Command Palette
Search for a command to run...
유연성의 함정: 확산 언어 모델에서 임의의 순서 제한이 추론 가능성을 어떻게 제한하는가
유연성의 함정: 확산 언어 모델에서 임의의 순서 제한이 추론 가능성을 어떻게 제한하는가
초록
확산 대규모 언어 모델(Diffusion Large Language Models, dLLMs)은 기존 LLMs의 고정된 왼쪽에서 오른쪽 순서 제약을 깨고, 임의의 순서로 토큰을 생성할 수 있도록 한다. 직관적으로 이 유연성은 고정된 자동회귀 경로를 엄격히 포함하는 해 공간을 제공하며, 수학 및 코딩과 같은 일반적인 작업에서 더 뛰어난 추론 능력을 이론적으로 가능하게 한다. 이에 따라 수많은 연구들이 dLLMs의 추론 능력을 유도하기 위해 강화학습(Reinforcement Learning, RL)을 활용해왔다. 본 논문에서는 반직관적인 사실을 밝힌다. 현재 형태의 임의 순서 생성은 dLLMs의 추론 범위를 넓히기보다 오히려 좁히는 경향이 있음을 보여준다. 우리는 dLLMs가 이 순서 유연성을 활용해 탐색에 핵심적인 역할을 하는 높은 불확실성의 토큰을 회피하려는 경향이 있음을 발견하였으며, 이로 인해 해 공간이 조기에 붕괴되는 현상이 발생한다. 이러한 관측은 기존 dLLMs를 위한 RL 접근 방식의 전제를 도전한다. 기존 접근 방식은 조합적 경로 처리와 계산이 불가능한 확률 추정과 같은 복잡성을 다루기 위해 상당한 노력을 기울이고 있으나, 이러한 노력은 오히려 유연성의 함정에 빠지게 만든다. 우리는 오히려 임의 순서 생성을 의도적으로 포기하고 표준적인 그룹 상대 정책 최적화(Group Relative Policy Optimization, GRPO)를 적용하는 것이 효과적인 추론을 유도하는 데 더 효과적임을 입증한다. 본 연구에서 제안하는 JustGRPO는 단순하지만 놀랍게도 효과적이다(예: GSM8K에서 89.1%의 정확도)면서도 dLLMs의 병렬 디코딩 능력을 완전히 유지한다. 프로젝트 페이지: https://nzl-thu.github.io/the-flexibility-trap
One-sentence Summary
Researchers from Tsinghua University and Alibaba Group reveal that arbitrary-order generation in diffusion LLMs (dLLMs) paradoxically narrows reasoning potential by bypassing high-uncertainty logical tokens. They propose JustGRPO, a minimalist RL method using standard autoregressive training that boosts performance (e.g., 89.1% on GSM8K) while preserving parallel decoding.
Key Contributions
- Diffusion LLMs’ arbitrary-order generation, while theoretically expansive, paradoxically narrows reasoning potential by letting models bypass high-uncertainty tokens that are critical for exploring diverse solution paths, as measured by Pass@k on benchmarks like GSM8K and MATH.
- The paper reveals that this “flexibility trap” stems from entropy degradation: models prioritize low-entropy tokens first, collapsing branching reasoning paths before they can be explored, unlike autoregressive decoding which forces confrontation with uncertainty at critical decision points.
- To counter this, the authors propose JustGRPO — a minimalist method that trains dLLMs under standard autoregressive order using Group Relative Policy Optimization — achieving strong results (e.g., 89.1% on GSM8K) while preserving parallel decoding at inference, without complex diffusion-specific RL adaptations.
Introduction
The authors leverage diffusion language models (dLLMs), which theoretically support arbitrary token generation order, to challenge the assumption that this flexibility enhances reasoning. Prior work assumed arbitrary-order decoding could unlock richer reasoning paths, leading to complex reinforcement learning (RL) methods designed to handle combinatorial trajectories and intractable likelihoods — but these approaches often rely on unstable approximations. The authors reveal that, counterintuitively, arbitrary order causes models to bypass high-uncertainty tokens critical for exploring diverse reasoning paths, collapsing the solution space prematurely. Their main contribution, JustGRPO, discards arbitrary-order complexity and trains dLLMs using standard autoregressive RL (Group Relative Policy Optimization), achieving strong results (e.g., 89.1% on GSM8K) while preserving parallel decoding at inference.
Dataset

- The authors use the official training splits of mathematical reasoning datasets, adhering to standard protocols from prior work (Zhao et al., 2025; Ou et al., 2025).
