Command Palette
Search for a command to run...
RAGEN-2:Agentic RLにおけるReasoning Collapse(推論の崩壊)
RAGEN-2:Agentic RLにおけるReasoning Collapse(推論の崩壊)
概要
ご提示いただいた英文は、LLM Agentの強化学習(RL training)における新たな課題「Template Collapse(テンプレート崩壊)」とその解決策に関する非常に重要な研究成果です。ご依頼に基づき、専門用語を適切に処理しつつ、学術的・技術的に洗練された日本語に翻訳いたしました。翻訳文マルチターンLLM AgentのRL trainingは本質的に不安定であり、その推論(reasoning)の質がタスクのパフォーマンスを直接的に決定する。これまで、推論の安定性を追跡するためにEntropy(エントロピー)が広く用いられてきた。しかし、Entropyは同一入力内における多様性を測定するのみであり、推論が異なる入力に対して適切に反応しているかどうかを判断することはできない。RAGEN-2の研究において、我々は、たとえEntropyが安定していても、モデルが「一見多様に見えるが、入力に依存しない固定されたテンプレート」に依存してしまう現象を確認した。我々はこの現象を「Template Collapse(テンプレート崩壊)」と呼び、これはEntropyや既存のあらゆる指標では検知できない失敗モード(failure mode)である。この失敗を診断するために、我々は推論の質を「入力内の多様性(Entropy)」と「入力間の識別性(Mutual Information:相互情報量、以下MI)」に分解し、オンライン診断のための一連のMIプロキシ(proxy)を導入した。多様なタスクにおける検証の結果、MIはEntropyよりも最終的なパフォーマンスとの相関が極めて強く、推論の質を測る指標としてより信頼性が高いことが示された。さらに、我々はTemplate CollapseのメカニズムをSignal-to-Noise Ratio(SNR:信号対雑音比)の観点から説明する。Rewardの分散が低いと、タスクの勾配(gradient)が弱まり、正則化項(regularization terms)が支配的になることで、入力間の推論の差異が消失してしまう。これに対処するため、我々は「SNR-Aware Filtering」を提案する。これは、Rewardの分散を軽量なプロキシとして利用し、各iterationにおいて信号強度の高いpromptを選択する手法である。Planning、数学的推論、Web Navigation、およびCode Executionの各タスクにおいて、本手法は入力依存性とタスクパフォーマンスの両方を一貫して向上させることを確認した。
One-sentence Summary
By identifying template collapse as a failure mode where agentic reinforcement learning models adopt input-agnostic reasoning patterns despite stable entropy, the RAGEN-2 study proposes using mutual information proxies for diagnosis and introduces SNR-Aware Filtering to improve performance across planning, math reasoning, web navigation, and code execution tasks.
Key Contributions
- The paper introduces the concept of template collapse, a failure mode in multi-turn LLM agent training where models rely on input-agnostic reasoning templates that appear diverse but do not respond to specific inputs.
- This work presents a new diagnostic framework that decomposes reasoning quality into within-input diversity and cross-input distinguishability through a family of mutual information proxies. These proxies demonstrate a stronger correlation with final task performance than traditional entropy metrics.
- The researchers propose SNR-Aware Filtering, a method that uses reward variance as a proxy for signal strength to select high-signal prompts during training. Experiments across planning, math, web navigation, and code execution show that this approach improves both input dependence and overall task performance.
Introduction
Training multi-turn LLM agents using reinforcement learning is a critical task for developing autonomous reasoning systems, but it is inherently unstable. While researchers typically use entropy to monitor reasoning stability, entropy only measures diversity within a single input and fails to detect when a model begins to rely on fixed, input-agnostic templates. The authors identify this phenomenon as template collapse, a failure mode where reasoning appears diverse but loses its dependence on the specific input. To address this, the authors leverage a mutual information (MI) proxy to diagnose input dependence and introduce SNR-Aware Filtering, which uses reward variance to select high-signal prompts and maintain effective task gradients during training.
