Command Palette
Search for a command to run...
ASPIRE: ロボティクスのためのエージェント型スキル発見
ASPIRE: ロボティクスのためのエージェント型スキル発見
概要
従来のロボットプログラミングは、マルチモーダルな知覚の統合、複雑な物理的接触ダイナミクスの管理、多様な環境設定や実行失敗への対処が必要であり、極めて困難である。我々はAspire(反復的ロボット探索によるエージェント型スキルプログラミング)を提案する。これは、コード・アズ・ポリシーのパラダイムでロボット制御プログラムを自律的に作成・改良し、経験を再利用可能なスキルライブラリに蓄積する継続学習システムである。Aspireは、複数のタスク、シミュレーションと実環境、異なるエンボディメントにわたって持続する再利用可能なスキルの自動発見を可能にする。固定された人間設計のパイプラインに依存せず、Aspireは以下の3つの主要コンポーネントからなるオープンエンドな学習ループで動作する:(1) 詳細なマルチモーダルトレース(知覚オーバーレイ、把持候補、動作軌道、衝突フィードバックなど)を公開する閉ループロボット実行エンジン。これによりエージェントは自律的に失敗を診断し、修正を合成し、結果を検証できる。(2) 検証済みの修正を再利用可能で転移可能なロボット知識へと蒸留する、継続的に拡張されるスキルライブラリ。(3) 多様なタスクシーケンスと制御プログラムを生成し、体系的にデバッグすることで単一軌道の改良を超えた探索を行う進化的探索手順。Aspireがより多くのタスクに遭遇するにつれて、成長するスキルライブラリにより適応が加速する。その結果、Aspireは摂動下のマニピュレーションタスク(LIBERO-Pro)で最大77%、Robosuiteの双腕ハンドオーバータスクで72%、長時間の家庭内タスク(BEHAVIOR-1K)で最大32%、従来手法を上回った。蓄積されたスキルライブラリは強力なゼロショット汎化を可能にする:代表的な未見の長時間タスク(LIBERO-Pro Long)において、Aspireは31%の成功率を達成し、テスト時推論と再試行に大きく依存する従来手法の4%を大幅に上回った。最後に、シミュレーションで発見されたスキルは、異なるエンボディメントやロボットAPIにもかかわらず、実ロボットへのプログラミング労力を大幅に削減するsim-to-real転移の初期証拠を提供する。
One-sentence Summary
NVIDIA et al. propose ASPIRE, an agentic skill discovery system that autonomously refines robot control programs through closed-loop multimodal traces, an evolving skill library, and evolutionary search, achieving up to 77% improvement on manipulation tasks (LIBERO-Pro), 72% on Robosuite's bimanual handover task, 32% on long-horizon household tasks (BEHAVIOR-1K), 31% zero-shot success on LIBERO-Pro Long tasks (vs. 4% for prior methods), and initial sim-to-real transfer.
Key Contributions
- Aspire’s closed-loop robot execution engine integrates fine-grained multimodal traces (perception overlays, grasp candidates, motion trajectories, collision feedback) to autonomously diagnose failures and synthesize program repairs, contributing to a performance gain of up to 77% on manipulation tasks under perturbation (LIBERO-Pro).
- A continually expanding skill library distills validated program fixes into reusable and transferable robotic knowledge, enabling strong zero-shot generalization with a 31% success rate on unseen long-horizon tasks (LIBERO-Pro Long) compared to just 4% for prior methods.
- An evolutionary search procedure generates diverse task sequences and control programs, systematically debugging them beyond single-trajectory refinement, yielding gains of up to 72% on Robosuite's bimanual handover task and 32% on long-horizon household tasks (BEHAVIOR-1K).
