Command Palette
Search for a command to run...
ストリーミング動画理解のためのシンプルなベースライン
ストリーミング動画理解のためのシンプルなベースライン
Yujiao Shen Shulin Tian Jingkang Yang Ziwei Liu
概要
近年のストリーミング動画理解手法は、長尺の動画ストリームを処理するために、複雑な記憶メカニズムへの依存度を高めています。しかし、本研究では、単一の知見をもってこの傾向に挑戦します。すなわち、最新の商品化済みVLM(Vision-Language Model)に対して、直近の N フレームのみを入力するスライディングウィンドウ方式のベースラインが、すでに既存のストリーミングモデルと同等かそれ以上の性能を発揮するという事実です。本研究ではこのベースラインを「SimpleStream」として定式化し、OVO-Bench および StreamingBench において、13 の主要なオフラインおよびオンライン動画 LLM ベースラインと比較評価を行いました。その単純さにもかかわらず、SimpleStream は一貫して高い性能を達成しました。直近の 4 フレームのみを使用する設定においても、OVO-Bench では平均精度 67.7%、StreamingBench では 80.59% を記録しています。統制されたアブレーション研究により、より長いコンテキストの有用性はバックボーンに依存するものであり、モデルのスケールとともに一様に増加するわけではないことが示されました。さらに、一貫した「知覚と記憶のトレードオフ」が明らかになりました。すなわち、より多くの歴史的コンテキストを追加することでリコールは向上しますが、リアルタイム知覚能力がしばしば低下するという現象です。このことは、同一のプロトコル下で SimpleStream を明確に上回る性能を示さない限り、より強力な記憶、検索、または圧縮モジュールの導入を「進歩」として扱うべきではないことを示唆しています。したがって、本研究では、将来のストリーミングベンチマークにおいて、直近のシーン知覚と長距離記憶を分離し、複雑化に伴う性能向上をより明確に評価できるようにすべきであると主張します。
One-sentence Summary
Researchers from Nanyang Technological University introduce SIMPLESTREAM, a minimal baseline that feeds only recent frames to off-the-shelf VLMs, outperforming complex memory-centric models on OVO-Bench and StreamingBench while revealing a critical perception-memory trade-off.
Key Contributions
- The paper introduces SIMPLESTREAM, a minimal streaming baseline that processes only the most recent N frames with an off-the-shelf VLM, eliminating the need for complex memory banks, retrieval systems, or compression modules.
- Comprehensive evaluations on OVO-Bench and StreamingBench demonstrate that this simple recent-context approach achieves state-of-the-art performance while maintaining lower peak GPU memory usage and competitive latency compared to prior streaming methods.
- Controlled ablation studies reveal that the benefit of longer context is backbone-dependent rather than uniform across model scales, and that adding historical context often improves memory recall at the expense of real-time perception.
Introduction
Streaming video understanding is critical for real-time applications where models must process continuous video feeds under strict causal and memory constraints. Prior research has increasingly relied on complex memory mechanisms, such as external banks, retrieval systems, or compression modules, based on the assumption that managing long-term history requires elaborate architectural designs. However, these sophisticated approaches often yield modest gains while introducing significant computational overhead and a trade-off where enhanced memory recall can degrade real-time scene perception. The authors introduce SIMPLESTREAM, a minimal baseline that feeds only the most recent N frames directly to an off-the-shelf VLM without additional memory or training. They demonstrate that this simple recency-based approach matches or surpasses complex streaming models on major benchmarks like OVO-Bench and StreamingBench, revealing that longer context benefits are backbone-dependent rather than universal and arguing for a new evaluation standard that separates perception from memory performance.
Method
The authors introduce SimpleStream as a deliberately simple baseline designed to isolate the capabilities of current off-the-shelf Vision Language Models (VLMs) using only recent visual context. Unlike prior streaming systems that incorporate mechanisms for managing long-range history, SimpleStream relies on a sliding window approach. Refer to the framework diagram below, which illustrates how the system processes a continuous video stream by selecting a "Recent N-frames window" centered around the current frame to feed into the Vision Language Model.
