Command Palette
Search for a command to run...
Qwen-Image-Agent: 実世界における画像生成のコンテキストギャップを埋める
Qwen-Image-Agent: 実世界における画像生成のコンテキストギャップを埋める
概要
テキストから画像への変換(T2I)モデルは著しい進歩を遂げているものの、しばしば指定が不十分であったり暗黙的であったり、最新の知識に依存したりする現実世界のリクエストには対応が困難である。本研究では、この課題を「Context Gap」として位置づける。これは、ユーザーの文脈とT2Iモデルによる生成に必要な十分な文脈との不一致を指す。このギャップを解消するため、本研究ではQwen-Image-Agentを提案する。これは、plan, reason, search, memory, feedbackを文脈中心の手法で統合する統一されたagentic frameworkである。Qwen-Image-Agentはユーザー入力を部分的な文脈として扱い、Context-Aware PlanningおよびContext Groundingを通じて生成文脈を段階的に構築する。具体的には、Context-Aware Planningが不足している文脈を特定し、その取得方法および利用方法を計画する。一方、Context Groundingはreason, search, memory, feedbackから当該文脈を収集する。agentによる画像生成を評価するため、本研究ではImage Agent Bench(IA-Bench)を新たに導入する。これは、Plan, Reason, Search, Memoryの4つのコアimage agent能力を網羅するベンチマークである。IA-Bench、Mindbench、WISE-Verified上での実験により、Qwen-Image-Agentが強力なベースラインを上回り、最先端の性能を達成することが示された。
One-sentence Summary
Qwen-Image-Agent bridges the context gap in real-world text-to-image generation through a unified agentic framework that employs Context-Aware Planning and Context Grounding to progressively integrate reasoning, search, memory, and feedback, thereby achieving state-of-the-art performance on the IA-Bench, Mindbench, and WISE-Verified benchmarks.
Key Contributions
- Qwen-Image-Agent is a training-free agentic framework that bridges the context gap in text-to-image generation by unifying planning, reasoning, search, memory, and feedback. The system progressively constructs sufficient generation context through Context-Aware Planning and Context Grounding to handle underspecified or implicit user requests.
- IA-Bench systematically evaluates agentic image generation across plan, reason, search, and memory capabilities using 17 real-world tasks, 730 test instances, and 1801 fine-grained checklist items. A structured vision-language model evaluation protocol ensures reliable assessment of these core agent functions.
- Experiments on IA-Bench, MindBench, and WISE-Verified demonstrate that Qwen-Image-Agent substantially outperforms strong agentic baselines and achieves state-of-the-art performance. Ablation studies confirm that integrating multiple grounded context sources yields complementary improvements in generation quality and task completion.
Introduction
Text-to-image models have advanced rapidly, yet their deployment in practical fields like marketing and product design is hindered by a fundamental mismatch between explicit training prompts and the underspecified, knowledge-dependent requests users actually submit. Prior work has explored isolated agentic capabilities such as planning, reasoning, or web search, but these efforts remain fragmented and fail to systematically acquire and integrate the missing context required for real-world generation. The authors bridge this divide with Qwen-Image-Agent, a unified framework that progressively constructs complete generation context through context-aware planning and multi-source grounding. The authors leverage reasoning, web search, memory, and iterative feedback to transform incomplete user inputs into fully specified generation conditions. To validate this approach, the authors also introduce IA-Bench for systematically evaluating agentic capabilities and demonstrate state-of-the-art performance across multiple benchmarks.
