Command Palette
Search for a command to run...
DanceOPD: オンポリシー生成フィールド蒸留
DanceOPD: オンポリシー生成フィールド蒸留
概要
現代の画像生成は、テキストから画像への変換(T2I)、ローカル編集、グローバル編集など、多様な能力を統合する単一モデルを求めている。しかし、これらの能力は自然に整合することは稀であり、しばしば競合する。例えば、編集処理はT2Iのパフォーマンスを低下させる傾向があり、グローバル編集とローカル編集は互いに干渉し合う。したがって、これらの能力を効果的に組み合わせることが、画像生成モデルの学習における中核的な課題となっている。本課題に対処するため、本稿ではDanceOPDを提案する。DanceOPDはフローマッチングモデル向けのオンポリシー生成場蒸留フレームワークであり、各サンプルを1つの能力場にルーティングし、1つの低ノイズ学生誘起状態をクエリし、単純な速度MSE目的関数を用いて学習を行う。各能力源を共有フロー状態空間上の速度場として定義し、学生モデルは自身のロールアウト状態上でクエリされた場から学習を行うことで、専門家の能力を統合する。本定式化は、クラスファイヤーフリーガイダンスなどの演算子定義の場も吸収する。T2I、編集、リアリズム場吸収、CFG吸収に関する包括的な実験により、本手法がマルチ能力の統合を改善し、アンカー生成の品質を維持しつつ目標能力を強化することが示された。本稿が、フローマッチングモデルにおける生成場蒸留の実用的な道筋を確立すると考える。
One-sentence Summary
DanceOPD is an on-policy generative field distillation framework for flow-matching models that routes each sample to a specific capability velocity field, queries student-induced states during rollouts, and trains via a velocity mean squared error objective to unify text-to-image generation with local and global editing while preserving anchor generation quality, as validated across T2I, editing, realism-field, and classifier-free guidance experiments.
Key Contributions
- This work introduces DanceOPD, an on-policy generative field distillation framework that unifies text-to-image generation, local editing, and global editing within a single flow-matching model by treating each capability as a frozen velocity field over a shared state space.
- Cross-capability conflicts are resolved through hard field routing and a single semantic-side low-noise query on the student rollout, optimizing with a velocity MSE objective to provide direct supervision without relying on dense reward optimization or parameter merging.
- Comprehensive experiments on text-to-image generation, editing, realism-field absorption, and classifier-free guidance absorption demonstrate that the framework composes multiple capabilities, strengthening target performance while preserving baseline generation quality and surpassing individual teacher models.
Introduction
Modern image generation increasingly relies on flow-matching models that must handle multiple capabilities like text-to-image synthesis, local editing, and global style transformation within a single deployed system. This unified approach matters because it eliminates the need for specialized tools and streamlines complex creative workflows. However, these tasks are inherently misaligned and frequently interfere with one another. Prior approaches that rely on joint training, parameter merging, or adapter composition often suffer from gradient conflicts, diluted supervision, or compromised generation quality. The authors leverage on-policy generative field distillation to resolve this by routing samples to specialized velocity fields and training a unified student model through a simple velocity mean squared error objective. This framework enables the model to compose expert capabilities, absorb external guidance operators, and maintain strong baseline performance without the interference typical of conventional multi-task training.
Dataset

- Dataset composition and sources: The authors do not provide dataset composition or source information in the provided excerpt, which only lists author names and institutional affiliations.
- Key details for each subset: No subset sizes, origins, or filtering rules are described in the text.
- How the paper uses the data: The authors do not specify training splits, mixture ratios, or processing pipelines in the provided content.
- Cropping strategy and processing details: The excerpt lacks any mention of cropping strategies, metadata construction, or additional processing steps.
Method
The authors formulate multi-capability image generation as an on-policy generative field distillation framework. Rather than combining frozen capability sources through static parameter interpolation or data-ratio tuning, each source is treated as a deterministic velocity field over a shared generative state space. Capability composition is thus reduced to a field-query problem, requiring coordinated decisions on which field supervises a given sample, where in the state space the field should be queried, and how many trajectory states are utilized for supervision.
