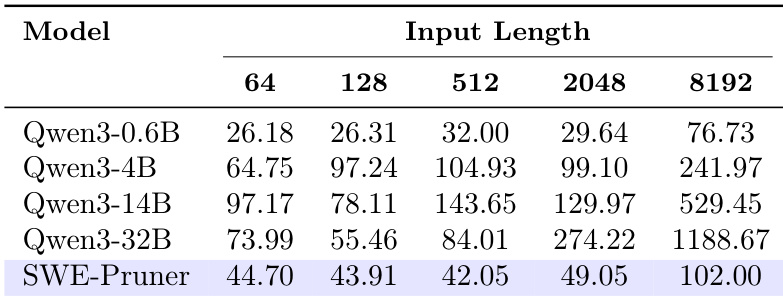
The authors use SWE-Pruner to evaluate its efficiency across different model sizes and input lengths, measuring first token latency. Results show that SWE-Pruner maintains consistently low latency, with values below 100 ms even at 8192 tokens, while larger models like Qwen3-32B exhibit significantly higher and more rapidly increasing latency.
Results show that SWE-Pruner achieves the highest success rate of 64.0% while reducing token consumption to 0.670 million, outperforming all baselines in both task performance and compression efficiency. The method maintains a high success rate with significantly fewer interaction rounds and tokens compared to alternatives like LLMingua2, RAG, and LongCodeZip.
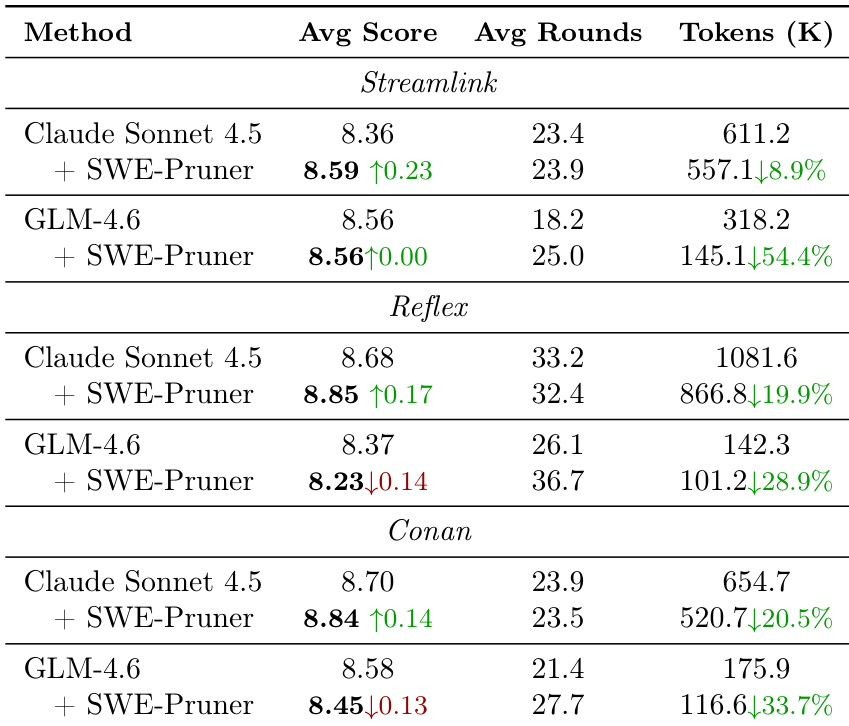
The authors use SWE-Pruner to reduce token consumption in coding agents on SWE-QA tasks across three repositories, achieving 28.9% to 54.4% reductions in tokens while maintaining or slightly improving average scores and reducing interaction rounds. The results show that SWE-Pruner effectively prunes irrelevant context without degrading task performance, enabling more efficient agent behavior.
The authors use SWE-Pruner to reduce token consumption in coding agents by filtering redundant context during file reads. Results show that the pruner reduces token usage by 83.3% and decreases the number of steps from 164 to 56, enabling task completion where the baseline agent fails due to resource exhaustion.

The authors use SWE-Pruner to reduce token consumption in coding agents by filtering redundant context during file reads. Results show that the Pruner reduces token usage by 6% while increasing the number of read operations and decreasing execution steps, indicating more focused exploration with less redundant processing.