Dataset
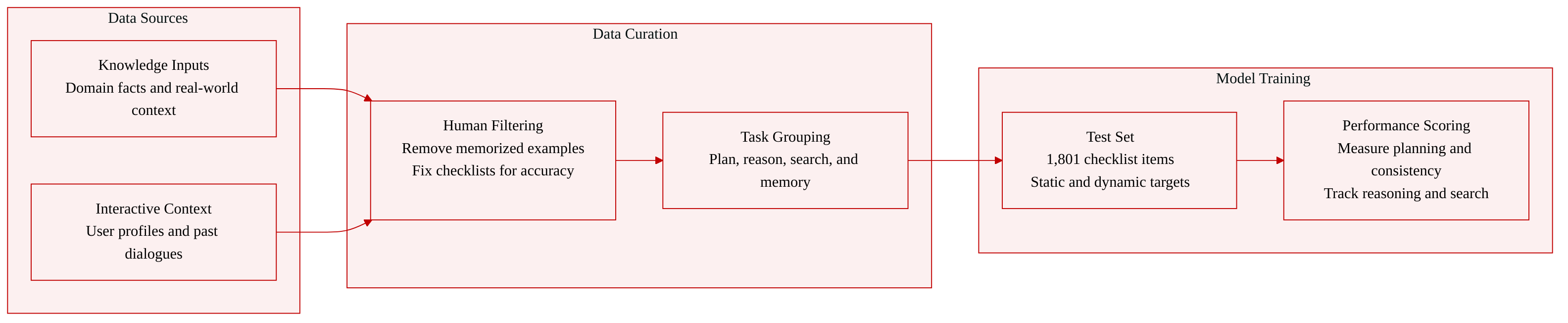
- Dataset Composition and Sources: The authors introduce IA-Bench, a benchmark designed to holistically evaluate agentic capabilities in image generation. It consists of 730 instances organized into four primary tasks and seventeen subtasks, supported by 1,801 evaluation checklist items. The data draws from domain knowledge, physical commonsense, logical and spatio-temporal reasoning, external world knowledge, and interactive conversational context.
- Key Details for Each Subset:
- Planning tasks (Composition, Enumeration, Multi-Panel) focus on decomposing high-level goals into structured layouts and satisfying multi-object constraints.
- Reasoning tasks (Math, Science, Commonsense, Maze, Map, Geometry) test logical, commonsense, and visual reasoning to infer latent constraints before rendering.
- Search tasks (IP entities like games and celebrities, plus Information like stocks and weather) evaluate the ability to retrieve and ground external or real-time knowledge.
- Memory tasks (User Profile and Conversation History) assess cross-turn consistency and the retention of persistent user attributes or prior dialogue.
- How the Paper Uses the Data: The authors use IA-Bench strictly as an evaluation framework to measure planning, reasoning, search, and memory capabilities. The dataset is not applied to model training, fine-tuning, or data mixing, and no training splits or mixture ratios are utilized.
- Processing and Construction Details: The benchmark relies on careful human annotation to balance quality and difficulty. The authors filter out instances solvable by memorization or pretrained visual priors, such as removing highly iconic characters that models can generate without external search. Evaluation checklists are initially generated by LLMs and then manually refined for accuracy and necessity. For memory-focused tasks, the authors implement dynamic evaluation checklists where reference targets adapt based on previously generated images rather than static ground truth. Feasibility is verified and evaluation ambiguity is minimized across all subtasks.
Method
The authors leverage a conditional rendering formulation that explicitly accounts for the discrepancy between incomplete user inputs and the complete context required by image generators. To resolve this context gap, the framework treats the image generator as a renderer and introduces an iterative context construction process. At each step, the agent maintains a state st=(ct,Ot−1) representing the current context and accumulated observations, selects an action at from a defined operation space, and receives an observation ot. This interaction forms a trajectory τ={(st,at,ot)}t=1T. The overall generation process is mathematically expressed as:
pagent(y∣cu)=τ∑p(τ∣cu)pgen(y∣cg=c(τ))Under this formulation, the agent progressively builds the generation context before executing the final rendering pass.
The architecture is organized around two core modules: Context-Aware Planning and Context Grounding. Context-Aware Planning operates across three hierarchical levels to systematically manage information flow. Information-level planning identifies missing context elements and routes specific queries to appropriate grounding strategies. Content-level planning assembles the retrieved signals and rewrites the initial prompt into a detailed specification that explicitly defines subjects, attributes, layout, style, and textual elements. Generation-level planning handles context allocation for multi-turn and multi-image workflows, mitigating content drift by filtering relevant historical information and distributing context across dependent images.
