Command Palette
Search for a command to run...
Nemotron-Cascade:汎用推論モデル向けカスケード強化学習のスケーリング
Nemotron-Cascade:汎用推論モデル向けカスケード強化学習のスケーリング
概要
強化学習(RL)を用いた汎用的推論モデルの構築には、推論時の応答長や検証遅延に顕著なドメイン間の異質性が伴い、これによりRLインフラの構築が複雑化し、学習速度が低下するだけでなく、学習カリキュラム(例:応答長の拡張)やハイパーパラメータ選定も困難となる。本研究では、汎用的推論モデルであるNemotron-Cascadeを構築するため、階層的ドメイン別強化学習(Cascade RL)を提案する。この手法により、指示処理モードと深層思考モードの両方で動作可能なモデルの実現が可能となる。従来の異なるドメインからの異質なプロンプトを混合するアプローチとは異なり、Cascade RLは順次的かつドメイン別に強化学習を実行することで、エンジニアリングの複雑性を低減しつつ、幅広いベンチマークにおいて最先端の性能を達成している。特に、アライメントのためのRLHFを前段階として用いることで、単なる好み最適化以上の推論能力の向上が実現され、その後のドメイン別RLVR段階では、以前のドメインで達成されたベンチマーク性能をほとんど低下させず、場合によってはさらに向上させることが確認されている(図1を参照)。本研究で開発した14Bパラメータのモデルは、RL処理を経た後、SFT教師モデルであるDeepSeek-R1-0528を上回り、LiveCodeBench v5/v6/Proにおいて優れた性能を示し、2025年国際情報オリンピック(IOI)では銀メダル相当の成績を収めた。本研究の学習プロトコルおよびデータレシピは、透明性を重視して公開している。
One-sentence Summary
The authors propose Nemotron-Cascade reasoning models using cascaded domain-wise reinforcement learning (Cascade RL), which processes domains sequentially instead of blending heterogeneous prompts to reduce infrastructure complexity. This approach, enhanced by RLHF pre-training that significantly boosts reasoning beyond alignment, enables their 14B model to outperform the DeepSeek-R1 teacher on LiveCodeBench and achieve a silver medal in the 2025 IOI.
Key Contributions
- Cascade RL addresses cross-domain heterogeneity in reinforcement learning for reasoning models by replacing blended prompt training with sequential domain-wise reinforcement learning stages, reducing engineering complexity and enabling effective training curricula without domain interference.
- The method leverages RLHF as an initial step to significantly boost reasoning capabilities beyond standard alignment, and subsequent domain-wise reinforcement learning stages maintain or improve prior domain performance due to resistance to catastrophic forgetting.
- The 14B Nemotron-Cascade model outperforms its SFT teacher on LiveCodeBench v5/v6/Pro and achieves silver-medal performance in the 2025 International Olympiad in Informatics, demonstrating state-of-the-art results across multiple reasoning benchmarks.
Introduction
Reinforcement learning (RL) is critical for advancing general-purpose language models with robust reasoning capabilities, but training such models faces significant challenges due to domain heterogeneity: math tasks use fast symbolic verification, code generation requires slow execution-based checks, and alignment relies on reward models. This diversity complicates infrastructure, slows training, and hinders hyperparameter optimization, while prior joint-training approaches—like those in DeepSeek-R1 and Qwen3—struggle to unify "thinking" (long-chain reasoning) and "instruct" (instant-response) modes without degrading reasoning performance. The authors address this by scaling cascaded reinforcement learning (Cascade RL), which sequences domain-specific RL stages (e.g., math before code) to leverage verification speed differences, prevent catastrophic forgetting, and enable a single open-weight model—Nemotron-Cascade—that achieves state-of-the-art results across math, code, science, and instruction-following tasks while operating effectively in both thinking and non-thinking modes.
Dataset
The authors curate a multi-domain dataset for training, structured as follows:
-
General-Domain Data:
- 2.8 million samples (3.2 billion tokens) sourced from diverse tasks including dialogue, QA, creative writing, safety, instruction following, and knowledge-intensive domains (e.g., law, ethics).
- Processed by generating parallel responses via DeepSeek-R1-0528 (thinking mode) and DeepSeek-V3-0324 (non-thinking mode) with 16K max tokens; low-quality outputs filtered via cross-validation with Qwen2.5-32B-Instruct; multi-turn conversations augmented by rewriting single-turn samples or random concatenation.