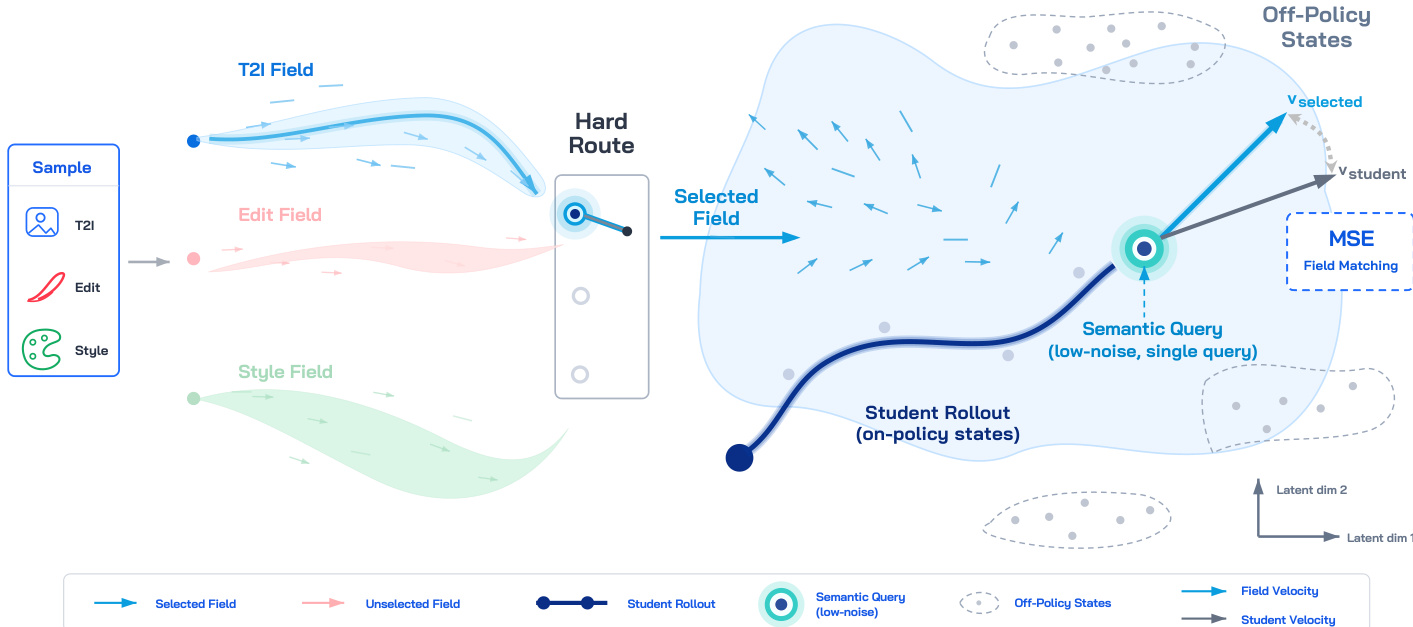
As shown in the framework diagram, the training process begins by sampling a capability source and routing the corresponding training data to a specific frozen velocity field. To preserve the semantic identity of each capability and avoid target-field ambiguity, the method employs hard-routed sample-wise field matching. Each sample is dispatched to exactly one capability field, ensuring that the supervision signal corresponds to a well-defined task rather than a potentially conflicting average of multiple fields. This routing strategy maintains clear semantic boundaries between distinct generative behaviors.
Once a field is selected, the framework addresses state-distribution mismatch by querying the frozen field on the current student rollout. Instead of relying on fixed off-policy data states or teacher-induced trajectories, the student generates its own trajectory from initial noise. A specific state along this rollout is selected and passed through a stop-gradient operation to prevent backpropagation through the entire solver. This on-policy querying aligns the supervision distribution with the states the student actually visits during inference, effectively mitigating covariate shift.
To resolve trajectory-query correlation, the method avoids dense supervision across multiple states from the same rollout. States along a single trajectory share identical conditioning, noise seeds, and path history, leading to highly correlated gradient signals that can bias optimization. Instead, the framework samples a single semantic-side query located in the low-noise regime of the trajectory. This region concentrates capability-specific information, such as style or edit attributes, providing a high signal-to-noise supervision signal while maintaining computational efficiency.