Context Grounding collects and structures missing information through four distinct mechanisms. Reasoning grounding employs vision-language models to infer implicit intents through commonsense, logical, and visual reasoning, transforming underspecified requests into concrete context items. Search grounding retrieves external factual knowledge or visual references by extracting keywords, performing web queries, and utilizing vision-language models to rank and retain the most relevant results. Memory grounding preserves continuity in extended interactions by incorporating conversation history, updating user profiles, and querying external multimodal knowledge bases via a dedicated retriever. Feedback grounding closes the iterative loop by evaluating generated outputs against a predefined attribute checklist. Vision-language models assess each result, and any discrepancies are converted into feedback signals that are merged with existing context to refine the prompt for subsequent generation rounds.
Experiment
The evaluation employs a checklist-based VLM protocol across three distinct benchmarks to systematically assess planning, reasoning, search, and memory capabilities against a wide range of proprietary and open-source baselines. Quantitative and qualitative analyses demonstrate that the proposed agentic framework substantially outperforms direct generation models by effectively bridging context gaps through progressive information grounding and iterative refinement. Ablation studies further validate that sustained performance relies on a powerful multimodal language backbone, carefully structured contextual inputs, and a capable image renderer. Ultimately, the findings underscore the necessity of intelligent context management for complex image synthesis while highlighting ongoing challenges in handling implicit requirements, multiturn context limits, and computational efficiency.
