HyperAI
Command Palette
Search for a command to run...
Papers
최신 AI 트렌드를 파악할 수 있도록 매일 업데이트되는 최첨단 AI 연구 논문
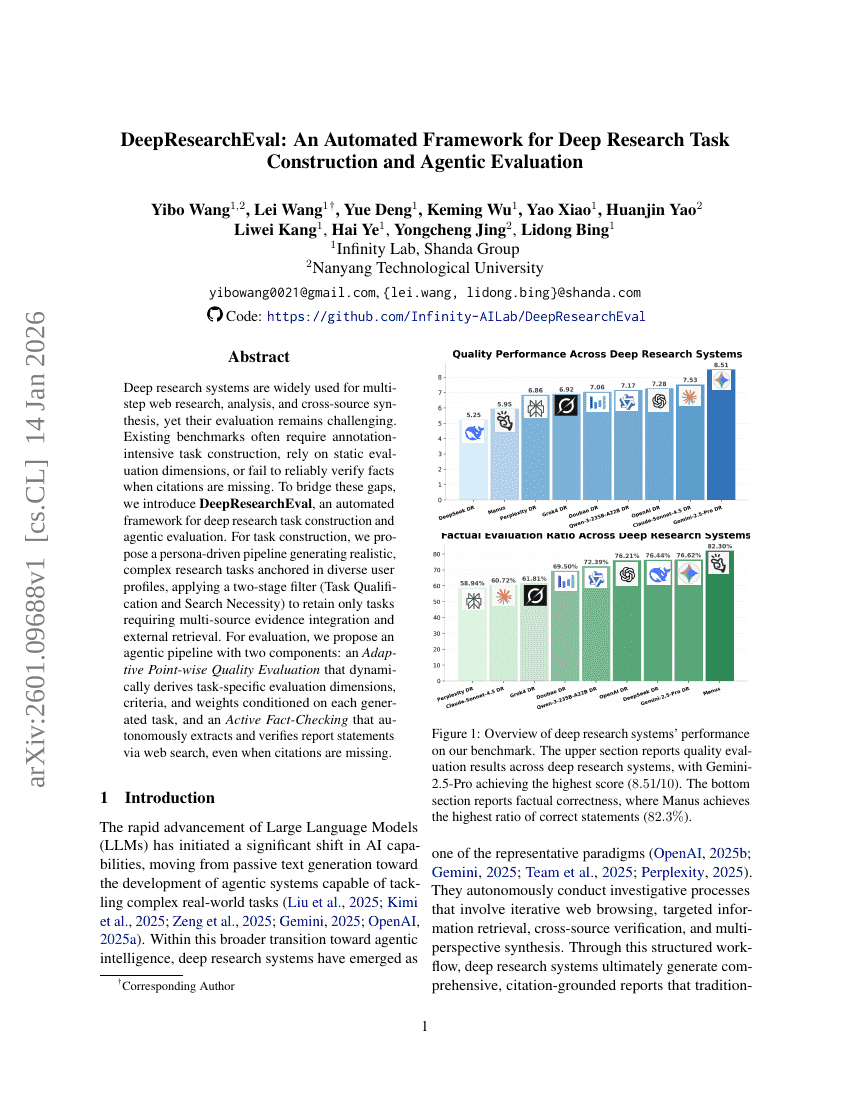
DeepResearchEval: 심층 연구 과제 구성 및 에이전트 평가를 위한 자동화된 프레임워크

형수 0의 사상에 의한 플래그 다양체로의 공간의 모티브적 클래스


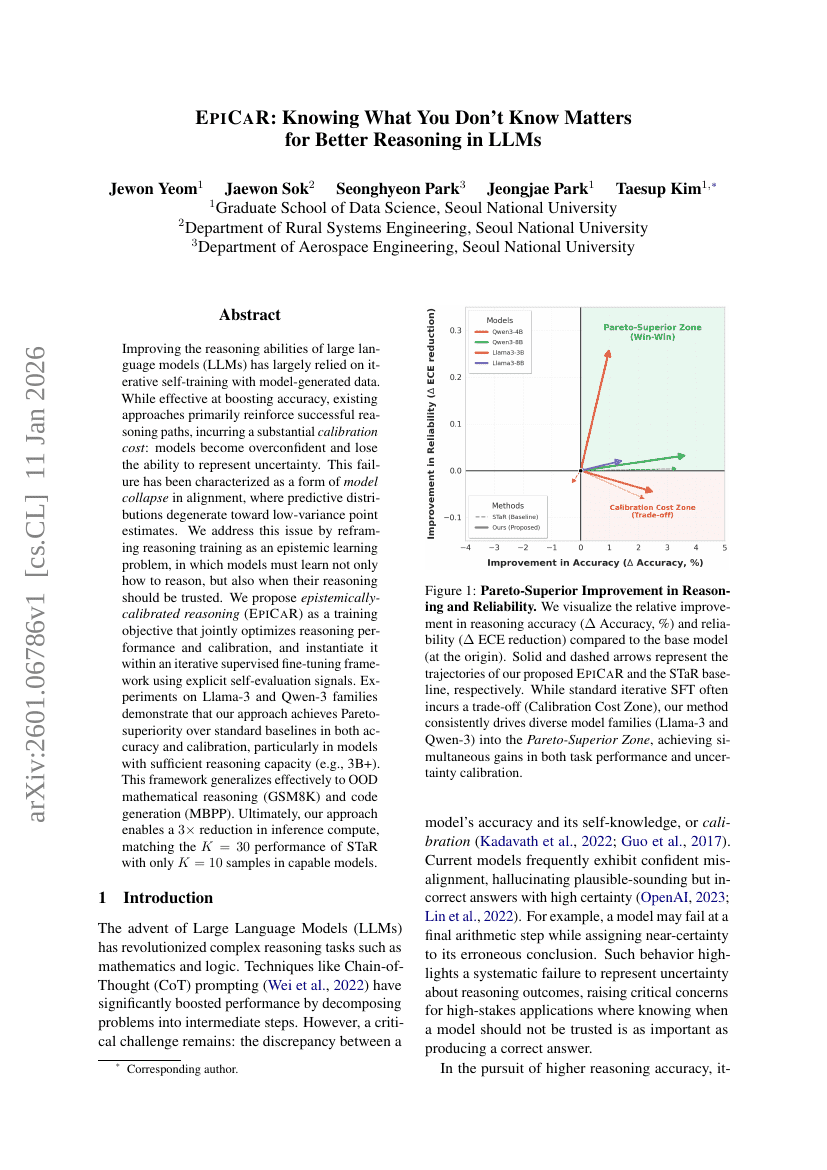











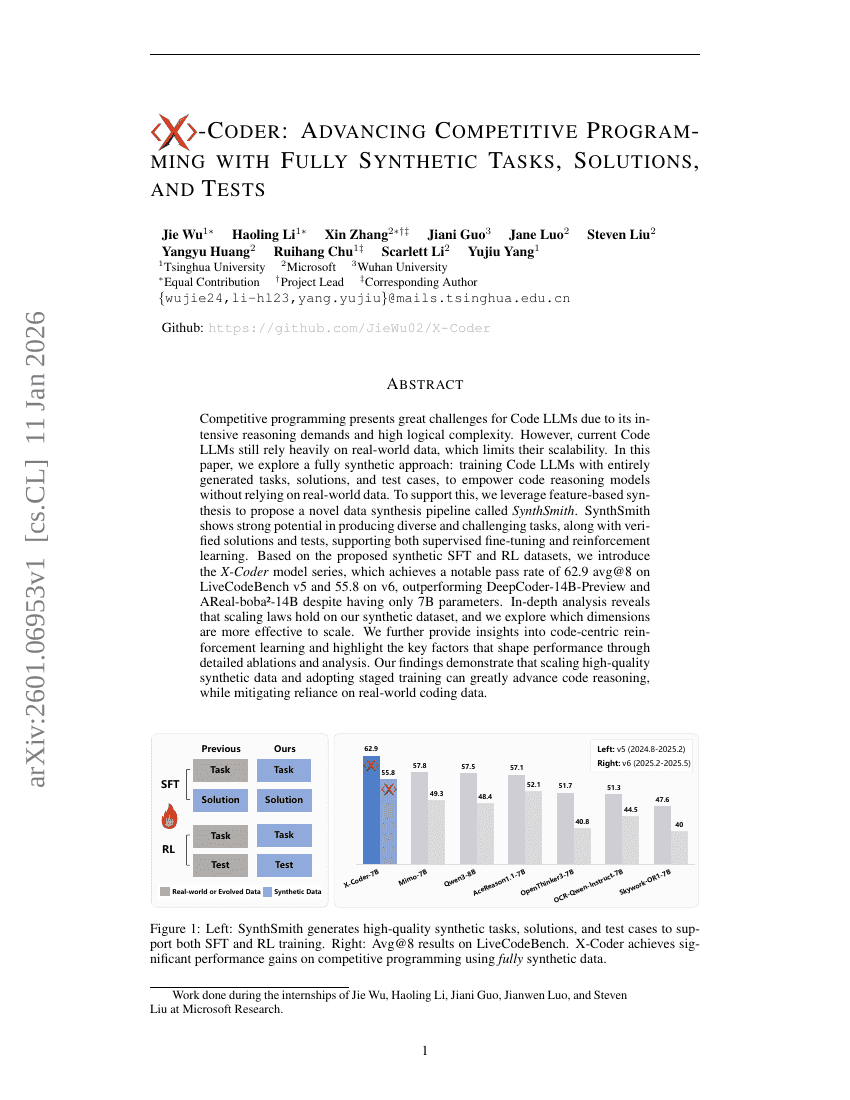
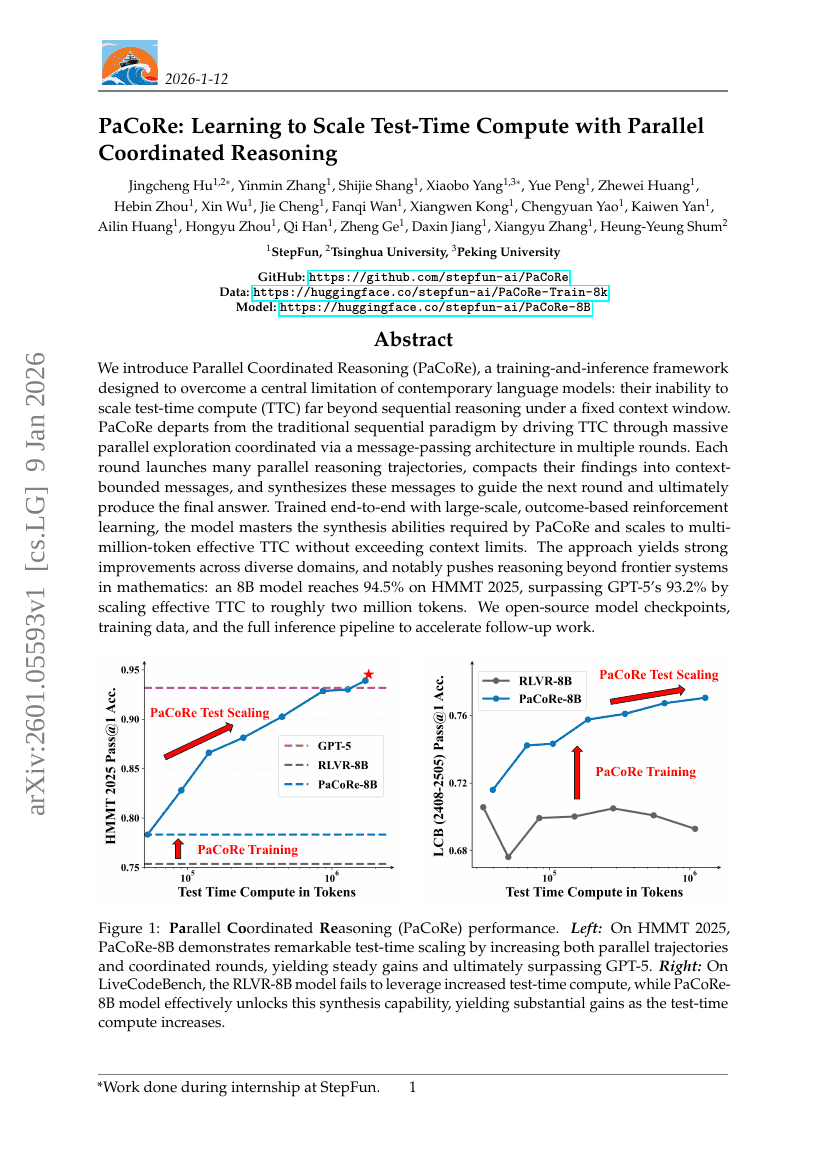











DeepResearchEval: 심층 연구 과제 구성 및 에이전트 평가를 위한 자동화된 프레임워크
