Command Palette
Search for a command to run...
ReFusion:並列自己回帰デコーディングを備えた拡散大規模言語モデル
ReFusion:並列自己回帰デコーディングを備えた拡散大規模言語モデル
Jia-Nan Li Jian Guan Wei Wu Chongxuan Li
概要
自己回帰モデル(ARMs)は、逐次的な推論が遅いために制限を受けています。一方、マスク付き拡散モデル(MDMs)は並列推論の代替手段を提供しますが、以下の重大な欠点を抱えています:キー・バリュー(KV)キャッシュを活用できないため計算負荷が高く、トークン組み合わせの扱いが困難な空間上で依存関係を学習することにより、一貫性の欠如した生成が生じます。これらの課題に対処するため、本研究ではReFusionを提案します。これは、トークンレベルではなく、固定長かつ連続する部分列である「スロット」レベルで並列デコードを実現する新しいマスク付き拡散モデルであり、高い性能と効率を達成しています。この実現には、反復的な「計画・補完(plan-and-infill)」推論プロセスを採用しています。まず、拡散モデルを用いた計画ステップで弱い依存関係を持つスロット集合を特定し、その後、自己回帰的手法による補完ステップで選択されたスロットを並列にデコードします。スロットベースの設計により、統一された因果フレームワーク下で完全なKVキャッシュ再利用が可能となり、同時に学習の複雑さをトークン組み合わせ空間から扱いやすいスロットレベルの順列空間へと大幅に低減できます。7つの多様なベンチマークにおける広範な実験結果から、ReFusionは従来のMDMsを大きく上回り、平均して34%の性能向上と18倍以上の高速化を達成するとともに、強力なARMsに近い性能を実現しつつ、平均2.33倍の高速化を維持していることが示されました。
One-sentence Summary
Researchers from Renmin University of China and Ant Group propose REFUSION, a slot-based masked diffusion model that replaces token-level decoding with a diffusion-guided "plan-and-infill" process. By generating fixed-length sub-sequences in parallel, it enables full KV cache reuse and reduces learning complexity, overcoming prior diffusion models' inefficiency and incoherence. REFUSION achieves 34% higher performance with 18× speedup over existing diffusion models while outperforming autoregressive models by 2.33× speed.
Key Contributions
- Autoregressive models face slow sequential inference, while existing masked diffusion models suffer from high computational overhead due to incompatible Key-Value caching and incoherent generation from learning over intractable token combinations. REFUSION addresses these by elevating parallel decoding from the token level to fixed-length contiguous slots through an iterative "plan-and-infill" process.
- The novel slot-based design enables full Key-Value cache reuse via a unified causal framework during autoregressive infilling while reducing learning complexity from the token combination space to a manageable slot-level permutation space. This simultaneously resolves the architectural bottleneck of KV caching and the incoherence issue in prior masked diffusion models.
- Evaluated across seven diverse benchmarks, REFUSION achieves 34% performance gains and over 18× speedup compared to previous masked diffusion models, while bridging the performance gap to strong autoregressive models and maintaining a 2.33× average speedup.
Introduction
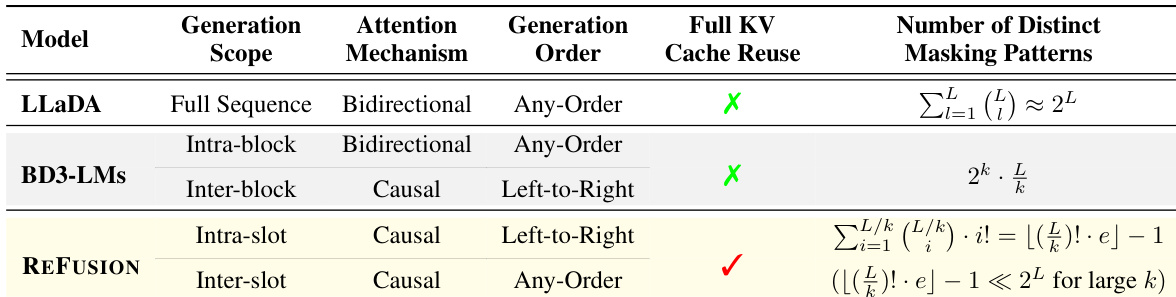
Masked Diffusion Models (MDMs) aim to accelerate language generation by enabling parallel token decoding compared to traditional Autoregressive Models (ARMs), but they face a critical bottleneck: standard bidirectional attention prevents efficient KV cache reuse during inference, undermining their speed advantage. Prior approaches attempted partial solutions—approximating cache reuse, mixing causal/bidirectional attention in fixed blocks, or using pure causal attention—but these either sacrificed global generation flexibility, relied on unreliable confidence heuristics, introduced separate verification models, or incurred intractable training complexity. The authors leverage a novel "slot" framework to propose ReFusion, which integrates inter-slot parallel planning with intra-slot autoregressive decoding. This design uniquely achieves full KV cache reuse for every decoded token while preserving flexible any-order generation, eliminating the trade-offs inherent in prior MDM architectures.