The authors evaluate image generation models on the IA-Bench benchmark, comparing closed-source, open-source, and agentic methods. Results show that the proposed Qwen-Image-Agent achieves the highest overall IA-score, significantly outperforming both direct generation baselines like Qwen-Image-2.0 and other agentic models. The agentic framework demonstrates substantial improvements in Plan, Reason, and Search capabilities, while closed-source models retain a noticeable advantage in Memory performance. Qwen-Image-Agent achieves the highest overall IA-score among all evaluated models. The agentic framework significantly improves performance over the direct generation baseline Qwen-Image-2.0. Agentic models generally outperform direct generation models in Plan, Reason, and Search dimensions.
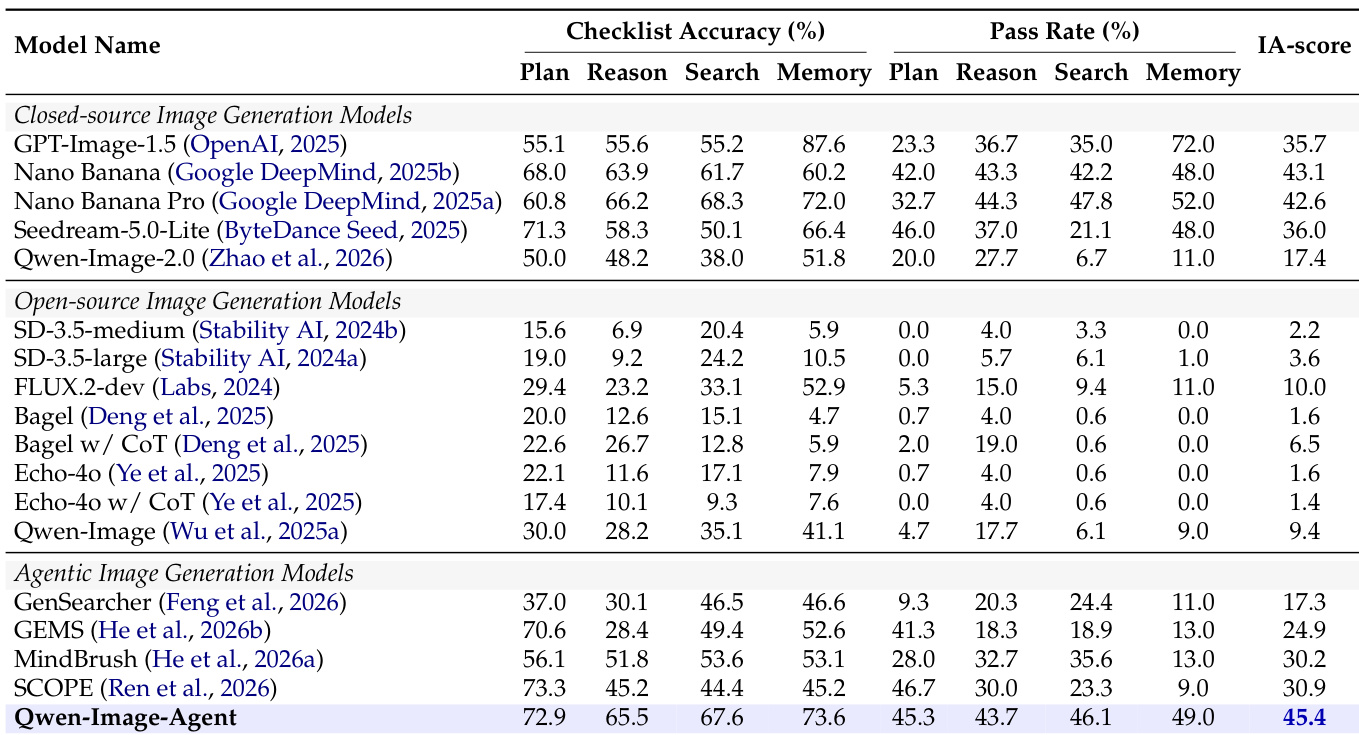
The evaluation of Qwen-Image-Agent on the IA-Bench demonstrates its superior performance compared to a wide range of proprietary and open-source baselines. The model achieves the highest overall scores, significantly outperforming strong closed-source models like Nano Banana Pro and GPT-Image-1.5 across both knowledge-driven and reasoning-driven tasks. Qwen-Image-Agent achieves the highest overall IA-score, surpassing leading proprietary models. The model demonstrates substantial improvements in knowledge-driven and reasoning-driven capabilities. The agentic framework significantly boosts performance over the direct generation baseline Qwen-Image-2.0.
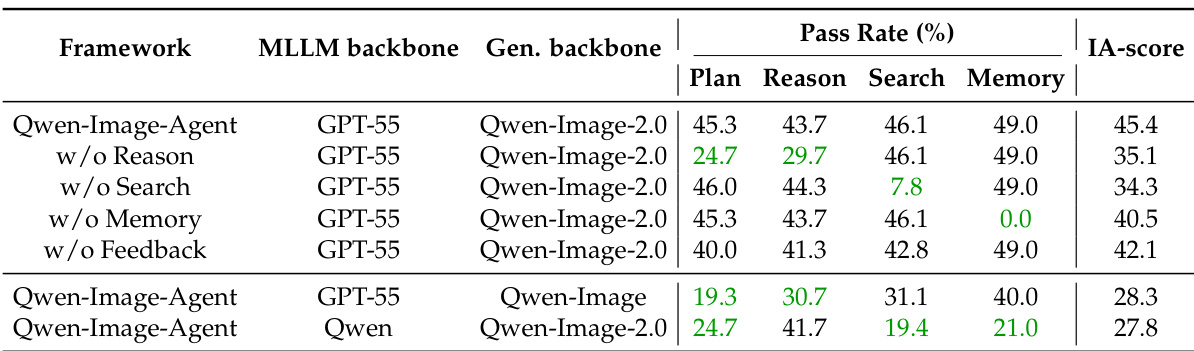
The authors conduct an ablation study to validate the contribution of specific components within the Qwen-Image-Agent framework. The results demonstrate that the full system significantly outperforms ablated versions, with the removal of any grounded context leading to a distinct decline in its corresponding evaluation dimension. Furthermore, substituting the MLLM or generation backbones with weaker alternatives consistently degrades performance across all metrics. Removing the memory context leads to a complete collapse in the memory dimension performance. The search component is critical for search capabilities, as removing it causes a drastic decline in that specific metric. Replacing the MLLM or generation backbones with weaker models results in consistent performance degradation across all evaluated capabilities.
