Command Palette
Search for a command to run...
Dockerless: コーディングエージェントのための環境不要プログラム検証器
Dockerless: コーディングエージェントのための環境不要プログラム検証器
概要
プログラム検証器は、教師ありファインチューニング(SFT)のための軌跡選択や強化学習(RL)の報酬提供など、コーディングエージェントの訓練において中心的な役割を果たす。標準的な実行ベースの検証では、Dockerイメージのようなリポジトリごとの環境内でユニットテストを実行する必要があり、多大な環境構築コストが発生する。我々は、生成されたコードパッチを実行せずに評価する、環境不要のエージェント型パッチ検証器「Dockerless」を提案する。Dockerlessは、候補パッチを単純に参照と照合するのではなく、エージェントによるリポジトリ探索を通じて収集した証拠に基づいてパッチの正しさを判定する。検証器評価ベンチマークにおいて、Dockerlessは最強のオープンソース検証器を14.3 AUCポイント上回った。DockerlessをSFT軌跡フィルタおよびRL報酬の両方に用いることで、完全に環境不要なポストトレーニングパイプラインが実現される。得られたモデルは、SWE-bench Verified、Multilingual、Proにおいてそれぞれ62.0%、50.0%、35.2%の解決率に達し、Qwen3.5-9Bベースラインを2.4、8.7、2.9ポイント上回り、環境ベースのポストトレーニングに匹敵する性能を示した。
One-sentence Summary
Researchers from Shanghai Jiao Tong University and Douyin Group propose Dockerless, an environment-free patch verifier that uses agentic repository exploration to evaluate code correctness without execution, outperforming the best open-source verifier by 14.3 AUC points and enabling a fully environment-free post-training pipeline that boosts a Qwen3.5-9B coding agent to resolve rates of 62.0%, 50.0%, and 35.2% on SWE-bench Verified, Multilingual, and Pro, surpassing its baseline by 2.4, 8.7, and 2.9 points and matching environment-based post-training.
Key Contributions
- Dockerless, an environment-free agentic verifier, judges patch correctness by actively exploring the repository with real tool calls and outperforms the strongest open-source verifier by 14.3 AUC points on a verifier benchmark.
- Acting as both the trajectory filter for supervised fine-tuning and the reward signal for reinforcement learning, Dockerless enables a fully environment-free post-training pipeline.
- The resulting model achieves 62.0%, 50.0%, and 35.2% resolve rates on SWE-bench Verified, Multilingual, and Pro, surpassing the Qwen3.5-9B baseline by 2.4, 8.7, and 2.9 points and matching environment-based post-training performance.
Introduction
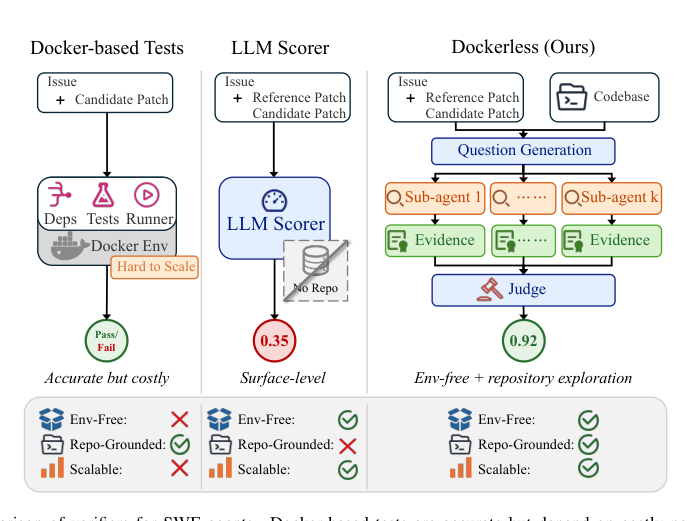
Automated coding agents depend on verifiers to judge whether a patch solves a task, providing correctness feedback for supervised fine-tuning and reinforcement learning. The gold standard of execution-based verification demands per-repository Docker environments with custom dependencies and test suites, but this approach often fails on private, legacy, or test-poor codebases and imposes heavy engineering overhead. Prior environment-free verifiers attempt to lower setup costs by scoring patches from a shared base image, yet they rely on shallow text or diff signals without inspecting the repository, making them unreliable for complex functional equivalence checks that require understanding call graphs and module integration. The authors address these limitations with Dockerless, an agentic verifier that actively explores the actual codebase by generating verification questions and dispatching sub-agents to collect repository evidence, thereby enabling a fully environment-free post-training pipeline while matching the accuracy of execution-based methods.