Introduction
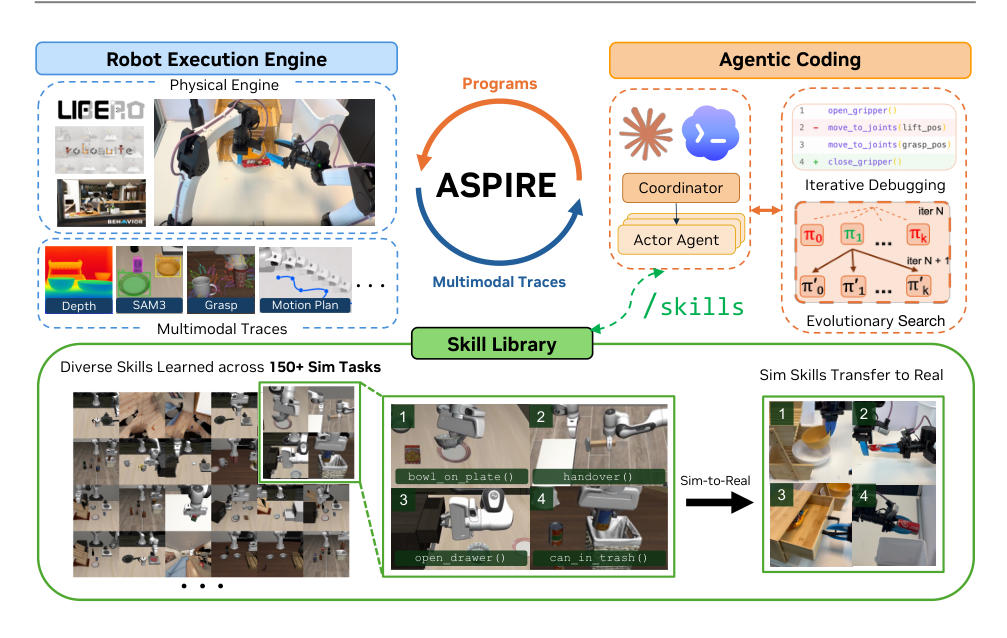
The authors tackle the challenge of building robot coding agents that can improve over time, not just solve single tasks. Existing code-as-policy systems compose perception, planning, and control primitives into executable programs, but they rely on coarse task-level feedback that makes it hard to diagnose why a program failed across all the interacting components. Moreover, these agents discard fixes and recovery strategies after each task, so they never accumulate experience. The authors introduce Aspire, a self-improving robotic system that overcomes these limitations by providing a closed-loop execution engine with per-primitive multimodal traces, a continually expanding skill library that stores validated repairs for future reuse, and an evolutionary search procedure that explores diverse fixes. Aspire’s main contribution is enabling autonomous, continual learning where debugging knowledge compounds across tasks, leading to strong performance gains and zero-shot transfer on long-horizon and real-world manipulation.
Method
The authors propose Aspire, a system that forms an open-ended learning loop through three core components: a robot execution engine, a skill library, and an evolutionary search procedure. As the system encounters more tasks, its skill library grows, allowing future tasks to inherit accumulated repairs and reusable strategies.
Aspire adopts a coordinator-actor architecture. A central coordinator manages the shared skill library and dispatches actor coding agents to individual tasks. Each actor writes, executes, diagnoses, and repairs robot programs within the robot execution engine. Actors do not exchange full chat histories or raw rollout trajectories. Instead, transferable experience is distilled into the skill library, allowing each actor's context window to remain focused on the task specification, current program, and structured execution traces associated with the current failure.
Refer to the framework diagram:
The robot execution engine turns the fixed feedback channel into an open-ended debugging environment. It records per-primitive multimodal traces for perception, planning, and control calls, exposes the trace to the coding agent, and executes agent-written repairs for closed-loop validation. For each primitive call, the trace stores the invoked API, inputs and outputs, return status, and relevant multimodal evidence such as RGB keyframes, overlays, grasp candidates, object poses, and motion-planning results. The agent does not receive full video frames; the engine keeps frames immediately before and after each primitive call together with the corresponding overlays and return values, so the agent can focus on evidence around calls implicated by the failure.
As shown in the figure below:

This debugging episode illustrates how the primitive trace localizes a failure. The ego-view keyframes show that the robot finds the radio but repeatedly fails to approach it. The primitive trace reveals that perception succeeds and returns a radio pose, but repeated navigation calls return a planning error. By checking the navigation return values and associated logs, the agent finds that the generated navigation target lies too close to the table boundary, triggering collision avoidance. The agent then patches the program with a multi-angle approach routine that samples alternative navigation targets around the radio, successfully completing the grasp.
