Command Palette
Search for a command to run...
오미트랜스퍼: 시공간 비디오 전이를 위한 통합 프레임워크
오미트랜스퍼: 시공간 비디오 전이를 위한 통합 프레임워크
초록
비디오는 이미지나 텍스트보다 풍부한 정보를 전달하며 공간적 및 시간적 동적 특성을 동시에 포착할 수 있다. 그러나 기존의 대부분의 비디오 커스터마이징 기법은 참조 이미지나 작업에 특화된 시간적 사전 지식에 의존하여, 비디오 내에 내재된 풍부한 공간-시간 정보를 충분히 활용하지 못함으로써 비디오 생성의 유연성과 일반화 능력에 한계가 있다. 이러한 문제를 해결하기 위해 우리는 공간-시간 비디오 전이를 위한 통합 프레임워크인 OmniTransfer를 제안한다. OmniTransfer는 프레임 간 다중 시점 정보를 활용하여 외형 일관성을 향상시키고, 시간적 신호를 이용해 세밀한 시간적 제어를 가능하게 한다. 다양한 비디오 전이 작업을 통합하기 위해, OmniTransfer는 세 가지 핵심 설계를 포함한다: 작업 인지형 위치 편향(Task-aware Positional Bias)은 참조 비디오 정보를 적응적으로 활용하여 시간 정렬 또는 외형 일관성을 개선하며, 참조-타겟 분리형 인과 학습(Reference-decoupled Causal Learning)은 참조 및 타겟 브랜치를 분리함으로써 정확한 참조 전이를 가능하게 하면서도 효율성을 높이며, 작업 적응형 다모달 정렬(Task-adaptive Multimodal Alignment)은 다모달 의미 지침을 활용해 작업에 따라 동적으로 구분하고 각각의 작업을 효과적으로 해결한다. 광범위한 실험 결과는 OmniTransfer가 기존 방법보다 외형(개인 식별 및 스타일) 및 시간 전이(카메라 움직임 및 비디오 효과) 측면에서 우수한 성능을 보이며, 자세 정보를 사용하지 않음에도 불구하고 자세 유도 방법과 동등한 운동 전이 성능을 달성함으로써, 유연하고 고해상도의 비디오 생성을 위한 새로운 패러다임을 제시한다.
One-sentence Summary
Researchers from ByteDance’s Intelligent Creation Lab propose OmniTransfer, a unified framework for spatio-temporal video transfer that leverages multi-view and temporal cues for appearance consistency and fine-grained control, outperforming prior methods in style, ID, motion, and camera effects without requiring pose or task-specific priors.
Key Contributions
- OmniTransfer introduces a unified framework for spatio-temporal video transfer, addressing the limitations of existing methods that rely on static references or task-specific priors by leveraging multi-frame video cues for both appearance and temporal control across diverse tasks like ID, style, motion, and camera effects.
- The framework integrates three novel components: Task-aware Positional Bias for adaptive spatio-temporal alignment, Reference-decoupled Causal Learning for efficient reference transfer without full attention, and Task-adaptive Multimodal Alignment using MLLM-guided MetaQueries to dynamically handle cross-task semantics.
- Evaluated on standard benchmarks, OmniTransfer surpasses prior methods in appearance and temporal transfer quality, matches pose-guided approaches in motion transfer without pose input, and reduces runtime by 20% compared to full-attention baselines.
Introduction
The authors leverage video’s rich spatio-temporal structure to overcome the limitations of prior methods that rely on static images or task-specific priors like pose or camera parameters, which restrict flexibility and generalization. Existing approaches struggle to unify appearance and motion transfer, often requiring fine-tuning or failing under real-world conditions. OmniTransfer introduces three core innovations: Task-aware Positional Bias to align temporal or spatial cues adaptively, Reference-decoupled Causal Learning to enable efficient one-way transfer without copying, and Task-adaptive Multimodal Alignment to dynamically route semantic guidance using multimodal prompts. Together, these components allow a single model to handle diverse video transfer tasks—including ID, style, motion, and camera movement—while improving fidelity, reducing runtime by 20%, and generalizing to unseen task combinations.
Dataset