Method
The authors address the scalabilitybottleneck in software engineering post-training by introducing an environment-free verifier, Dockerless, which replaces expensive repository-specific test execution with a learned model rϕ(x,y).
As shown in the figure below, the architecture of Dockerless operates in two distinct stages to ground its judgment in repository exploration rather than surface-level patch comparison.
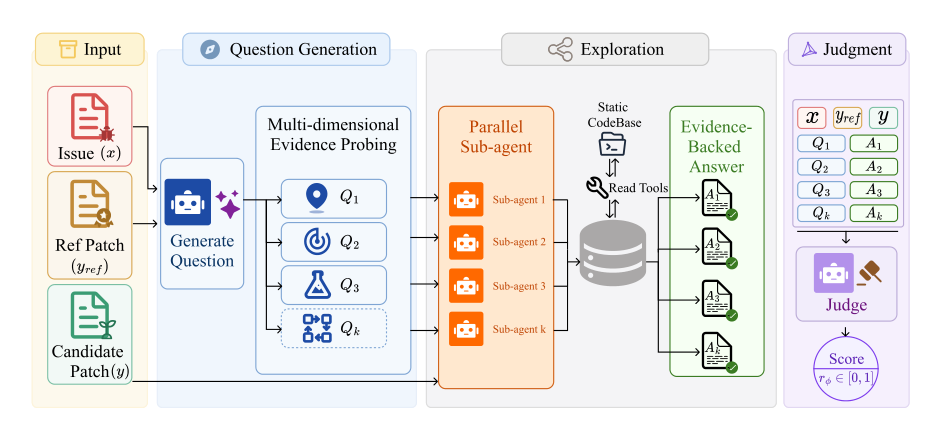
First, given an issue x and a reference patch yref, the model generates a set of K verification questions {Q1,…,QK} probing where the fix should apply, what the code should do, and potential breakages. Parallel sub-agents then explore the static codebase using read-only shell tools to return evidence-backed answers Ak. In the second stage, the model aggregates the issue, patches, and the collected (Qk,Ak) pairs to output a binary verdict token in {0,1}. At inference, the continuous correctness score is computed from the logits ℓ0 and ℓ1 of these tokens:
rϕ(x,y)=exp(ℓ0)+exp(ℓ1)exp(ℓ1)
To train this verifier, the authors employ a rejection sampling pipeline on execution-labeled candidate patches.
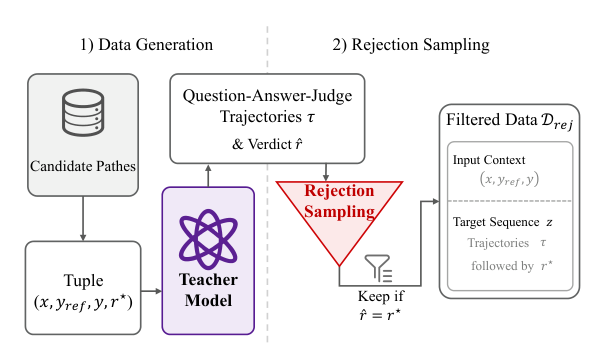
A teacher model generates full question-answer-judge trajectories τ for tuples (x,yref,y,r⋆), where r⋆ is the ground-truth verdict from held-out unit tests. The pipeline retains only those trajectories where the teacher's predicted verdict r^ matches r⋆, forming the filtered dataset Drej. To mitigate class imbalance, the negative-to-positive sample ratio is capped at ρ. The verifier is then trained end-to-end using standard next-token cross-entropy loss over the full output sequence z:
Lϕ=−EDrej[∑t=1Tlogpϕ(zt∣x,yref,y,z<t)]
Once trained, Dockerless is integrated into environment-free post-training pipelines to curate data and compute rewards without per-repository dependencies.