Method
The authors leverage a novel architecture called REFUSION, which restructures the parallel decoding process from the token level to a higher slot level to overcome the efficiency and coherence limitations of traditional masked diffusion models (MDMs). The core innovation lies in partitioning the sequence into fixed-length, non-overlapping slots and executing a two-step, iterative decoding cycle: diffusion-based slot planning followed by autoregressive slot infilling. This design is grounded in the empirical observation that inter-token dependency decays rapidly with distance, allowing tokens within a slot to be generated serially to preserve local coherence, while slots themselves can be processed in parallel to exploit computational efficiency.
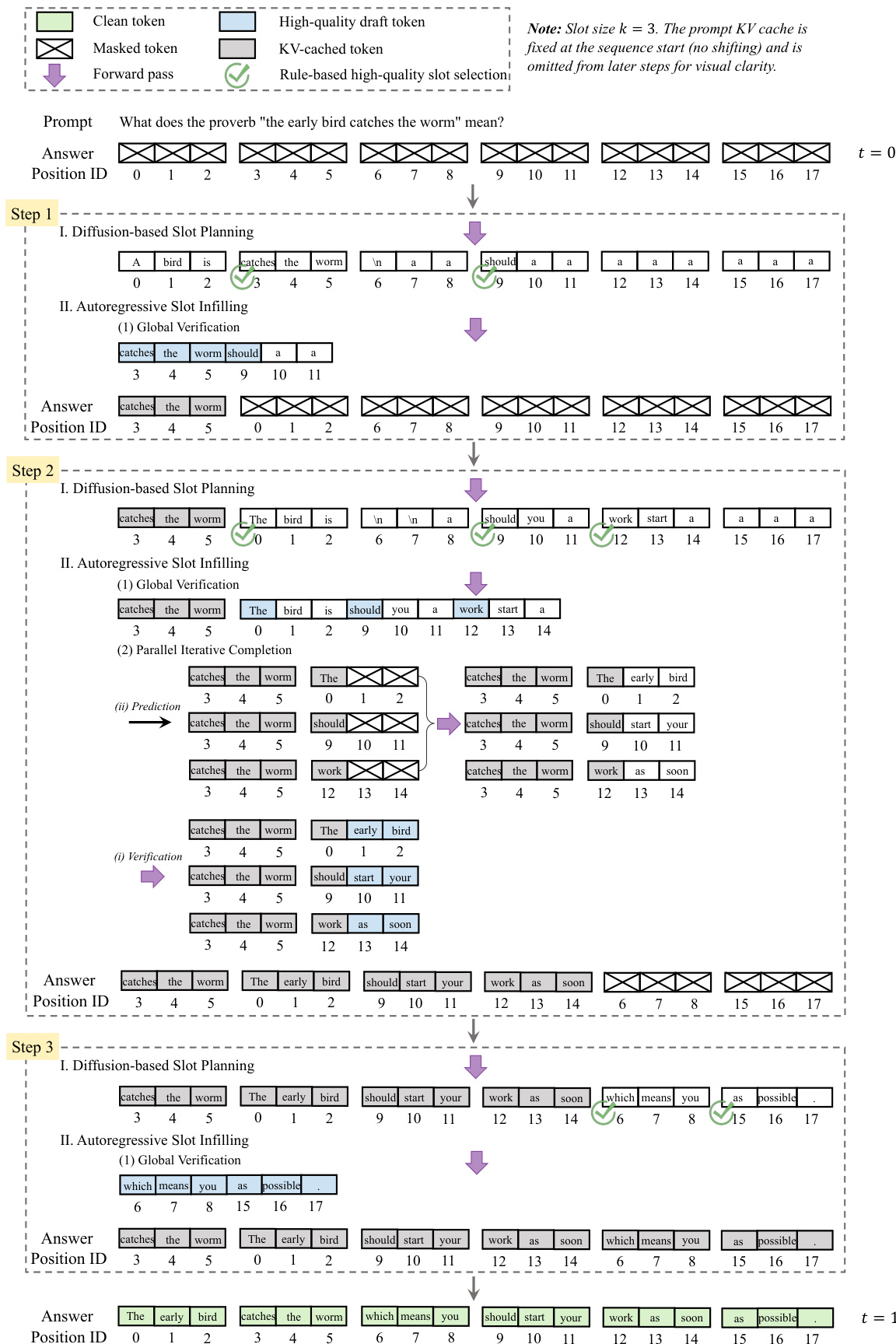
The inference process begins with a fully masked response sequence, which is divided into K consecutive slots of k tokens each. At each iteration, the model first performs slot planning: it computes a draft for all masked slots in parallel and assigns a certainty score to each, typically based on the probability of the first token in the slot. A batch of slots exceeding a predefined threshold is selected for infilling. This step identifies slots that are strongly constrained by the context but weakly interdependent, making them suitable for parallel processing. The selected draft slots are then verified and completed in the second step. The model first attempts a global verification by concatenating the drafts and checking for a prefix of tokens whose conditional probabilities exceed a token-level threshold; if this prefix spans one or more complete slots, they are accepted wholesale. If not, the model reverts to a parallel iterative completion process, where each slot is refined independently through cycles of verification