Dataset

-
Dataset Composition and Sources: The authors utilize a diverse testbed of seven synthetic, fully controllable environments designed to evaluate various decision-making regimes. The environments include Sokoban (grid puzzles), FrozenLake (navigation), MetaMathQA (mathematical reasoning), Countdown (arithmetic games), SearchQA (multi-turn search), WebShop (e-commerce navigation), and DeepCoder (program synthesis). DeepCoder specifically draws from PrimeIntellect, TACO, and LiveCodeBench v5.
-
Key Subset Details:
- Sokoban: Uses procedurally generated puzzles with configurable dimensions and box counts to study irreversible planning.
- FrozenLake: A navigation task featuring a 2% random transition rate to simulate stochastic dynamics and sparse rewards.
- MetaMathQA: A math QA task where correctness is determined by exact matches with ground truth.
- Countdown: A compositional arithmetic task where agents must construct expressions to reach a target number.
- SearchQA: A multi-turn environment requiring iterative web search and information synthesis.
- WebShop: An interactive e-commerce simulation with a large action space and realistic product catalogs.
- DeepCoder: A coding benchmark where agents generate Python functions to pass specific test cases.
-
Training and Usage: The authors train a Qwen2.5-3B model using the veRL/HybridFlow stack. The training process involves comparing different RL algorithms, including PPO, DAPO, GRPO, and Dr. GRPO, for up to 400 rollout-update iterations. In each iteration, the model collects 128 trajectories per environment using a prompt batch size of 8 and a group size of 16 trajectories per prompt.
-
Processing and Reward Engineering:
- Reward Shaping: The authors apply specific reward structures to guide learning, such as a diminishing reward scheme for MetaMathQA (halving the reward for each subsequent retry) and multi-tier rewards for Countdown based on format and solution correctness.
- SNR-Aware Filtering: When applying this filtering technique, the authors reduce the effective minibatch size by the keep rate and scale the per-step loss accordingly to maintain a comparable optimization step size.
Method