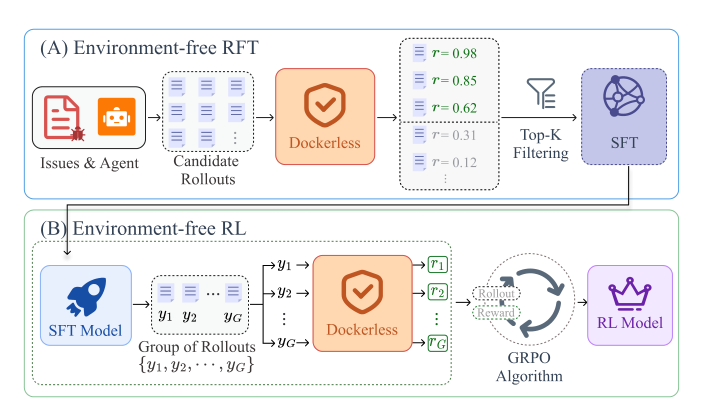
For Environment-free Rejection-sampling Fine-tuning (RFT), the authors collect a large pool of agent rollouts in a minimal Linux image. Dockerless scores the final patch of each rollout, and the top-K rollouts ranked by rϕ are selected to form DRFT for standard SFT. For Environment-free Reinforcement Learning (RL), Dockerless serves as the reward model on top of the SFT model. Rollouts are collected in the same minimal environment, and the verifier scores each final patch yi. These scores are used to compute group-normalized advantages for the GRPO objective:
Ai=σ^rrϕ(x,yi)−rˉ,rˉ=G1∑j=1Grϕ(x,yj)
where σ^r is the standard deviation of rewards within a group of G rollouts. To further stabilize the reward signal, each reward is computed by averaging M independent Dockerless evaluations of the same patch.
Experiment
The evaluation setup compares env-free SFT and RL training of Qwen3.5-9B agents on SWE-bench benchmarks against env-based counterparts and open-source specialists. Key findings demonstrate that a custom verifier (Dockerless) trained on rejection-sampled trajectories effectively filters noisy rollouts and provides rewards that nearly match real test execution, enabling fully environment-free post-training to reach top open-source performance. The verifier's agentic exploration yields strong discrimination and adds minimal latency, making scalable, env-free agent training practical.
A fully environment-free post-training pipeline delivers state-of-the-art open-source results on SWE-bench benchmarks, surpassing both the base model and a prior specialist. Environment-free SFT matches environment-based SFT, while environment-free RL approaches the performance of test-execution RL and outperforms a verifier-based reward method, all with negligible additional latency from agentic reward computation. The environment-free model Dockerless-RL-9B substantially improves over the Qwen3.5-9B base model, with the largest relative gain on the Multilingual split. Removing per-repository execution from SFT data filtering yields performance on par with environment-based SFT across all three SWE-bench splits. Environment-free RL with Dockerless rewards achieves results close to oracle test-execution RL and clearly outperforms the DeepSWE Verifier reward approach. Agentic verification adds only a small fraction of the total per-rollout time compared to agent rollout generation, making the extra cost negligible in RL training.
