Command Palette
Search for a command to run...
LongCat-Flash-Thinking-2601 기술 보고서
LongCat-Flash-Thinking-2601 기술 보고서
초록
우리는 초거대 규모의 오픈소스 전문가 혼합(Mixture-of-Experts, MoE) 추론 모델인 LongCat-Flash-Thinking-2601을 소개합니다. 이 모델은 5600억 파라미터를 보유하고 있으며, 뛰어난 에이전트형 추론 능력을 지닙니다. LongCat-Flash-Thinking-2601은 에이전트 기반 검색, 에이전트 기반 도구 활용, 도구 통합 추론 등 다양한 에이전트 기반 벤치마크에서 오픈소스 모델 중 최고 성능을 달성했습니다. 벤치마크 성능을 넘어서, 모델은 복잡한 도구 상호작용에 대한 뛰어난 일반화 능력과 실제 노이즈가 있는 환경에서도 안정적인 행동을 보입니다. 이러한 고도의 성능은 도메인 병렬 전문가 훈련을 통합한 후 융합하는 통합적 훈련 프레임워크와 사전 훈련부터 사후 훈련에 이르는 데이터 구성, 환경 설계, 알고리즘, 인프라까지 종합적으로 공ออกแบบ된 엔드투엔드 설계에 기인합니다. 특히, 복잡한 도구 사용에 대한 강력한 일반화 능력은 환경 확장(environment scaling)과 체계적인 작업 구성(principled task construction)에 대한 심층적인 탐구에 기반합니다. 긴 꼬리 분포(long-tailed), 편향된 생성 및 다턴 에이전트 상호작용을 최적화하고, 20개 이상의 도메인에 걸쳐 1만 개 이상의 환경에서 안정적인 훈련을 가능하게 하기 위해, 우리는 비동기 강화 학습 프레임워크인 DORA를 체계적으로 확장하여 대규모 다중 환경 훈련의 안정성과 효율성을 확보했습니다. 더불어, 실제 작업이 본질적으로 노이즈를 내포하고 있음을 인지하여, 실제 노이즈 패턴을 체계적으로 분석하고 분해한 후, 이러한 불완전성을 훈련 과정에 명시적으로 반영할 수 있도록 특화된 훈련 절차를 설계함으로써, 실제 응용 환경에서의 강건성(robustness)을 향상시켰습니다. 또한, 복잡한 추론 작업에서의 성능을 further 향상시키기 위해, 집중적인 병렬적 사고를 통해 추론의 깊이와 폭을 동시에 확장함으로써 테스트 시에 효과적인 스케일링이 가능한 '헤비 사고(Heavy Thinking)' 모드를 도입하였습니다.
One-sentence Summary
The Meituan LongCat Team introduces LongCat-Flash-Thinking-2601, a 560B MoE model excelling in agentic reasoning via unified domain-parallel training and noise-aware design, enabling robust tool use across 10K+ environments and enhanced performance through Heavy Thinking mode for real-world applications.
Key Contributions
- LongCat-Flash-Thinking-2601 introduces a unified training framework combining domain-parallel expert training and fusion, enabling state-of-the-art open-source performance on agentic benchmarks like BrowseComp (73.1%) and RWSearch (77.7%) through end-to-end co-design of data, environments, and infrastructure.
- The model leverages an extended asynchronous RL system, DORA, to stabilize training across over 10,000 environments spanning 20+ domains, while incorporating real-world noise patterns into training to improve robustness in noisy, out-of-distribution settings.
- It features a Heavy Thinking mode for test-time scaling that jointly expands reasoning depth and width via parallel thinking, enhancing complex reasoning performance without requiring additional training, and is released open-source to support future agentic system research.
