HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

VOccl3D:現実の遮蔽下における3次元人体ポーズおよび形状推定のための動画ベンチマークデータセット

アルパマヨ-R1:長尾領域における汎用的な自動運転のための推論と行動予測の統合

























VOccl3D:現実の遮蔽下における3次元人体ポーズおよび形状推定のための動画ベンチマークデータセット
アルパマヨ-R1:長尾領域における汎用的な自動運転のための推論と行動予測の統合
すべてはつながっている:テスト時記憶化、注意バイアス、保持、オンライン最適化をめぐる旅
推論時スケーリングにおけるテキストから視覚生成へのプロンプト設計の再考
推論時スケーリングアプローチとしての視覚言語行動モデルのステアリング:探索の逆効果
OneThinker:画像および動画向けの一体型推論モデル
ViDiC:ビデオ差分キャプション
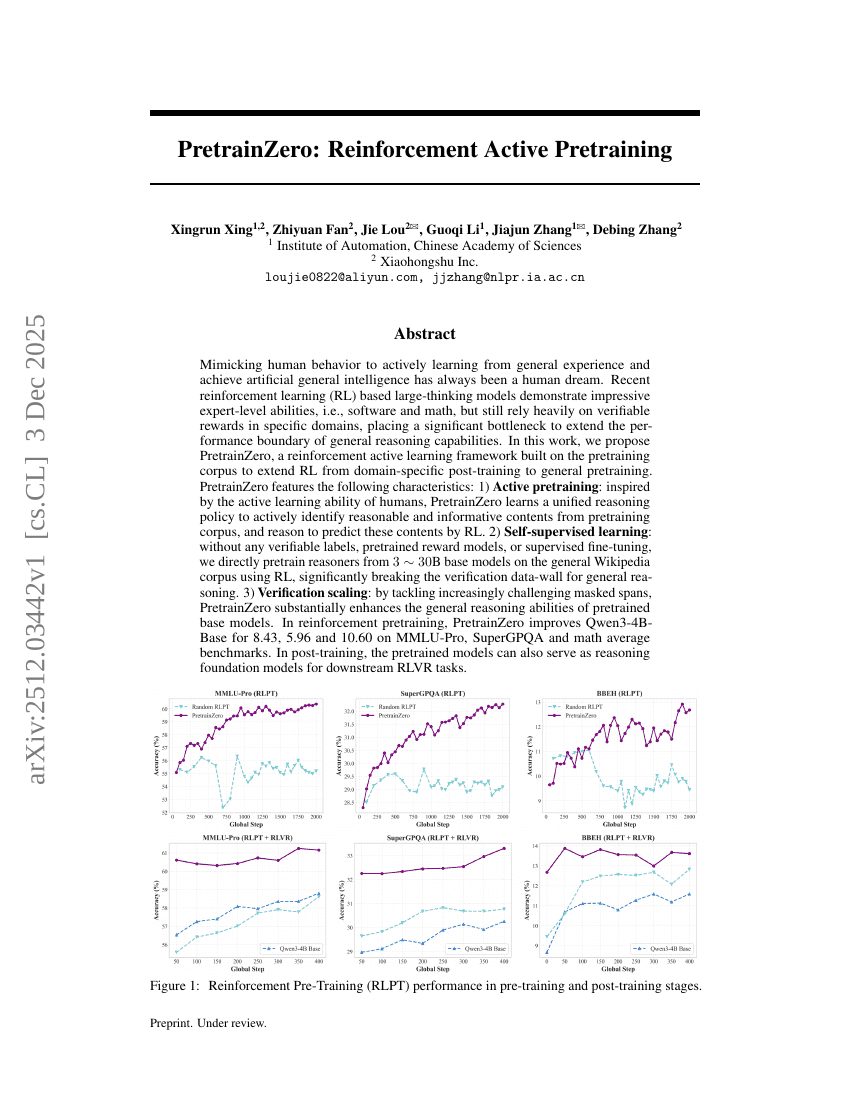
PretrainZero:強化学習を用いたアクティブ事前学習
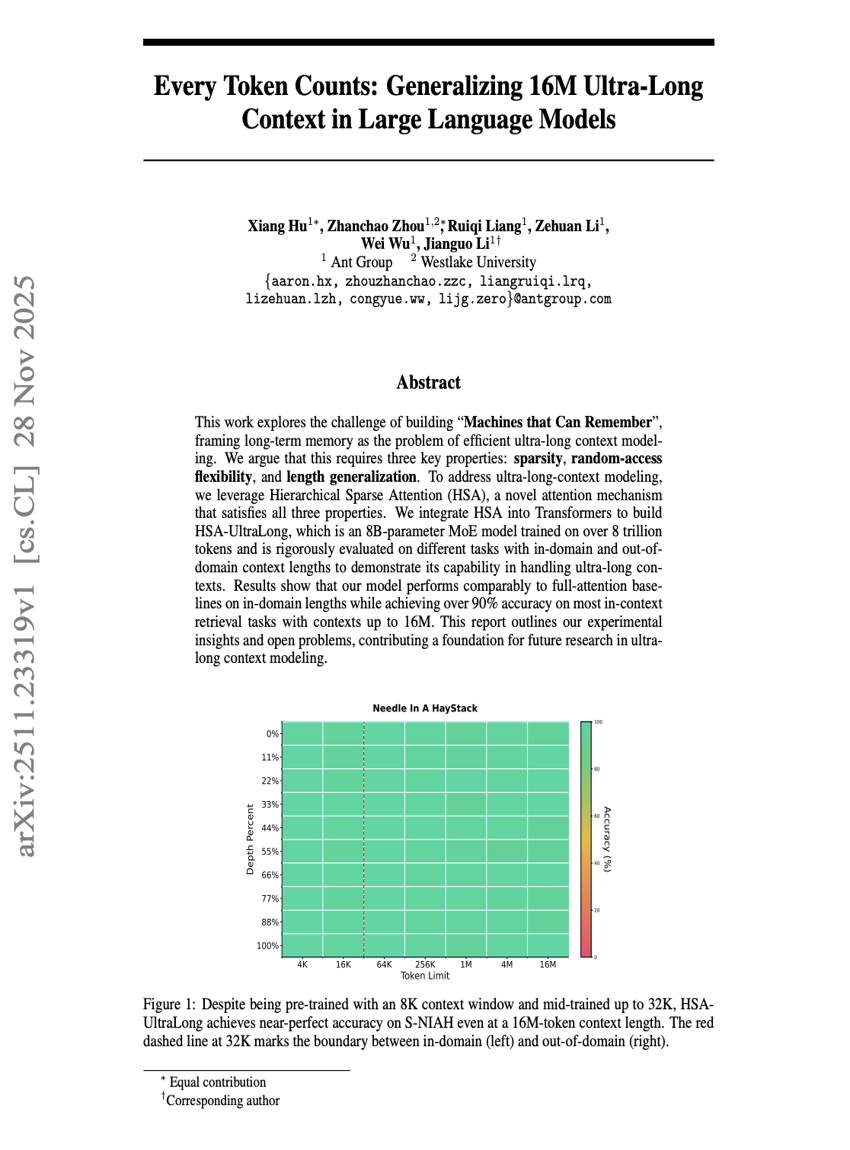
すべてのトークンが重要である:大規模言語モデルにおける1600万トークン超の長文脈の一般化
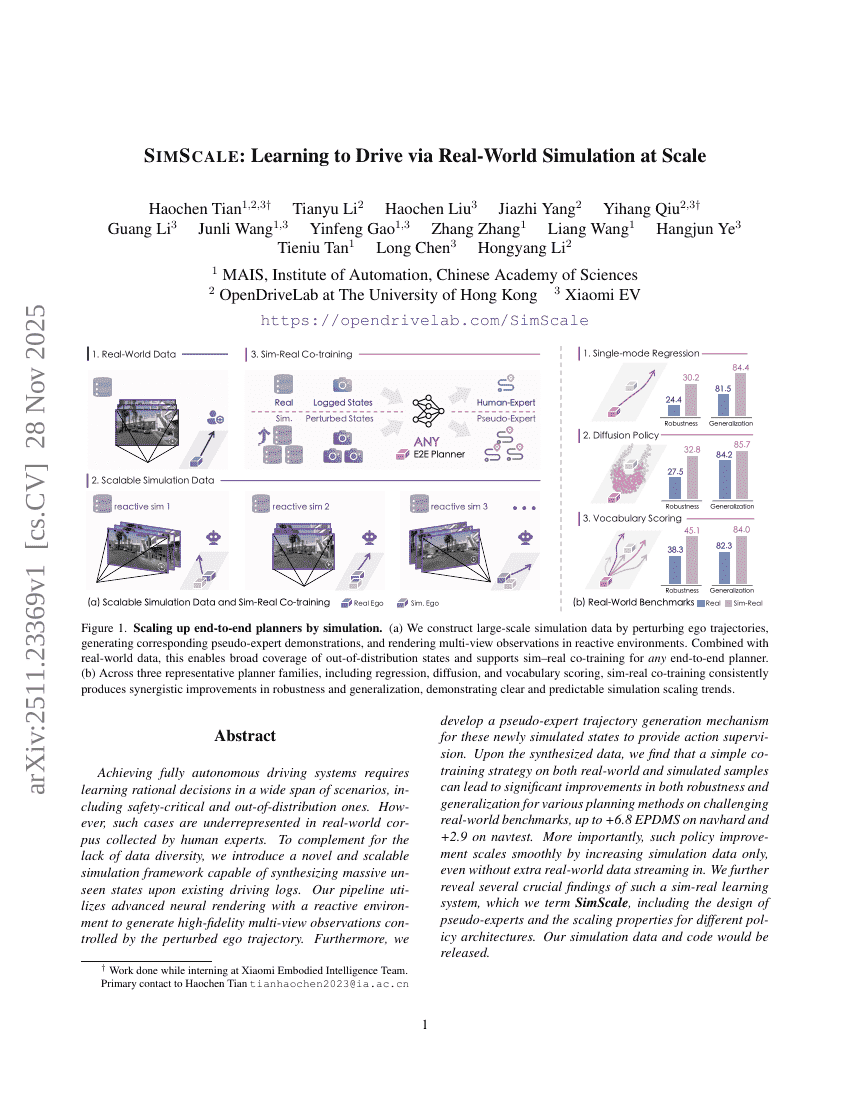
SimScale:スケールにおける現実世界シミュレーションを用いたドライブ学習