형수 0의 사상에 의한 플래그 다양체로의 공간의 모티브적 클래스
UniversalRAG: 다양한 모달리티와 해상도를 가진 문헌 집합에서의 검색 증강 생성
후기 훈련에서 감독형 미세조정과 강화 학습의 비분리성에 관한 연구
EpiCaR: LLM에서 더 나은 추론을 위한 '모르는 것'을 아는 것이 중요하다
텍스트, 코드, 시각 정보의 정렬: 텍스트 기반 시각화를 위한 다중 목적 강화 학습 프레임워크
지속적 사전 훈련 중 대규모 언어 모델(LLM)은 어떻게 개념을 학습하는가?
JudgeRLVR: 효율적인 추론을 위한 먼저 판단하고 나서 생성하기
SnapGen++: 엣지 장치에서 효율적인 고해상도 이미지 생성을 위한 확산 트랜스포머의 잠재력 해방
비디오 생성을 위한 모션 어트리뷰션
VLingNav: 적응형 추론 및 시각 보조 언어 메모리를 활용한 Embodied Navigation
민스트랄 3
야생에서 잠재 동작 세계 모델 학습하기
제로 박사: 훈련 데이터 없이 자가진화하는 검색 에이전트
MHLA: 토큰 수준 다중 헤드를 통한 선형 어텐션의 표현력 복원
GlimpRouter: 사고의 하나의 토큰을 스캔함으로써 효율적인 공동 추론 구현
X-Coder: 완전히 합성된 작업, 해법 및 테스트를 통한 경쟁 프로그래밍의 발전
PaCoRe: 병렬 조정 추론을 통한 테스트 시 계산량 확장 학습
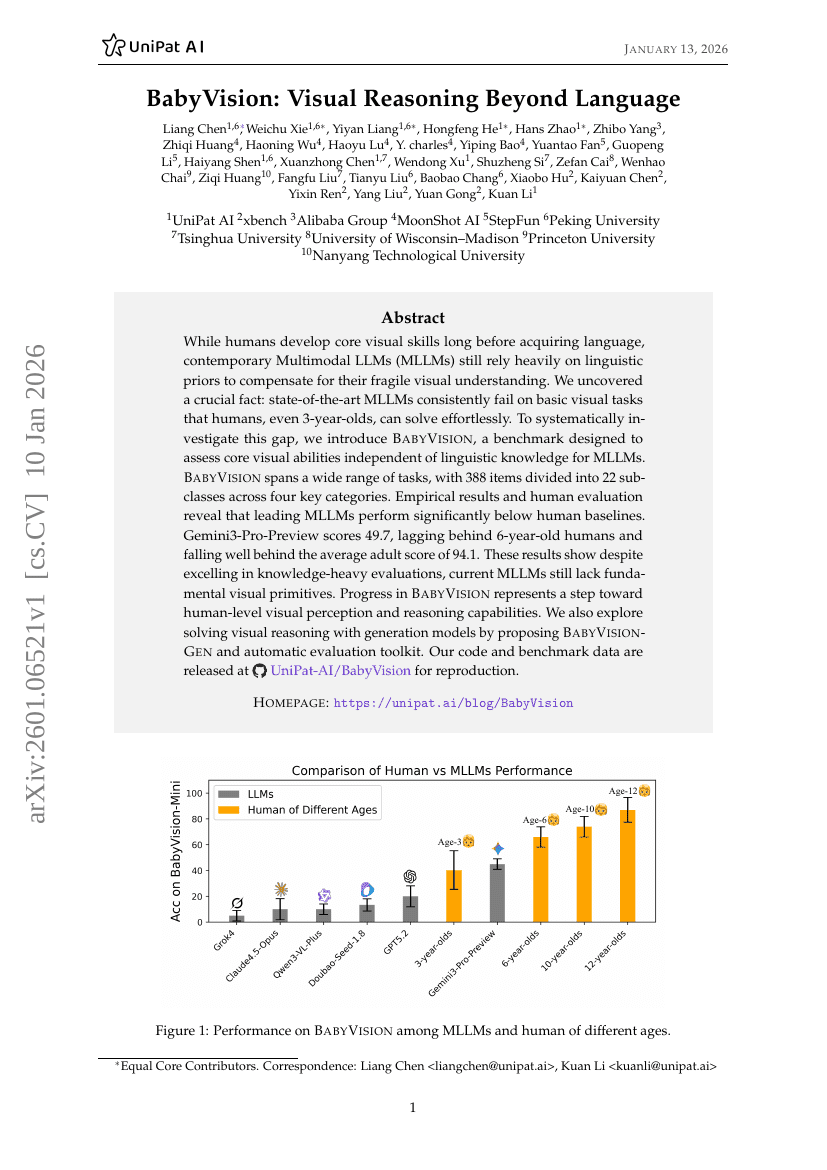
베비비전: 언어를 초월한 시각적 추론
시청, 추론, 탐색: 에이전트형 비디오 추론을 위한 오픈 웹 기반 비디오 딥 리서치 벤치마크
스케일러블 룩업을 통한 조건부 메모리: 대규모 언어 모델을 위한 새로운 희소성 축
