Command Palette
Search for a command to run...
CUDA-L2:強化学習を活用した行列積演算におけるcuBLASを凌駕する性能
CUDA-L2:強化学習を活用した行列積演算におけるcuBLASを凌駕する性能
Songqiao Su Xiaofei Sun Xiaoya Li Albert Wang Jiwei Li Chris Shum
概要
本稿では、大規模言語モデル(LLM)と強化学習(RL)を統合したシステム「CUDA-L2」を提案する。CUDA-L2は、16ビット精度一般行列乗算(HGEMM)のCUDAカーネルを自動最適化することを目的としており、CUDAの実行速度をRLの報酬関数として用いる。本システムは1,000種類のカーネル設定を自動的に探索・最適化し、これまでに提唱された主要な行列乗算(matmul)基準手法、すなわち広く利用されている torch.matmul から、NVIDIAの非公開ライブラリである cuBLAS および cuBLASLt に至るまで、一貫して優れた性能を示す。 オフラインモード(時間的間隔を設けずにカーネルを連続実行)では、CUDA-L2は torch.matmul に対して平均で+22.0%の高速化を達成。cuBLAS に対しては最適なレイアウト設定(normal-normal NN および transposed-normal TN)を用いて+19.2%、cuBLASLt-heuristic(ヒューリスティックによる推奨アルゴリズムを基に選択)に対しては+16.8%、最も競争力の高い cuBLASLt-AutoTuning(cuBLASLt が提示する最大100候補から最速のアルゴリズムを選定)に対しては+11.4%の性能向上を示した。 サーバーモード(リアルタイム推論を模倣するようにランダムな間隔でカーネルを実行)では、各基準手法に対する高速化率がさらに向上し、それぞれ torch.matmul で+28.7%、cuBLAS で+26.0%、cuBLASLt-heuristic で+22.4%、cuBLASLt-AutoTuning で+15.9%の改善が得られた。 本研究は、HGEMM といった極めて性能最適化が進んだカーネルであっても、LLMを用いた強化学習による自動化アプローチによって、人間が実行可能なスケールでは不可能な広範な設定空間の体系的探索が可能であり、さらなる性能向上が実現可能であることを示している。プロジェクトおよびコードは、github.com/deepreinforce-ai/CUDA-L2 にて公開されている。
One-sentence Summary
The authors propose CUDA-L2, an LLM-guided reinforcement learning system that automatically optimizes half-precision matrix multiplication (HGEMM) kernels for LLM inference on A100 GPUs, achieving double-digit speedups over torch.matmul and Nvidia's cuBLAS libraries across 1,000 matrix configurations by systematically exploring optimization spaces impractical for manual tuning in prior frameworks.
Key Contributions
- Manual optimization of Half-precision General Matrix Multiply (HGEMM) kernels for LLMs is challenging due to varying matrix dimensions (M, N, K) requiring distinct strategies and poor transferability across GPU architectures, hindering scalable tuning despite matmul's critical role in computation.
- CUDA-L2 introduces an LLM-guided reinforcement learning system that automatically optimizes HGEMM kernels across 1,000 dimension configurations (all 103 combinations from {64, 128, ..., 16384}), leveraging multi-stage RL training, enhanced CUDA code pretraining, and NCU profiling metrics for architecture-specific decisions.
- Evaluated on 1,000 HGEMM configurations covering common LLM layer dimensions, CUDA-L2 achieves average speedups of +22.0% over torch.matmul and +11.4% over cuBLASLt-AutoTuning offline, with gains rising to +28.7% and +15.9% respectively in server-mode inference simulations.
Introduction
High-performance matrix multiplication (HGEMM) is critical for accelerating AI workloads on GPUs, where even marginal speed gains significantly impact large-scale model training and inference. Existing vendor libraries like cuBLAS set a high performance bar, but prior optimization frameworks such as CUDA-L1 struggled with HGEMM due to narrow training data limited to specific benchmarks and insufficient knowledge of modern GPU tools like CUTLASS, CuTe, and recent architectures. The authors overcome these limitations with CUDA-L2, a reinforcement learning system that generalizes beyond constrained benchmarks and integrates up-to-date hardware insights to surpass cuBLAS in HGEMM execution speed.
Dataset
The authors use a CUDA code dataset from two primary sources for continued pretraining. Key details:
-
Composition and sources:
Combines web-sourced CUDA code (cleaned via rule-based filtering and LLM-based extraction) with implementations from established libraries (PyTorch, ATen, CUTLASS, NVIDIA tutorials/examples). -
Subset specifics:
- Web sources: Raw code undergoes rigorous cleaning and segmentation; lacks natural instructional prompts.
