Command Palette
Search for a command to run...
プリミティブではなくオブジェクトとしてのシーン:未知視点画像からのインスタンス構造化3Dトークン化
プリミティブではなくオブジェクトとしてのシーン:未知視点画像からのインスタンス構造化3Dトークン化
Mijin Yoo In Cho Subin Jeon Jiwoo Lee Eunbyung Park Seon Joo Kim
概要
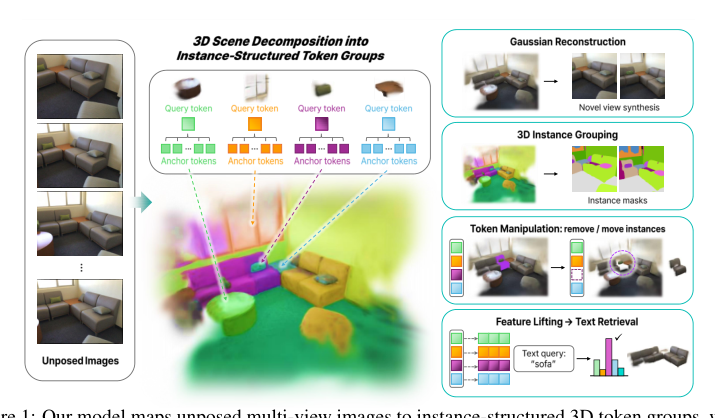
3Dシーンは、それを構成するプリミティブではなく、オブジェクトによって理解される。しかし、フィードフォワード再構成手法は、密で非構造化な点群やガウシアン集合を出力し、オブジェクトレベルの構造は事後的に復元する必要がある。我々は、未知視点の多視点画像から直接、シーンをインスタンス構造化された3Dトークン群に分解するフィードフォワードフレームワークを提案する。これは、再構成、セグメンテーション、操作がすべて可能なコンパクトなオブジェクト中心の単位である。各トークン群は、エンティティレベルの識別情報を捉えるインスタンストークンと、局所的な幾何形状や外観を符号化するアンカートークンを組み合わせ、3Dガウシアン集合にデコードされる。この2層の因子分解により、オブジェクトの識別情報と局所的外観が分離され、オブジェクトインスタンスが派生プロダクトではなく、表現のネイティブなインタフェースとなる。トークン群は、3Dアノテーションを必要とせず、再構成とセグメンテーションの同時教師を用いた微分可能レンダリングを通じて学習される。我々のフィードフォワードモデルは、新規視点合成で競争力を維持しつつ、クラス非依存のインスタンスセグメンテーションにおいてシーンごとの最適化ベースラインを上回る。さらに、同じトークン群を通じて、オブジェクトの削除、移動、挿入といったインスタンスレベルのシーン編集や、検索複雑度がプリミティブ数ではなくインスタンス数に比例する効率的なオープンボキャブラリ3Dインスタンス検索が直接可能になる。
One-sentence Summary
Proposed by researchers from Yonsei University and Seoul National University, a feed-forward framework decomposes scenes into instance-structured 3D token groups from unposed multi-view images, decoupling object identity from local appearance with two-level tokens, and trained via differentiable rendering and joint reconstruction/segmentation supervision without 3D annotations, it surpasses per-scene optimization in class-agnostic instance segmentation while enabling direct instance-level editing and efficient open-vocabulary retrieval.
Key Contributions
- The method is a feed-forward framework that directly reconstructs a 3D scene from unposed multi-view images as instance-structured token groups, where each group consists of an instance token for object-level identity and anchor tokens encoding local geometry and appearance, decoded into 3D Gaussians.
- Trained with differentiable rendering and joint reconstruction plus segmentation supervision without 3D annotations, the model surpasses per-scene optimization baselines in class-agnostic instance segmentation while staying competitive in novel view synthesis.
- The same token groups directly support instance-level scene editing (removing, translating, and inserting objects) and efficient open-vocabulary 3D instance retrieval with complexity scaling by the number of instances rather than primitives.