EnvScaler: 프로그래머틱한 합성을 통한 LLM 에이전트를 위한 스케일링 도구 상호작용 환경
증거 연결하기: 인용 인식형 기준 보상이 있는 깊이 있는 검색 에이전트를 위한 강화 학습의 견고성
카리카처GS: 가우시안 곡률을 이용한 3D 가우시안 스플래터링 얼굴의 과장
사고의 분자 구조: 장거리 체인-오프-사고의 위상 구조 지도화
MMFormalizer: 월드와이드에서의 다중모달 자동공식화
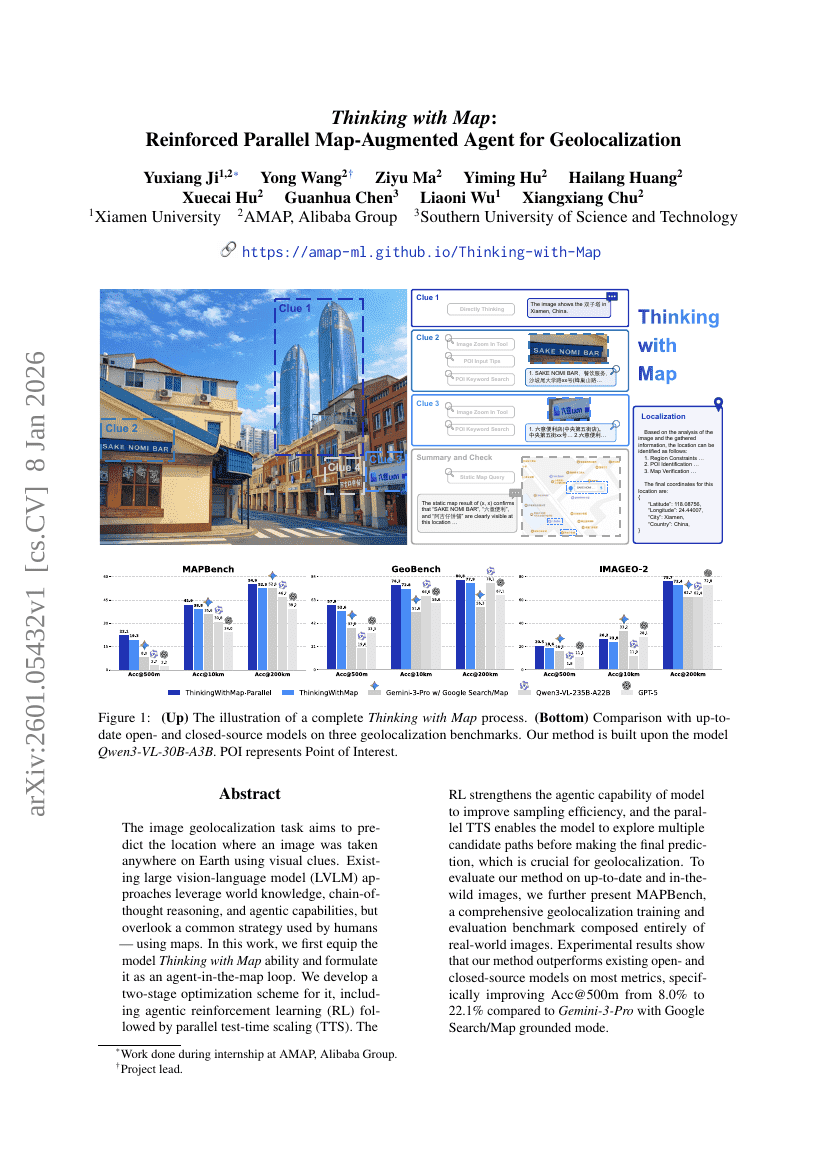
맵을 활용한 사고: 지오로컬라이제이션을 위한 강화된 병렬 맵 증강 에이전트
정방향 단일 출발지 최단 경로 문제의 정렬 장벽 극복
GR-Dexter 기술 보고서
VideoAuto-R1: 한 번 생각하고 두 번 답변하는 영상 자동 추론