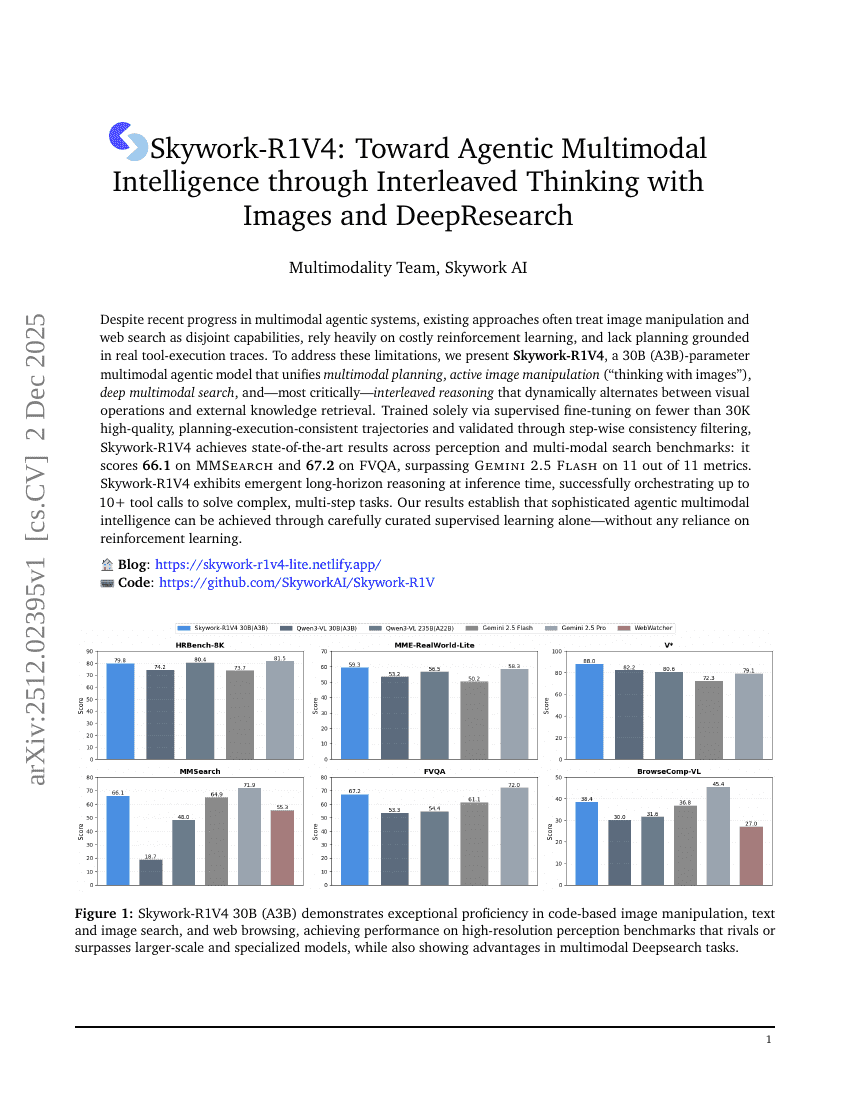
Skywork-R1V4:画像とDeepResearchを用いたインタリーブド・シンキングによるエージェント型マルチモーダル知能への挑戦
最小限の人的監視によるガイド付き自己進化型LLM
MultiShotMaster:制御可能なマルチショット動画生成フレームワーク
MG-Nav:スパース空間記憶を用いたデュアルスケール視覚ナビゲーション
コンシステンシー・クリティック:リファレンス誘導型アテンティブアライメントを用いた生成画像内の不整合の修正
深層学習を用いた実用的な研究エージェントは、果たしてどの程度現実のものに近づいているのか?