- Library code: Directly integrated without additional filtering.
Both subsets are processed into instruction-context-code triplets.
-
Usage in training:
Triplets train DeepSeek 671B via continued pretraining. Each triplet pairs:
(1) LLM-generated instructions (via Claude Sonnet 4) describing code functionality,
(2) Retrieved documentation/examples from search queries based on instructions,
(3) Original CUDA code snippet.
This mixture develops general-purpose CUDA optimization and retrieval-augmented capabilities. -
Processing details:
No cropping applied. Metadata is constructed by generating descriptive prompts for raw code, then augmenting with retrieved context. Final triplets form the training split exclusively.
Method
The authors leverage a multi-stage reinforcement learning (RL) framework combined with large language models (LLMs) to autonomously generate and optimize HGEMM CUDA kernels. The system, CUDA-L2, extends its predecessor CUDA-L1 by incorporating domain-specific pretraining, fine-grained profiling feedback, and retrieval-augmented context to navigate the vast configuration space of matrix dimensions (M, N, K) and hardware constraints.
The training pipeline begins with continued pretraining on a diverse corpus of approximately 1,000 CUDA kernels drawn from established libraries such as PyTorch, ATen, and CUTLASS. These kernels span linear algebra, convolution, reduction, attention, and other operations, enabling the LLM to develop a broad understanding of CUDA idioms. During this phase, the model is trained using a contrastive RL strategy, where it compares generated kernel variants against reference implementations and receives rewards based on average speedup across test iterations. GRPO is employed for parameter updates, with smoothed and clipped rewards to mitigate reward hacking.
In the subsequent HGEMM-specific RL stage, the model is constrained to generate kernels for half-precision matrix multiplication under varying (M, N, K) configurations. The reward function is designed to balance performance, correctness, and code conciseness:
r(custom)=N1i=1∑N[tcustomitrefi−α⋅diffi]−βL(custom)where diffi measures the maximum element-wise deviation from an FP32 CPU ground truth, and L(custom) penalizes code length. This encourages the model to produce kernels that are not only fast but also numerically accurate and compact.
To guide optimization decisions, CUDA-L2 integrates NVIDIA Nsight Compute (NCU) profiling metrics—such as memory throughput, SM occupancy, and cache efficiency—into the RL context. This allows the model to reason about low-level hardware behavior rather than relying solely on end-to-end execution time. Generated kernels are compiled as standalone .cu files using nvcc, permitting the use of CUDA C/C++, CuTe, inline PTX, and CUTLASS templates, while excluding Python-based DSLs like Triton.
The model autonomously selects appropriate abstractions based on problem size: for small matrices, it favors lightweight kernels using raw WMMA intrinsics with minimal synchronization; for larger matrices, it adopts CuTe’s higher-level abstractions to manage complex tiled operations and multi-stage pipelining. This abstraction selection is reinforced by the reward’s preference for shorter code, which naturally favors CuTe’s expressiveness for intricate optimizations.
CUDA-L2 discovers and applies a suite of advanced optimization techniques, including shared memory bank conflict avoidance via swizzle patterns, multi-stage pipelining with configurable buffering stages, asynchronous memory copies, register accumulation, and block swizzling to improve L2 cache locality. It also determines optimal parameterizations for these techniques—such as swizzleStride or n_stage—based on the specific (M, N, K) triplet.
One notable innovation is the use of double-buffered register fragments with ping-pong execution, which overlaps data prefetching with tensor core computation to eliminate stall cycles. For configurations with sufficient register headroom and large K, this technique significantly improves throughput. Similarly, the model employs aggressive multi-step prefetching, loading data multiple iterations ahead to fully overlap memory and compute pipelines, particularly beneficial for high-iteration-count scenarios.
In the epilogue phase, CUDA-L2 eliminates unnecessary intermediate tensors when register and shared memory layouts align, performing direct register-to-shared-memory transfers using wide data types (e.g., uint128_t) to reduce copy operations and improve bandwidth utilization. As shown in the figure below, this direct wide copy replaces the standard two-step approach involving an intermediate tensor.

Additionally, CUDA-L2 modifies prefetch scheduling by staggering A and B matrix loads around the MMA operation. Instead of issuing both prefetches consecutively, it interleaves them: A is prefetched first, then MMA executes on already-loaded data, and finally B is prefetched. This increases instruction-level parallelism and better utilizes execution units, particularly when computation is the bottleneck. The figure below illustrates this staggered prefetching strategy compared to the standard consecutive approach.