-
Math Reasoning Data:
- Stage-1: 2.77 million samples from AceMath, NuminaMath, and OpenMathReasoning (353K prompts, 7.8 responses each; 16K max tokens), decontaminated via 9-gram overlap filtering.
- Stage-2: 1.88 million samples from filtered Stage-1 prompts (163K prompts, 11.5 responses each; 32K max tokens), generated by DeepSeek-R1-0528 for detailed reasoning trajectories. All in thinking mode.
-
Code Reasoning Data:
- Stage-1: 1.42 million samples from TACO, APPs, and OpenCodeReasoning (172K prompts, 8.3 responses each; 16K max tokens), deduplicated and decontaminated.
- Stage-2: 1.39 million samples from OpenCodeReasoning (79K prompts, 17.6 responses each; 32K max tokens). All in thinking mode.
-
Science Reasoning Data:
- 289K Stage-1 and 345K Stage-2 samples from S1K and Llama-Nemotron datasets, filtered for scientific rigor and augmented with synthetic questions via DeepSeek-R1-0528; decontaminated via 9-gram overlap. Stage-2 data upsampled 2× during training.
-
Tool Calling Data:
- 310K conversations (1.41 million turns) from Llama-Nemotron, covering single/multi-turn interactions with up to 4.4 tools per conversation; responses generated by Qwen3-235B-A22B in thinking mode.
-
Software Engineering Data:
- Code Repair: 127K high-quality samples (17K SWE-Bench-Train, 17K SWE-reBench, 18K SWE-Smith, 77K SWE-Fixer-Train), filtered via Unidiff similarity ≥0.5.
- Localization: 92K samples (recall=1.0); Test Generation: 31K samples (syntax-error-free). All upsampled 3× in Stage-2 training.
The dataset is used in two-stage supervised fine-tuning:
- Stage-1 blends general-domain data with Stage-1 math/code/science subsets.
- Stage-2 combines Stage-2 math/code/science data (with science upsampled 2× and software engineering upsampled 3×), tool calling data, and general-domain data at 32K max tokens. All reasoning-focused data uses thinking-mode formatting to encourage step-by-step outputs.
Method
The authors leverage a cascaded reinforcement learning (Cascade RL) framework to train Nemotron-Cascade, a general-purpose reasoning model capable of operating in both instruct and deep thinking modes. The training pipeline begins with a multi-stage supervised fine-tuning (SFT) phase, which equips the base model with foundational capabilities across diverse domains including math, coding, science, tool use, and software engineering. This is followed by a sequence of domain-specific RL stages—RLHF, Instruction-Following RL, Math RL, Code RL, and SWE RL—applied in a progressive, domain-wise manner to enhance reasoning performance while minimizing catastrophic forgetting.
Refer to the framework diagram, which illustrates the sequential flow from the base model through SFT and the cascaded RL stages to the final Nemotron-Cascade model. The SFT curriculum is structured in two stages: Stage 1 (16K tokens) introduces general-domain data alongside math, science, and code reasoning data, with thinking-mode responses for the latter; Stage 2 (32K tokens) extends response length and incorporates tool use and software engineering datasets, further refining the model’s reasoning capacity.
As shown in the figure below, the model’s interaction schema is governed by a custom chat template that supports explicit control over generation mode. The /think and /no_think flags are appended to individual user prompts—rather than placed in the system prompt—to enable both global and local mode switching within a conversation. For tool calling, available functions are declared in the system prompt within tags, and the model is instructed to emit tool calls enclosed in <tool_call> and <tool_call> tags. This design simplifies mode control compared to prior approaches and ensures reliable transitions without performance degradation.

The RL training is conducted using the Group Relative Policy Optimization (GRPO) algorithm with strict on-policy updates, ensuring stability and mitigating entropy collapse. The GRPO objective is simplified by removing the KL divergence term, reducing it to a standard REINFORCE objective with group-normalized rewards and token-level loss:
IGRPO(θ)=E(q,a)∼D,{oi}i=1G∼πθ(⋅∣q)∑i=1G∣oi∣1i=1∑Gt=1∑∣oi∣A^i,t,whereA^i,t=std({ri}i=1G)ri−mean({ri}i=1G)forallt,where {ri}i=1G denotes the group of rewards assigned to sampled responses for a given question q, verified against ground-truth answers in RLVR stages or scored by a reward model in RLHF.