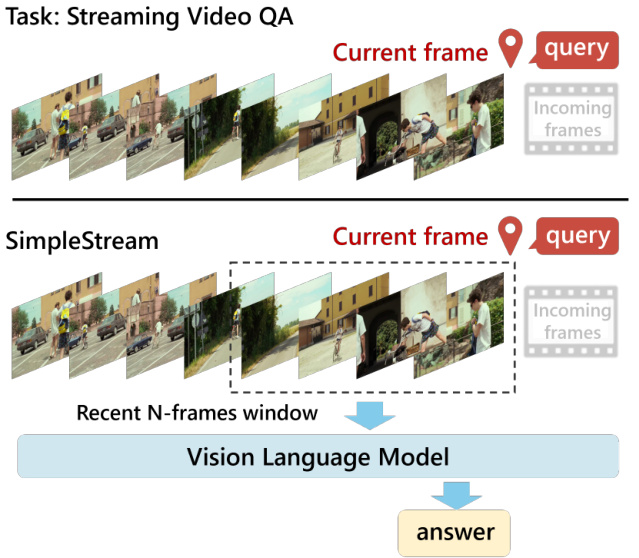
Let the video stream be represented as a sequence of frames where fi denotes the visual frame at time step i. Given a question qt at time t, the method feeds the base VLM only the most recent N frames and the text query. This process is formalized as:
SIMPLESTREAM(t)=VLM({ft−N+1,…,ft},qt)
By construction, SimpleStream omits additional memory mechanisms, meaning frames outside the sliding window are discarded. Consequently, per-query memory and computation remain bounded by N and do not grow with the stream length. The method introduces no architectural modification, memory module, or additional training; it functions strictly as an inference-time input policy applied to an off-the-shelf VLM.
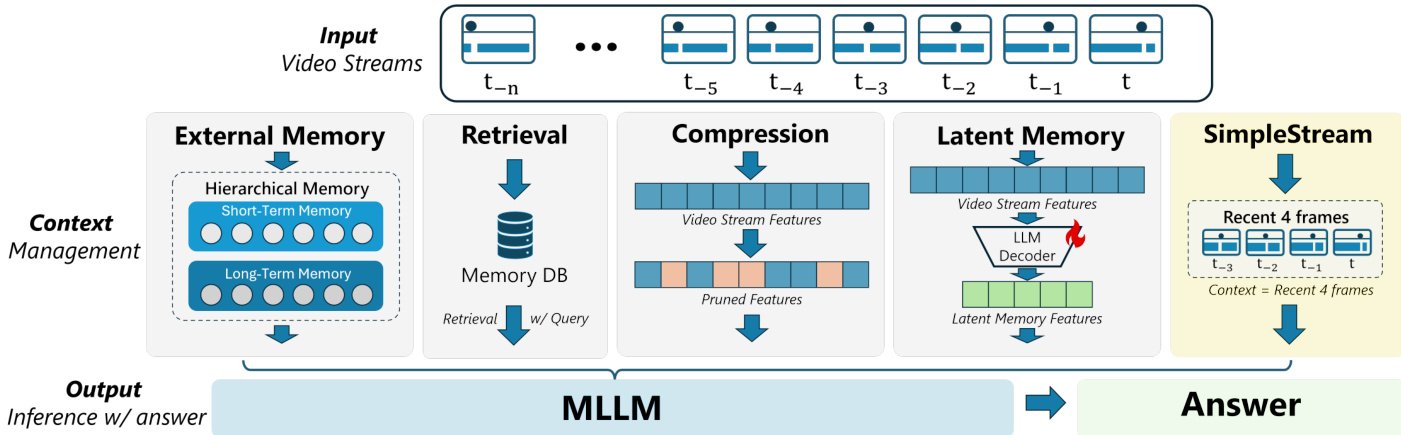
The architectural comparison below highlights how SimpleStream differs from other context management strategies. While alternative approaches utilize External Memory, Retrieval, Compression, or Latent Memory to handle long-term dependencies, SimpleStream bypasses these components entirely. It serves as a controlled reference baseline to determine how much streaming performance can be obtained from recent visual context alone while minimizing confounding effects from additional training or system-level engineering.
Experiment
- Experiments on OVO-Bench and StreamingBench validate that SIMPLESTREAM, a minimalist approach using only a fixed recent frame window, outperforms complex streaming systems with dedicated memory banks or retrieval modules, particularly in real-time visual perception tasks.
- Ablation studies on recency window size and model scale demonstrate that performance does not improve monotonically with longer context; while modest window expansions help, further increases often yield diminishing returns or degradation, indicating that more historical context is not universally beneficial.
- Visual-RAG analysis reveals a distinct perception-memory trade-off where retrieving historical chunks improves episodic memory recall but consistently degrades real-time perception, suggesting that current memory injection techniques often corrupt the model's understanding of the present scene.
- Efficiency evaluations confirm that SIMPLESTREAM maintains low latency and stable GPU memory usage regardless of stream length, proving that persistent historical state is not required for competitive streaming inference.
- Overall conclusions indicate that current benchmarks heavily favor recent perception capabilities, and future progress requires methods that can leverage historical evidence without sacrificing the clarity of current-scene understanding.