Command Palette
Search for a command to run...
EdgeTAM: オンデバイスTrack Anything Model
EdgeTAM: オンデバイスTrack Anything Model
概要
Segment Anything Model (SAM) を基盤として、SAM 2はメモリバンク機構により画像から動画入力へと機能を拡張し、従来手法と比較して顕著な性能を達成し、動画セグメンテーションタスクの基盤モデルとなっている。本論文では、SAM 2をより効率化し、モバイルデバイス上でも同等の性能を維持しつつ動作させることを目指す。SAMの効率化に関する既存研究はいくつか存在するが、それらは画像エンコーダの圧縮に焦点を当てており、我々のベンチマークでは新たに導入されたメモリアテンションブロックも遅延のボトルネックであることが判明したため、SAM 2には不十分である。この観察に基づき、我々はEdgeTAMを提案する。これは新規の2D Spatial Perceiverを活用して計算コストを削減する。具体的には、提案する2D Spatial Perceiverは、固定された学習可能なクエリ集合を含む軽量なTransformerを用いて、密に保存されたフレームレベルのメモリを符号化する。動画セグメンテーションが密な予測タスクであることを考慮し、メモリの空間構造を保持することが不可欠であると我々は見出し、クエリをグローバルレベルとパッチレベルのグループに分割する。また、推論時のオーバーヘッドなしに性能をさらに向上させる蒸留パイプラインも提案する。結果として、EdgeTAMは、DAVIS 2017、MOSE、SA-V val、SA-V testにおいてそれぞれ87.7、70.0、72.3、71.7のJ&Fを達成し、iPhone 15 Pro Max上で16 FPSで動作する。
One-sentence Summary
Researchers from Meta Reality Labs, Nanyang Technological University, and Shanghai AI Laboratory propose EdgeTAM, an efficient on-device Track Anything Model that adapts SAM 2 with a novel 2D Spatial Perceiver to reduce the computational cost of memory attention bottlenecks, preserves spatial structure via split global and patch-level learnable queries, and employs a distillation pipeline, achieving 87.7, 70.0, 72.3, and 71.7 J&F on DAVIS 2017, MOSE, SA-V val, and SA-V test while running at 16 FPS on an iPhone 15 Pro Max.
Key Contributions
- Latency profiling identifies the memory attention module, not the image encoder, as the primary computational bottleneck in SAM 2.
- A 2D Spatial Perceiver encodes dense frame-level memories into a compact set of learnable queries split into global and patch groups, preserving spatial structure to reduce cross-attention cost with comparable performance.
- A distillation pipeline aligns image and video segmentation features with SAM 2, improving accuracy without inference overhead; EdgeTAM attains 87.7 J&F on DAVIS 2017, 70.0 on MOSE, 72.3/71.7 on SA-V val/test, and runs at 16 FPS on an iPhone 15 Pro Max.
Introduction
The Segment Anything Model 2 (SAM 2) enables promptable video segmentation by maintaining a dense memory bank that captures frame-level features and object pointers from past frames. However, the cross-attention between current frame features and these densely encoded memories creates a computational bottleneck, making on-device inference infeasible. Prior approaches that only accelerate SAM’s image encoder fail to address this because, in SAM 2, the memory attention blocks dominate the latency even when the encoder is heavily compressed. The authors propose EdgeTAM, which tackles this bottleneck with a 2D Spatial Perceiver: a lightweight module that compresses the memory feature maps into a smaller set of tokens while preserving their 2D spatial structure. Combined with a feature-wise knowledge distillation pipeline from the original SAM 2 teacher, EdgeTAM matches or exceeds the performance of much larger models and runs at 16 FPS on a mobile device, making it the first on-device model for unified video segmentation and tracking.