The student model is then updated by minimizing a plain velocity mean squared error (MSE) loss between its predicted velocity and the routed frozen field evaluated at the stop-gradient query state:
LDanceOPD=Em∼π,(x,c)∼Dm,zT∼pT,s∼qsem[∥vθ(zˉt,t,c)−vm(zˉt,t,c)∥22],t=t(s).This local regression objective naturally aligns with the deterministic velocity fields generated by flow-matching models. Under a local Gaussian transition view, KL-style field matching reduces to this weighted MSE form, making it a stable and theoretically grounded choice for velocity distillation. The same formulation can also absorb operator-defined fields, such as classifier-free guidance, by treating the guided velocity as an additional capability field and applying the identical matching objective.
Experiment
The experiments evaluate DanceOPD across text-to-image composition, editing, and field absorption settings to validate whether a single student model can integrate heterogeneous generative capabilities without collapsing into capability interference. Diagnostic and qualitative analyses reveal that hard field routing, single semantic-side trajectory queries, and targeted initialization successfully preserve anchor capabilities while strengthening target skills, whereas soft teacher mixing, dense same-step supervision, and correlated state queries consistently degrade performance. Ultimately, the framework demonstrates that isolating semantic identity at the query level provides a stable and efficient alternative to traditional joint training or weight-merging approaches for multi-capability model distillation.
The authors analyze the effects of query timing and initialization methods on generative capability composition. The data demonstrates that querying teacher fields at lower timesteps consistently produces higher average performance across editing tasks compared to median or high timesteps. Furthermore, utilizing a local edit checkpoint for initialization results in significantly better outcomes than merged or other baseline initialization strategies. Low-timestep querying achieves superior performance compared to median and high-timestep alternatives. Local edit initialization outperforms merged, text-to-image, and global edit initialization baselines. Optimal configurations show robust performance at later training steps, particularly in subject removal and background change.
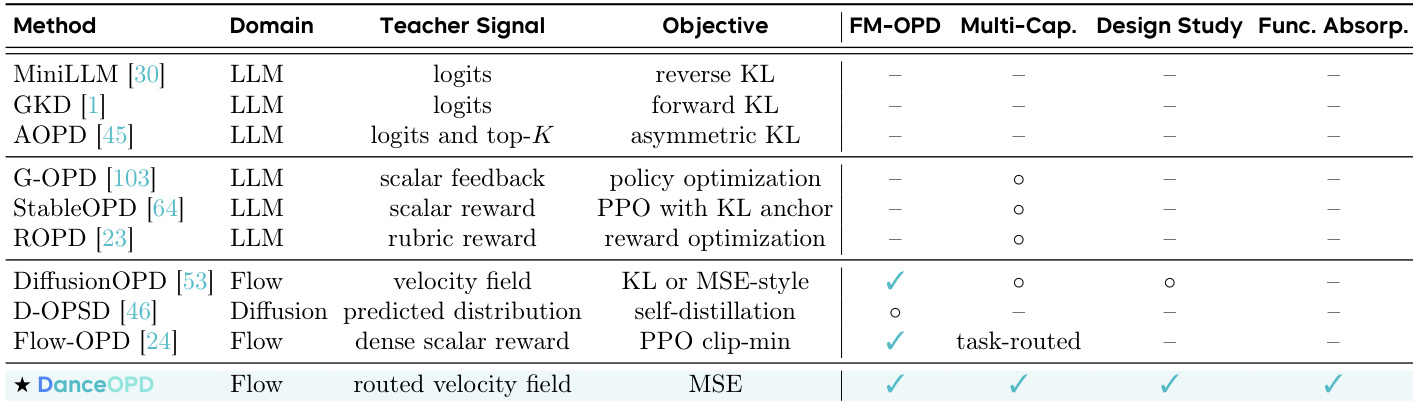
The the the table categorizes DanceOPD as a flow-based method utilizing a routed velocity field and MSE objective, distinguishing it from LLM-focused approaches and other diffusion techniques. The method is shown to support flow matching on-policy distillation, multi-capability composition, design studies, and functional absorption. Experimental results confirm that DanceOPD successfully composes heterogeneous capabilities and absorbs target fields while preserving the anchor model's original generation behavior. DanceOPD improves target capability performance while maintaining the anchor capability, avoiding the interference seen in joint training or weight merging approaches. Hard routing of teacher fields is necessary to preserve sample-level semantic identity, whereas soft teacher mixing leads to degraded performance. Single semantic-side queries per rollout are more effective than dense trajectory queries, as correlated states in dense queries can amplify conflicting gradients.