- For code generation, they adopt AceCoder-87K (Zeng et al., 2025), then filter it using the DiffuCoder pipeline (Gong et al., 2025) to retain 21K challenging samples that include verifiable unit tests.
- The data is used directly as training input without further mixture ratios or cropping; no metadata construction or additional preprocessing is mentioned beyond the described filtering.
Method
The authors leverage a diffusion-based framework for language modeling, where the core mechanism operates through a masked diffusion process. The model, referred to as a Masked Diffusion Model (MDM), generates sequences by iteratively denoising a partially masked input state xt, which is initialized from a fully masked sequence. This process is governed by a continuous time variable t∈[0,1], representing the masking ratio. In the forward process, each token in the clean sequence x0 is independently masked with probability t, resulting in the distribution q(xtk∣x0k), which either retains the original token or replaces it with a [MASK] token. Unlike traditional Gaussian diffusion models, MDMs directly predict the clean token at masked positions. A neural network pθ(x0∣xt) estimates the original token distribution, and the model is trained by minimizing the Negative Evidence Lower Bound, which simplifies to a weighted cross-entropy loss over the masked tokens.
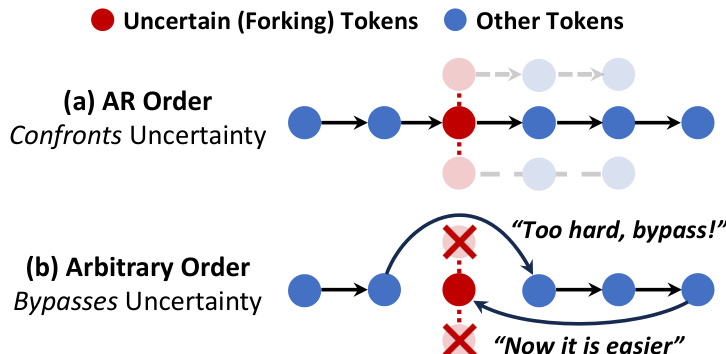
As shown in the figure below, the model's generation process can be constrained to follow an autoregressive (AR) order, where tokens are generated sequentially from left to right, or it can follow an arbitrary order, where tokens are generated in a non-sequential manner. The AR order approach confronts uncertainty by generating tokens in a structured, sequential fashion, which is beneficial for reasoning tasks. In contrast, the arbitrary order approach bypasses uncertainty by allowing for non-sequential generation, which can lead to suboptimal outcomes as indicated by the "Too hard, bypass!" and "Now it is easier" annotations. This distinction highlights the importance of the generation order in the model's performance.
To bridge the gap between the sequence-level denoising architecture of diffusion models and the autoregressive policy framework, the authors propose a method called JustGRPO. This method explicitly forgoes arbitrary-order generation during the reinforcement learning stage, transforming the diffusion language model into a well-defined autoregressive policy πθAR. The autoregressive policy is defined by constructing an input state x~t where the past tokens are observed and the future tokens are masked. The probability of the next token ot given the history o<t is defined as the softmax of the model logits at the position corresponding to ot. This formulation enables the direct application of standard Group Relative Policy Optimization (GRPO) to diffusion language models. The GRPO objective maximizes a clipped surrogate function with a KL regularization term, where the advantage is computed by standardizing the reward against the group statistics. This approach allows the model to achieve the reasoning depth of autoregressive models while preserving the inference speed of diffusion models.
Experiment
- Evaluated reasoning potential via Pass@k on dLLMs (LLaDA-Instruct, Dream-Instruct, LLaDA 1.5) across GSM8K, MATH500, HumanEval, MBPP: AR decoding outperforms arbitrary order in scaling with k, revealing broader solution space coverage (e.g., AR solves 21.3% more HumanEval problems at k=1024).
- Identified “entropy degradation” in arbitrary order: bypassing high-entropy logical tokens (e.g., “Therefore”, “Since”) collapses reasoning paths into low-entropy, pattern-matching trajectories, reducing exploration.
