Command Palette
Search for a command to run...
LIBERO-Para: VLAモデルにおける言い換えに対する堅牢性を評価するための診断用benchmarkおよび評価指標
LIBERO-Para: VLAモデルにおける言い換えに対する堅牢性を評価するための診断用benchmarkおよび評価指標
Chanyoung Kim Minwoo Kim Minseok Kang Hyunwoo Kim Dahuin Jung
概要
Vision-Language-Action (VLA) モデルは、学習済みの vision-language バックボーンを活用することで、ロボット操作において高い性能を実現しています。しかし、下流のロボット設定においては、通常限られたデータで fine-tuning が行われるため、特定の指示形式(instruction formulations)に対して過学習(overfitting)が起こりやすく、言い換えられた(paraphrased)指示に対する堅牢性(robustness)については十分に検討されていません。このギャップを調査するために、本研究では、言語的な汎化性能をきめ細かく分析するため、動作の表現(action expressions)と対象物への言及(object references)を独立して変化させる制御された benchmark である「LIBERO-Para」を導入します。7つの VLA 設定(0.6B-7.5B)において、言い換えが行われると、一貫して 22-52 pp の性能低下が観察されました。この性能低下は、主にオブジェクトレベルの語彙の変化によって引き起こされています。たとえ単純な類義語の置換であっても大幅な性能低下を招いており、これはモデルが意味的な grounding(semantic grounding)ではなく、表面的な一致(surface-level matching)に依存していることを示唆しています。さらに、失敗の 80-96% は、実行エラー(execution errors)ではなく、計画レベルの軌跡の乖離(planning-level trajectory divergence)に起因しており、言い換えがタスクの特定(task identification)を妨げていることが示されました。また、従来の二値の成功率(Binary success rate)では、すべての言い換えを等しく扱ってしまうため、モデルが異なる難易度間で一貫した性能を発揮しているのか、あるいは容易なケースに依存しているのかが不明瞭になります。これに対処するため、我々は意味的および構文的要因を用いて言い換えの難易度を定量化する指標「PRIDE」を提案します。本 benchmark および対応するコードは、以下の URL で公開しています:https://github.com/cau-hai-lab/LIBERO-Para
One-sentence Summary
Researchers from Soongsil University and Chung-Ang University introduce LIBERO-Para, a diagnostic benchmark and the PRIDE metric designed to evaluate paraphrase robustness in Vision-Language-Action models by isolating action and object variations to reveal that performance degradation is primarily driven by surface-level lexical matching and planning-level trajectory divergence.
Key Contributions
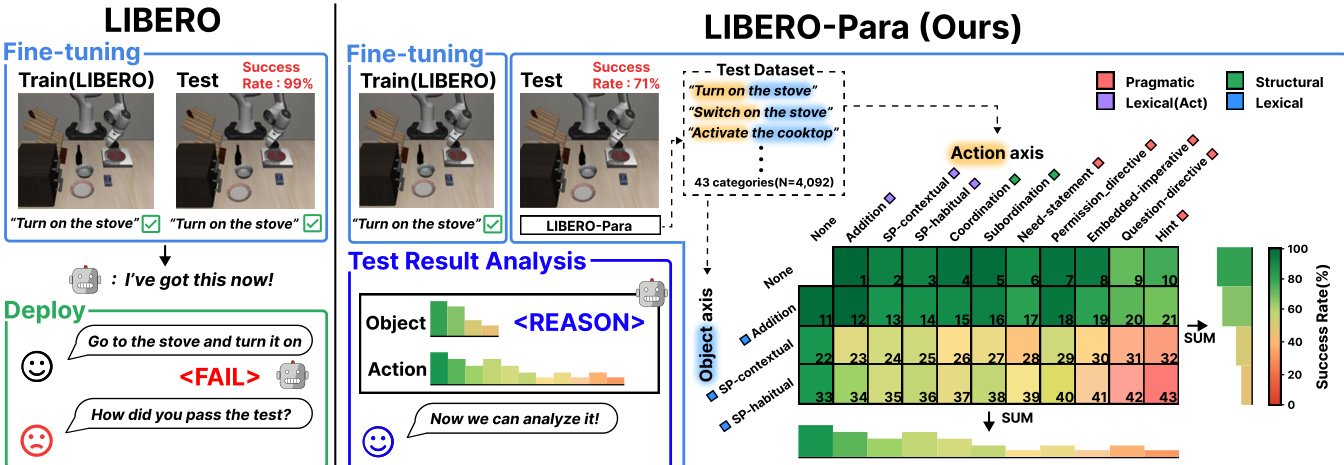
- The paper introduces LIBERO-Para, a controlled benchmark designed to isolate meaning-preserving linguistic variation from task-level semantic changes by decomposing paraphrases into 43 fine-grained types based on action verbs and object references.