Introduction
For 3D scenes to support object-level reasoning, the representation must treat whole objects, not individual primitives, as first-class units. Existing feed-forward reconstruction methods produce dense, unstructured collections of Gaussians or points; even when per-primitive semantics are lifted from 2D models, object identity remains scattered and any instance-level operation relies on post-hoc grouping. The authors address this representation mismatch by reconstructing a scene as a compact set of instance-structured token groups in a single forward pass. Each group couples an instance token that captures object identity with anchor tokens that encode local geometry, yielding a representation where objects are explicit, manipulable interfaces for both reconstruction and segmentation tasks, with no 3D annotations required.
Method
The authors present instance-structuredtoken groups, a feed-forward 3D scene representation constructed from unposed multi-view images. Each group pairs an instance token capturing entity-level identity with anchor tokens that encode local geometry and appearance, which are subsequently decoded into a set of 3D Gaussians.
Refer to the framework diagram:
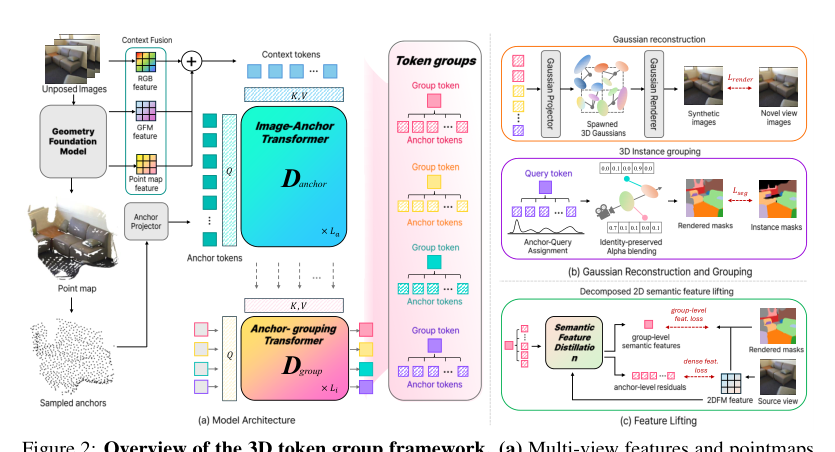
As shown in the figure below, the model architecture begins with a frozen geometry foundation model that extracts multi-view features and pointmaps from the input images. These are fused into context tokens. An image-anchor transformer cross-attends to these context tokens to produce anchor tokens, and an anchor-grouping transformer cross-attends to the anchor tokens to produce group tokens. These group tokens compete for anchor ownership via softmax assignment.
Multi-view Feature Encoding and Token Initialization Given V unposed RGB images, the frozen 3D foundation model extracts multi-view features and pointmaps. The pointmaps are downsampled to obtain patch-aligned 3D coordinates. To provide additional appearance and geometry cues, the RGB images and pointmaps are linearly patchified and added to the foundation model features. The resulting features are flattened to serve as multi-view context for the token group decoder.
Anchor tokens are initialized from the patch-aligned 3D coordinates and their corresponding context features. The authors apply farthest point sampling over all patch coordinates to select K anchor positions. The k-th anchor token at position ak is initialized as: Ak(0)=xak+ϕpos(ak) where xak is the context feature at the patch selected as anchor position ak, and ϕpos is a 2-layer MLP projecting the 3D coordinate to the feature dimension. L group tokens are initialized as learnable embeddings.
Token Group Decoding and Gaussian Reconstruction The token group decoder consists of two cross-attention transformers: an image-anchor decoder and an anchor-group decoder. The image-anchor decoder grounds the anchor tokens in the multi-view context by cross-attending to the context features. The anchor-group decoder then updates the group tokens by cross-attending to the decoded anchors, allowing each group token to aggregate object-level information: A=Danchor(A(0),X),G=Dgroup(G(0),A) where D(Q,Z) denotes a cross-attention transformer that updates queries Q using context Z.
Each decoded anchor's assignment probability over the L groups is computed by a softmax over dot-product similarities with the group tokens: πk,ℓ=softmax({⟨Ak,Gℓ′⟩}ℓ′=1L)ℓ This softmax induces competition among group tokens for anchor ownership. Each decoded anchor is then mapped to Ng 3D Gaussians by a 2-layer MLP that predicts Gaussian attributes, including position offsets, scale, rotation, opacity, and spherical harmonics. Each generated Gaussian inherits the assignment score of its parent anchor.