LLMを用いた強化学習の安定化:定式化と実践
Envision:因果的世界プロセスインサイトにおける統一的理解・生成のベンチマーク
LongVT:ネイティブ・ツールコールによる「長時間動画を用いた思考」のインセンティブ化
コード基盤モデルからエージェントおよびアプリケーションへ:コードインテリジェンス実践ガイド
物理駆動型時空間モデルによるAI生成動画検出
Mem-α:強化学習を用いたメモリ構築の学習
自己対戦による探索:教師なしでエージェント能力の限界を押し広げる
CudaForge:ハードウェアフィードバックを活用したCUDAカーネル最適化向けエージェントフレームワーク
ScaleNet:増分パラメータを用いた事前学習ニューラルネットワークのスケーリング
ブロック注意の混合最適化
フラクタルフォレンジックス:フラクタルウォーターマークを用いたプロアクティブなディープフェイク検出と局所化
チェーン・オブ・シンク・ハイジャッキング
InstanceAssemble:インスタンスアセンブリーアテンションを用いたレイアウト認識型画像生成
3EED:3次元空間におけるあらゆるものを基礎化する
DetectiumFire:視覚と言語を橋渡しする火災理解のための包括的なマルチモーダルデータセット
CHIP:産業現場における椅子の6次元姿勢推定のためのマルチセンサデータセット
すべてはつながっている:テスト時記憶化、注意バイアス、保持、オンライン最適化をめぐる旅
推論時スケーリングにおけるテキストから視覚生成へのプロンプト設計の再考
推論時スケーリングアプローチとしての視覚言語行動モデルのステアリング:探索の逆効果
OneThinker:画像および動画向けの一体型推論モデル
ViDiC:ビデオ差分キャプション
PretrainZero:強化学習を用いたアクティブ事前学習
すべてのトークンが重要である:大規模言語モデルにおける1600万トークン超の長文脈の一般化
SimScale:スケールにおける現実世界シミュレーションを用いたドライブ学習
Skywork-R1V4:画像とDeepResearchを用いたインタリーブド・シンキングによるエージェント型マルチモーダル知能への挑戦
最小限の人的監視によるガイド付き自己進化型LLM
MultiShotMaster:制御可能なマルチショット動画生成フレームワーク
MG-Nav:スパース空間記憶を用いたデュアルスケール視覚ナビゲーション
コンシステンシー・クリティック:リファレンス誘導型アテンティブアライメントを用いた生成画像内の不整合の修正
深層学習を用いた実用的な研究エージェントは、果たしてどの程度現実のものに近づいているのか?
LLMを用いた強化学習の安定化:定式化と実践
Envision:因果的世界プロセスインサイトにおける統一的理解・生成のベンチマーク
LongVT:ネイティブ・ツールコールによる「長時間動画を用いた思考」のインセンティブ化
コード基盤モデルからエージェントおよびアプリケーションへ:コードインテリジェンス実践ガイド
物理駆動型時空間モデルによるAI生成動画検出
Mem-α:強化学習を用いたメモリ構築の学習
自己対戦による探索:教師なしでエージェント能力の限界を押し広げる
CudaForge:ハードウェアフィードバックを活用したCUDAカーネル最適化向けエージェントフレームワーク
ScaleNet:増分パラメータを用いた事前学習ニューラルネットワークのスケーリング
ブロック注意の混合最適化
フラクタルフォレンジックス:フラクタルウォーターマークを用いたプロアクティブなディープフェイク検出と局所化
チェーン・オブ・シンク・ハイジャッキング
InstanceAssemble:インスタンスアセンブリーアテンションを用いたレイアウト認識型画像生成
3EED:3次元空間におけるあらゆるものを基礎化する
DetectiumFire:視覚と言語を橋渡しする火災理解のための包括的なマルチモーダルデータセット
CHIP:産業現場における椅子の6次元姿勢推定のためのマルチセンサデータセット