Introduction
The authors leverage a 560-billion-parameter Mixture-of-Experts model to advance agentic reasoning — the ability to solve complex tasks through adaptive interaction with external environments, such as tools or search systems. Prior models struggle with long-horizon, multi-domain interactions and real-world noise, often lacking scalable training infrastructure or robustness to imperfect environments. Their main contribution is a unified training pipeline that combines domain-parallel expert training, automated multi-domain environment scaling, and noise-injection via curriculum-based RL to improve generalization. They also introduce a Heavy Thinking mode that boosts test-time performance by expanding reasoning depth and width in parallel, enabling state-of-the-art results on open-source agentic benchmarks.
Dataset

-
The authors use a dual-environment framework for agentic training: one for coding (executable code sandbox) and one for general tool use (domain-specific tool graphs), both designed to support scalable, reproducible, and diverse interaction patterns.
-
For the code sandbox, they build a high-throughput system that standardizes terminal tools (search, file I/O, shell execution) and schedules thousands of concurrent sandboxes via asynchronous provisioning to eliminate startup overhead during training.
-
For tool-use environments, they construct over 20 domain-specific tool graphs (each with 60+ tools) using an automated pipeline that converts high-level domain specs into executable tool-database pairs, validated via unit tests and debugging agents (95% success rate).
-
Each environment begins with a sampled seed tool chain; it’s expanded via controlled BFS-style graph growth to preserve database consistency and executable correctness, avoiding cascading dependency failures.
-
Environments can be further complexified by adding new seed chains based on structural complexity, remaining node count, and solver difficulty — with a fallback to ensure at least 20 tools per environment.
-
Cold-start training data is sourced from real-world platforms (for coding/math) or synthesized (for search/tool-use), with strict filtering: executability checks, action-level pruning, and rubric-based validation.
-