Program failures recur across tasks, but the reusable knowledge is rarely an entire task program. Aspire's skill library stores heterogeneous repair knowledge, including localization heuristics, perception prompts, grasping constraints, navigation recovery strategies, motion primitives, scene-understanding routines, and debugging workflows. Skills are induced from validated repairs: the coding agent diagnoses a failure from execution traces, patches the program, validates the fix on debugging configurations, and the coordinator admits only reusable patterns into the shared library.
Each skill is stored as compact in-context guidance, including the failure signature, when-to-apply condition, repair strategy, and a representative code sketch.
As shown in the figure below:

The library grows across heterogeneous categories. For the radio task mentioned earlier, the admitted skill is a navigation recovery pattern rather than a complete radio-pickup program. This representation lets future actors reuse validated repairs instead of rediscovering them through test-time reasoning, supports zero-shot transfer to harder simulated tasks, and provides the mechanism for selected simulation-discovered skills to generalize across embodiments and transfer to real robots. Actors report structured findings that summarize the failure mode, validated fix, and potentially transferable repair pattern. The coordinator audits these findings, verifies compliance with the allowed API policy, and promotes only reusable repairs that have passed debug validation into the shared skill library.
Trace-guided debugging alone can collapse into local repair loops, where the agent repeatedly patches the same failed strategy instead of exploring fundamentally different ways to solve the task. Aspire uses evolutionary search to broaden exploration of executable robot programs, encouraging diverse repair hypotheses and task strategies. In each round, based on the skill library, the coding agent proposes a population of k candidate programs conditioned on the top-performing previous programs and failure traces from previous evaluations. Each candidate is executed in the robot execution engine, producing task outcomes together with new diagnostic traces. The next round is then conditioned on the best-performing programs together with their remaining failure modes, allowing the search to explore distinct strategies rather than repeatedly refining the same solution. The search target is the robot program itself. Candidates are selected through closed-loop execution, and validated repairs are admitted into the skill library after search concludes, provided they generalize across environment variations and tasks. Search terminates when a candidate solves the debugging configurations or when the search budget is exhausted.
Experiment
Across simulated manipulation benchmarks, Aspire substantially outperforms both code-as-policy baselines and end-to-end VLA policies, especially under object, goal, and spatial perturbations and on long-horizon tasks. Zero-shot transfer experiments show that the skill library accumulated on short-horizon tasks steadily benefits unseen long-horizon compositions. Real-robot skill transfer across embodiments reduces debugging cost and improves success, confirming that failure-derived repairs generalize beyond simulator-specific code. Ablation studies identify the robot execution engine as the dominant contributor to performance, with evolutionary search offering further gains on difficult cases.
Retrieving simulation-discovered skills consistently reduces the debugging token cost for real-robot program synthesis across all tasks. The impact on success rate is task-dependent: bowl placement succeeds in both settings, soda-can lifting improves markedly, and drawer manipulation only reaches success when skill guidance is provided. These findings indicate that failure-derived skills offer reusable in-context guidance that transfers across embodiments and API changes. Skill retrieval lowers total token usage for every task, with the largest relative reduction seen in soda-can lifting (nearly an order of magnitude). Without skills, drawer manipulation exhausts a large token budget and never produces a successful program; with skills, it reaches 11/20 success while using far fewer tokens. Bowl placement achieves perfect success in both conditions, but skill guidance still reduces the debugging token count. Soda-can lifting success improves from 13/20 to 19/20 when skills are used, alongside a dramatic drop in token cost.

Retrieving simulation-discovered skills consistently reduces the debugging token cost for real-robot program synthesis across all tasks, with the largest relative drop seen in soda-can lifting. Success rates improve variably: bowl placement succeeds in both settings, soda-can lifting improves markedly, and drawer manipulation only reaches success with skill guidance. These failure-derived skills provide reusable in-context guidance that transfers across embodiments and API changes, enabling cost-effective completion of otherwise unsolvable tasks.