The authors address the challenge of template collapse in closed-loop multi-turn agent reinforcement learning, where a policy πθ generates reasoning tokens zt and executable actions at in response to observations ot, forming trajectories τ={ot,zt,at,rt}t=1T. A key insight is that standard reinforcement learning objectives, such as PPO or GRPO, apply uniform regularization (e.g., KL divergence, entropy bonus) across all inputs, which can inadvertently promote input-agnostic reasoning. This phenomenon is characterized by a low mutual information I(X;Z) between the input prompt X and the generated reasoning Z, indicating the model fails to adapt its reasoning to the specific problem. The authors formalize this problem through a signal-to-noise ratio (SNR) analysis of policy gradients, identifying low within-prompt reward variance as the primary cause of template collapse.
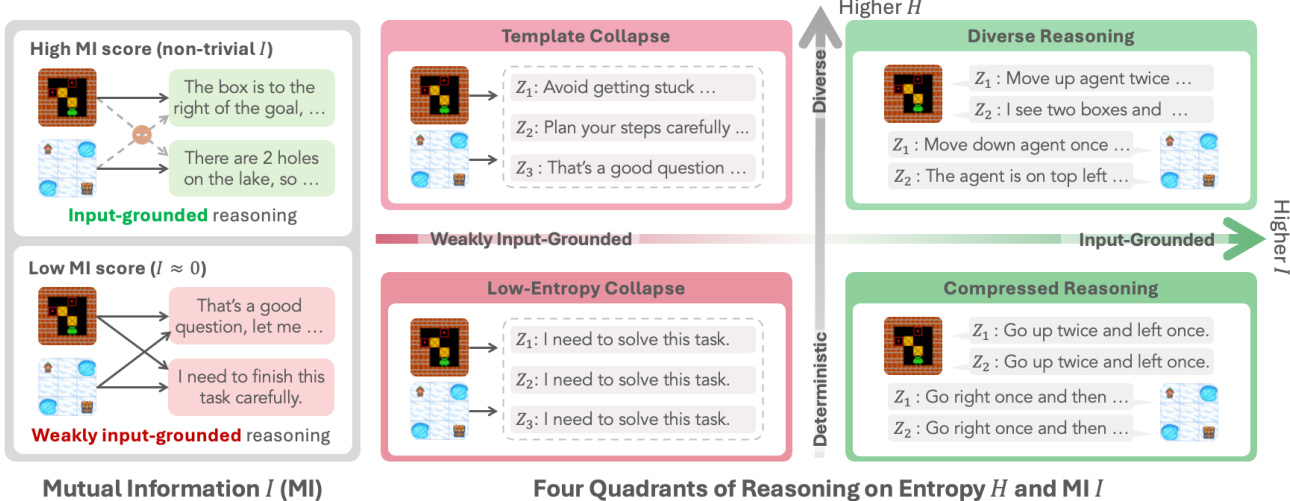
The framework for understanding reasoning regimes is established by analyzing two key dimensions: within-input diversity, measured by conditional entropy H(Z∣X), and input dependence, measured by mutual information I(X;Z). As shown in the figure above, these two axes define four distinct reasoning regimes. High H(Z∣X) and high I(X;Z) correspond to diverse and input-grounded reasoning, where the model adapts its thought process to the specific input. Conversely, low H(Z∣X) and low I(X;Z) define a "Low-Entropy Collapse" regime, characterized by deterministic, template-like responses that are weakly input-grounded. The authors argue that the standard practice of using entropy regularization to increase H(Z∣X) can be counterproductive, as it may not increase I(X;Z) and can even cause it to decrease, as formalized in Theorem M.2. The core mechanism of template collapse is a dominance of reward-agnostic regularization over task-relevant signal, which is particularly pronounced on prompts with low reward variance.
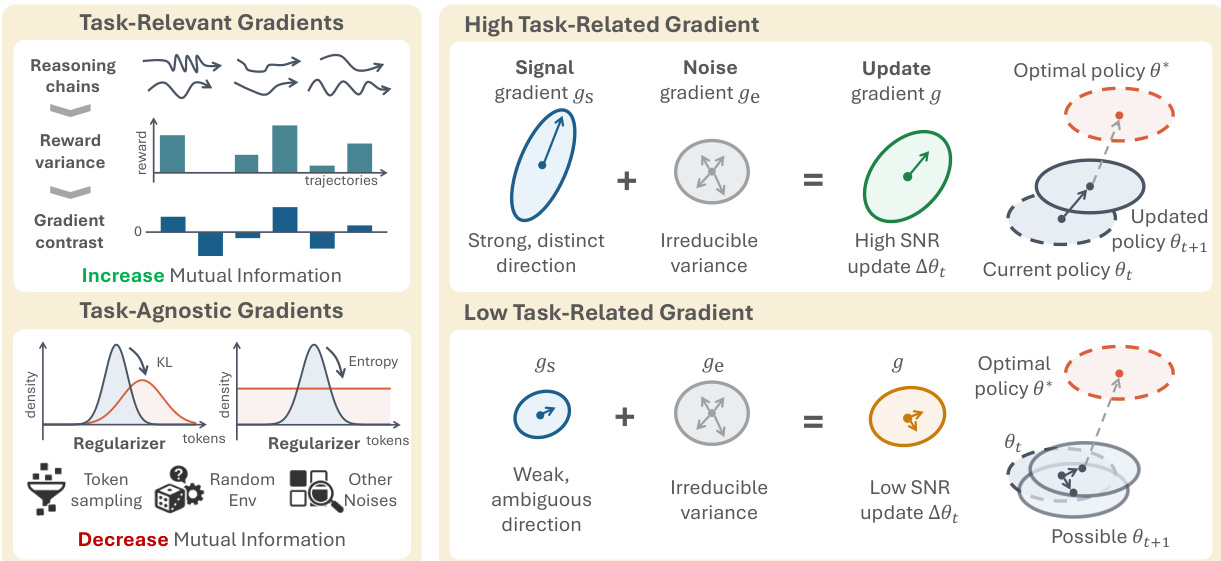
The authors provide a detailed gradient-level explanation of this phenomenon, illustrated in the figure above. In high-SNR regimes, the task gradient gtask is strong and distinct, representing a clear signal to improve the policy. This strong signal is amplified by the reward variance, as shown by the Cauchy-Schwarz inequality bound in Theorem H.2. The regularization gradient greg acts as a noise term, but its influence is outweighed by the strong task signal. In contrast, on low-RV prompts, the task gradient gtask weakens significantly, while the regularization gradient greg remains constant. This leads to a situation where the total update is dominated by the input-agnostic regularization noise, pushing the policy towards a state of low mutual information I(X;Z). This is visualized as a weak, ambiguous direction for the update gradient g, which can lead to policy drift away from the optimal policy θ∗.