- The authors use five dedicated test sets to evaluate spatio-temporal video transfer, each targeting a distinct subtask.
- ID transfer: 50 videos of diverse individuals, each paired with two prompts to measure identity consistency.
- Style transfer: 20 unseen visual styles, each tested with two prompts to evaluate stylistic variation.
- Effect transfer: 50 unseen visual effects sourced from visual-effects websites.
- Camera movement transfer: 50 professionally shot videos featuring complex camera trajectories.
- Motion transfer: 50 popular dance videos capturing diverse and fine-grained body motions.
- All test sets are curated for qualitative and quantitative evaluation, with no training or filtering mentioned — used purely for benchmarking model performance.
Method
The authors leverage the Wan2.1 I2V 14B diffusion model as the foundational architecture, building upon its diffusion transformer (DiT) blocks that incorporate both self-attention and cross-attention mechanisms. The input to the model is a latent representation lt∈Rf×h×w×(2n+4), which is constructed by concatenating three components along the channel dimension: the latent noise zt, the condition latent c, and the binary mask latent m. The latent noise zt is derived by adding timestep t noise to the VAE-compressed video features z, while the condition latent c is generated by encoding the condition image I concatenated with zero-filled frames. The binary mask latent m indicates preserved frames with a value of 1 and generated frames with a value of 0. The self-attention within each DiT block employs a 3D Rotary Positional Embedding (RoPE), defined as Attn(Rθ(Q),Rθ(K),V)=softmax(dRθ(Q)Rθ(K)⊤)V, where Q, K, and V are learnable projections of the input latent, and Rθ(⋅) applies the RoPE rotation to queries and keys. Cross-attention integrates textual features from the prompt p as Attn(Q, Kp, Vp).
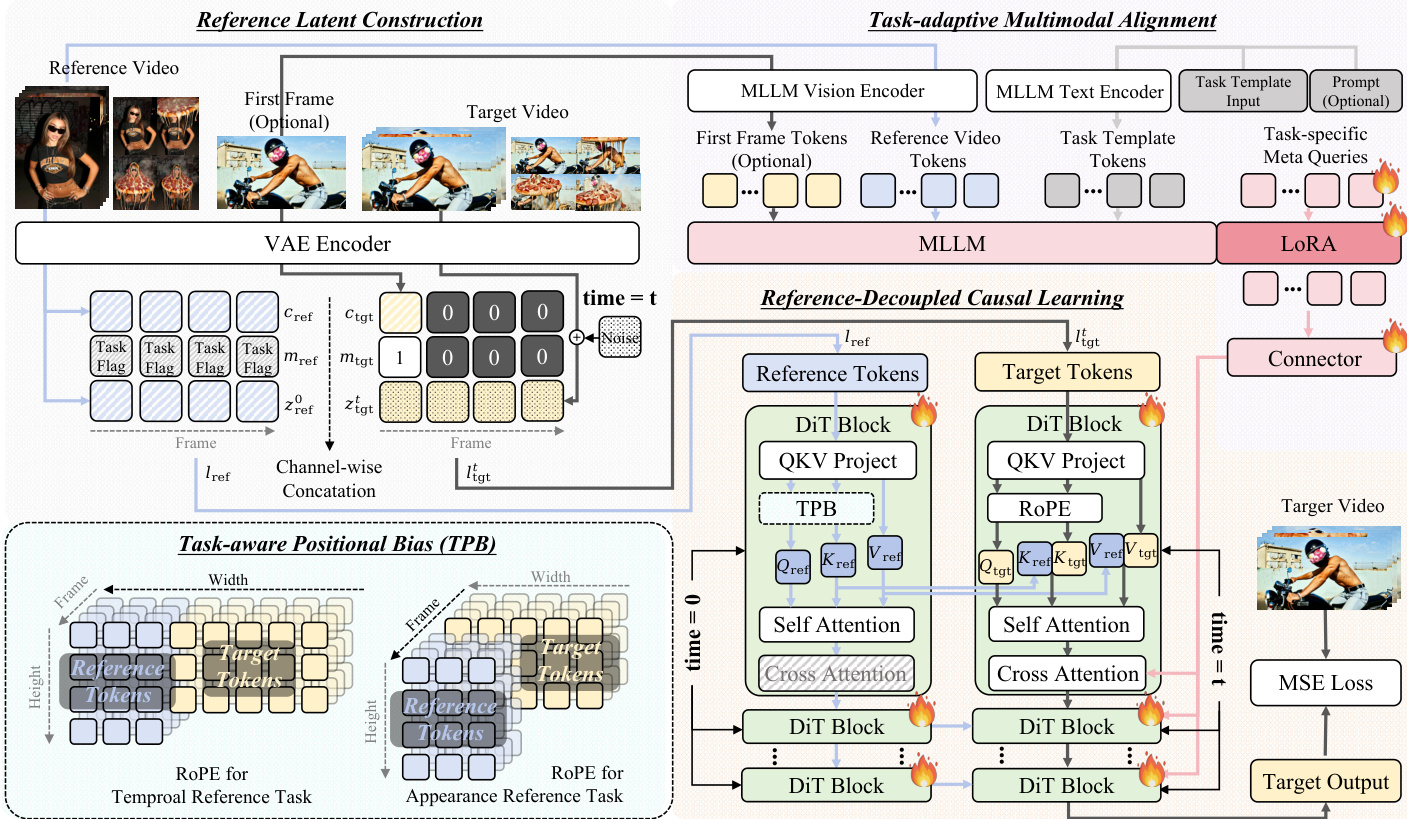
As shown in the figure below, the OmniTransfer framework is composed of four key components: Reference Latent Construction, Task-aware Positional Bias, Reference-decoupled Causal Learning, and Task-adaptive Multimodal Alignment. The process begins with Reference Latent Construction, where the reference video and target video are processed through a VAE Encoder to generate latent representations. The reference video's latent is combined with task-specific flags and a binary mask to form the reference latent lref, while the target video's latent is similarly processed to form ltgt. These latents are then used in the subsequent modules.
The Task-aware Positional Bias (TPB) module introduces an offset to the RoPE of the reference video's latent to exploit spatial and temporal context cues. For temporal reference tasks, an offset is applied along the spatial (width) dimension, equal to the width of the target video wtgt, to leverage spatial in-context cues for temporal consistency. For appearance reference tasks, an offset is applied along the temporal dimension, equal to the number of frames in the target video f, to exploit the temporal propagation of appearance information. This is formalized as Rθ∗(⋅)={Rθ(⋅,Δ=(0,wtgt,0)), for temporal ref.Rθ(⋅,Δ=(f,0,0)), for appearance ref., where Δ=(ΔT,ΔW,ΔH) represents the offsets along the temporal, width, and height dimensions.