For general thinking, they use a K-Center-Greedy selection with sliding-window perplexity to prioritize samples that expose reasoning gaps, downsampling 210K high-quality trajectories.
-
For agentic coding, trajectories are filtered for full executability, functional correctness, and long-horizon reasoning — with earlier steps compressed to retain context without length penalty.
-
For agentic search, synthetic trajectories enforce multi-step evidence gathering, explicit condition verification, and robustness against shortcuts; trivial cases are removed.
-
For agentic tool-use, they generate tasks across 33 domains with variable structure, length, and multiple valid solutions; turn-level loss masking excludes failed or malformed actions during training.
-
All synthesized tasks include three components: task description, user profile, and evaluation rubrics — validated via consistency checks to ensure reliable supervision and reject incomplete trajectories.
Method
The authors leverage a multi-stage training framework designed to scale agentic reasoning capabilities in large language models, beginning with a pre-training phase that extends the LongCat-Flash-Chat recipe to incorporate structured agentic data. This phase addresses the dual challenges of long-context modeling efficiency and the scarcity of real-world agentic trajectories. To manage long-context requirements, a staged mid-training procedure is employed, progressively increasing context lengths and allocating specific token budgets to 32K, 128K, and 256K stages. The model is exposed to moderate-scale agentic data to establish foundational behaviors before reinforcement learning. To overcome the scarcity of high-quality agentic trajectories, a hybrid data synthesis pipeline is constructed, drawing from both unstructured text and executable environments. Text-driven synthesis mines implicit procedural knowledge from large-scale corpora, converting abstract workflows into explicit multi-turn user-agent interactions through text filtering, tool extraction, and refinement. This process is further enhanced with decomposition-based augmentations, including tool decomposition, which iteratively hides parameters into the environment, and reasoning decomposition, which