Command Palette
Search for a command to run...
베이지안VLA: 잠재적 액션 쿼리를 통한 시각-언어-액션 모델의 베이지안 분해
베이지안VLA: 잠재적 액션 쿼리를 통한 시각-언어-액션 모델의 베이지안 분해
Shijie Lian Bin Yu Xiaopeng Lin Laurence T. Yang Zhaolong Shen Changti Wu Yuzhuo Miao Cong Huang Kai Chen
초록
시각-언어-행동(Vision-Language-Action, VLA) 모델은 로봇 조작 분야에서 유망한 성과를 보여주고 있으나, 새로운 지시나 복잡한 다중 작업 시나리오로의 일반화 능력이 여전히 부족한 문제가 있다. 본 연구에서는 현재의 학습 패러다임에서 발생하는 핵심적인 문제를 규명한다. 목표 중심의 데이터 수집 방식은 데이터셋 편향을 초래하며, 이로 인해 시각 관측만으로도 언어 지시가 매우 예측 가능해진다. 이로 인해 지시어와 행동 간의 조건부 상호정보량(conditional mutual information)이 사라지는 현상이 발생하며, 우리는 이를 '정보 붕괴(Information Collapse)'라고 명명한다. 결과적으로 모델은 언어 제약을 무시하고 시각 정보에만 의존하는 정책으로 악화되며, 분포 외(OOD, out-of-distribution) 환경에서는 실패하게 된다. 이를 해결하기 위해 우리는 베이지안 분해를 통한 지시어 준수를 보장하는 새로운 프레임워크인 BayesianVLA를 제안한다. 학습 가능한 잠재 행동 쿼리(latent action queries)를 도입함으로써, 시각 정보에 기반한 사전 확률 p(a∣v)와 언어 조건부 사후 확률 π(a∣v,ℓ)을 추정하는 이중 브랜치 아키텍처를 구축한다. 이후 행동과 지시어 간의 조건부 포인트와이즈 상호정보량(Pointwise Mutual Information, PMI)을 최대화하도록 정책을 최적화한다. 이 목적함수는 시각적 단순화 경로를 효과적으로 방지하고, 언어 명령을 명확히 설명하는 행동을 보상함으로써, 모델의 일반화 능력을 크게 향상시킨다. 추가적인 데이터 수집 없이도 BayesianVLA는 기존 모델에 비해 뚜렷한 성능 향상을 보이며, SimplerEnv와 RoboCasa에서 수행된 광범위한 실험을 통해, 특히 도전적인 OOD SimplerEnv 벤치마크에서 11.3%의 성능 향상을 달성하여, 본 연구의 접근 방식이 언어를 행동에 견고하게 연결할 수 있음을 입증한다.
One-sentence Summary
Researchers from HUST, ZGCA, and collaborators propose BayesianVLA, a framework that combats instruction-ignoring in VLA models via Bayesian decomposition and Latent Action Queries, boosting OOD generalization by 11.3% on SimplerEnv without new data.
Key Contributions
- We identify "Information Collapse" in VLA training, where goal-driven datasets cause language instructions to become predictable from visuals alone, leading models to ignore language and fail in OOD settings.
- We introduce BayesianVLA, a dual-branch framework using Latent Action Queries to separately model vision-only priors and language-conditioned posteriors, optimized via conditional PMI to enforce explicit instruction grounding.
- BayesianVLA achieves state-of-the-art results without new data, including an 11.3% OOD improvement on SimplerEnv and preserves text-only conversational abilities of the backbone VLM.
Introduction
The authors leverage Vision-Language-Action (VLA) models to enable robots to follow natural language instructions, but identify a critical flaw: in goal-driven datasets, visual observations alone can predict instructions, causing models to ignore language and rely on “vision shortcuts.” This leads to poor generalization in out-of-distribution or ambiguous scenarios. To fix this, they introduce BayesianVLA, which uses Bayesian decomposition and learnable Latent Action Queries to train a dual-branch policy—one estimating a vision-only prior and the other a language-conditioned posterior—optimized to maximize the mutual information between actions and instructions. Their method requires no new data and significantly improves OOD performance, while preserving the model’s core language understanding, making it more robust and reliable for real-world deployment.
Method
The authors leverage a Bayesian framework to address the vision shortcut problem in Vision-Language-Action (VLA) models, where the conditional mutual information between instructions and actions collapses due to deterministic mappings from vision to language in goal-driven datasets. To counteract this, they propose maximizing the conditional Pointwise Mutual Information (PMI) between actions and instructions, which is formalized as the Log-Likelihood Ratio (LLR) between the posterior policy and the vision-only prior. This objective, derived from information-theoretic principles, encourages the model to learn action representations that carry instruction-specific semantics not predictable from vision alone.
