Command Palette
Search for a command to run...
考える時間を見つける:リアルタイム強化学習における計画予算の学習
考える時間を見つける:リアルタイム強化学習における計画予算の学習
Aneesh Muppidi Firas Darwish Dylan Cope João F. Henriques Jakob Nicolaus Foerster
概要
熟考には時間がかかる。リアルタイムの設定では、その時間は無料ではない。標準的な強化学習(RL)では、環境がエージェントの決定を無期限に待つため、この問題を回避している。代わりに我々は、エージェントの行動を待つ間も環境が進行するリアルタイムRL環境を研究する。先行するリアルタイム形式化に基づき、我々は可変遅延リアルタイムRLを導入する。ここでは、エージェントが各決定点でどれだけ熟考するかを選択するが、その間も環境は進行する。我々が使用する計画エージェントにとって、適切な遅延は状態に依存し、計画にどれだけ時間をかけるかを単純に計画しようとするとエージェントが麻痺してしまう可能性がある。そこで我々は、プランナーの上に軽量なゲーティングポリシーを訓練し、状態依存の計画予算を選択することでこの設定に取り組む。リアルタイムのパックマン、テトリス、スネーク、スピードヘックス、スピード囲碁において、我々のゲーティングポリシーは固定予算やヒューリスティックなベースラインを上回り、環境とエージェントが異なる2つのGPU上で動作するリアルタイム設定にも転移する。
One-sentence Summary
Researchers at the University of Oxford (BOLD, VGG, and Department of Statistics) propose a variable-delay real-time reinforcement learning framework where a lightweight gating policy learns state-dependent planning budgets for a planner, outperforming fixed-budget and heuristic baselines across real-time Pac-Man, Tetris, Snake, Speed Hex, and Speed Go, and transfers to a real-time setup with the environment and agent running on two different GPUs.
Key Contributions
- The paper introduces variable-delay real-time reinforcement learning, where the agent can choose how long to deliberate at each step and the cost of thinking is paid directly by the environment progressing rather than through artificial reward penalties.
- A lightweight gating policy trained with PPO on top of a frozen AlphaZero planner selects state-dependent planning budgets, outperforming fixed-budget and heuristic baselines across five real-time games (Pac-Man, Tetris, Snake, Speed Hex, Speed Go).
- The same gating policy transfers to a true asynchronous two-GPU deployment without architectural changes, enabled by a training protocol that captures real-time interaction dynamics and makes the cost of deliberation legible during learning.
Introduction
In real-time decision-making, the environment advances while an agent deliberates, breaking the standard RL assumption of an infinitely patient world. Prior work addressed this by fixing a one-step action delay, but that prevents the agent from allocating more thinking time to critical states and less to trivial ones. The authors generalize this to a variable-delay setting where the agent is a procedure that runs in time, and the cost of deliberation is paid as world progress. They introduce a lightweight gating policy trained on top of a frozen AlphaZero-style planner that learns to choose a state-dependent planning budget, outperforming fixed-budget baselines and transferring to real hardware without retraining.
Dataset
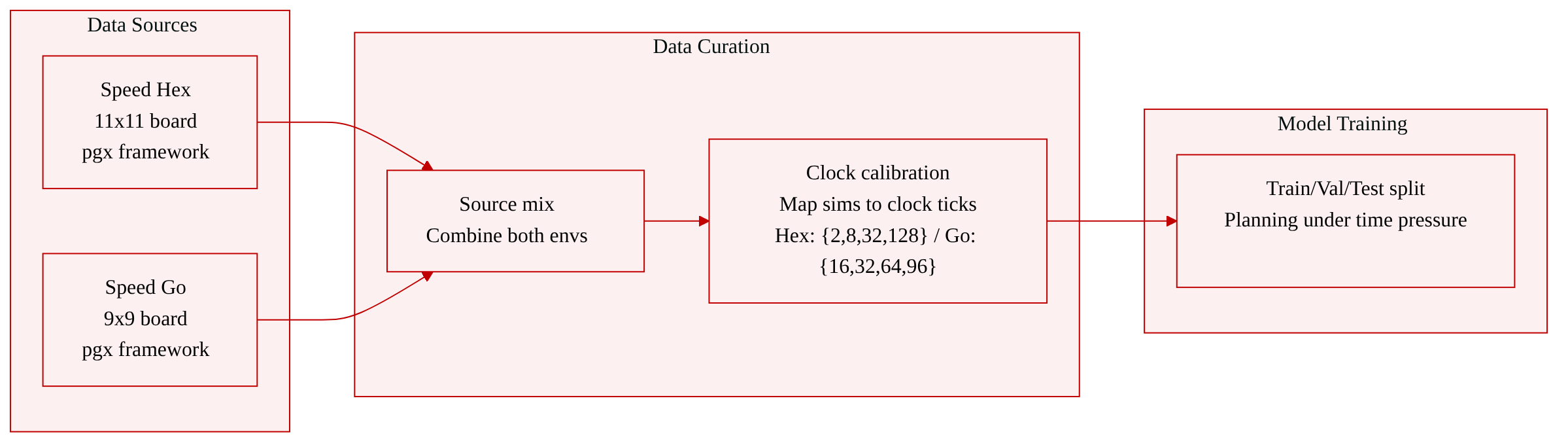
Here is a concise dataset description based on the provided text.