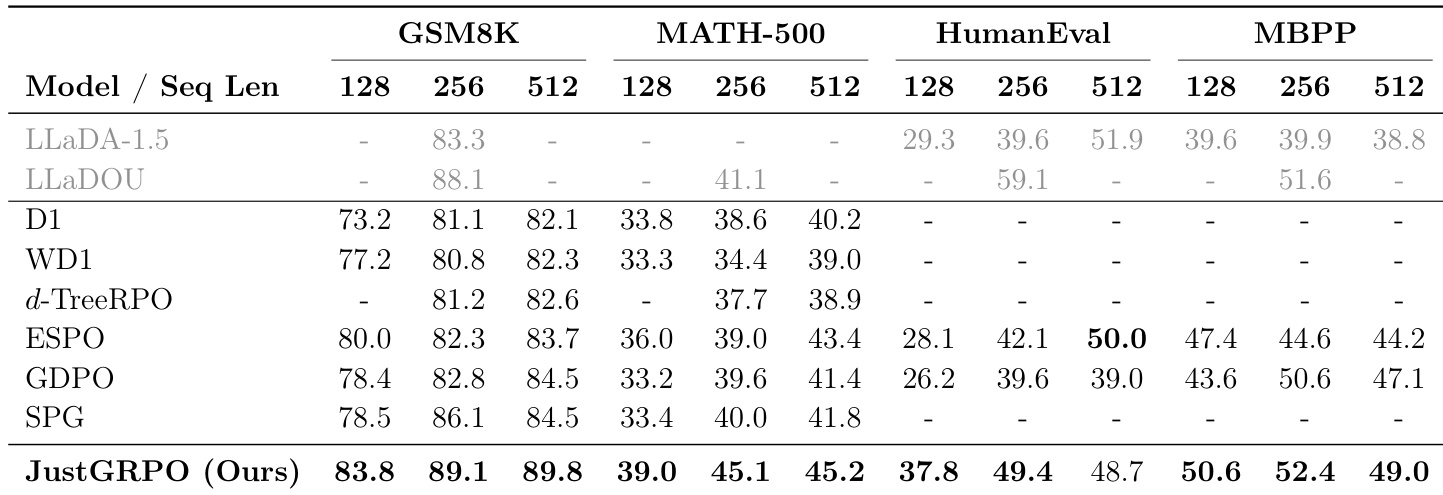
- Introduced JustGRPO: enforcing AR order during RL training on LLaDA-Instruct yields state-of-the-art results—89.1% on GSM8K (↑3.0% over SPG), 6.1% gain on MATH-500 over ESPO—with consistent gains across sequence lengths (128, 256, 512).
- JustGRPO preserves parallel decoding: under EB sampler, accuracy improves with parallelism (e.g., +25.5% on MBPP at ~5 tokens/step vs. +10.6% at 1 token/step), indicating robust reasoning manifold.
- Ablations confirm findings: smaller block sizes (more AR-like) improve Pass@k; higher temperatures help arbitrary order but can’t match AR; advanced samplers correlate highly with AR (0.970) but still underperform.
- Training efficiency: JustGRPO surpasses approximation-based ESPO in accuracy-wall-clock time trade-off; heuristic gradient restriction to top-25% entropy tokens accelerates convergence without performance loss.
The authors use JustGRPO to train diffusion language models with an autoregressive constraint during reinforcement learning, achieving state-of-the-art performance across multiple reasoning and coding benchmarks. Results show that this approach consistently outperforms methods designed for arbitrary-order decoding, with significant accuracy gains on GSM8K, MATH-500, HumanEval, and MBPP, while also preserving the model's parallel decoding capabilities at inference.
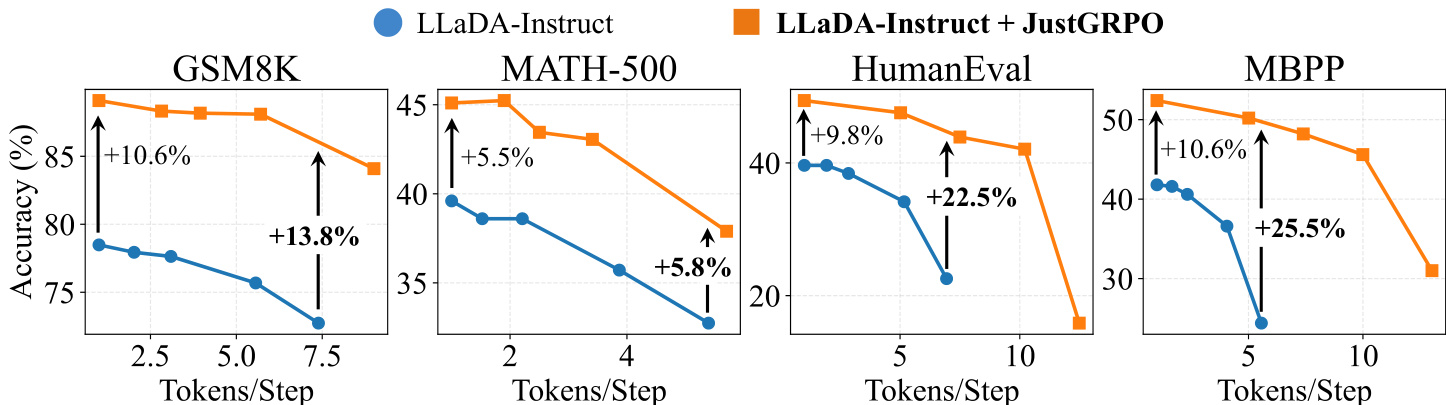
The authors use Pass@k to measure reasoning potential, showing that while arbitrary order performs competitively at k=1, AR order demonstrates significantly stronger scaling behavior as the number of samples increases. Results show that JustGRPO achieves state-of-the-art performance across all benchmarks, outperforming prior methods on GSM8K, MATH-500, HumanEval, and MBPP, with consistent gains across different generation lengths.