Dataset
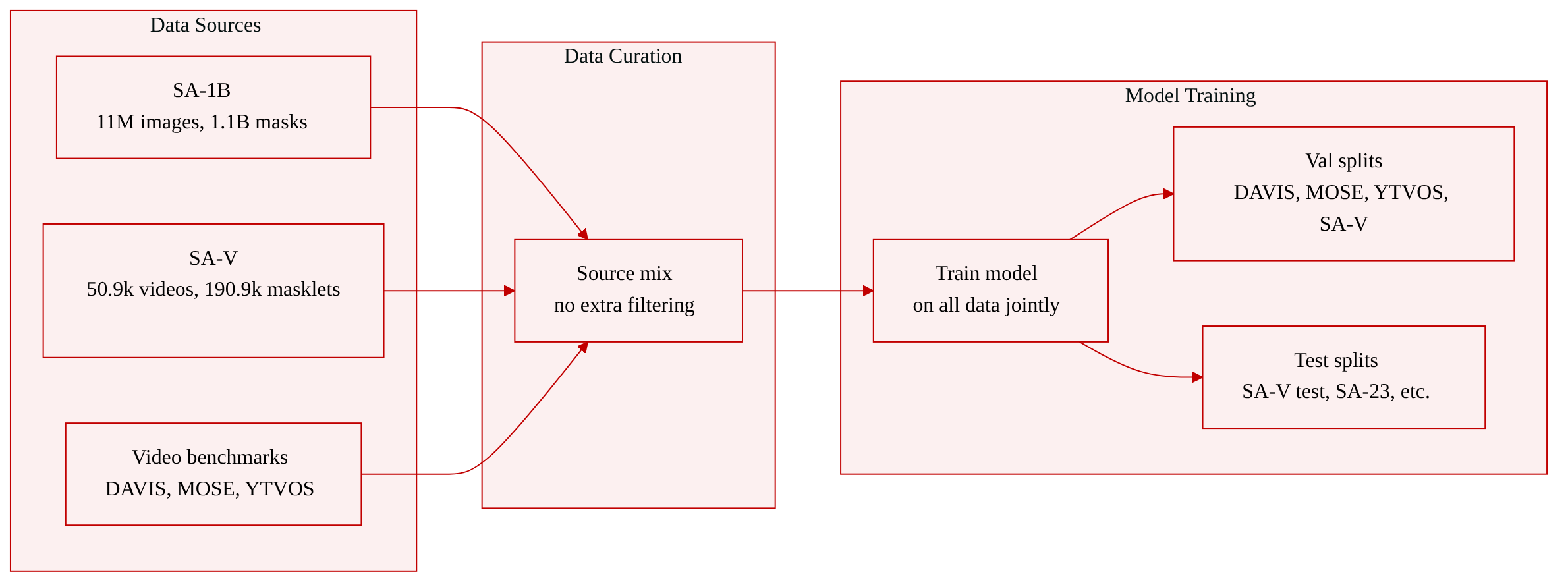
Dataset Composition and Usage
The authors construct a training collection from both image and video segmentation datasets, while evaluation is performed across multiple settings to cover promptable and semi-supervised tasks.
- Training data
- SA-1B – 11 million images annotated with 1.1 billion masks at part and object levels; average resolution 3300 × 4950 pixels. It is the largest image segmentation dataset available.
- SA-V – 50.9k videos with 190.9k masklet annotations. Videos average 14 seconds, are resampled to 24 FPS, and the annotation frame rate is 6 FPS. Scenes split 54% indoor / 46% outdoor. From these, 155/150 videos are reserved for val/test, contributing 293/278 masklets manually chosen to stress fast motion, complex occlusions, and object disappearance.
- DAVIS, MOSE, YTVOS – established video object segmentation benchmarks included in the training mix alongside SA-1B and SA-V.
No additional filtering or cropping strategy beyond the original dataset preparation is mentioned. All training subsets are used jointly to train the model; the paper does not disclose mixture ratios or custom processing steps for these datasets.
- Evaluation data
- Promptable Video Segmentation (PVS) – zero-shot evaluation across 9 datasets (online and offline modes). Metric: J&F and G.
- Segment Anything (SA) on images – evaluated on SA-23, a collection of 23 open-source datasets that cover both video frames (treated as still images) and dedicated image segmentation sets. Metric: mIoU.
- Semi-supervised Video Object Segmentation (VOS) – performance measured on the validation splits of DAVIS 2017, MOSE, YouTubeVOS, and the challenging SA-V val/test set, where ground-truth masks from the first frame are provided. Metric: J&F and G.