The authors use two custom board-game environments, Speed Hex and Speed Go, to study planning under time pressure. These environments are built on the pgx framework and isolate the effect of a ticking clock by removing all other dynamic elements.
-
Dataset Composition and Sources
-
The environments are Speed Hex (11×11 board) and Speed Go (9×9 board).
-
They are instantiated using a degenerate reflex policy that deterministically takes a no-op action, meaning the board state remains fixed while the agent thinks.
-
Key Details for Each Subset
-
The clock is the only dynamic element; it decrements with thinking time while the board waits for a move.
-
A one-to-one mapping is used between MCTS simulations and clock ticks, where each simulation increments the player's clock by one unit.
-
The simulation options are calibrated to represent distinct tradeoffs between inference latency and planning quality. The resulting option sets are:
-
Speed Hex: {2, 8, 32, 128}
-
Speed Go: {16, 32, 64, 96}
-
How the Paper Uses the Data
-
The environments are used to model the pressure found in speed chess, where a player's limited clock runs continuously while they deliberate.
-
The equal-compute-per-frame constraint does not apply in this setting, so the simulation budgets are calibrated separately per environment to create meaningfully different planning strategies.
Method
The authors address the problem ofreal-time Markov Decision Processes (MDPs), where the environment advances at fixed intervals regardless of the agent's computation speed. In this setting, deliberation carries a direct cost: the world progresses while the agent thinks. To manage this tradeoff, the authors leverage a solution based on a Semi-Markov Decision Process (SMDP) over budgeted options.
The framework constructs the agent's procedure from three primary ingredients: a fast reflex policy, a set of anytime action-refinement computations, and a learned gating policy.
Reflex Policy and Anytime Computations The authors commit to a fast reflex policy πreflex(a∣s) that executes in well under one frame. This policy supplies the agent's frame-by-frame output under the real-time protocol, ensuring the environment always receives an action. In committed-action environments like Pac-Man, real-time Tetris, or Snake, this is instantiated as the planner's policy network evaluated without search. In clock environments like Speed Hex or Speed Go, it acts as a deterministic no-op.
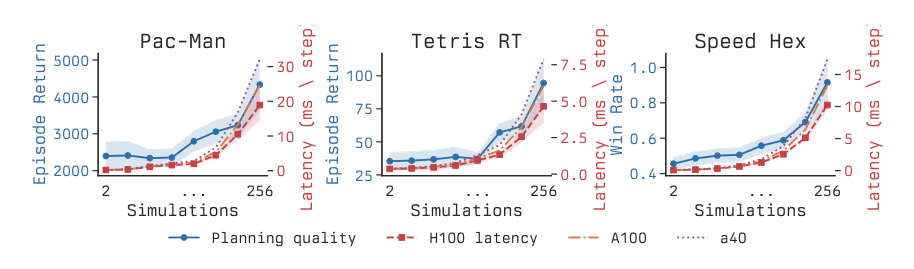
Complementing the reflex policy is a finite family of anytime action-refinement computations {ck}k∈K, indexed by discrete duration k. Each computation ck runs for exactly k frames to refine the action choice, typically instantiated as Monte Carlo Tree Search (MCTS). A core observation motivating this approach is that planning quality and inference cost scale together.
As shown in the figure below:
Longer-running computations produce expectedly better actions, but the extended inference time advances the environment further before the refined action lands.
Budgeted Options and Meta-Level SMDP These components are combined into temporally extended budgeted options ok. When option ok is initiated at state st, it wraps the computation ck. During the intermediate frames j=0,…,k−2, the agent emits committed actions drawn from the reflex policy: at+j∼πreflex(⋅∣st+j) On the terminal frame, the refined action distribution πk produced by ck is applied: at+k−1∼πk(⋅∣st) This formulation defines a transition kernel Pk(s′∣s) and an option-level reward Rk(s).
