HyperAI
Command Palette
Search for a command to run...
Papers
최신 AI 트렌드를 파악할 수 있도록 매일 업데이트되는 최첨단 AI 연구 논문

비잉-하이프: 교차 몸체 일반화를 위한 인간 중심 로봇 학습의 확장

LLM 기반 소프트웨어 공학 문제 해결의 최신 동향 및 전망: 종합적 서베이


























비잉-하이프: 교차 몸체 일반화를 위한 인간 중심 로봇 학습의 확장
LLM 기반 소프트웨어 공학 문제 해결의 최신 동향 및 전망: 종합적 서베이
Nemotron-Math: Multi-Mode Supervision을 통한 수학적 추론의 효율적인 Long-Context Distillation
Gemini를 위한 프로덕션 준비 완료 프로브 구축
LFM2 기술 보고서
CoDance: 강건한 다중 주제 애니메이션을 위한 Unbind-Rebind 패러다임
어시스턴트 축: 언어 모델의 기본 성격 설정과 안정화
ABC-Bench: 실세계 개발에서 에이전트 기반 백엔드 코드 작성 성능 평가
멀티플렉스 사고: 토큰 단위 브랜치 앤 머지를 통한 추론
이론 모델이 사고의 사회를 생성한다
다중 에이전트 AI 시스템의 개발 및 문제에 관한 대규모 연구
ACoT-VLA: 비전-언어-행동 모델을 위한 행동 체인 오브 써Thought