and prediction until fully completed. Crucially, after each infilling step, the newly generated slots are physically reordered to precede the remaining masked slots, enabling full reuse of the Key-Value (KV) cache for all previously generated tokens. This reordering is made possible by maintaining invariant absolute position IDs for all tokens, which, when combined with RoPE, allow the model to correctly compute relative distances despite the dynamic buffer reordering. The process repeats until all slots are filled, and the final response is constructed by restoring the original slot order.
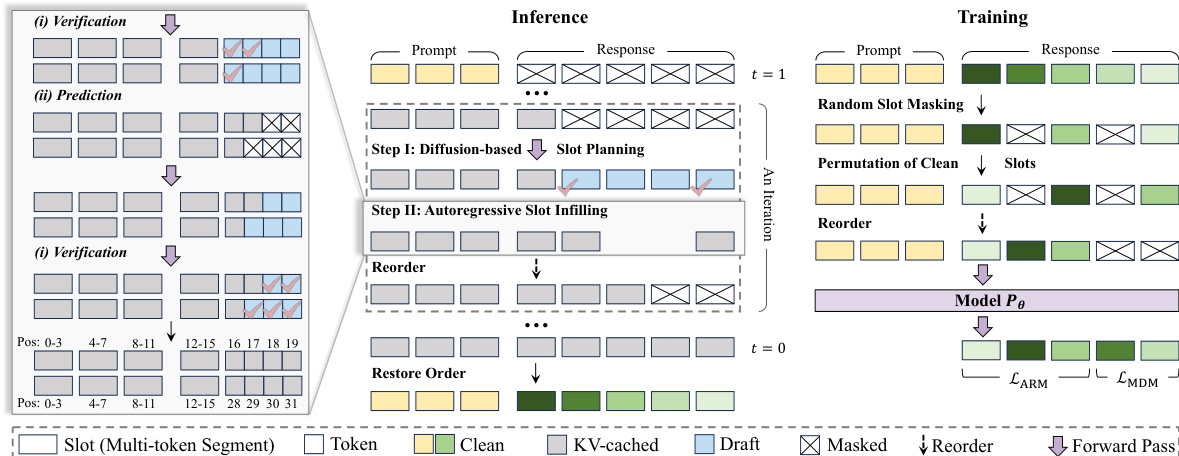
The training procedure is meticulously designed to mirror the inference dynamics. For each training sample, the response is partitioned into slots. A subset of these slots is randomly masked, while the unmasked (clean) slots are permuted to simulate the non-sequential generation order encountered during inference. The final training input is constructed by concatenating the permuted clean slots followed by the masked slots. The model is then optimized with a hybrid objective that jointly trains its planning and infilling capabilities. The clean slots are trained with a standard autoregressive loss, where the model predicts each token conditioned on its preceding tokens within the slot. The masked slots are trained with a denoising loss, where the model reconstructs the original tokens conditioned on the clean context and the partially revealed masked tokens. This dual objective ensures that every token in the sequence provides direct supervision, significantly improving data efficiency compared to traditional MDMs that only learn from masked positions. The final loss is a weighted sum of the ARM and MDM components, and the model is initialized from an off-the-shelf autoregressive backbone.