The gating policy πgate(k∣st) operates as a meta-policy over these options. At each meta-decision state st, the agent samples a budget k, executes option ok, and returns to the meta-level in state st+k after k primitive frames. The induced control problem is an SMDP with holding time τ(k)=k. The meta-Bellman equation is: V(st)=Ek∼πgate(⋅∣st)[∑j=0k−1γjrt+j+γkV(st+k)] This transforms the problem from selecting primitive actions to selecting temporally extended computation-and-control routines.
Gating Policy Architecture and Behavior The gating policy takes three inputs at each meta-step: the raw game observation, the planner’s intermediate spatial features extracted from its frozen trunk, and the planner’s scalar value estimate V(st). In clock environments, the remaining time budget is also included. A lightweight network processes these inputs to produce a distribution over k.
This design enables the gate to respond to meaningful decision difficulty. In committed-action environments, the policy allocates deeper planning (higher k) precisely when the state is dangerous or constrained.
As shown in the figure below:
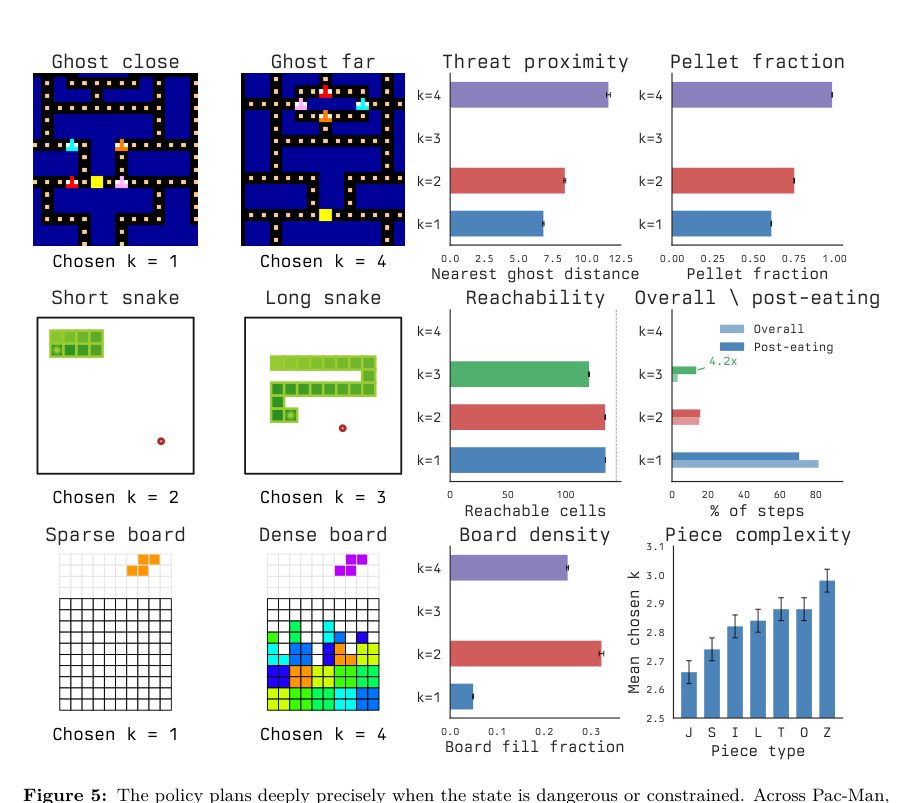
For example, in Pac-Man, larger budgets are chosen when the nearest ghost is far, allowing for deeper planning, while close threats trigger reactive k=1 responses. In real-time Tetris, dense boards trigger deeper search compared to near-empty boards.
In clock environments, the allocation strategy shifts based on the interaction between board state and remaining time.
As shown in the figure below:

Under small clock budgets, the policy heavily favors the cheapest options due to high opportunity costs, whereas larger budgets allow for more even distribution across deeper search options.
Training Process The authors employ a two-phase training procedure. First, they train AlphaZero-style base planners for each environment. For clock environments, these are trained via self-play. Once the base planner is selected, it is frozen. The gating policy is then trained using Proximal Policy Optimization (PPO) on top of the frozen planner. To accommodate the variable duration k of meta-steps, the authors adapt Generalized Advantage Estimation (GAE) to carry the per-meta-step discount γk through the advantage computation.
Experiment
The evaluation spans classic real-time games (Pac-Man, Tetris, Snake) and clock-constrained board games (Speed Hex, Speed Go), comparing a learned gating policy against fixed-budget and heuristic baselines to show that dynamic compute allocation consistently outperforms static strategies. The gating policy learns to trigger deeper planning based on state features such as ghost proximity, board density, or spatial constraints, and it generalizes across clock budgets, shifting allocation in response to remaining time. Real-time deployment with asynchronous two-GPU execution validates the committed-action training protocol, with policies transferring cleanly and preserving both returns and budget distributions, supporting the abstraction of simulated committed steps as a model for hardware-separated planning.