개인화가 오도할 때: 개인화된 LLM에서 환각 현상을 이해하고 완화하기
RubricHub: 자동적 계층적 생성을 통한 종합적이고 고도로 구분 가능한 평가기준 데이터셋
암묵적 경험의 해방: 텍스트에서 도구 사용 궤적 합성하기
독한 사과 효과: AI 에이전트의 기술 확장에 의한 매개 시장의 전략적 조작
귀하의 그룹 상대적 우위는 편향되어 있습니다
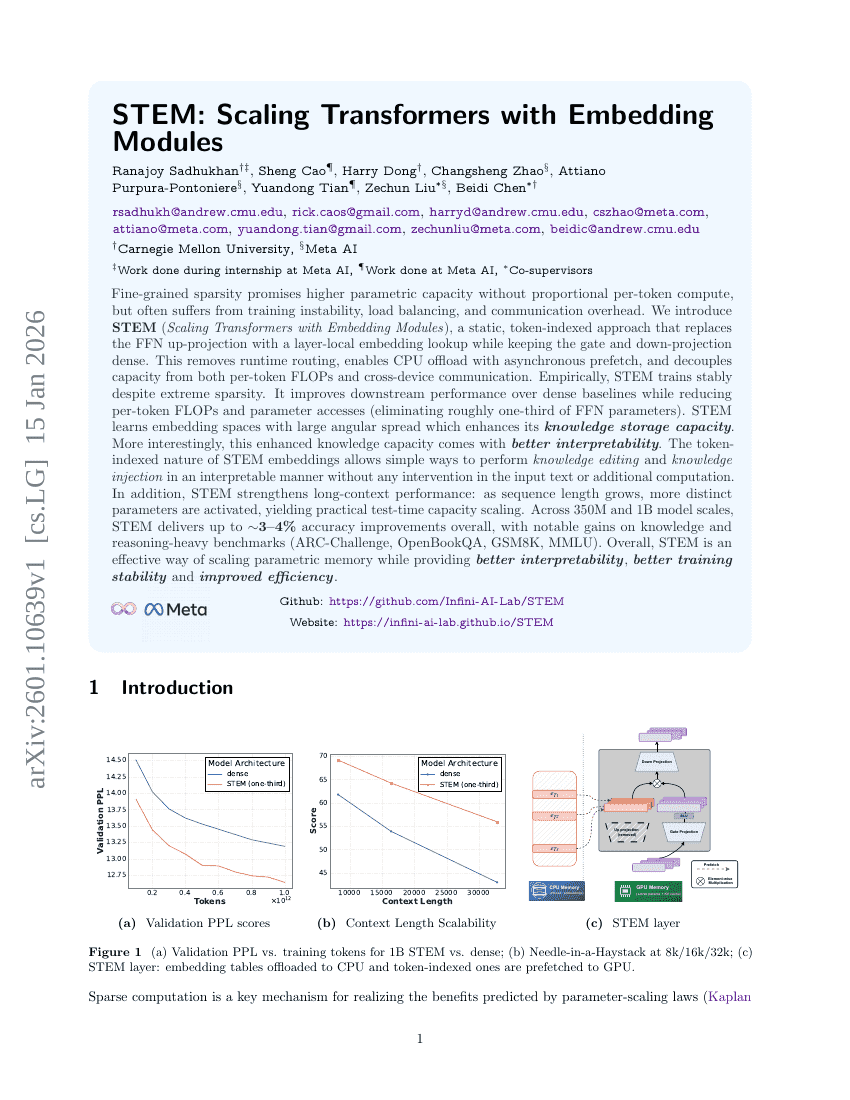
STEM: 임베딩 모듈을 활용한 Transformer의 스케일링
노이즈 속에서 망가진다: 추론 모델이 문맥적 방해 요소에 어떻게 실패하는가
정적 도구를 넘어서: 과학적 추론을 위한 테스트 시점 도구 진화
VIBE: 시각적 지시 기반 편집기
협업형 다중 에이전트 테스트 시점 강화 학습을 통한 추론
희귀한 것을 보상하기: LLM에서 창의적 문제 해결을 위한 고유성 인지 강화 학습
도시 사회세마틱 세그멘테이션: 비전-언어 추론을 활용한 접근
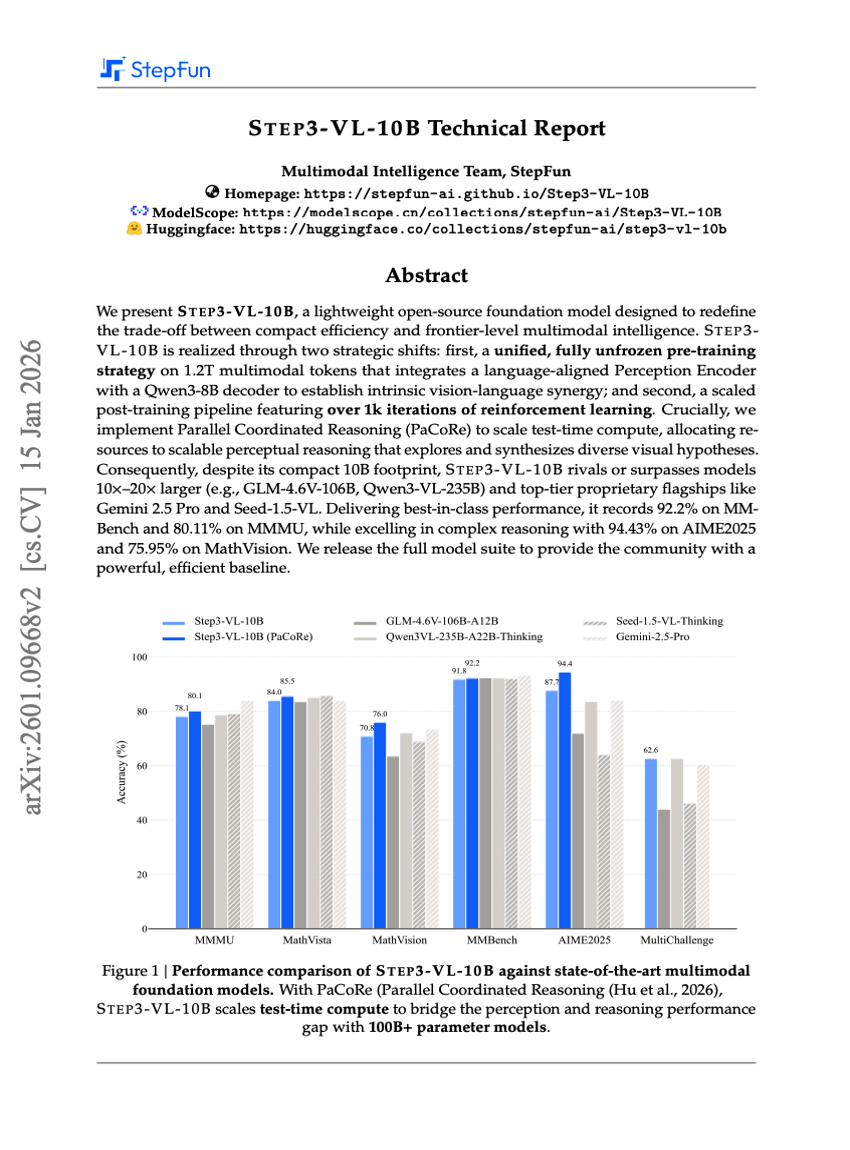
STEP3-VL-10B 기술 보고서
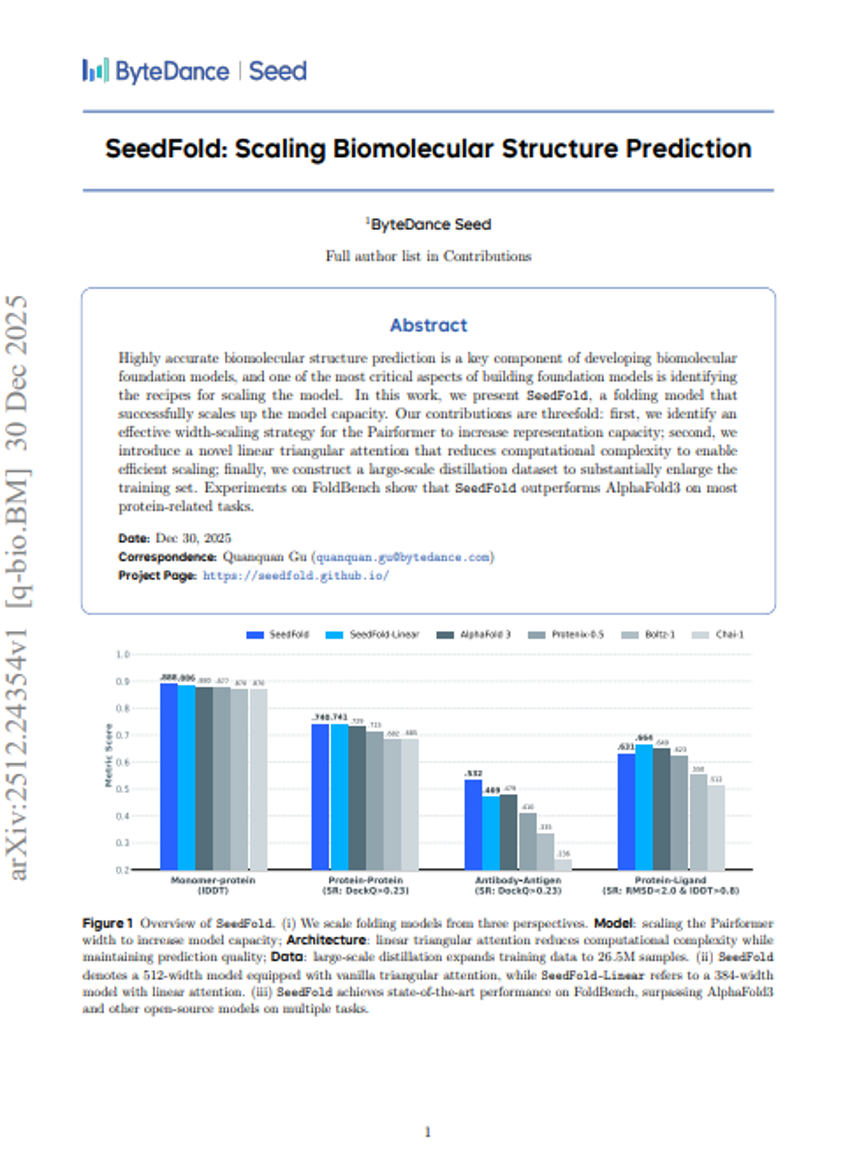
SeedFold: 생물분자 구조 예측의 확장
Gemini 기술 보고서