generates alternative action candidates to transform trajectories into multi-step decision-making processes. Environment-grounded synthesis ensures logical consistency by implementing lightweight Python environments for toolsets and modeling tool dependencies as a directed graph. Valid tool execution paths are sampled from this graph, and corresponding system prompts are reverse-synthesized and verified through code execution, guaranteeing the correctness of the generated trajectories. A dedicated planning-centric data augmentation strategy is also introduced to explicitly strengthen planning ability, transforming existing trajectories into structured decision-making processes through problem decomposition and candidate selection. 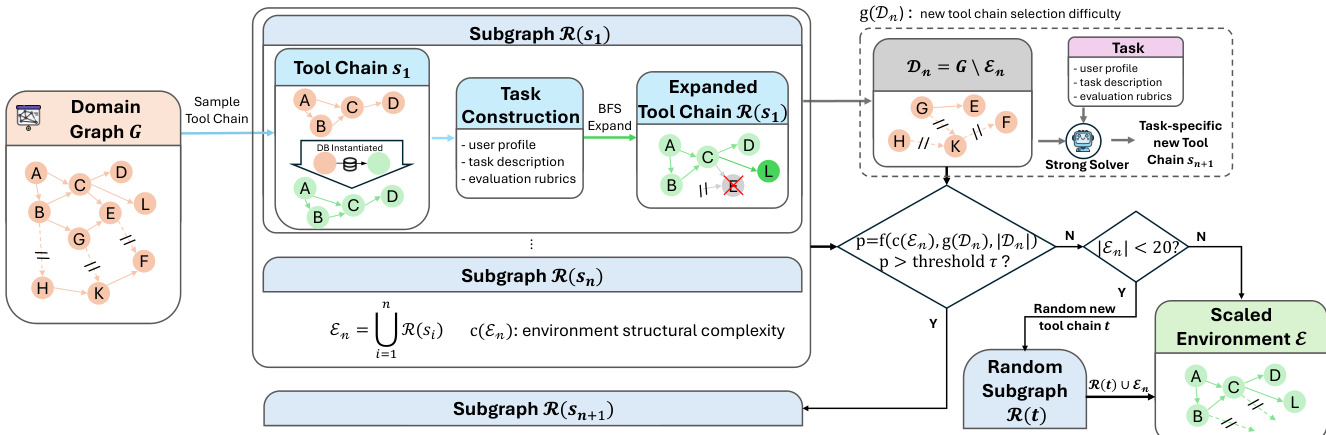
Following pre-training, the model undergoes a scalable reinforcement learning (RL) phase to elicit stronger reasoning capabilities. This phase is built upon a unified multi-domain post-training pipeline that first trains domain-specialized expert models under a shared framework and then consolidates them into a single general model. The RL framework is designed to handle the unique challenges of agentic training, including the need for scalable environment construction, high-quality cold-start data, and well-calibrated task sets, as well as the requirement for a dedicated infrastructure to support high-throughput, asynchronous, and long-tailed multi-turn rollouts. The authors extend their multi-version asynchronous training system, DORA, to support this setting. The core of the system is a producer-consumer architecture, as illustrated in the framework diagram, which consists of a RolloutManager, a SampleQueue, and a Trainer, running on different nodes and coordinating via Remote Procedure Call (RPC). This architecture enables a fully streaming asynchronous pipeline, removing batch barriers to minimize device idleness during multi-turn rollouts. To address the long-tailed generation problem, the system supports multi-version asynchronous training, where trajectories from different model versions are immediately enqueued upon completion, allowing the Trainer to initiate training as soon as conditions are met. 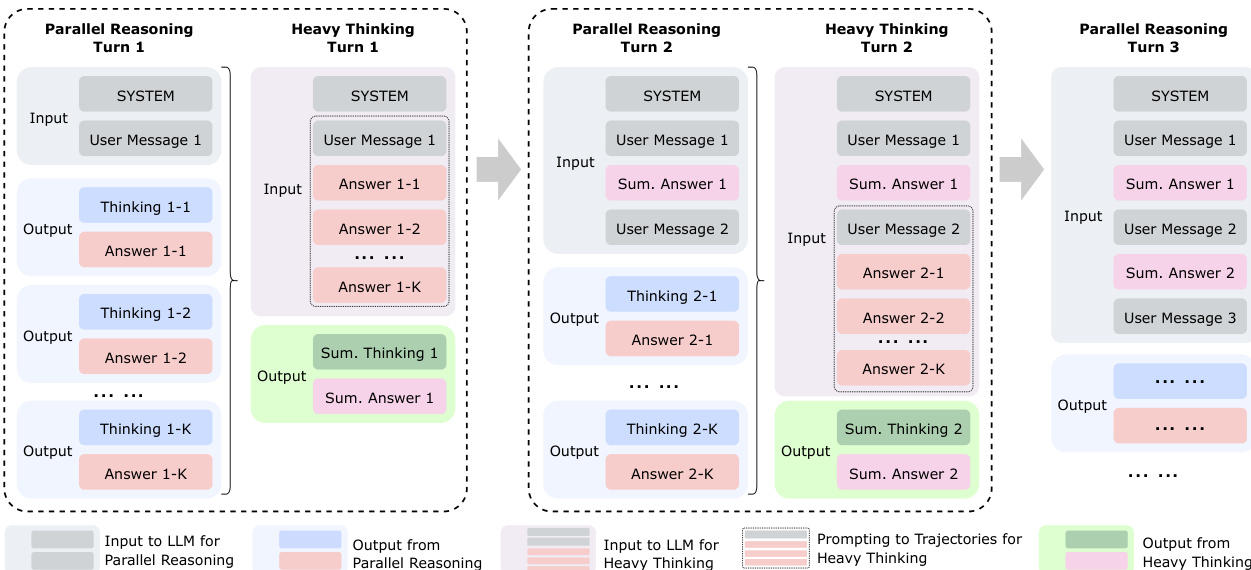