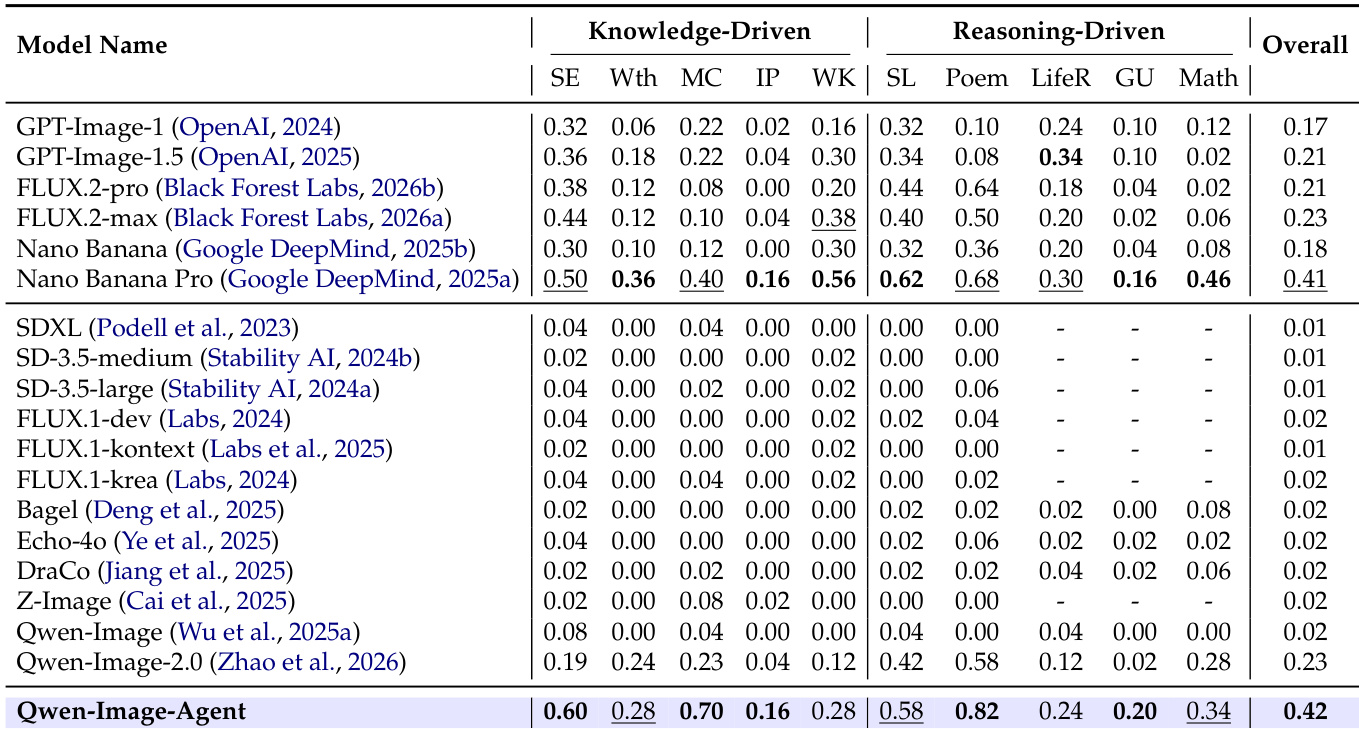
The authors present an evaluation of Qwen-Image-Agent against various proprietary and open-source baselines to measure semantic understanding and world knowledge. The results demonstrate that Qwen-Image-Agent achieves the highest performance across all categories, including culture, time, space, biology, physics, and chemistry. It significantly outperforms strong closed-source models like Nano Banana Pro and GPT-Image-1.5, validating the effectiveness of the proposed agentic framework. Qwen-Image-Agent achieves the highest overall score, outperforming all other listed models including Nano Banana Pro and GPT-Image-1.5. The model demonstrates consistent superiority across all specific knowledge domains such as biology, physics, and chemistry. The agentic framework shows substantial improvements over direct generation baselines like Qwen-Image-2.0.