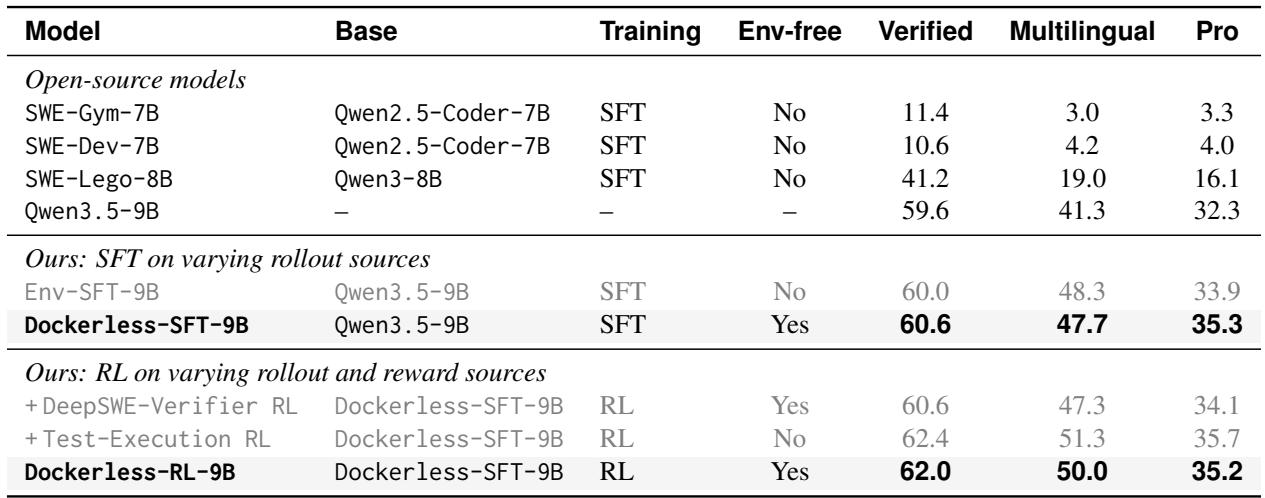
Dockerless attains the highest verifier AUC on both evaluation splits, surpassing frontier LLM judges and trained open-source verifiers. Its agentic exploration with a small number of verification questions improves patch judgment accuracy, but gains plateau or fluctuate beyond four questions, prompting the use of two to four questions at inference to balance accuracy and cost. Despite longer reward evaluation, the extra latency is a minor fraction of total RL rollout time. Dockerless achieves 81.0 AUC on the Verified split and 72.1 on the Multi-SWE-bench Flash split, outperforming all baselines. Incremental verification questions lift AUC from 78.3 at zero questions to 81.0 at four, but performance stalls or dips beyond that threshold. Reward evaluation with Dockerless adds only 7.2% to the total per-rollout wallclock time, so exploration overhead is low relative to agent rollouts.
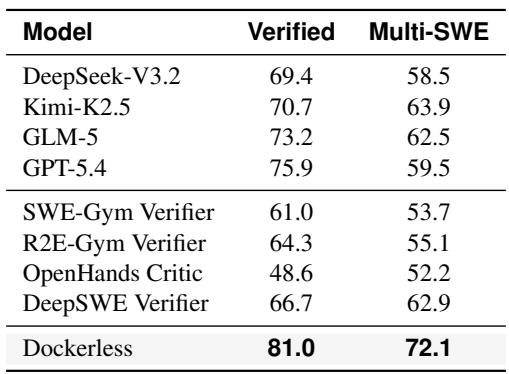
Supervised fine-tuning on all unfiltered environment-free trajectories degrades or fails to improve over the base model, indicating raw rollouts cannot be used directly. Filtering trajectories with Dockerless yields performance that matches using environment-based data, and it substantially outperforms random selection, demonstrating effective trajectory quality filtering. Using all 16K unfiltered trajectories does not improve resolve rates over the base model and even slightly decreases them on some benchmarks. Dockerless 4K outperforms Random 4K by clear margins across all benchmarks, showing that the Dockerless verifier provides a better selection signal than uniform sampling. Dockerless 4K matches Env-based 4K on all three benchmarks, indicating environment-free trajectory collection combined with strong filtering can replace per-repository environment setup.
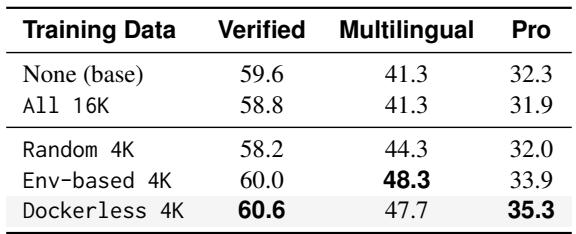
A fully environment-free post-training pipeline is evaluated on SWE-bench benchmarks, demonstrating that environment-free SFT matches environment-based SFT and environment-free RL approaches the performance of oracle test-execution RL while agentic reward computation adds only a minor fraction of total rollout wallclock time. Filtering SFT trajectories with the Dockerless verifier is essential and yields performance equal to using environment-based data, far outperforming random selection. The Dockerless verifier also achieves the highest verifier AUC, with a small number of verification questions improving patch judgment accuracy, and the overall pipeline substantially improves over the base model, especially on multilingual splits.