Command Palette
Search for a command to run...
WAXAL:大規模多言語アフリカ言語音声コーパス
WAXAL:大規模多言語アフリカ言語音声コーパス
概要
音声技術の進展は主に高資源言語を優遇しており、サハラ以南アフリカの大部分の言語を話す話者にとって大きなデジタル格差を生み出している。この格差に対処するため、24 の言語(総話者数は 1 億人以上)を対象とした大規模で公開アクセス可能な音声データセット「WAXAL」を提案する。本データセットは主に 2 つのコンポーネントで構成される。1 つは多様な話者から収集された約 1,250 時間の転記済み自然音声を含む自動音声認識(ASR)用データセットであり、もう 1 つは音韻的にバランスの取れたテキストを読み上げる高品質な単一話者録音を含む 235 時間以上の音声合成(TTS)用データセットである。本稿では、4 つのアフリカの学術機関および地域団体との連携を通じて実施されたデータ収集、アノテーション、品質管理の方法論を詳述する。また、データセットの詳細な統計的概要を提示するとともに、その潜在的な限界と倫理的課題について議論する。WAXAL データセットは、研究の促進、包摂的技術の開発の実現、ならびにこれらの言語のデジタル保存における重要な資源としての役割を果たすことを目的として、包括的な CC-BY-4.0 ライセンスの下で https://huggingface.co/datasets/google/WaxalNLP より公開されている。
One-sentence Summary
To address the significant digital divide for Sub-Saharan African languages, WAXAL provides a large-scale, openly accessible speech corpus of 24 languages representing over 100 million speakers, consisting of approximately 1,250 hours of transcribed natural speech for Automated Speech Recognition and over 235 hours of high-quality single-speaker recordings reading phonetically balanced scripts for Text-to-Speech, developed in partnership with four African academic and community organizations and released under a CC-BY-4.0 license to catalyze research, enable inclusive technology development, and support digital preservation.
Key Contributions
- We introduce WAXAL, a large-scale speech dataset for 24 Sub-Saharan African languages representing over 100 million speakers. The collection comprises an Automated Speech Recognition (ASR) dataset with approximately 1,250 hours of transcribed natural speech and a Text-to-Speech (TTS) dataset with over 235 hours of high-quality recordings.
- We detail a methodology for data collection, annotation, and quality control established through partnerships with four African academic and community organizations. This process supports the inclusion of diverse speakers and maintains quality control standards for the resulting speech resources.
- The datasets are released at https://huggingface.co/datasets/google/WaxalNLP under a permissive CC-BY-4.0 license to catalyze research and enable the development of inclusive technologies. We provide a detailed statistical overview of the dataset and discuss its potential limitations and ethical considerations.
Introduction
Automatic speech recognition systems often lack sufficient training data for African languages, which limits technological accessibility and inclusivity in these regions. Existing datasets frequently do not offer the scale or multilingual diversity required for robust model performance across the continent. The authors introduce WAXAL, a large-scale multilingual African language speech corpus designed to address this resource gap. They also emphasize that releasing any large-scale human data requires careful consideration of its limitations and ethical implications.
Dataset
-
Dataset Composition and Sources
- The authors present WAXAL, a large-scale speech dataset covering 24 Sub-Saharan African languages spoken by over 100 million people.
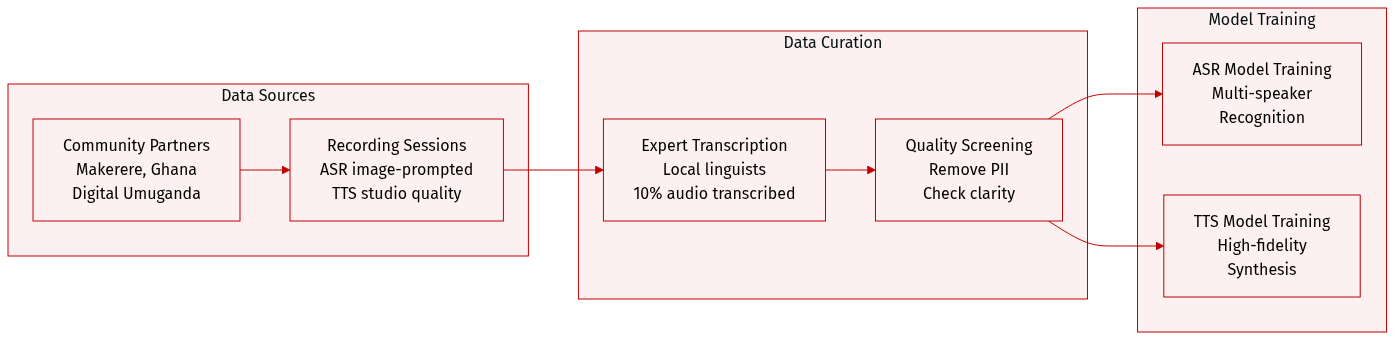
- Collection efforts were conducted in partnership with four African academic and community organizations, such as Makerere University and the University of Ghana.
- The entire collection is released under a CC-BY-4.0 license to encourage academic and commercial research.
-
Key Details for Each Subset
- ASR Subset: Includes approximately 1,250 hours of transcribed natural speech across 14 languages. Recordings were image-prompted to capture spontaneous speech with a minimum duration of 15 seconds.
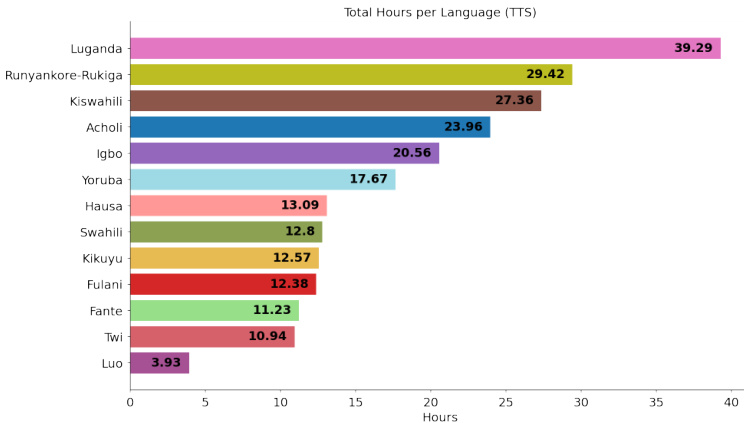
- TTS Subset: Comprises over 180 hours of studio-quality recordings from 72 voice actors across 10 languages. Speakers read phonetically balanced scripts in professional environments.
- File Statistics: The released ASR data occupies 1.7 TB, while the TTS data totals 99 GB.
-
Data Usage and Processing
- Intended Use: The ASR data is suitable for training and evaluating multi-speaker recognition models, whereas the TTS data is designed for high-fidelity voice synthesis.
- Annotation Strategy: Transcriptions were created by local linguistic experts using local scripts or English transliteration. Only 10% of the total collected audio was transcribed for the release.
- Metadata Construction: The dataset includes speaker demographics such as age, gender, and recording environment (e.g., indoor, outdoor).
- Quality Control: The authors removed personally identifiable information and screened audio for clarity, language accuracy, and appropriate content.