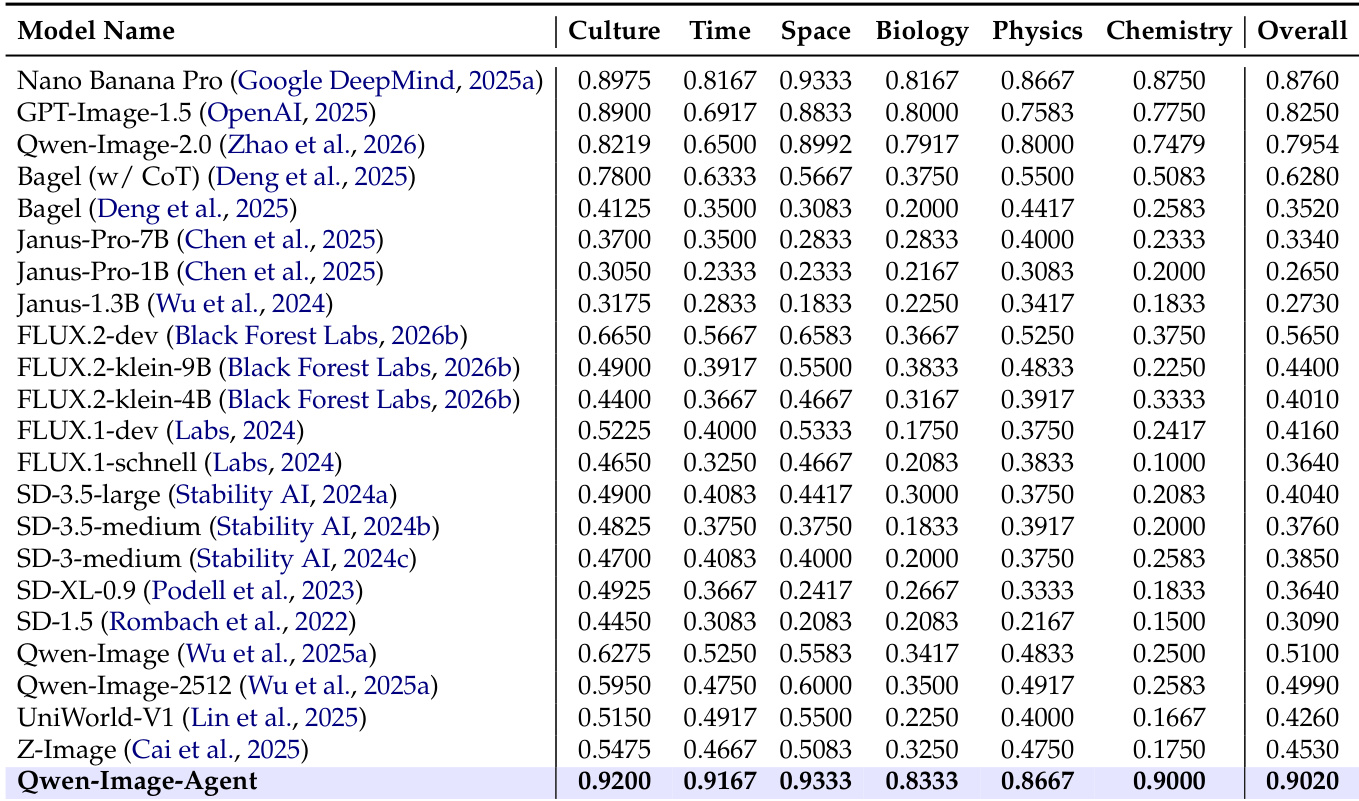
Evaluated on the IA-Bench benchmark, Qwen-Image-Agent is compared against direct generation baselines, other agentic approaches, and leading proprietary models, while an ablation study validates the necessity of its core architectural components. The benchmark evaluation demonstrates that the agentic framework substantially enhances planning, reasoning, search, and domain-specific knowledge capabilities, establishing a clear qualitative advantage over direct generation methods. Component analysis confirms that each module is essential for maintaining robust performance across all evaluated dimensions. Ultimately, the model achieves consistent superiority across knowledge and reasoning tasks, though proprietary baselines retain a relative edge in memory retention.