To scale to large-scale agentic training, the system decomposes the RolloutManager into a Lightweight-RolloutManager for global control and multiple RolloutControllers for managing virtual rollout groups in a data-parallel manner. This design, combined with an extension of the PyTorch RPC framework to provide CPU-idleness-aware remote function invocation, enables the efficient deployment of massive environments across thousands of accelerators. A key technique for efficient generation of large models like LongCat-Flash-Thinking-2601 is Prefill-Decode (PD) Disaggregation, which separates the prefetch and decode workloads into distinct device groups. This prevents the decode execution graph from being interrupted by prefetch workloads, maintaining high throughput during multi-turn rollouts. To mitigate the associated challenges of KV-cache transfer and recomputation, the system aggregates KV-cache blocks in chunks for asynchronous transmission and introduces a CPU-resident KV-cache that dynamically swaps blocks in and out as needed, eliminating recomputation overhead due to insufficient on-device memory. 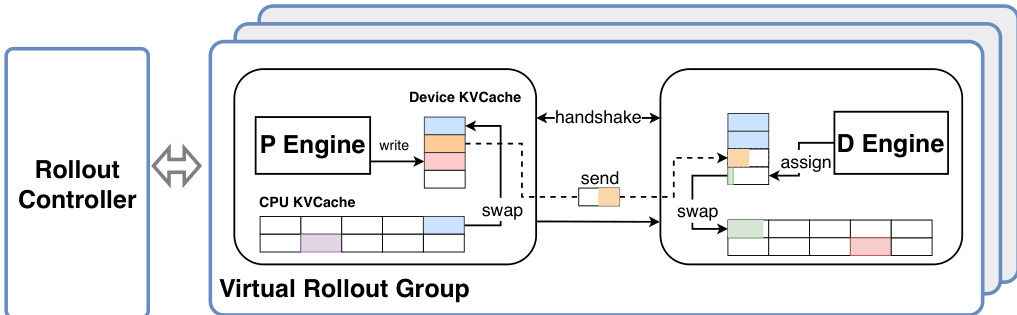
The RL training strategy is designed to be stable, efficient, and scalable. The authors adopt Group Sequence Policy Optimization (GSPO) as the training objective, which provides more stable sequence-level optimization for long-horizon agentic trajectories. A curriculum learning strategy is employed to progressively increase task difficulty along two axes: task difficulty, quantified by the model's pass rate, and capability requirement, such as basic tool invocation or multi-step planning. This allows the model to first acquire reusable skills before composing them to solve complex problems. Dynamic budget allocation is applied within each training batch to prioritize tasks that provide higher learning value, using a dynamic value function that estimates the value of a task based on the model's real-time training state. This strategy adapts to the model's evolving capabilities, ensuring that the most informative tasks are allocated more rollout budget. Self-verification is introduced as an auxiliary task, where the model evaluates its own on-policy trajectories, which accelerates optimization and improves generation performance. 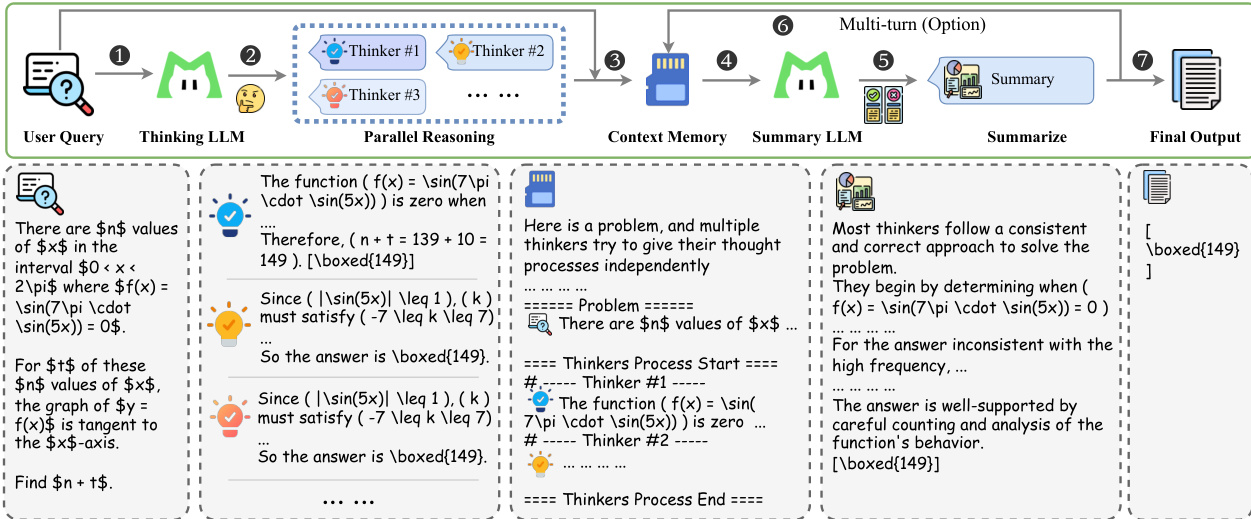