The RLHF stage initializes the cascade and improves response quality by reducing verbosity and repetition, which enhances reasoning efficiency in subsequent stages. The reward model for RLHF is trained on pairwise human preferences using the Bradley–Terry objective, initialized from Qwen2.5-72B-Instruct. For unified models, RLHF is performed in both thinking and non-thinking modes with equal batch allocation.
Instruction-Following RL (IF-RL) is applied next, with distinct strategies for unified and dedicated thinking models. For unified models, IF-RL is conducted exclusively in non-thinking mode to avoid degrading human alignment, while for thinking models, a combined reward function integrates instruction-following verification with normalized human preference scores:
ri={RIF(oi)+sigmoid(R^RM(oi)),0,ifRIF(oi)=1otherwise,thereinR^RM(oi)=std({RRM(oi)}i=1G)RRM(oi)−mean({RRM(oi)}i=1G)Math RL follows, employing a staged response length extension curriculum (24K → 32K → 40K) to progressively deepen reasoning chains. Dynamic filtering is applied per epoch to retain only problems that provide meaningful gradient signals, ensuring stable training. Code RL is then performed on the Math RL checkpoint, using a fixed 44K–48K response length without overlong filtering.
The final stage, SWE RL, targets software engineering tasks using an execution-free verifier that computes reward based on lexical and semantic similarity between generated and ground-truth patches:
r(p^,p∗)=⎩⎨⎧1,0,−1,ssem(p^,p∗),ifslex(p^,p∗)=1,p^isidenticaltotheoriginalcodesnippetifp^cannotbeparsed,otherwise,where semantic similarity is assessed via a 72B LLM prompted with a yes/no question. Training employs a two-stage context extension curriculum (16K → 24K input tokens) to stabilize long-context learning. The entire pipeline culminates in the Nemotron-Cascade model, which demonstrates state-of-the-art performance across multiple benchmarks, including silver-medal results in the 2025 IOI.
Experiment
- Cascade RL framework validated across human-feedback alignment, instruction following, math, competitive programming, and software engineering, showing domain-specific RL stages rarely degrade prior performance and enable tailored hyperparameters.
- Nemotron-Cascade-14B-Thinking achieved 78.0 on LiveCodeBench v5 and 74.8 on v6, surpassing DeepSeek-R1-0528 (74.8/73.3) and Gemini-2.5-Pro-06-05, while securing silver medal at IOI 2025.
- Unified Nemotron-Cascade-8B closed the reasoning performance gap with dedicated 8B-Thinking models and achieved 75.3 on LiveCodeBench v5, matching DeepSeek-R1-0528 despite its 671B size.
- Nemotron-Cascade-14B-Thinking reached 43.1% pass@1 on SWE-bench Verified, exceeding specialized models DeepSWE-32B (42.2%) and SWE-agent-LM-32B (40.2).
- RLHF with 72B reward models maximized ArenaHard performance and improved math/code benchmarks by 3% over smaller reward models, while preserving response conciseness.
- Code RL with temperature 1.0 boosted LiveCodeBench scores by reducing verbosity and enhancing token efficiency, with 8B/14B models gaining 3-4 points post-training.
- SWE RL combined generation-retrieval localization and execution-free rewards, enabling 14B model to achieve 43.1% resolve rate and 53.8% best@32 via test-time scaling.
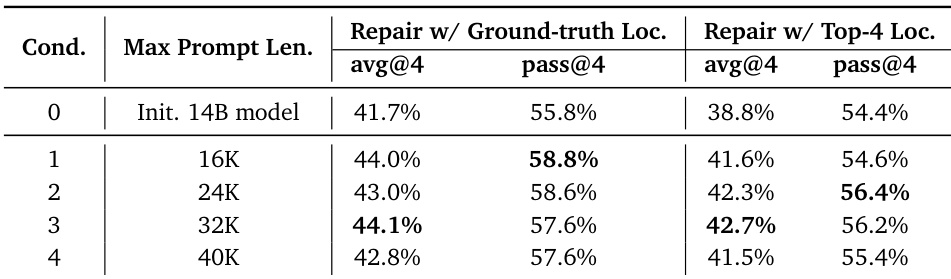
The authors evaluate the impact of maximum prompt length on code repair performance using a 14B model, finding that performance peaks at 24K–32K prompt length and degrades at 40K. When using ground-truth file localization, the model achieves 44.1% avg@4 and 57.6% pass@4 at 32K, while top-4 retrieved localization yields 42.7% avg@4 and 56.2% pass@4 under the same condition. Results suggest that longer prompts improve repair capability up to a point, beyond which noise and context limitations reduce effectiveness.