Fast-ThinkAct: 말로 표현 가능한 잠재적 계획을 통한 효율적인 시각-언어-행동 추론
SkinFlow: 동적 시각 인코딩과 단계별 강화학습을 통한 개방형 피부과 진단을 위한 효율적인 정보 전송
A^3-Bench: 앵커 및 어트랙터 활성화를 통한 메모리 기반 과학적 추론 평가
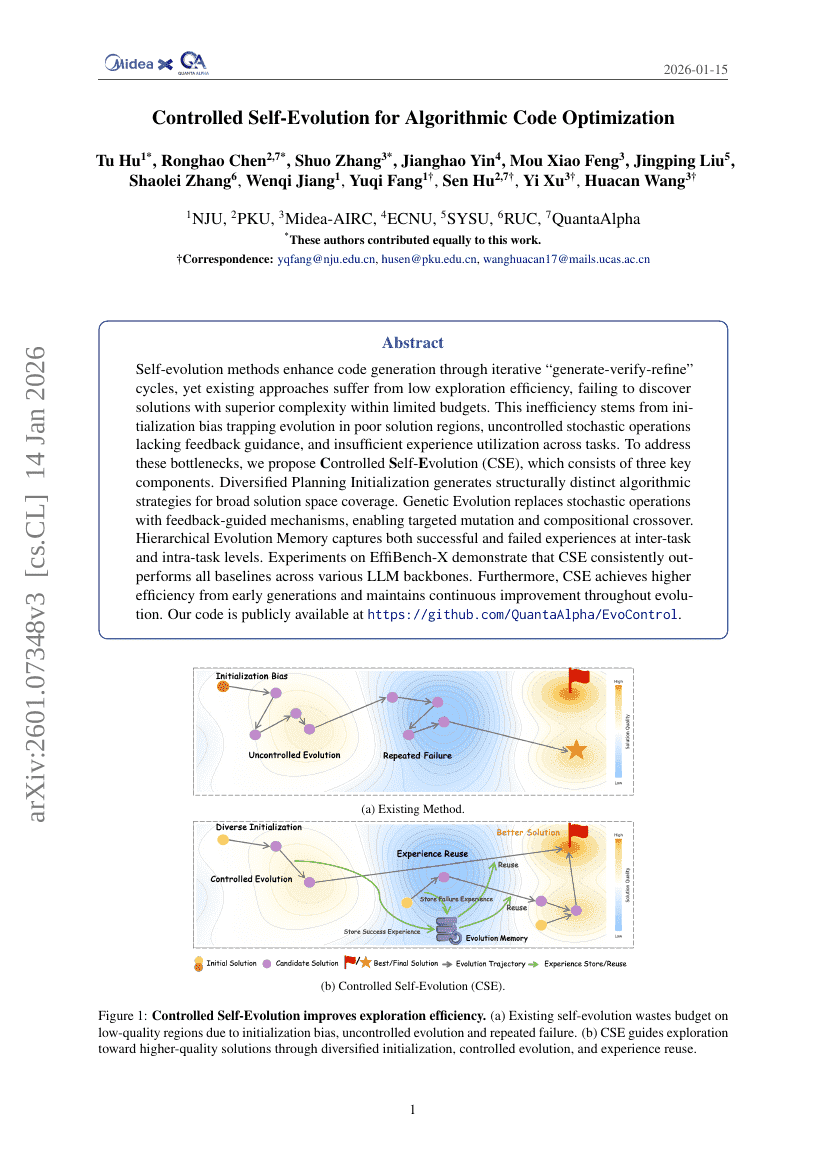
알고리즘 코드 최적화를 위한 통제된 자기진화
MAXS: LLM 에이전트를 활용한 메타적 적응 탐색
Nemotron-Math: Multi-Mode Supervision을 통한 수학적 추론의 효율적인 Long-Context Distillation
Gemini를 위한 프로덕션 준비 완료 프로브 구축
LFM2 기술 보고서
CoDance: 강건한 다중 주제 애니메이션을 위한 Unbind-Rebind 패러다임
어시스턴트 축: 언어 모델의 기본 성격 설정과 안정화
ABC-Bench: 실세계 개발에서 에이전트 기반 백엔드 코드 작성 성능 평가
멀티플렉스 사고: 토큰 단위 브랜치 앤 머지를 통한 추론
이론 모델이 사고의 사회를 생성한다
다중 에이전트 AI 시스템의 개발 및 문제에 관한 대규모 연구
ACoT-VLA: 비전-언어-행동 모델을 위한 행동 체인 오브 써Thought
개인화가 오도할 때: 개인화된 LLM에서 환각 현상을 이해하고 완화하기