Method
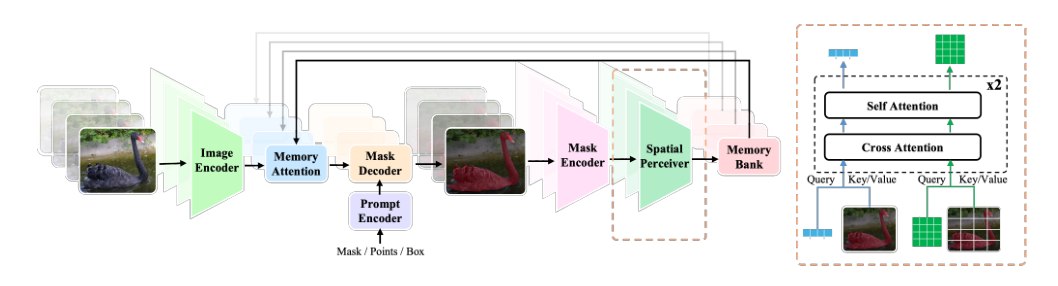
The authors basetheir proposed model on the Segment Anything Model 2 (SAM 2), which consists of four primary components: an image encoder Eimg, a mask decoder D, a memory encoder Emem, and a memory attention module A. The image encoder utilizes a hierarchical backbone (Hiera) to output feature maps at strides 4, 8, and 16:
{F4,F8,F16}=Eimg(I)
where I represents the current frame input. The feature F16 is then fused with memory features {M1,M2,…,MT} from the previous T frames using the memory attention module A, which functions as a stack of Transformer blocks. In this configuration, F16 acts as the queries, while the temporally concatenated memory features serve as the keys and values:
FM=A(F16,M1,M2,…,MT)
The mask decoder D subsequently encodes the user prompt and decodes the mask prediction O using the prompt embedding P and the image features FM,F4,F8:
O=D(FM,F4,F8,P)
Finally, F16 and O are fused and encoded by the memory encoder Emem to update the memory bank in a first-in-first-out manner:
MT+1=Emem(F16,O)
To adapt this architecture for mobile devices, the authors initially explore naive modifications, such as replacing the heavy image encoder with a compact backbone (RepViT-M1) and reducing the number of memory attention blocks from 4 to 2.
However, benchmarks reveal that memory attention remains a significant latency bottleneck. The computational complexity of memory attention is O(TCH2W2), which involves massive matrix multiplications that mobile devices handle inefficiently. Since reducing the number of memory frames T degrades temporal consistency, the authors propose summarizing the memory spatially before performing memory attention to exploit the redundancy in videos.
They first introduce a Global Perceiver, inspired by the Perceiver architecture, to compress the dense memory features Mt∈RC×H×W into a small set of vectors Gt∈RC×Ng. This is achieved using learnable latents Zg through single-head cross attention (CA) followed by self attention (SA):
Zg′=CA(Q(Zg),K(Mt+p),V(Mt+p)) Gt=SA(Zg′)
This approach reduces the complexity to O(TCHWNg). However, because the output does not maintain its spatial structure, it lacks the explicit positional information required for dense prediction tasks like video object segmentation.
To address this, the authors propose a 2D Spatial Perceiver. This module shares the same architecture but assigns spatial priors to the learnable latents Zl and restricts each latent to attend only to a local window. The memory feature map is split into non-overlapping patches:
Mt′=window-partition(Mt) Zl′=CA(Q(Zl),K(Mt′),V(Mt′)),Lt′=SA(Zl′) Lt=window_unpartition(Lt)+p′
The global and 2D spatial perceiver outputs are concatenated along the flattened dimension. This combined design reduces the overall memory attention complexity to O(TCHW(Ng+Nl)).
The training process follows a distillation pipeline divided into image segmentation pre-training (Simg) and video segmentation training (Svid) stages.