The model’s architecture is built upon a standard causal transformer, with a key modification to accept an explicit, non-contiguous list of position IDs. This allows the model to correctly attend to all logical predecessors regardless of their physical position in the buffer. The slot-based design inherently reduces the learning complexity from modeling an intractable space of token combinations to a more manageable space of slot permutations. Furthermore, the authors demonstrate that the model’s performance is robust to variations in block size, with a sweet spot identified for block sizes between 32 and 128 tokens, where it consistently outperforms strong autoregressive baselines in both throughput and accuracy.
The authors also note that the model’s design is compatible with semi-autoregressive remasking, where larger blocks are decoded sequentially, and the synergistic slot-level algorithm is applied within each block. This flexibility allows the model to be adapted to different computational constraints while maintaining its core advantages.
Experiment
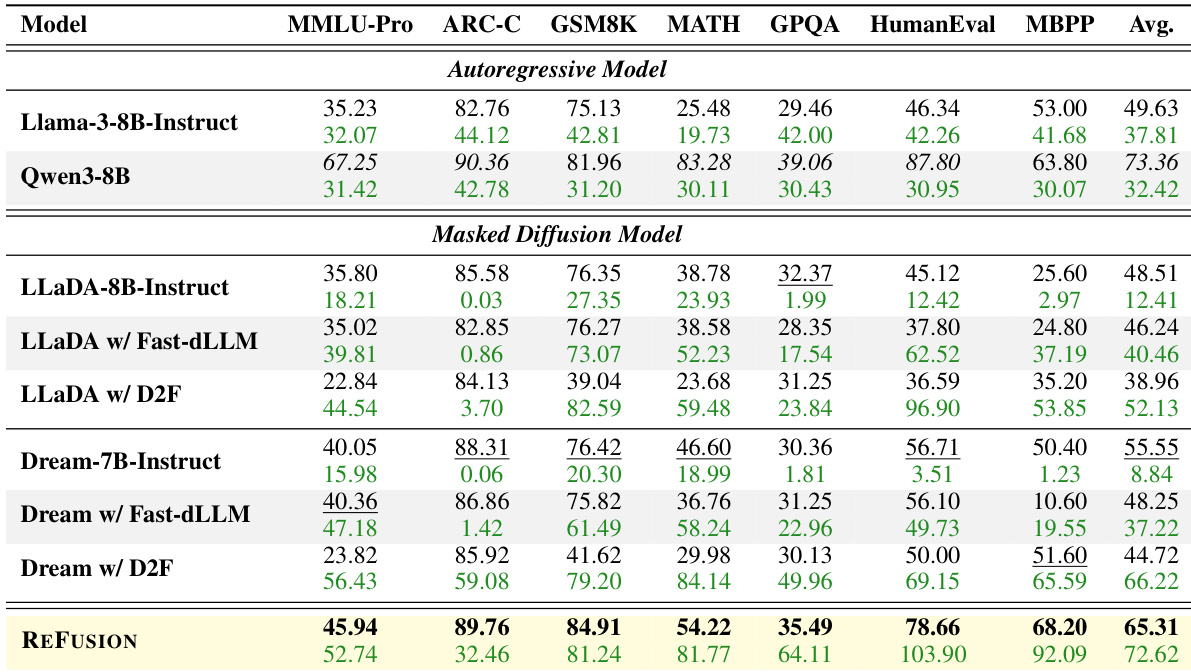
- On seven benchmarks, REFUSION surpassed all masked diffusion model (MDM) baselines by up to 22 absolute points (e.g., 78.66% pass@1 on HumanEval) with 34% average performance gains and 18× speedup, while exceeding Qwen3-8B autoregressive model performance on GSM8K and MBPP by 3.68 points at 2.33× average speedup.
- In controlled comparisons using Qwen3-8B backbone, REFUSION outperformed retrained baselines by ~16 points on HumanEval with 1.9× speedup, confirming architectural superiority without data advantages.
- Against Dream-7B-Instruct, REFUSION achieved 2.23% average performance gain and 11.05× speedup despite skipping pre-training, excelling on GSM8K, HumanEval, and MBPP.
- KV cache reuse ablation showed 1.16–1.33× throughput improvement across benchmarks with stable or slightly improved accuracy, validating efficiency without quality trade-offs.