RubricHub: 자동적 계층적 생성을 통한 종합적이고 고도로 구분 가능한 평가기준 데이터셋
암묵적 경험의 해방: 텍스트에서 도구 사용 궤적 합성하기
독한 사과 효과: AI 에이전트의 기술 확장에 의한 매개 시장의 전략적 조작
귀하의 그룹 상대적 우위는 편향되어 있습니다
STEM: 임베딩 모듈을 활용한 Transformer의 스케일링
노이즈 속에서 망가진다: 추론 모델이 문맥적 방해 요소에 어떻게 실패하는가
정적 도구를 넘어서: 과학적 추론을 위한 테스트 시점 도구 진화
VIBE: 시각적 지시 기반 편집기
협업형 다중 에이전트 테스트 시점 강화 학습을 통한 추론
희귀한 것을 보상하기: LLM에서 창의적 문제 해결을 위한 고유성 인지 강화 학습
도시 사회세마틱 세그멘테이션: 비전-언어 추론을 활용한 접근
STEP3-VL-10B 기술 보고서
SeedFold: 생물분자 구조 예측의 확장
Gemini 기술 보고서
Fast-ThinkAct: 말로 표현 가능한 잠재적 계획을 통한 효율적인 시각-언어-행동 추론
SkinFlow: 동적 시각 인코딩과 단계별 강화학습을 통한 개방형 피부과 진단을 위한 효율적인 정보 전송
A^3-Bench: 앵커 및 어트랙터 활성화를 통한 메모리 기반 과학적 추론 평가
알고리즘 코드 최적화를 위한 통제된 자기진화
MAXS: LLM 에이전트를 활용한 메타적 적응 탐색