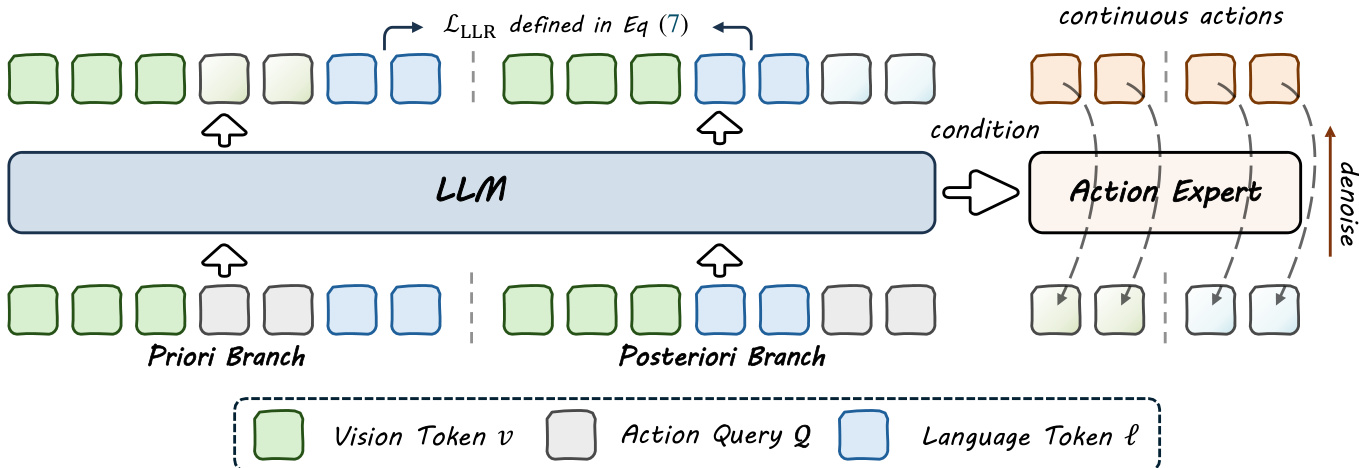
As shown in the figure below, the proposed BayesianVLA framework operates through a dual-branch training strategy that shares a single Large Language Model (LLM) backbone while maintaining distinct input structures for each branch. The core innovation lies in the use of Latent Action Queries, which are learnable tokens appended to the input sequence to serve as a dedicated bottleneck interface between the LLM and the continuous action head. This design enables precise control over the information flow by leveraging the causal masking of decoder-only models, allowing the queries to attend to different subsets of the input depending on their position.

In the Priori Branch, the input sequence is structured as [v,Q,ℓ], where v is the visual observation, Q is the set of action queries, and ℓ is the language instruction. Due to the causal attention mask, the queries can attend to the visual input but not to the language instruction, resulting in hidden states HQprior that encode only vision-dependent information. These features are used to predict the action a via a flow-matching loss Lprior, effectively learning the dataset's inherent action bias p(a∣v).
In the Posteriori Branch, the input sequence is arranged as [v,ℓ,Q], allowing the queries to attend to both the visual and language inputs. This produces hidden states HQpost that encode the full context of vision and language, which are used to predict the expert action a with a main flow-matching loss Lmain. The two branches are trained simultaneously, sharing the same LLM weights.
To explicitly maximize the LLR objective, the framework computes the difference in log-probabilities of the language tokens between the two branches. The LLR loss is defined as LLLR=logp(ℓ∣v,HQprior)−sg(logp(ℓ∣v)), where the stop-gradient operator prevents the model from degrading the baseline language model capability. This term is optimized to force the action representations to carry information that explains the instruction.
The total training objective combines the action prediction losses from both branches with the LLR regularization term: Ltotal=(1−λ)LFM(ψ;HQpost)+λLFM(ψ;HQprior)−βLLLR. The action decoder is trained using the Rectified Flow Matching objective, where the Diffusion Transformer predicts the velocity field for action trajectories conditioned on the query features. During inference, only the Posteriori Branch is executed to generate actions, ensuring no additional computational overhead compared to standard VLA baselines.
Experiment
- Pilot experiments reveal that standard VLA models often learn vision-only policies p(a|v) instead of true language-conditioned policies π(a|v,ℓ), even when trained on goal-driven datasets.
- On RoboCasa (24 tasks), vision-only models achieve 44.6% success vs. 47.8% for language-conditioned baselines, showing minimal reliance on instructions due to visual-task correlation.
- On LIBERO Goal, vision-only models drop to 9.8% success (vs. 98.0% baseline) when scenes map to multiple tasks, exposing failure to resolve ambiguity without language.