Training via Joint Reconstruction and Grouping Supervision The decoders are trained entirely through 2D supervision. The predicted Gaussians are rendered at target viewpoints and supervised against the ground-truth images with a combined MSE and perceptual loss: Lrender=Lmse+λlpipsLlpips To supervise grouping, the authors cast anchor-to-group assignment as a 2D instance segmentation problem. Each Gaussian inherits the assignment probability of its parent anchor; rendering these probabilities through alpha compositing produces instance probability maps. Following standard 2D segmentation pipelines, Hungarian matching is performed between the predicted and ground-truth masks. For each matched pair, a per-pixel binary cross-entropy loss and a Dice loss are applied: Lseg=λbceLbce+λdiceLdice The full training loss combines both objectives, with a linear warm-up applied to the segmentation loss weight during the initial training steps to ensure grouping supervision takes full effect once initial geometry has emerged.
Decomposed Semantic Feature Distillation The instance structure provides a natural basis for integrating semantics. Rather than attaching a high-dimensional feature vector independently to every Gaussian, the token groups enable a decomposed representation. A shared group-level embedding captures the dominant semantics of each instance, while a low-dimensional anchor-level residual accounts for spatially varying detail within the group.
Given per-view 2D foundation features, the trained image-anchor cross-attention is reused to aggregate them into anchor semantic tokens. Group-level semantic tokens are produced by an additional anchor-to-group cross-attention transformer. At rendering time, each anchor is hard-assigned to its highest-probability group, and the tuple of the one-hot assignment and the anchor-level residual is attached to every Gaussian spawned from that anchor. The full per-pixel semantic feature is reconstructed as: Fv(u)=∑ℓS^v,ℓ(u)sℓ+WrR^v(u) where Wr projects the residual back to the foundation feature dimension. The authors optimize two complementary losses: a pixel-level cosine similarity loss driving the full reconstructed feature to match the foundation model output, and a group-level alignment loss directly supervising each group embedding to capture an object-level semantic summary. This enforces a clean division of roles between the group and anchor levels.
Experiment
The tokenization framework is evaluated on ScanNet for reconstruction, feature lifting, and instance segmentation, then applied to instance-level editing and open-vocabulary retrieval. The token group representation yields superior open-vocabulary feature lifting and fully feed-forward instance segmentation that surpasses per-scene optimization methods, while the gap in raw reconstruction quality shrinks under zero-shot transfer, indicating a more transferable scene prior. Ablations demonstrate that joint training with a segmentation loss warm-up is essential for stable emergence of coherent groups, and the decomposition into group-level semantics and anchor-level residuals effectively captures both instance identity and sub-instance detail. The resulting representation supports natural entity-level operations and retrieval directly from a single forward pass, without requiring masks or per-scene optimization.
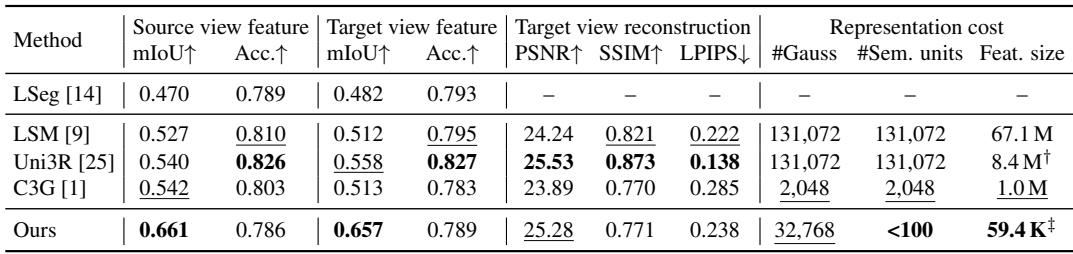
The proposed model achieves the highest feature-lifting mIoU on both source and target views by a clear margin, while using drastically fewer stored feature scalars. Semantic storage drops from 8.4M or 67.1M in other methods to just 59.4K, because instance-level token groups concentrate semantics instead of distributing them across individual Gaussians. Reconstruction quality is competitive, reaching the second-best PSNR with a fraction of the Gaussian primitives. The model attains a source-view mIoU of 0.661 and target-view mIoU of 0.657, outperforming the next best (0.542 and 0.558) with under 100 semantic units. Stored feature scalars are reduced to 59.4K, compared to 8.4M for Uni3R and 67.1M for LSM, while reconstruction PSNR (25.28) remains close to Uni3R's 25.53 despite using only 32,768 Gaussians.