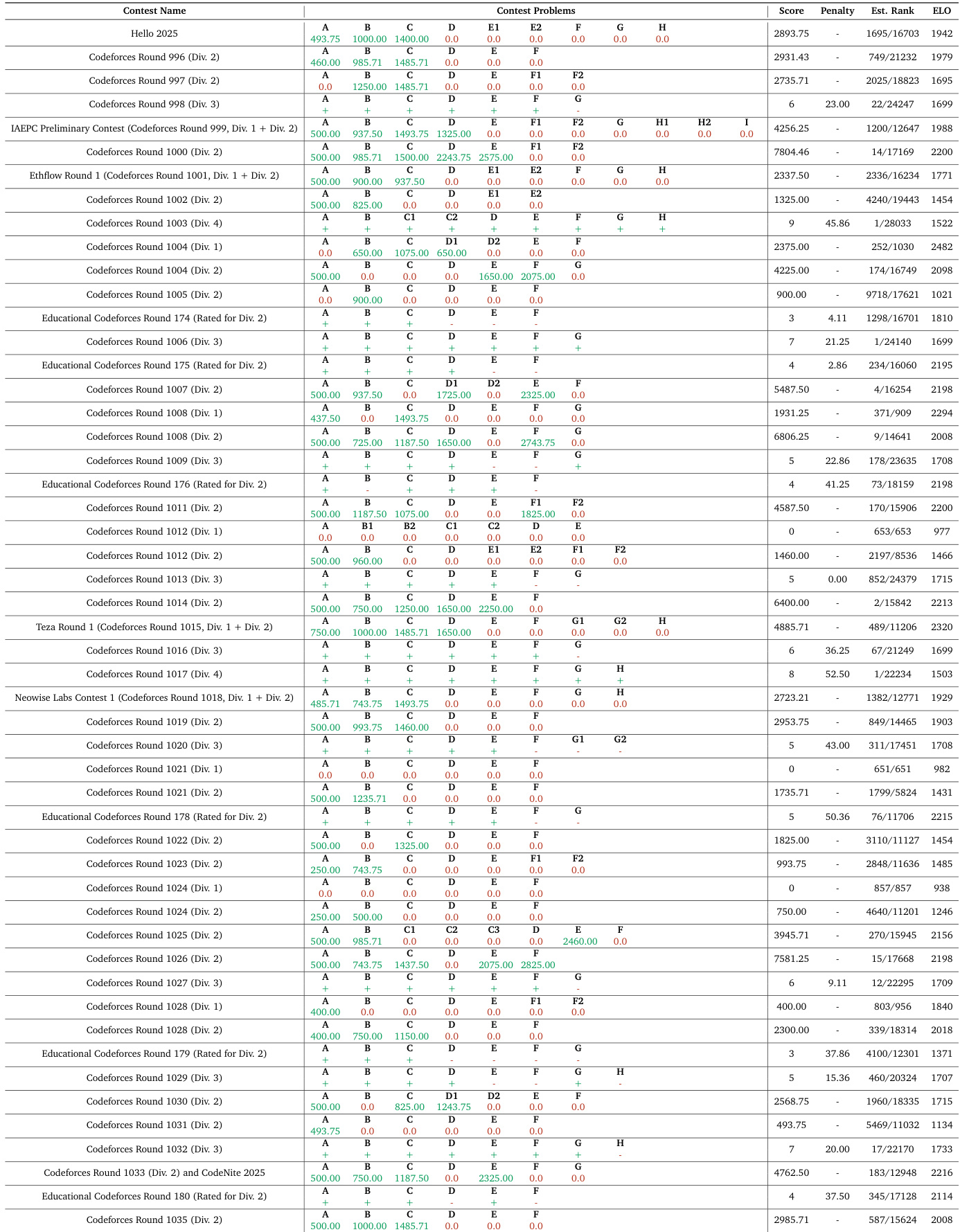
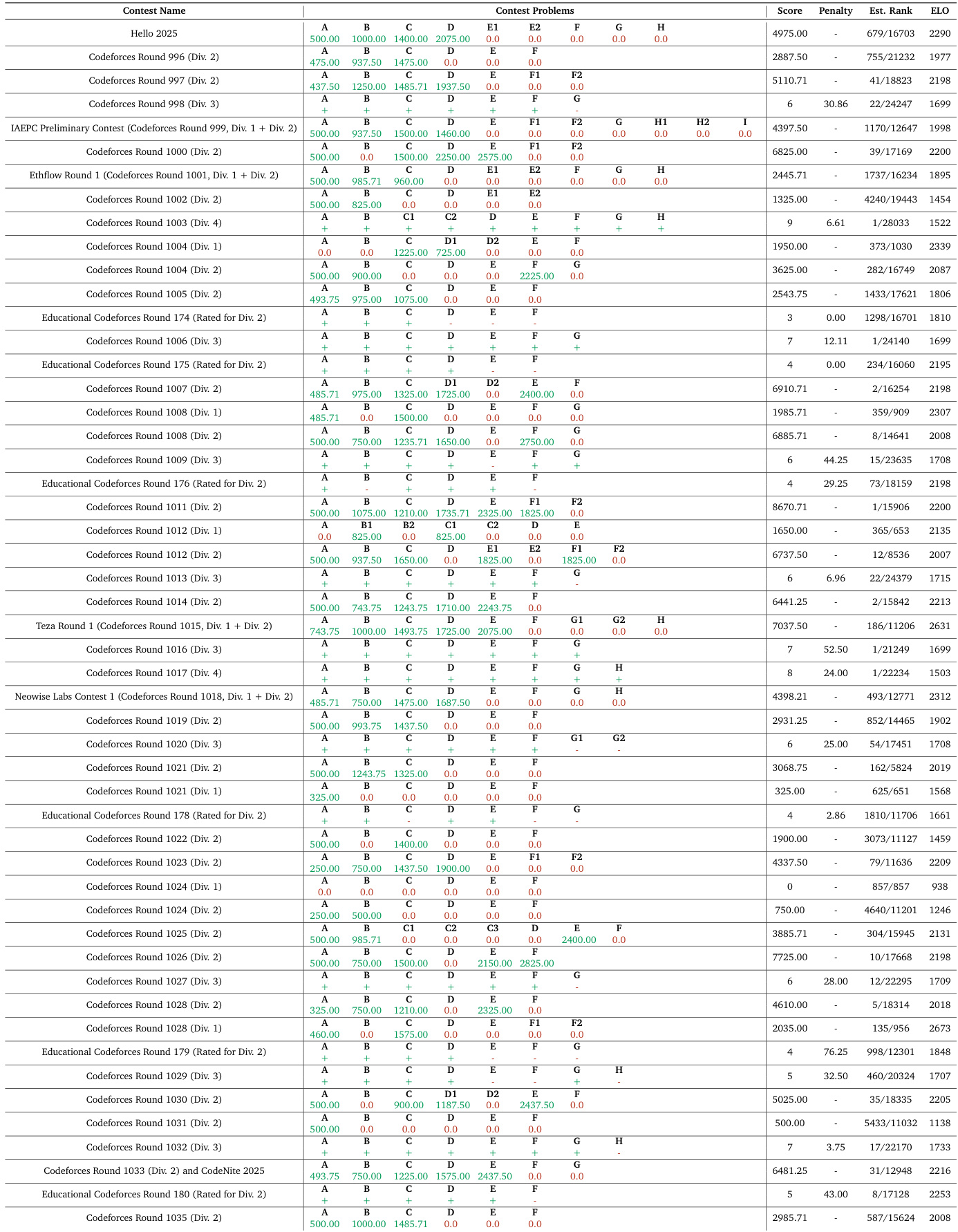
The authors evaluate their Nemotron-Cascade models on a series of competitive programming contests, reporting scores, penalties, and estimated ELO ratings across multiple Codeforces and educational rounds. Results show consistent performance across divisions, with estimated ranks often placing the model in the top 20% to 30% of participants, and ELO scores generally ranging between 1500 and 2300, indicating competitive proficiency at the intermediate to advanced level. The data reflects the model’s ability to solve algorithmic problems under contest conditions, with performance varying by round difficulty and problem set composition.
