Command Palette
Search for a command to run...
AUTOMEM: 認知的スキルとしての記憶の自動学習
AUTOMEM: 認知的スキルとしての記憶の自動学習
Shengguang Wu Hao Zhu Yuhui Zhang Xiaohan Wang Serena Yeung-Levy
概要
記憶の熟達は学習可能なスキルである。何を符号化し、いつ検索し、どのように知識を組織化するかを知ること、これは認知科学でメタ記憶と呼ばれる能力である。我々はこの視点を大規模言語モデル(LLM)に適用し、記憶管理を訓練可能なスキルとして扱う。ファイルシステム操作をタスクアクションと並ぶ第一級の記憶アクションに昇格させ、モデル自身に記憶の管理方法を決定させる。この記憶スキルは、それを支える構造(プロンプト、ファイルスキーマ、アクション語彙)と、それを行使するモデルの習熟度という2つの軸に沿って向上する。両軸とも手動最適化には抵抗を示す。長時間タスクのエピソードは数千ステップに及び、単一の記憶ミスが表面化するまで長く潜伏しうるため、全軌跡の人間によるレビューは非現実的である。我々はAUTOMEMを導入する。これは両軸を自動化するフレームワークである。第一のループでは、強力なLLMがエージェントの完全な軌跡をレビューし、エージェントが記憶ファイルと対話する方法を形成する記憶構造を反復的に改訂する。第二のループでは、多数のエピソードからエージェント自身の良好な記憶判断を特定し、それを訓練信号として用いてモデルの記憶習熟度を直接的に向上させる。手続き的に生成される3つの長時間ゲーム(Crafter、MiniHack、NetHack)において、モデルのタスクアクション行動を変更せずに記憶のみを最適化することで、ベースエージェントの性能が約2倍から4倍向上し、32BのオープンウェイトモデルがClaude Opus 4.5やGemini 3.1 Pro Thinkingといった最先端システムと競合する水準に達した。我々の結果は、記憶管理が独立して学習可能なスキルであり、長時間タスクにおいて大きな利益をもたらす高レバレッジな目的であることを示している。
One-sentence Summary
Stanford researchers propose AUTOMEM, which treats memory management as a learnable cognitive skill by using two iterative loops to automate memory-structure design and model proficiency, boosting performance by ∼2–4× on the procedurally generated long-horizon games Crafter, MiniHack, and NetHack and making a 32B open-weight model competitive with frontier systems such as Claude Opus 4.5 and Gemini 3.1 Pro Thinking.
Key Contributions
- AUTOMEM is a framework that automates the optimization of an LLM agent's memory skill along two axes: the memory structure (prompts, file schemas, action vocabulary) and the model's proficiency at memory decisions.
- The framework employs a dual-loop design where one loop uses a strong LLM to review complete long-horizon trajectories and iteratively revise the memory scaffold, and a second loop extracts successful memory decisions from many episodes as training signal to sharpen the agent's memory proficiency without altering task-action behavior.
- Across Crafter, MiniHack, and NetHack, optimizing memory alone with AUTOMEM yields 2× to 4× performance gains, lifting a 32B open-weight model to be competitive with Claude Opus 4.5 and Gemini 3.1 Pro Thinking, and demonstrating that memory management is an independently learnable, high-leverage skill.
Introduction
The authors tackle the bottleneck that fixed-size context windows impose on large language models (LLMs) by treating external memory management as an independently trainable skill rather than a fixed architectural module. Prior work typically hard-codes retrieval mechanisms or static buffers into the system, but manually optimizing memory behavior across episodes spanning tens of thousands of steps is intractable for humans. The authors promote file-system operations as first-class actions and introduce AUTOMEM, a framework in which a meta-LLM reviews complete episode traces to automatically improve both the memory scaffold (the prompts, file schema, and validation logic) and the agent’s parametric memory proficiency through targeted finetuning of a dedicated memory specialist, yielding two- to four-fold performance gains on long-horizon game environments.