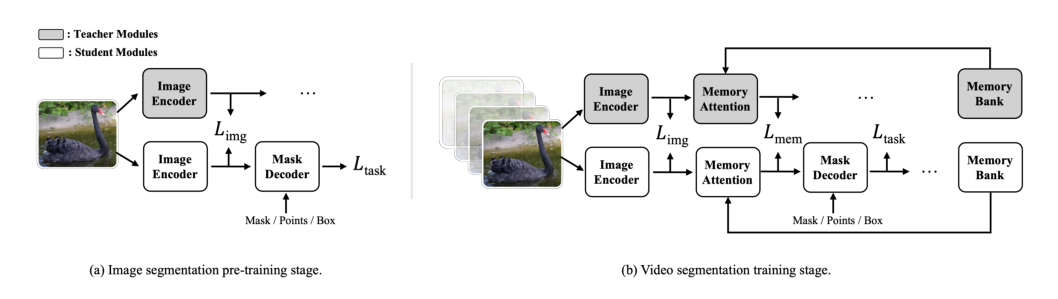
During the image pre-training stage Simg, the authors employ task-specific losses Ltask (dice loss, focal loss, and L1 loss) and align the image encoder feature maps (F16) between the teacher and student models using an MSE loss Limg. The pre-training loss is formulated as:
Lsam=Ltask(O,GT)+γ⋅Limg(F16t,F16s)
In the video training stage Svid, the task-specific losses are augmented with a BCE loss for occlusion prediction. To ensure the student's memory-related modules receive adequate supervision, an additional MSE loss Lmem is introduced to align the memory attention outputs FM from the teacher and student. The total loss becomes:
Lsam2=Ltask(O,GT)+α⋅Limg(F16t,F16s)+β⋅Lmem(FMt,FMs)
Experiment
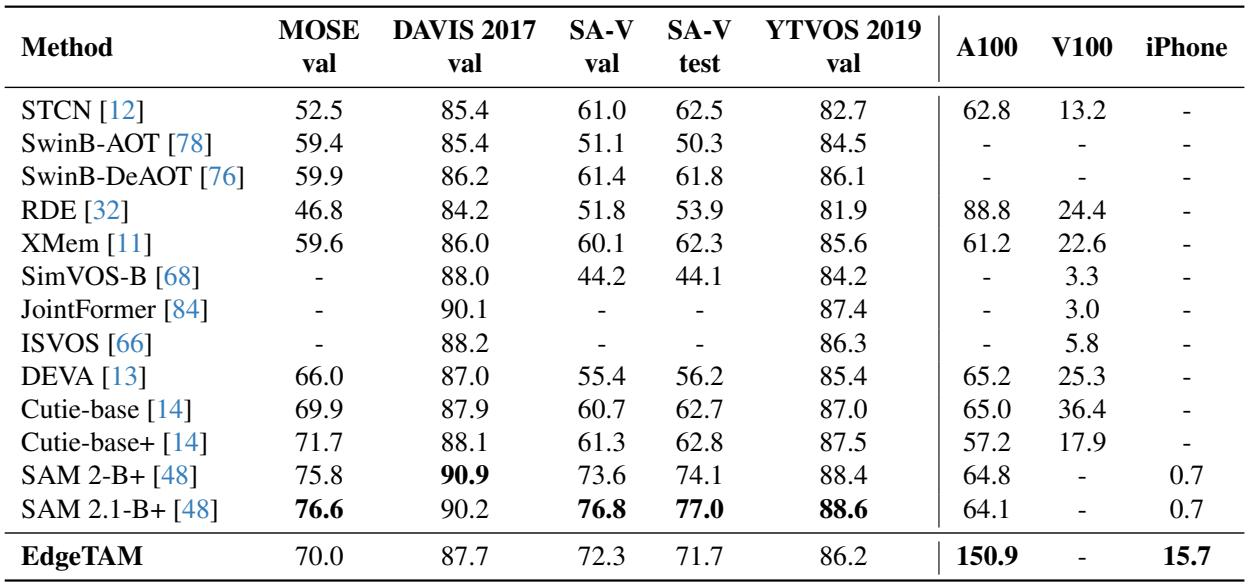
EdgeTAM is evaluated on promptable video segmentation (online/offline modes), image-based segment anything, and semi-supervised video object segmentation across diverse datasets including SA-V, DAVIS, MOSE, and YTVOS. The model demonstrates strong zero-shot performance: it surpasses prior promptable video methods, achieves comparable image segmentation accuracy to much larger SAM variants, and matches or exceeds dedicated VOS models while remaining compact and fast for on-device deployment. Ablations confirm that the 2D Spatial Perceiver, distillation, and the chosen encoder-attention configuration are crucial for this efficiency-accuracy trade-off, and qualitative analysis shows that EdgeTAM largely reproduces SAM 2 behavior but can occasionally inherit its tracking granularity failure in cases of rapid motion and occlusion.
EdgeTAM matches the zero-shot segmentation accuracy of SAM and SAM 2 while using only public data, becoming more competitive with additional clicks. With five input points it surpasses the image‑specialized SAM‑H (81.7 vs 81.3 mIoU) and delivers real‑time inference on an iPhone (40.4 FPS), enabling a single on‑device model for both image and video segmentation. EdgeTAM with five clicks attains 81.7 mIoU, outperforming SAM‑H (81.3) and matching SAM 2 trained on SA‑1B, without access to SAM 2’s internal data. On an iPhone, EdgeTAM runs at 40.4 FPS, over 30× faster than SAM 2’s 1.3 FPS, making it suitable for real‑time on‑device use.