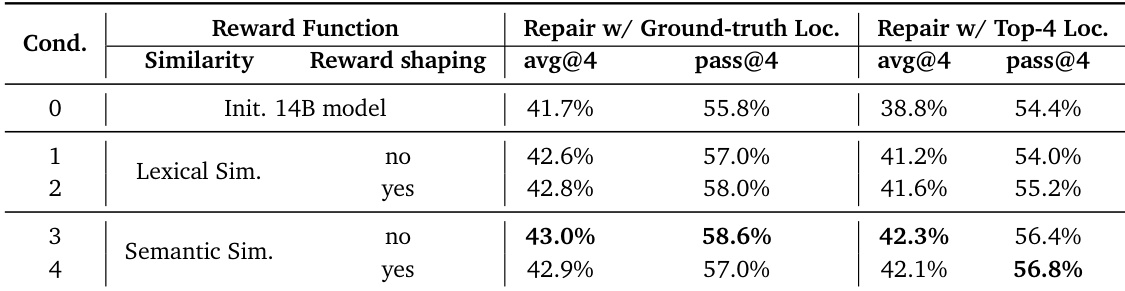
The authors evaluate different reward functions for SWE RL, finding that semantic similarity yields higher repair accuracy than lexical similarity, especially when ground-truth file localization is provided. Reward shaping improves performance with lexical similarity but offers no additional gain with semantic similarity, indicating the latter provides more reliable training signals even at low similarity scores.
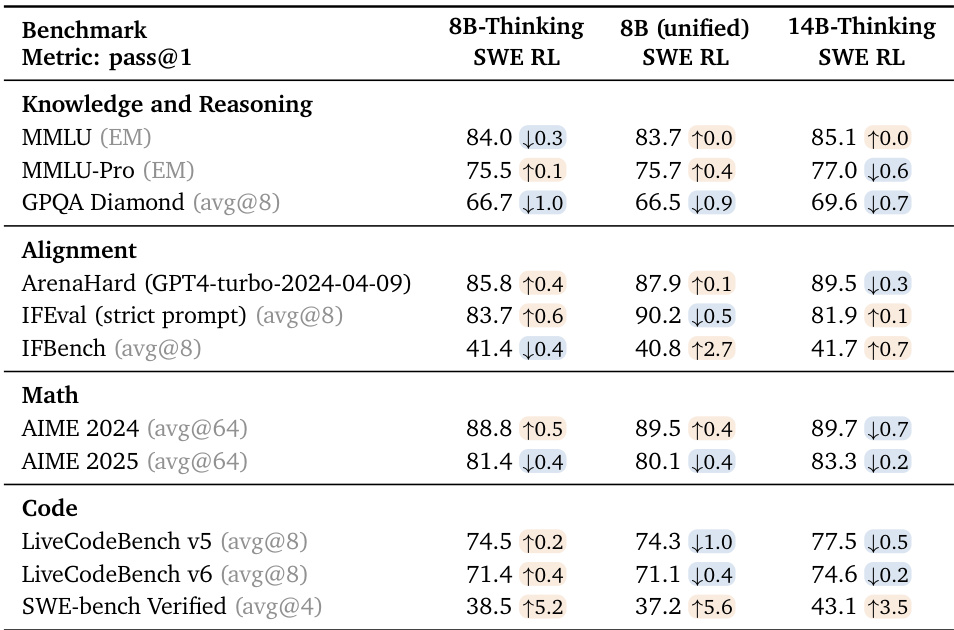
The authors apply SWE RL to their 8B and 14B models and observe substantial gains on SWE-bench Verified, with the 14B-Thinking model achieving 43.1% pass@1, outperforming specialized 32B models. Code and math benchmarks show minor fluctuations, mostly within evaluation variance, while alignment and knowledge benchmarks remain stable or see slight improvements. The unified 8B model closes the performance gap with its dedicated 8B-Thinking counterpart on SWE tasks after SWE RL, demonstrating effective cross-domain transfer.
The authors evaluate their Nemotron-Cascade models on a series of Codeforces contests, reporting scores, penalties, and estimated ranks across multiple divisions. Results show consistent performance across contests, with scores ranging from 0 to over 7000 and estimated ranks often placing the model in the top 2000 globally. The ELO score of 1942, derived from 51 Codeforces rounds, reflects competitive standing against other models in algorithmic problem solving.