- This work presents PRIDE, a specialized metric that quantifies linguistic deviation between original instructions and paraphrases by decomposing variation into keyword and structural axes to enable interpretable robustness assessment.
- Through evaluations of seven VLA configurations, the study demonstrates that paraphrase fragility is a persistent issue across scales, specifically identifying that object-level lexical variation and planning-level trajectory divergence are the primary drivers of performance degradation.
Introduction
Vision-Language-Action (VLA) models are essential for robotic manipulation, yet they often rely on data-scarce fine-tuning that causes them to overfit to specific instruction phrasings. Current benchmarks fail to adequately address this issue because they either use identical instructions during training and evaluation or conflate meaning-preserving paraphrases with task-altering semantic changes. The authors introduce LIBERO-Para, a controlled benchmark that isolates linguistic variation by independently varying action expressions and object references. To complement this, they propose PRIDE, a new metric that quantifies paraphrase difficulty through lexical and structural similarity to enable more granular robustness analysis.
Dataset

-
Dataset Composition and Sources: The authors introduce LIBERO-Para, a controlled benchmark built upon the LIBERO-Goal dataset. It is designed to evaluate the paraphrase robustness of Vision-Language-Action (VLA) models by focusing on tasks where linguistic understanding is the primary cue for task identification. The dataset is derived from 10 original instructions across four task types: Spatial, Object, Goal, and Long.
-
Key Details for Subsets: The benchmark is structured along two independent axes to allow for controlled analysis:
- Object Axis: Contains 3 lexical variation types.
- Action Axis: Contains 10 variation types, categorized into 3 lexical, 2 structural, and 5 pragmatic types.
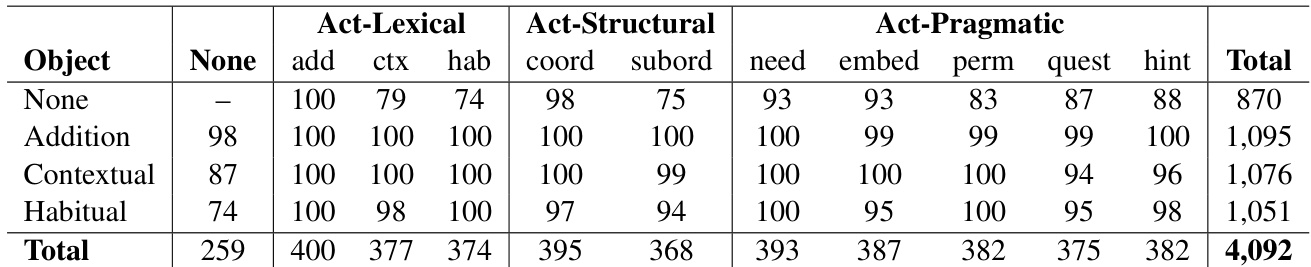
- Combinations: The two axes create 43 distinct paraphrase type combinations, including 259 Object-only variations, 870 Action-only variations, and 2,963 compositional variations. The dataset contains a total of 4,092 paraphrases, with each original instruction yielding between 386 and 423 variants.
-
Data Processing and Generation: The authors use a modular four stage workflow powered by Gemini 1.5 Pro to ensure high quality and reliability:
- Axis-wise Generation: An LLM generates paraphrases independently for the action and object axes.
- Verification: An LLM verifier filters outputs to ensure they preserve the original meaning and maintain grammatical naturalness.
- Merging: Verified action and object paraphrases are combined to create compositional instructions.
- Final Verification: A final LLM pass validates the merged instructions before they are added to the dataset.
-
Taxonomy and Filtering Rules: The paraphrase types are selected from the Extended Paraphrase Typology (EPT) and Directive Types, filtered by four strict criteria: applicability to robotic imperatives, preservation of meaning, compliance with visual/spatial constraints, and grammatical naturalness. Many categories from the original taxonomies were excluded to prevent semantic drift or ambiguity, such as morphology changes that alter object cardinality or negation switching that changes the task intent.
-
Usage in Research: The authors use the generated paraphrases exclusively for evaluation. By holding out all paraphrased instructions, they can assess how VLA models generalize to unseen linguistic variations under data-scarce fine-tuning scenarios.