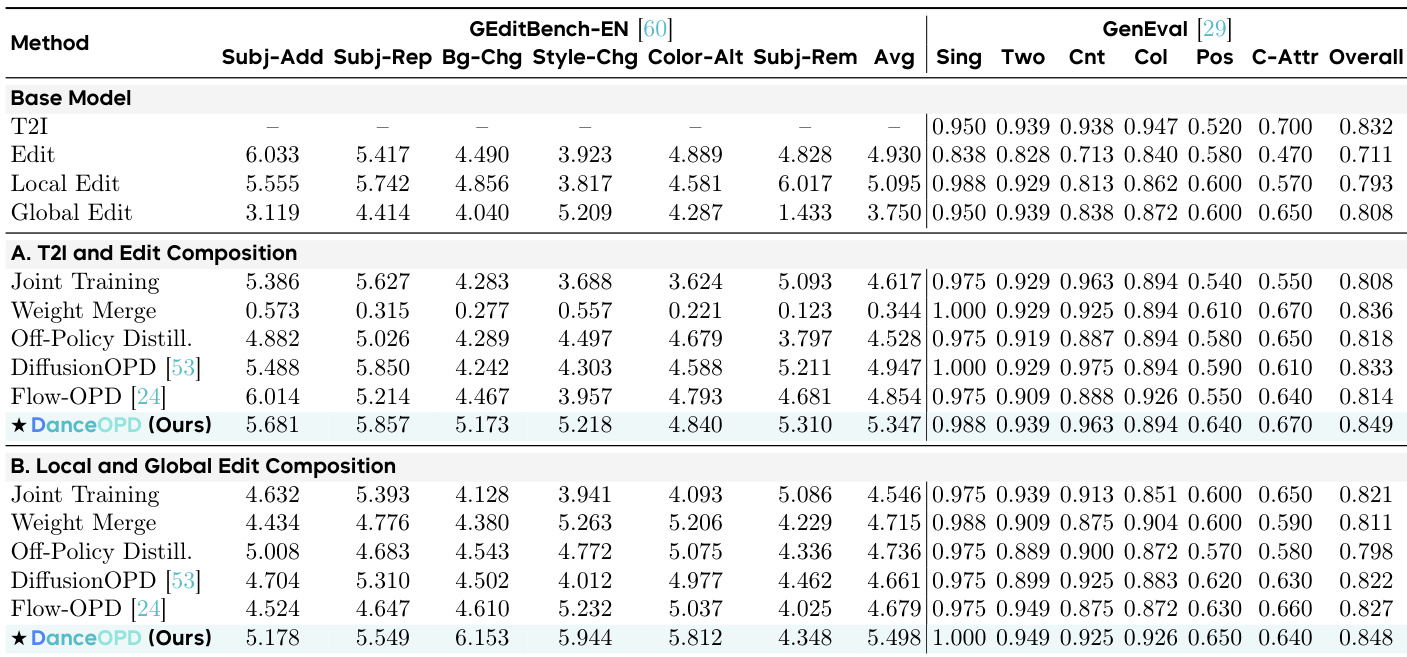
The authors evaluate DanceOPD for composing heterogeneous capability fields, specifically combining text-to-image generation with image editing tasks, as well as merging local and global editing capabilities. The results demonstrate that the method effectively strengthens the target capabilities while preserving the anchor capabilities, outperforming baselines such as joint training and weight merging which tend to reintroduce capability interference. DanceOPD demonstrates superior capability composition by strengthening target editing abilities while preserving base generation quality, particularly excelling in categories requiring substantial visual transformations like style and background changes. In composing local and global editing capabilities, the method achieves higher average editing scores compared to competing baselines, indicating effective handling of conflicting editing requirements without sacrificing general generation performance. The experiments highlight that hard routing and single-step querying are essential for stable training, as soft teacher mixing and dense trajectory supervision lead to performance degradation due to capability conflict and correlated query noise.