In agentic scenarios, effective context management is critical. The authors design a hybrid context management strategy that combines summary-based and discard-based approaches. When the context window exceeds a predefined limit of 80K tokens, the model performs a summary-based compression, distilling historical tool call results into a concise summary. When the interaction exceeds the maximum number of turns, a discard-all reset is triggered, restarting generation with an initialized system and user prompt. This hybrid strategy dynamically switches between compression and reset based on context window and interaction turn constraints, achieving a favorable trade-off between retaining critical reasoning context and controlling computational overhead. For training with scaled environments, a multi-domain environment training strategy is adopted, jointly optimizing across diverse environments within each training batch. To maintain training stability and prevent domain imbalance, separate oversampling ratios are configured for different data types and domains, ensuring that challenging or low-throughput domains contribute sufficient samples without blocking the pipeline. 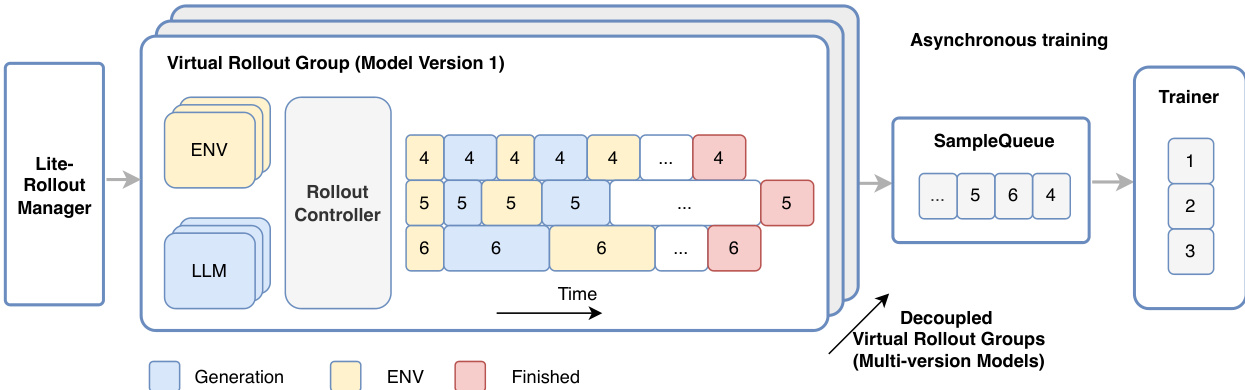
To improve robustness, the training process explicitly incorporates environmental imperfections, such as instruction noise and tool noise, using a curriculum-based strategy that progressively increases noise difficulty. This ensures the model learns resilient behaviors under non-ideal conditions. Finally, the authors propose a test-time scaling framework called heavy thinking, which decomposes computation into two stages: parallel reasoning and heavy thinking. In the first stage, a thinking model generates multiple candidate reasoning trajectories in parallel. In the second stage, a summary model conducts reflective reasoning over these trajectories to synthesize a final decision. This framework is supported by a context memory module to store message history and a specific prompt template to organize the parallel trajectories for the summary model. 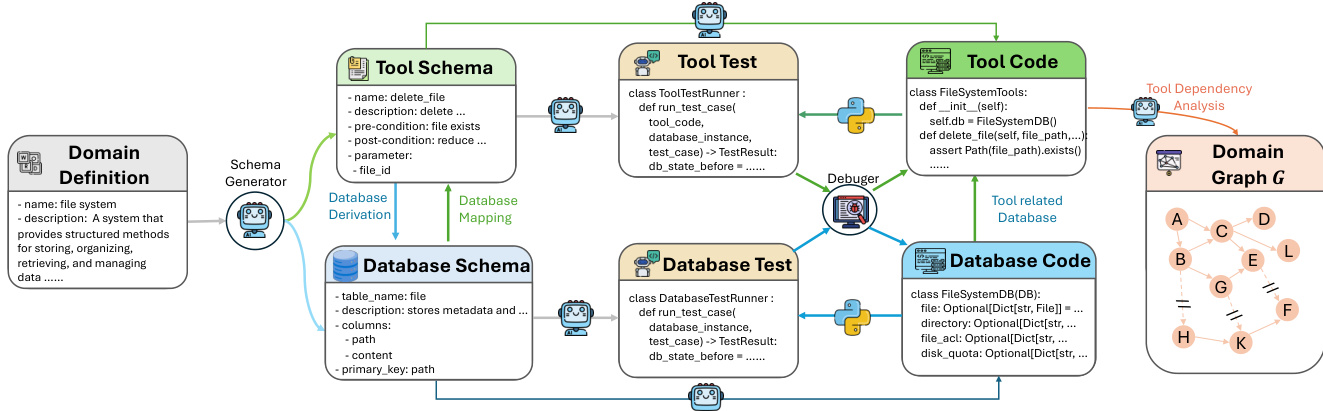
Experiment