Method
The authors design a framework for generating and evaluating paraphrased robotic manipulation instructions, centered on a large language model (LLM)-based pipeline that systematically introduces variation along two primary axes: action and object. The overall architecture operates in a multi-stage process, beginning with the generation of paraphrases through a LLM-based generator, followed by verification, merging, and evaluation. The framework is structured to produce a diverse set of paraphrased instructions that preserve task-critical semantics while varying in linguistic form, enabling robust testing of vision-language models under natural language variation.
The generation process starts with a prompt-based LLM, referred to as the Paraphrase Generator, which takes an original instruction and produces paraphrased versions while adhering to specific constraints. These constraints, detailed in the generator prompt, include preserving pluralization, avoiding the addition of visual attributes (such as color or size), and modifying only specified elements—object nouns for object tasks and action elements for action tasks—while maintaining the original sentence structure. The generated paraphrases are then processed through a Paraphrase Verifier, which ensures the output adheres to the required rules and maintains semantic fidelity. This verification step is crucial to filter out nonsensical or semantically divergent outputs.
Following verification, the framework employs a Paraphrase Merger to combine variations from both the action and object axes into a single, coherent paraphrased instruction. The action axis introduces three types of variation: lexical (synonym substitution, adverb insertion), structural (coordination, subordination), and pragmatic (indirect speech acts), while the object axis focuses on lexical-level modifications such as addition and same-polarity substitution. The Paraphrase Merger integrates these variations, producing a final set of paraphrased instructions that reflect the intended linguistic diversity. The resulting dataset, LIBERO-Para, is designed to test the robustness of robotic systems under paraphrased commands.
To evaluate the quality of these paraphrases, the authors introduce a two-component similarity metric: keyword similarity SK and structural similarity ST. Keyword similarity SK measures the preservation of task-critical content words—specifically, the action and object—by computing the average cosine similarity between embeddings of these words in the original and paraphrased instructions using Sentence-BERT. This focuses on semantic equivalence at the lexical level, avoiding the pitfalls of form-based metrics that may be misled by function words or syntactic rearrangements. As shown in the figure below, the computation involves matching each content word in the original instruction to its most similar counterpart in the paraphrase and averaging the cosine similarities.

Structural similarity ST complements SK by capturing syntactic differences through the tree edit distance (TED) between dependency trees of the original and paraphrased instructions. The dependency trees are constructed using part-of-speech tags and dependency relations rather than surface words, which reduces sensitivity to lexical substitutions. The TED is normalized by the combined size of the two trees to mitigate length effects, and ST is defined as 1−∣TO∣+∣TP∣TED(TO,TP). A lower value of ST indicates greater structural divergence, such as changes in word order or clause structure. The figure below illustrates the dependency trees and the computation of ST, with node colors indicating dependency relations such as root, direct object (dobj), and object of preposition (pobj).
These two similarity metrics are combined into a Paraphrase Distance (PD) score, which quantifies the overall deviation between an original instruction and its paraphrase: PD=1−(αSK(O,P)+(1−α)ST(TO,TP)), where α controls the relative weight of keyword and structural similarity. This PD score is then used to define the PRIDE score, which maps PD to a binary success signal based on whether a model succeeds or fails on the paraphrased instruction. This scoring system provides a continuous measure of paraphrase difficulty, enabling a more nuanced analysis of model robustness.
Experiment
The researchers evaluated seven Vision-Language-Action (VLA) model configurations across various architectures and scales to assess their robustness to linguistic variations in robotic instructions. Using the LIBERO-Para benchmark, which introduces compositional variations in both object references and action expressions, the study found that all models suffer significant performance degradation regardless of architecture, data scale, or fine-tuning strategy. The findings reveal that object grounding is the primary bottleneck for robustness, as models rely heavily on surface-level keyword matching rather than semantic understanding. Furthermore, trajectory analysis indicates that failures are predominantly planning-level errors where models identify the wrong task, rather than execution-level errors involving motor control.
The the the table presents a comparison of seven VLA models across different pre-training data, fine-tuning methods, and adaptation scopes. It highlights variations in training strategies, such as full fine-tuning versus expert-only adaptation, and differences in pre-training data sources and scale. Models differ in pre-training data, with some using proprietary datasets and others relying on open sources. Fine-tuning strategies vary, including full adaptation and expert-only adaptation, with distinct training scopes. The the the table includes both released models and custom-trained variants, reflecting diverse architectural and training approaches.