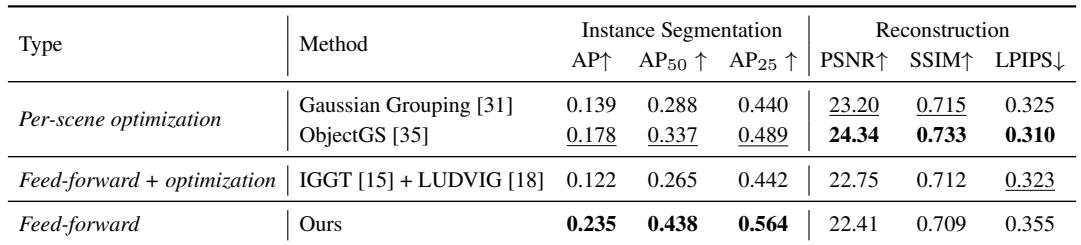
With 8 context views, the feed-forward token-based model achieves the best instance segmentation across all AP metrics, surpassing both per-scene optimization baselines and a feed-forward method with post-hoc optimization. Reconstruction quality remains competitive despite using a compact, token-based representation, while the instance segmentations are notably cleaner and more coherent. The model attains the highest instance segmentation scores, outperforming per-scene optimized Gaussian Grouping and ObjectGS as well as the IGGT+LUDVIG feed-forward+optimization pipeline. Reconstruction metrics are close to the top per-scene optimizer, even though the method does not perform per-scene optimization and relies on a compact token-based representation. The fully feed-forward approach, trained only with 2D supervision, surpasses methods that require per-scene grouping or optimization, indicating that native instance structure is a stronger inductive bias than post-hoc clustering.
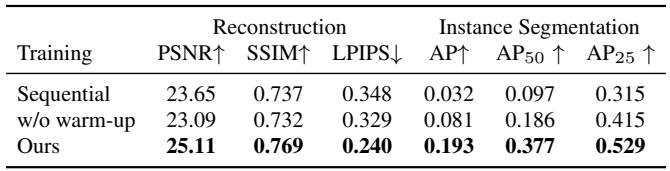
Joint training of reconstruction and segmentation achieves the strongest results (PSNR 25.11, AP 0.193). Training reconstruction first and then freezing it for segmentation collapses AP to 0.032 and degrades reconstruction metrics. Omitting the segmentation loss warm-up reduces reconstruction PSNR to 23.09 while partially recovering segmentation AP to 0.081, but both variants fall well below the joint scheme. Sequential training causes instance segmentation AP to plummet from 0.193 to 0.032, indicating reconstruction alone fails to induce the necessary grouping structure. Without warm-up, reconstruction PSNR drops to 23.09 and segmentation AP reaches only 0.081, showing that early stabilization of geometry benefits both objectives.
Ablations on feature lifting show that relying exclusively on anchor residuals produces the weakest results, while using only the shared group-level feature already achieves strong performance. Adding anchor residuals to the group embedding yields the best accuracy, confirming a division of labor where the group feature carries instance-level semantics and the anchor residuals capture fine-grained sub-instance variation. The group-only variant substantially outperforms the anchor-only variant, indicating that the shared group embedding is the primary semantic carrier. The full decomposition (group + anchor) reaches the highest mIoU and accuracy, as anchor residuals provide local detail that the group feature alone cannot represent. Anchor residuals alone perform worst, because low-dimensional features lack the capacity to represent full semantic content without the shared group embedding.
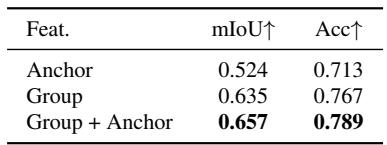
The proposed model compresses semantic storage drastically by concentrating semantics into instance-level token groups, achieving the highest feature-lifting mIoU with a fraction of the stored features. With multiple context views, the feed-forward token-based model outperforms per-scene optimization and post-hoc methods on instance segmentation, showing that native grouping is a stronger inductive bias. Joint training of reconstruction and segmentation is essential, as sequential training collapses segmentation and degrades reconstruction quality. Ablations reveal that a shared group embedding carries the primary semantic signal while anchor residuals contribute fine details, and using both achieves the best performance.