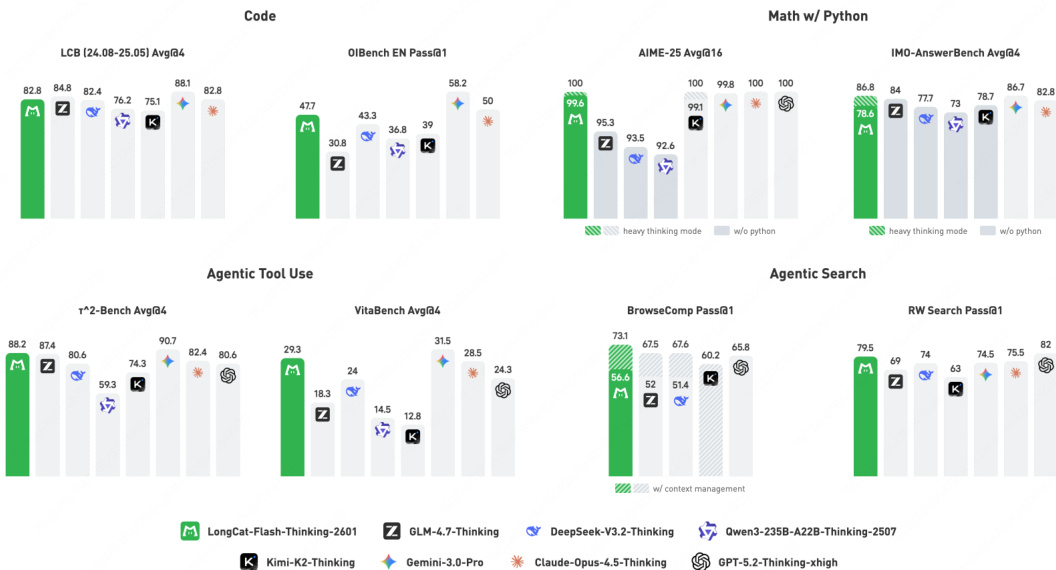
- Mathematical Reasoning: Achieved perfect score on AIME-2025, 86.8 on IMO-AnswerBench, and open-source SOTA on AMO-Bench (EN/zh), matching top closed-source models in heavy mode.
- Agentic Search: Set SOTA on BrowseComp (73.1) and BrowseComp-ZH (77.7) with context management; scored 79.5 on RWSearch, second only to GPT-5.2-Thinking.
- Agentic Tool-Use: Achieved open-source SOTA on τ²-Bench, VitaBench, and Random Complex Tasks, showing strong noise robustness and generalization.
- General QA: Scored 25.2 on HLE text-only subset and 85.2 on GPQA-Diamond (heavy mode), nearing open-source SOTA.
- Coding: Ranked top open-source on OIBench, second on OJBench, competitive on LiveCodeBench and SWE-bench Verified; outperformed GLM-4.7 with 45k vs 57k tokens per problem.
- Context Management: Optimal performance on BrowseComp at 80K token summary threshold (66.58% Pass@1).
Results show that LongCat-Flash-Thinking-2601 achieves state-of-the-art performance on mathematical reasoning benchmarks, including a perfect score on AIME-25 and a leading score on IMO-AnswerBench, while also demonstrating strong capabilities in agentic search, tool use, general QA, and coding across multiple benchmarks. The model consistently outperforms or matches leading open-source and closed-source models, particularly in tool-integrated reasoning and agentic tasks, with competitive results on both standard and noise-augmented benchmarks.

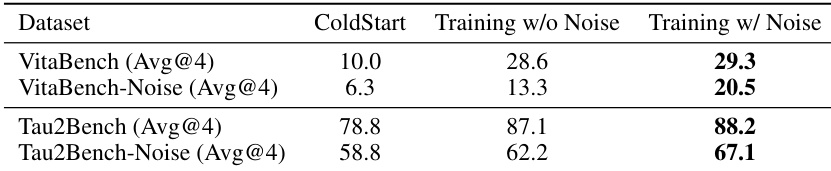
Results show that training with noise improves performance on both VitaBench and τ²-Bench, with the best results achieved when training includes noise, particularly on τ²-Bench where the score increases from 78.8 to 88.2. The performance on noise-augmented versions of the benchmarks also improves, indicating enhanced robustness.
The authors use a comprehensive set of benchmarks to evaluate LongCat-Flash-Thinking-2601 across mathematical reasoning, agentic search, tool use, general reasoning, and coding. Results show that LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on most tasks, particularly excelling in mathematical reasoning and agentic search, while also demonstrating strong generalization and robustness in tool-integrated reasoning.