The Reference-decoupled Causal Learning module separates the reference and target branches to enable causal and efficient transfer. The reference branch processes the reference latent lref through a series of DiT blocks, while the target branch processes the target latent ltgt. The target branch's self-attention and cross-attention mechanisms are designed to be independent of the reference branch, ensuring that the target generation process is not influenced by the reference's internal state. This decoupling allows for more efficient and causal transfer, as the target branch can focus solely on generating the target video based on the provided reference and prompt.
The Task-adaptive Multimodal Alignment module enhances semantic understanding across tasks by replacing the original T5 features with representations from a Multimodal Large Language Model (MLLM), specifically Qwen-2.5-VL. The MLLM takes as input the first-frame tokens of the target video, the reference video tokens, template tokens, and prompt tokens. To extract task-specific representations, the authors introduce a set of learnable tokens dedicated to each task. For temporal tasks, these tokens aggregate temporal cues from the reference video and the target's first-frame content, capturing cross-frame dynamics. For appearance tasks, they fuse identity or style information from the reference with the semantic context from the prompt tokens. The MLLM is fine-tuned using LoRA for parameter-efficient adaptation, and its outputs are passed through a three-layer MultiLayer Perceptron (MLP) and injected solely into the target branch. This ensures that the cross-attention in the target branch is defined as Attn(Qtgt, KMLLM, VMLLM), where KMLLM and VMLLM are the keys and values derived from the aligned MLLM features, thereby enhancing task-level alignment without interfering with the reference branch.
Experiment
- Trained via three-stage pipeline: DiT blocks first, then connector alignment, followed by joint fine-tuning (10K, 2K, 5K steps; lr=1e-5, batch=16), using custom video datasets for spatio-temporal transfer.
- ID Transfer: Outperformed ConsisID, Phantom, Stand-in on VSim-Arc/Cur/Glint metrics; preserved fine facial details (e.g., acne) and generated diverse poses while maintaining identity across frames.
- Style Transfer: Surpassed StyleCrafter and StyleMaster on CLIP-T, Aesthetics Score, and VCSD; effectively captured video-level style, exceeding image-based baselines.
- Effect Transfer: Outscored Wan 2.1 I2V and Seedance in user studies (effect fidelity, first-frame consistency, visual quality); demonstrated video references essential for complex effects.
- Camera Movement Transfer: Beat MotionClone and CamCloneMaster in user evaluations; uniquely replicated cinematic and professional tracking shots without resolution cropping.
- Motion Transfer: Matched WanAnimate (28B) in motion fidelity using smaller 14B model; preserved appearance without pose guidance, handled multi-person scenes naturally.
- Ablation Study: Full model (+TPB +RCL +TMA) improved motion transfer, reduced task confusion, alleviated copy-paste artifacts, and enhanced semantic control (e.g., generating correct objects/poses); RCL also sped up inference by 20%.
- Combined Transfers: Enabled seamless multi-task video transfers (e.g., ID + style + motion), proving strong generalization to unseen task combinations.
Results show that the proposed method outperforms StyleCrafter and StyleMaster on all three metrics for style transfer, achieving the highest scores in video CSD (VCSD), CLIP-T, and Aesthetics. The authors use these quantitative results to demonstrate superior style consistency and visual quality compared to existing text-to-video stylization approaches.

The authors compare their method with Wan2.1 I2V and Seedance on effect transfer, using a user study to evaluate effect fidelity, first-frame consistency, and overall visual quality. Results show that their method achieves the highest scores across all three metrics, outperforming the baselines.

Results show that the proposed method achieves the highest image consistency and quality among the compared approaches, with a score of 3.88 for image consistency and 3.45 for quality, outperforming MimicMotion and WanAnimate in both metrics. While WanAnimate achieves a higher motion fidelity score, the proposed method demonstrates competitive performance across all evaluated criteria.

The authors conduct an ablation study to evaluate the impact of each component in their model. Results show that adding TPB improves appearance consistency and temporal quality, while adding RCL further enhances both metrics. The full model with all components achieves the highest scores in both appearance and temporal consistency, with a slight increase in inference time.

The authors compare their method with SOTA approaches for ID transfer, using face recognition metrics and CLIP-T scores. Results show that their method achieves the highest VSim-Arc and VSim-Cur scores, while outperforming others in CLIP-T alignment, indicating superior identity preservation and text-video alignment.