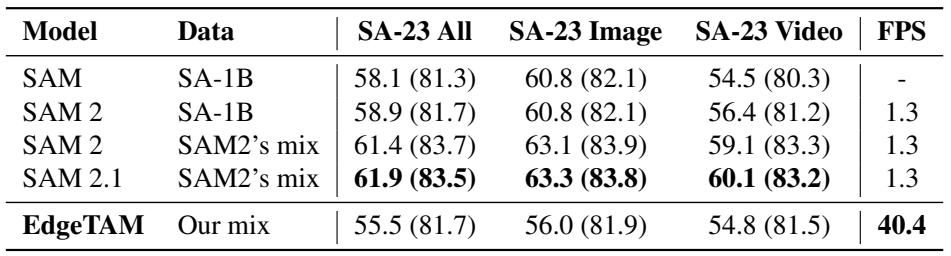
EdgeTAM, trained solely on SA-V and SA-1B, matches or exceeds prior video object segmentation models on MOSE, DAVIS, and YTVOS under a zero-shot setting, demonstrating strong generalization. On SA-V it outperforms all counterparts except SAM 2 and SAM 2.1, while its design prioritizes low latency on edge devices over high GPU throughput. Under a zero-shot setting, EdgeTAM is on par with or surpasses state-of-the-art VOS models on MOSE, DAVIS, and YTVOS that were trained on those specific datasets. On SA-V validation and test sets, EdgeTAM exceeds all compared methods except SAM 2 and SAM 2.1, and its inference speed optimization targets edge devices, where GPU streaming multiprocessor utilization remains low.
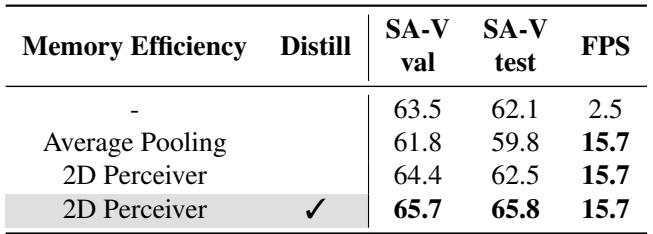
A 2D Spatial Perceiver replaces memory downsampling to accelerate inference while improving accuracy over both the baseline and average pooling. Distillation further lifts performance, and using a combination of global and 2D latents yields the best speed–accuracy trade-off. The optimal configuration uses RepViT-M1 with two memory attention blocks, and self-attention inside the 2D Perceiver enhances feature communication. The 2D Perceiver speeds up the baseline by 6.3× and outperforms average pooling on SA-V. Adding distillation to the 2D Perceiver boosts J&F by 1.3 on SA-V val and 3.3 on SA-V test. Employing both global and 2D latents achieves the highest speed-up with better performance. RepViT-M1 with two memory attention blocks offers the best trade-off among backbones and block counts. Self-attention in the 2D Perceiver improves results by letting non-overlapping local patches share information.
EdgeTAM achieves competitive zero-shot video object segmentation accuracy across prompt types, outperforming prior SAM-based memory approaches and approaching the performance of SAM 2 and SAM 2.1. With additional click prompts, the gap to SAM 2 narrows and EdgeTAM even surpasses it at five clicks, highlighting its strong ability to leverage detailed user guidance. Despite being optimized for edge devices, the model demonstrates robust generalization across diverse video datasets. With three clicks, EdgeTAM (72.7) exceeds SAM + Cutie (70.1) and SAM + XMem++ (68.4) in zero-shot segmentation, and nearly matches SAM 2 (73.2). At five clicks, EdgeTAM (75.5) slightly surpasses SAM 2 (75.4), showing that finer prompt input can offset architectural advantages of larger models.

EdgeTAM achieves competitive zero-shot segmentation accuracy across images and videos while trained solely on public data, matching SAM and SAM 2 and even surpassing SAM-H with additional click prompts. Optimized for on-device inference, it runs in real time on mobile hardware and generalizes strongly to multiple video object segmentation benchmarks. With progressive user guidance, the model can outperform larger architectures like SAM 2, demonstrating effective utilization of fine-grained input. Its design, including a 2D Spatial Perceiver and distillation, yields a favorable speed-accuracy trade-off without depending on proprietary datasets.