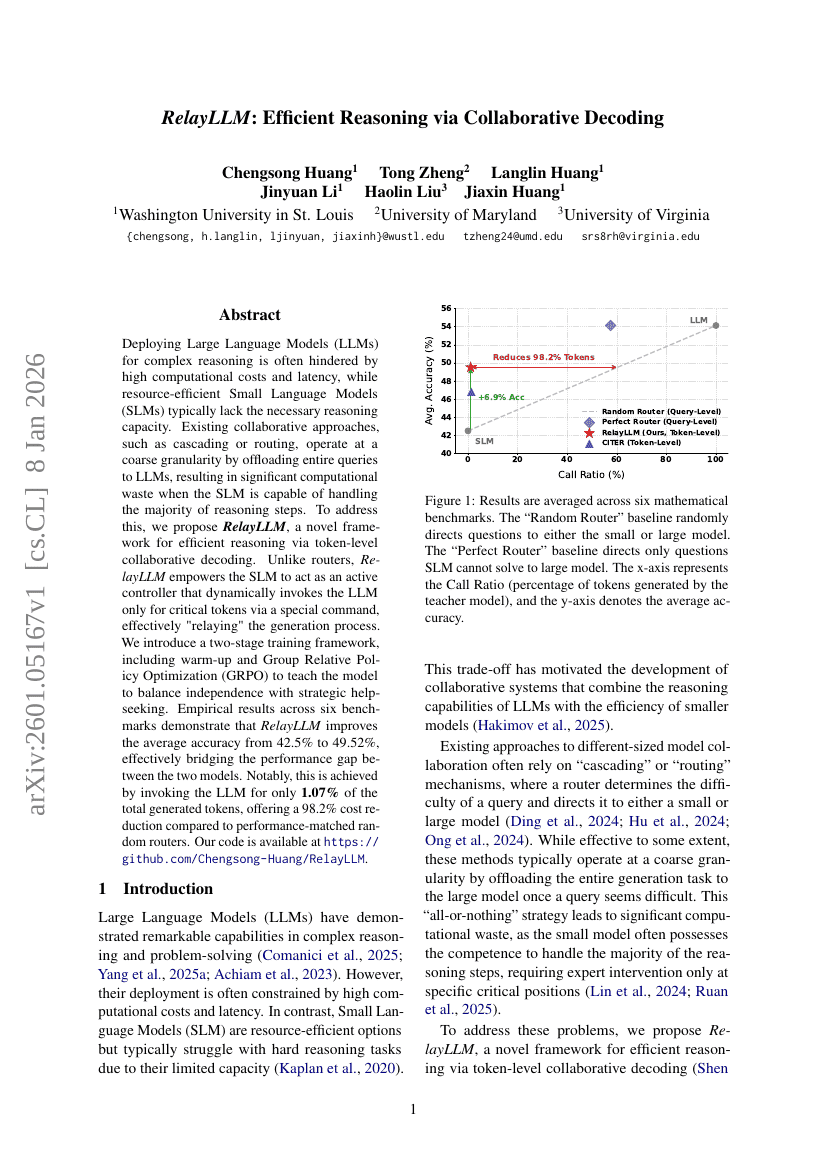
RelayLLM: 협업 디코딩을 통한 효율적인 추론
토큰 단위 LLM 협업을 위한 FusionRoute
UniversalRAG: 다양한 모달리티와 해상도를 가진 문헌 집합에서의 검색 증강 생성
후기 훈련에서 감독형 미세조정과 강화 학습의 비분리성에 관한 연구
EpiCaR: LLM에서 더 나은 추론을 위한 '모르는 것'을 아는 것이 중요하다
텍스트, 코드, 시각 정보의 정렬: 텍스트 기반 시각화를 위한 다중 목적 강화 학습 프레임워크
지속적 사전 훈련 중 대규모 언어 모델(LLM)은 어떻게 개념을 학습하는가?
JudgeRLVR: 효율적인 추론을 위한 먼저 판단하고 나서 생성하기
SnapGen++: 엣지 장치에서 효율적인 고해상도 이미지 생성을 위한 확산 트랜스포머의 잠재력 해방