The experiment analyzes how combining absorbed guidance with external evaluation guidance affects model performance. The results demonstrate that a moderate combination of these scales produces the best overall editing capability, whereas excessively high effective guidance strengths lead to significant performance degradation. Moderate composition of absorbed and external guidance achieves the highest average score. High effective guidance strengths cause substantial drops in performance across editing categories. Training-only absorption underperforms compared to the optimal moderate composition setting.

The authors evaluate the composition of multiple capability fields into a single student model, focusing on how different teacher scheduling, objective functions, and query strategies affect performance. The results indicate that hard routing of teacher signals to specific semantic queries is superior to soft mixing, which tends to blur distinct capability identities. Furthermore, updating the student with a single query per rollout step yields better overall results than accumulating multiple queries or using dense trajectory supervision, which introduces correlated noise and capability interference. Hard routing of teacher fields preserves semantic identity better than soft mixing, leading to higher average performance across editing tasks. Single-query updates per step outperform same-step accumulation, as accumulating multiple capability fields reintroduces interference. Increasing the number of trajectory queries per rollout degrades performance, suggesting that correlated states amplify conflicting gradients rather than stabilizing them.
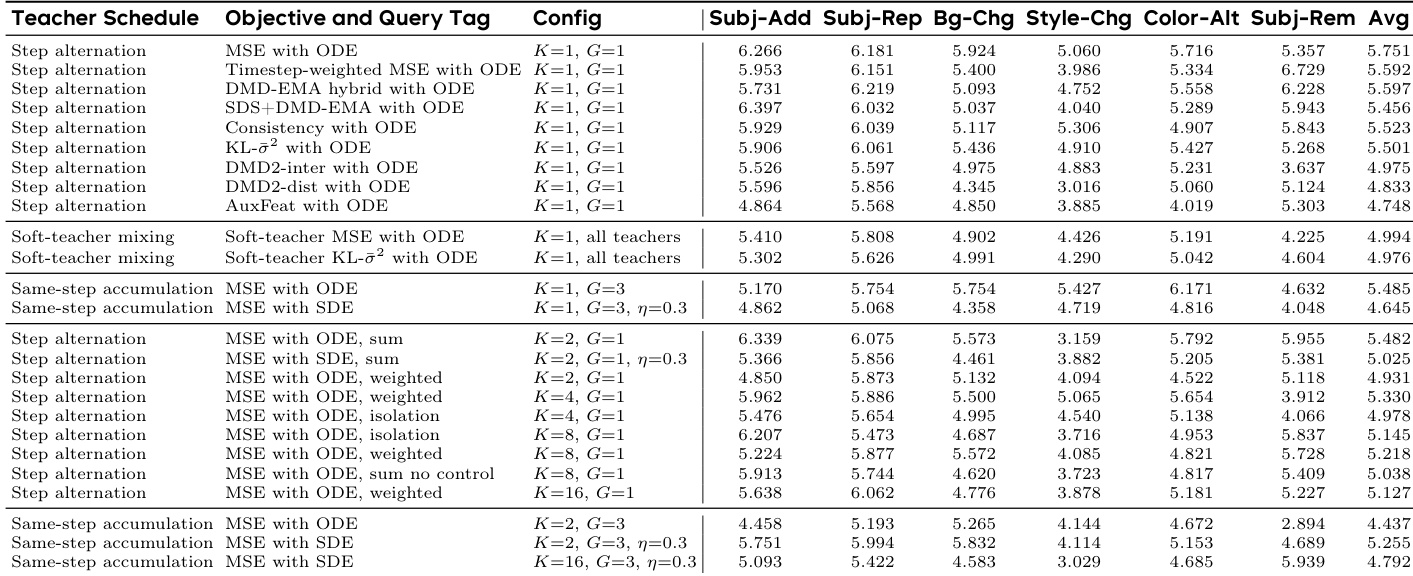
The experiments validate the DanceOPD framework's ability to compose heterogeneous capability fields by systematically testing query timing, initialization strategies, routing mechanisms, and guidance scaling. Results consistently demonstrate that hard routing of teacher signals and single-step querying per rollout effectively preserve semantic identity and prevent capability interference, whereas soft mixing and dense trajectory supervision degrade performance through conflicting gradients. Additionally, utilizing local edit checkpoints and a moderate combination of absorbed and external guidance yield the most stable editing outcomes, confirming that the method successfully integrates diverse functions while preserving the anchor model's original generation behavior.