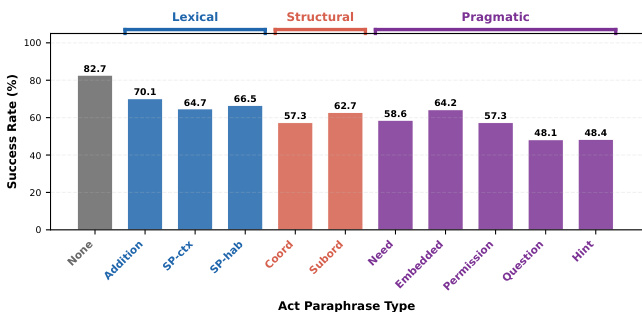
The bar chart shows success rates across different types of action paraphrases, with performance decreasing as the paraphrase type shifts from lexical to pragmatic. Models exhibit higher success rates for lexical variations compared to structural and pragmatic ones, indicating that indirect speech acts significantly reduce task success. Success rates decline as action paraphrase types become more indirect, from lexical to pragmatic. Lexical variations like 'Addition' and 'SP-cx' maintain higher success rates compared to structural and pragmatic types. Pragmatic paraphrases such as 'Question' and 'Hint' result in the lowest success rates, indicating significant performance degradation.
The the the table presents success rates across different combinations of object and action paraphrase types. Results show that object-level variations lead to significant performance drops, while action-level variations have a more moderate impact, with the most challenging cases occurring when both types of variations are combined. Object paraphrasing causes the largest performance drops compared to action paraphrasing. Success rates decline progressively as both object and action variations increase. The most challenging combinations involve indirect action types paired with object paraphrasing.
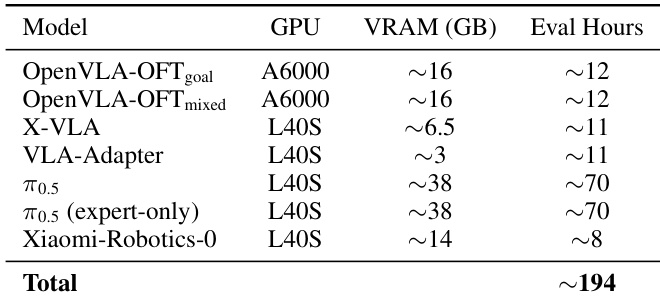
The the the table summarizes the computational resources used for evaluating seven VLA models, including GPU type, VRAM usage, and evaluation time. Results show significant variation in resource requirements across models, with some requiring high VRAM and longer evaluation times. Evaluation requires diverse GPU types and VRAM capacities across models Some models demand substantial computational resources, with up to 70 GPU hours Total evaluation cost across all models is approximately 194 GPU hours
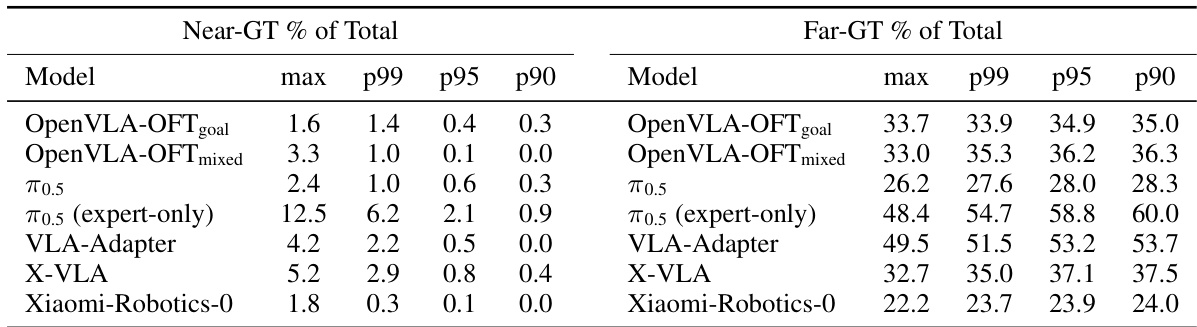
The authors classify failure modes in robotic task execution by comparing failure trajectories to successful ones using Dynamic Time Warping. Results show that the majority of failures are planning-level, where models generate incorrect trajectories from the start, rather than execution-level errors during task completion. Most failures are planning-level, indicating models fail to identify the correct task from the outset Near-GT failures, where trajectories follow the correct path but fail at execution, are rare across all models The exception is the frozen-VLM variant, which shows higher near-GT failures due to correct task identification but poor execution
This evaluation compares seven VLA models across diverse training strategies, linguistic variations, and computational requirements to assess their robustness in robotic task execution. The results demonstrate that model performance degrades significantly as instructions shift from lexical to pragmatic paraphrasing, with object-level variations posing a greater challenge than action-level changes. Furthermore, failure analysis reveals that most errors stem from planning-level inaccuracies rather than execution mistakes, highlighting a fundamental difficulty in initial task identification.