비디오 생성을 위한 모션 어트리뷰션
VLingNav: 적응형 추론 및 시각 보조 언어 메모리를 활용한 Embodied Navigation
민스트랄 3
야생에서 잠재 동작 세계 모델 학습하기
제로 박사: 훈련 데이터 없이 자가진화하는 검색 에이전트
MHLA: 토큰 수준 다중 헤드를 통한 선형 어텐션의 표현력 복원
GlimpRouter: 사고의 하나의 토큰을 스캔함으로써 효율적인 공동 추론 구현
X-Coder: 완전히 합성된 작업, 해법 및 테스트를 통한 경쟁 프로그래밍의 발전
PaCoRe: 병렬 조정 추론을 통한 테스트 시 계산량 확장 학습
베비비전: 언어를 초월한 시각적 추론
시청, 추론, 탐색: 에이전트형 비디오 추론을 위한 오픈 웹 기반 비디오 딥 리서치 벤치마크
스케일러블 룩업을 통한 조건부 메모리: 대규모 언어 모델을 위한 새로운 희소성 축
EnvScaler: 프로그래머틱한 합성을 통한 LLM 에이전트를 위한 스케일링 도구 상호작용 환경
증거 연결하기: 인용 인식형 기준 보상이 있는 깊이 있는 검색 에이전트를 위한 강화 학습의 견고성
카리카처GS: 가우시안 곡률을 이용한 3D 가우시안 스플래터링 얼굴의 과장
사고의 분자 구조: 장거리 체인-오프-사고의 위상 구조 지도화
MMFormalizer: 월드와이드에서의 다중모달 자동공식화
맵을 활용한 사고: 지오로컬라이제이션을 위한 강화된 병렬 맵 증강 에이전트
정방향 단일 출발지 최단 경로 문제의 정렬 장벽 극복
GR-Dexter 기술 보고서
VideoAuto-R1: 한 번 생각하고 두 번 답변하는 영상 자동 추론
RelayLLM: 협업 디코딩을 통한 효율적인 추론
토큰 단위 LLM 협업을 위한 FusionRoute