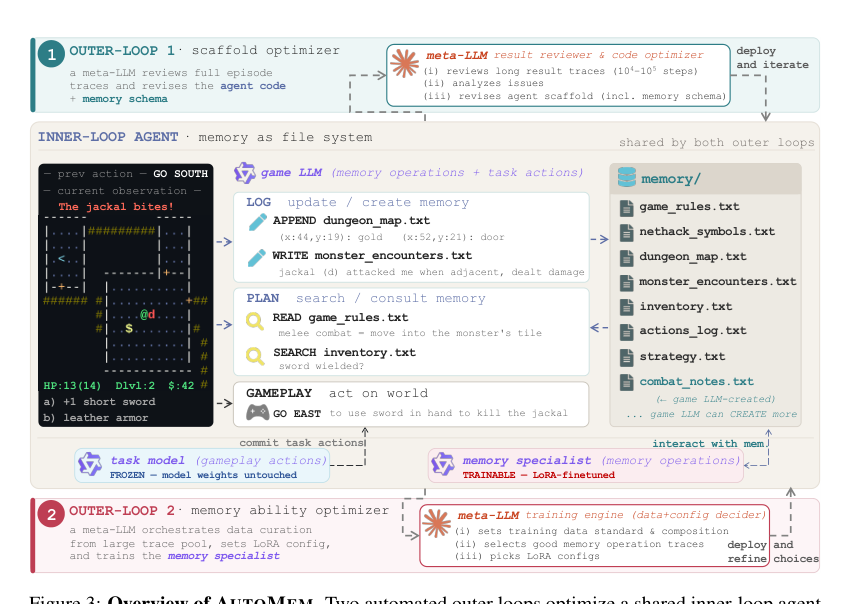
Method
The authors proposeAUTOMEM, a framework that automates the optimization of memory skills along two axes: structure and proficiency. This is achieved through two sequential outer loops that operate on a shared inner-loop agent.
The inner loop consists of a single LLM agent executing an episode of a long-horizon task. The agent is equipped with a directory of files on disk that serves as its external memory. At each step, the agent runs two routines. The LOG routine determines what information is worth recording about the environment's response to the previous action, such as appending to an existing file, creating a new one, or rewriting an entry. The PLAN routine determines what needs to be recalled to act now by searching across files, reading specific entries, and committing the next world action. By promoting file-system operations as first-class memory actions in the model's action space, memory becomes a learnable skill rather than a fixed mechanism.
The first outer loop optimizes the structure supporting the memory skill. The agent scaffold, which includes the code, prompts, file schema, and action vocabulary, is iteratively revised by a meta-LLM. Because the consequences of memory decisions are often delayed in long-horizon tasks, the optimization signal must be trajectory-level. The meta-LLM is provided with full episode traces, including per-step logs, the resulting memory directories, and the agent code itself. It functions as a code reviewer, identifying points where the scaffold caused failures. For example, the meta-LLM might identify that an unbounded map file is accumulating duplicate entries and respond by introducing a coordinate-keyed deduplication format.
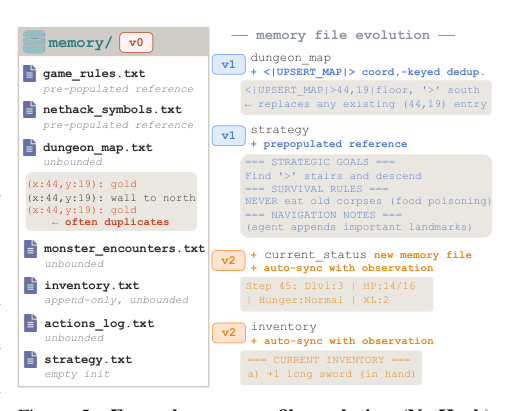
Each iteration is gated on measured improvement. The rewritten agent plays the same fixed seeds as the previous version, and the revision is kept only if the average progression improves. At rough convergence, typically after a few iterations, the scaffold has absorbed what code revision can express.
Once the scaffold is optimized, the model's parametric ability to navigate its memory becomes the remaining bottleneck. The second outer loop addresses this by training the model's memory proficiency. The meta-LLM acts as a training engine, orchestrating the supervised training process end-to-end. It reads the inner-loop agent code and a pool of episode traces to derive selection criteria and produce supervised training data. Every example in the training set is verbatim text produced by the inner-loop model during an episode. The meta-LLM selects which responses to reinforce, acting as a filter on the model's own behavior.
To ensure the training effectively absorbs the curated data, the meta-LLM training engine jointly orchestrates the data selection logic, data composition, and LoRA training configuration as a single decision, refining all three across iterative trials. Because memory is a separable skill, it is trained as a distinct target rather than finetuning on full episodes. During inference, the inner loop runs two model instances sharing a single conversation history. The memory specialist, a LoRA-finetuned copy, handles the LOG routine and the memory-consultation portion of the PLAN routine. The gameplay model, the unmodified base, commits the world action. This separation ensures the training signal stays focused on memory-operation behavior while preserving the base model's competence at producing well-formatted world actions.