- On BridgeDataV2, vision-only models match full models in training loss (0.13 vs. 0.08) but fail catastrophically (near 0%) on OOD SimplerEnv, confirming overfitting to visual shortcuts.
- BayesianVLA achieves 66.5% avg success on SimplerEnv (vs. 55.2% baseline), with +11.3% absolute gain, excelling in tasks like “Put Carrot on Plate” (+13.6%) and “Put Eggplant in Yellow Basket” (+15.0%).
- On RoboCasa, BayesianVLA reaches 50.4% avg success (vs. 47.8% baseline), outperforming all competitors and notably improving on ambiguous tasks like “PnP Novel From Placemat To Plate” (70.0% vs. 34.0% vision-only).
- Ablations confirm Bayesian decomposition drives core gains (+6.0% over +Action Query alone), while latent action queries improve efficiency by reducing DiT complexity from O(N²) to O(K²).
- Future work includes scaling to larger models (e.g., Qwen3VL-8B), real-world testing, and expanding to RoboTwin/LIBERO benchmarks.
The authors use the SimplerEnv benchmark to evaluate BayesianVLA, which is trained on BridgeDataV2 and Fractal datasets. Results show that BayesianVLA achieves a state-of-the-art average success rate of 66.5%, significantly outperforming the baseline QwenGR00T (55.2%) and other strong competitors, with notable improvements in tasks requiring precise object manipulation.
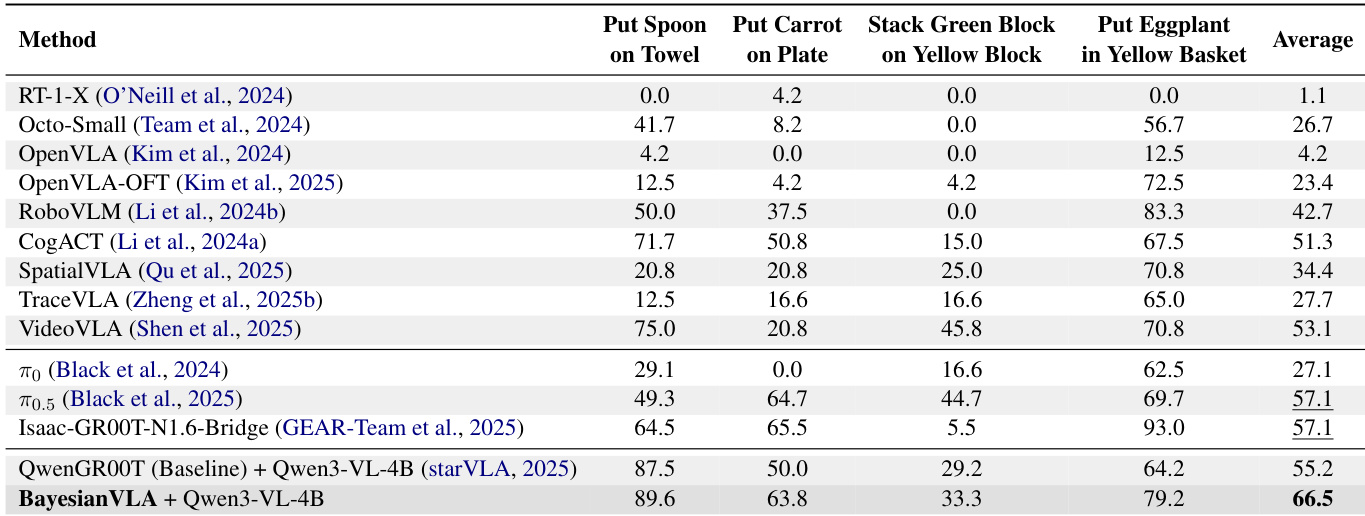
The authors use the SimplerEnv benchmark to evaluate the performance of BayesianVLA against baseline models, with results showing that BayesianVLA achieves a state-of-the-art average success rate of 63.5%, outperforming the QwenGR00T baseline by 8.3 percentage points. This improvement is particularly notable in tasks requiring precise object manipulation, such as "Put Carrot on Plate" and "Put Eggplant in Yellow Basket," where BayesianVLA demonstrates significant gains over the baseline. The results confirm that the proposed Bayesian decomposition effectively mitigates the vision shortcut by encouraging the model to rely on language instructions rather than visual cues alone.

The authors use the RoboCasa benchmark to evaluate VLA models, where the VisionOnly baseline achieves a high success rate of 44.7%, indicating that the model can perform well without language instructions due to visual shortcuts. BayesianVLA surpasses all baselines, achieving an average success rate of 50.4% and demonstrating significant improvements in tasks where the vision-only policy fails, such as "PnP Novel From Placemat To Plate," confirming that the method effectively mitigates the vision shortcut by leveraging language for disambiguation.