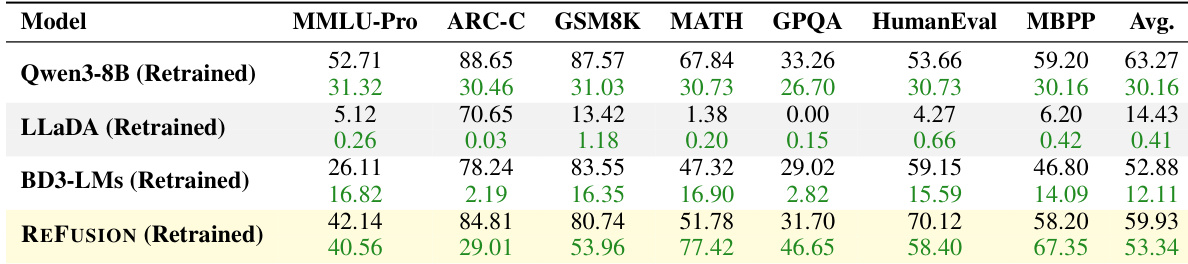
The authors retrain REFUSION on the Dream-7B-Instruct backbone to enable a controlled comparison, revealing that despite lacking pre-training and using fewer samples, REFUSION achieves a 2.23% average performance gain and an 11.05× speedup. Results show REFUSION significantly outperforms Dream-7B-Instruct on reasoning and coding tasks like GSM8K, HumanEval, and MBPP, while underperforming on knowledge-intensive benchmarks such as MMLU-Pro and ARC-C, consistent with its lack of pre-training for knowledge injection.

The authors retrain REFUSION and baseline models from the same Qwen3-8B checkpoint on a 120K dataset to isolate architectural effects. Results show REFUSION significantly outperforms both LLaDA and BD3-LMs in average performance and speed, achieving 53.34 average score versus 14.43 and 12.11 respectively, while also surpassing the retrained Qwen3-8B baseline by ~16 points on HumanEval. This confirms REFUSION’s design advantages enable superior learning efficiency even under data-constrained conditions where standard MDMs fail.
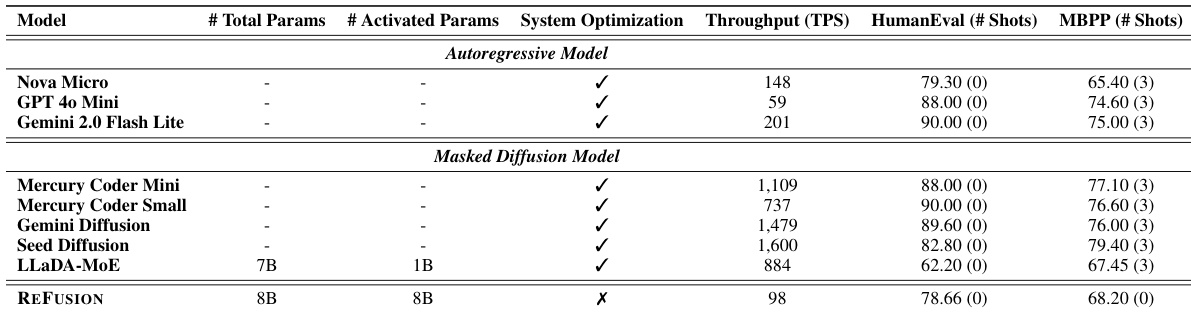
The authors use REFUSION to outperform all compared masked diffusion models and strong autoregressive baselines across seven benchmarks, achieving the highest average scores in both performance and throughput. Results show REFUSION delivers a 2.33× speedup over Qwen3-8B while surpassing it on key tasks like GSM8K and MBPP, demonstrating that its slot-based parallel decoding breaks the traditional speed-quality trade-off. The model’s design enables full KV cache reuse and reduces learning complexity, allowing it to consistently exceed prior MDMs by wide margins, including a 34% performance gain and over 18× speedup on average.
The authors use REFUSION, a slot-based masked diffusion model, to achieve competitive performance against autoregressive models while maintaining high throughput. Results show REFUSION matches or exceeds several autoregressive baselines in HumanEval and MBPP scores, despite not using system optimizations, and outperforms other masked diffusion models in both accuracy and speed.
The authors compare REFUSION with and without KV cache recomputation, showing that the default KV reuse method is 1.16–1.33× faster across benchmarks while maintaining or slightly improving performance. Results indicate that avoiding full contextualization during parallel decoding does not degrade accuracy and may even provide implicit regularization benefits.