Experiment
- Validated CUDA-L2's automatic HGEMM kernel optimization across 1,000 (M, N, K) configurations covering common LLM dimensions
- Achieved 22.0% speedup over torch.matmul in offline mode and 28.7% in server mode on A100 GPUs
- Surpassed cuBLAS-max by 19.2% (offline) and 26.0% (server) using optimal NN/TN layouts
- Outperformed cuBLASLt-heuristic by 16.8% (offline) and 22.4% (server) across 1,000 configurations
- Exceeded cuBLASLt-AutoTuning (100-algorithm search) by 11.4% (offline) and 15.9% (server) with consistent win rates of 79.3%-95.7%
- Demonstrated larger gains for smaller matrices (up to 1.4× speedup) where GPU underutilization allowed optimization opportunities
The authors use CUDA-L2 to benchmark against multiple baselines across 1,000 matrix configurations, reporting mean speedups in both offline and server modes. Results show CUDA-L2 consistently outperforms all baselines, with the largest gains over torch.matmul (22.0% offline, 28.7% server) and the strongest baseline cuBLASLt-AutoTuning-max (11.4% offline, 15.9% server), while maintaining win rates above 79% across all comparisons.
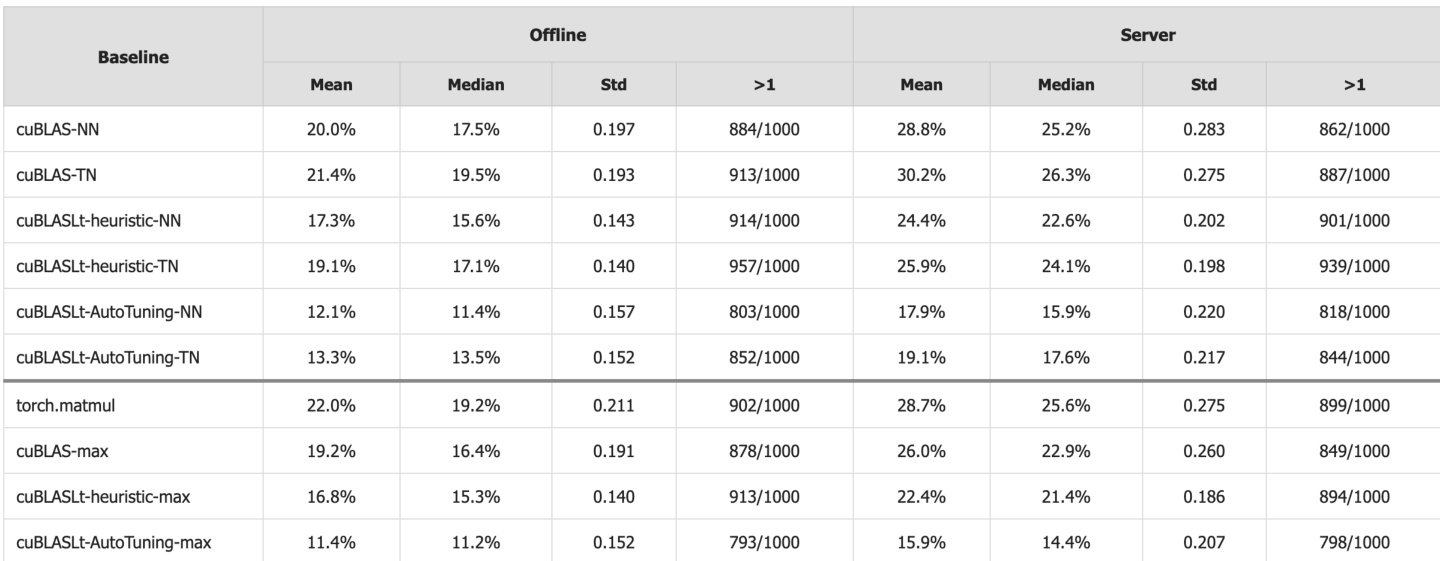
The authors use CUDA-L2 to benchmark against major HGEMM baselines across 1,000 matrix configurations, showing consistent speedups in both offline and server modes. Results show CUDA-L2 delivers 11.4% to 22.0% average speedups over baselines in offline mode, increasing to 15.9% to 28.7% in server mode, with further gains when selecting the faster of CUDA-L2 or baseline per configuration. The system outperforms even the most competitive cuBLASLt-AutoTuning, confirming its effectiveness in automating kernel optimization at scale.