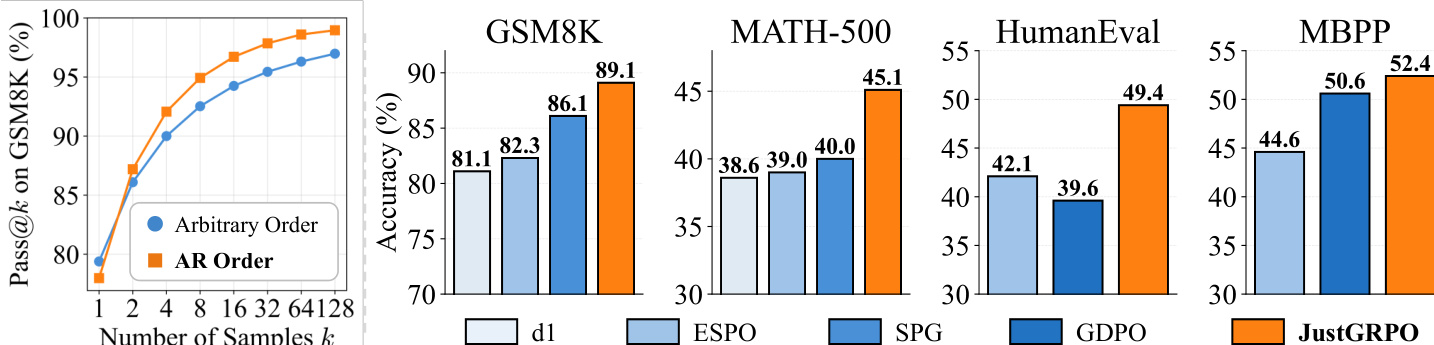
The authors use a system-level comparison to evaluate the performance of JustGRPO against existing reinforcement learning methods on reasoning and coding benchmarks. Results show that JustGRPO achieves state-of-the-art performance across all tasks and sequence lengths, outperforming previous methods such as SPG and ESPO, particularly on GSM8K and MATH-500, indicating that enforcing autoregressive order during training enhances reasoning capabilities.
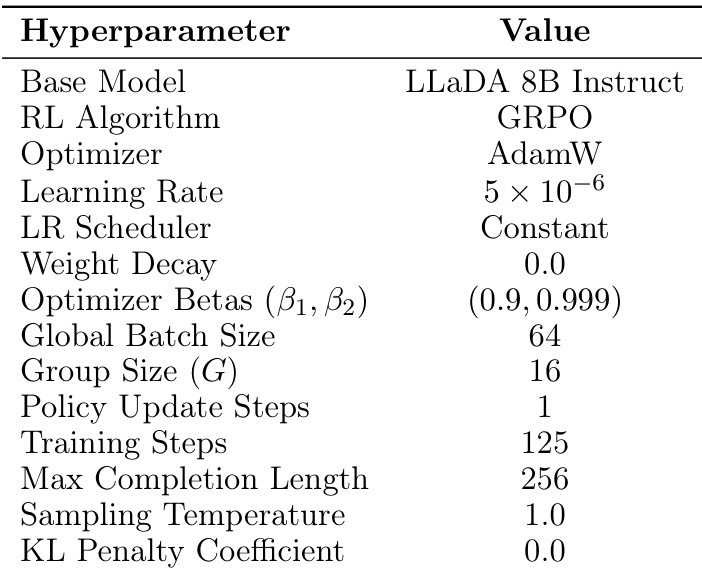
The authors use the GRPO algorithm with a base model of LLaDA 8B Instruct, training it for 125 steps with a constant learning rate of 5 × 10⁻⁶ and a group size of 16. The model achieves strong performance with a sampling temperature of 1.0 and no KL penalty, indicating that exact likelihood computation during training is effective despite higher computational cost.