Experiment
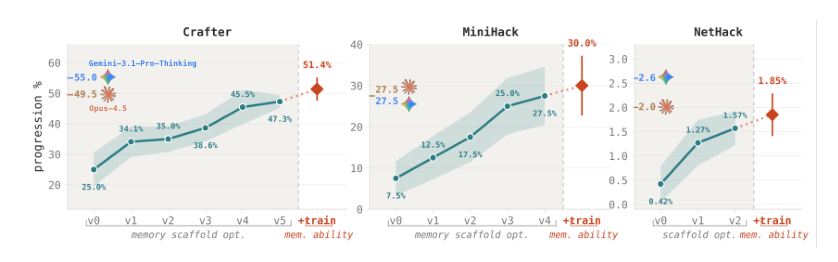
The experiments evaluate a Qwen2.5-32B-Instruct agent on three procedurally generated long-horizon games, where scaffold optimization that revises prompts and external memory schemas alone more than triples task progression without any model weight changes, outperforming both larger models and standard context-window approaches. Adding a separate memory-proficiency training loop further improves performance, bringing the open-weight agent to a level competitive with frontier proprietary systems. Qualitative analysis reveals that the optimized scaffold reduces wasteful task repetition and redundant memory operations while compressing context, and the trained specialist internalizes a consult-before-write pattern that improves memory use, demonstrating that memory management is a highly effective axis for long-horizon agent behavior.
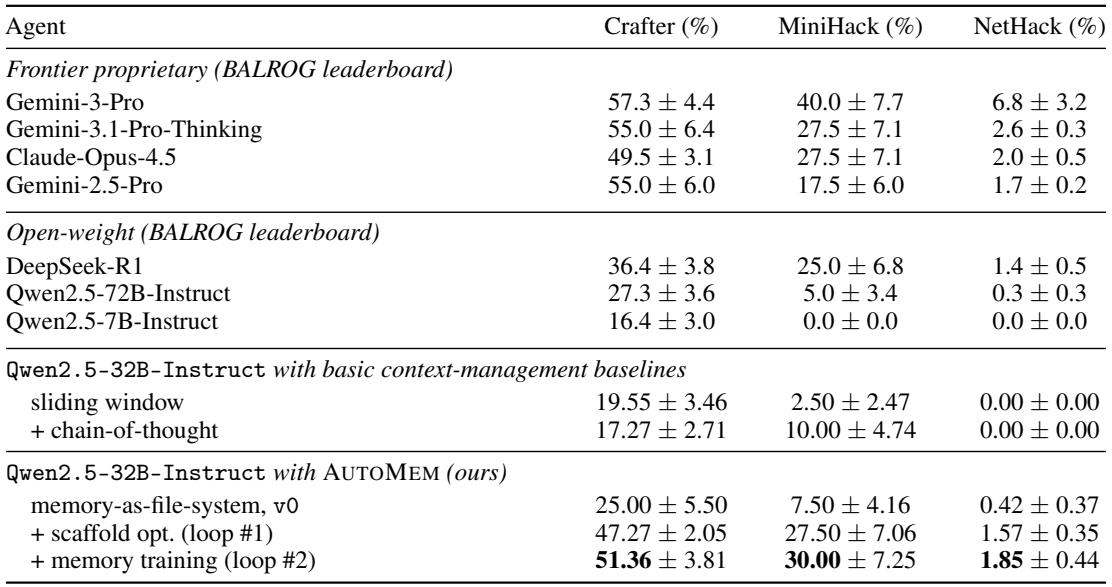
Starting from a 32B open-weight model with basic context management, optimizing the agent’s memory scaffold doubles or triples progression rates across long-horizon games, and adding a memory-training loop yields further complementary gains that bring the model close to frontier proprietary systems. The improvements derive from structural changes that slash redundant logging by 95% and from training the model to consult existing memory before writing, reducing memory waste. Scaffold optimization alone multiplies progression rate by 1.9× on Crafter, 3.7× on MiniHack, and 3.7× on NetHack. With both scaffold optimization and memory training, the 32B model reaches 51.4% on Crafter, 30.0% on MiniHack, and 1.9% on NetHack, comparable to Claude-Opus-4.5 (49.5%, 27.5%, 2.0%). The evolved memory structure reduces per-step memory growth from 138 to 6 characters (95% reduction), eliminating unbounded append-only log bloat.
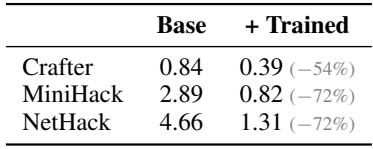
Training a memory specialist sharply reduces memory writes per search, instilling a consult-before-write discipline. The specialist searches existing files before appending new content, cutting the write-to-search ratio by more than half in Crafter and by over 70% in MiniHack and NetHack. This internalized pattern complements the optimized scaffold's structured memory, leading to more efficient and goal-directed agent behavior. The write-to-search ratio drops from 0.84 to 0.39 in Crafter, 2.89 to 0.82 in MiniHack, and 4.66 to 1.31 in NetHack after training the specialist. The specialist consistently searches memory before writing, avoiding blind appends and reducing redundant logging by up to 72%.
Optimizing the agent’s memory scaffold and training a memory specialist to consult memory before writing dramatically improve performance on long-horizon tasks, bringing a 32B open-weight model close to frontier proprietary systems. Restructuring memory alone eliminates 95% of per-step log bloat and boosts progression rates, while memory training cuts redundant writes by more than half by instilling a disciplined consult-before-write pattern.