To mitigate this issue, the authors propose a method called SNR-Aware Filtering. This approach directly addresses the root cause by selecting training examples based on their signal quality. The workflow, depicted in the figure above, operates in three steps. First, during sampling, the policy generates multiple trajectories for each prompt x. Second, the within-prompt reward variance RV(x) is computed for each prompt as a proxy for the task signal strength. Prompts with low variance are identified as having weak signal. Third, a filtering mechanism is applied to retain only the high-signal prompts. The authors use a top-p filtering strategy, which ranks prompts by descending reward variance and retains the smallest prefix whose cumulative variance mass reaches a fraction ρ of the total variance mass. This adaptive selection ensures that the policy update is concentrated on high-SNR prompts, effectively filtering out low-variance rollouts that would be dominated by input-agnostic regularization. This process prevents the degradation of I(X;Z) and restores input-conditioned reasoning.
Experiment
The experiments evaluate the phenomenon of template collapse in reinforcement learning agents by analyzing gradient dynamics and mutual information across various tasks, algorithms, and model scales. The results demonstrate that low reward variance causes task-discriminative gradients to be overwhelmed by input-agnostic regularization, leading to reasoning that is fluent but ignores input specifics. Implementing SNR-Aware Top-p filtering consistently improves task performance and preserves information content by prioritizing high-signal updates, proving more effective than entropy-based diagnostics or regularization alone.
The the the table outlines key characteristics of different environments used in the experiments, including their stochasticity, turn structure, state representation, and reward type. These features help categorize the tasks and inform the experimental setup. Environments vary in stochasticity, with some being stochastic and others deterministic. Multi-turn tasks involve multiple interaction steps, while single-turn tasks have a single step. State representations differ between grid-based and text-based formats, and reward types are either dense or binary.

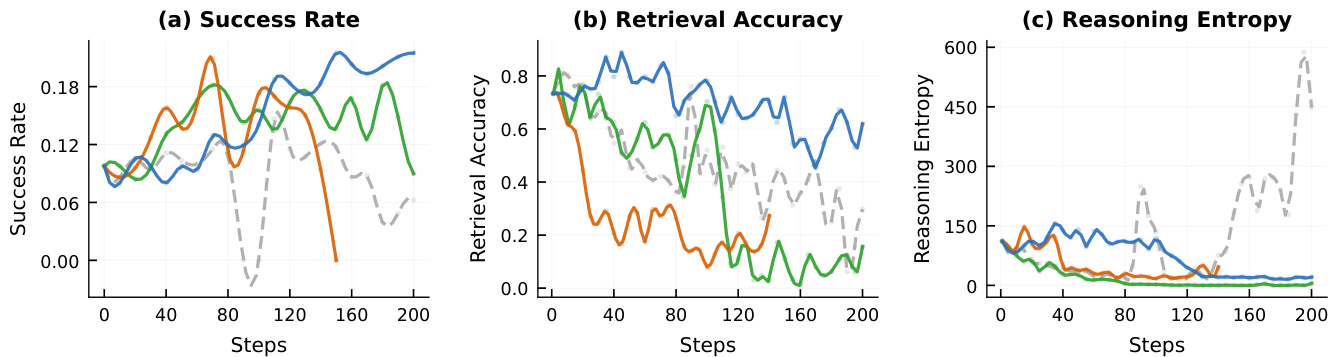
The authors compare different intervention strategies in reinforcement learning training, showing that SNR-Aware Filtering preserves task performance and reasoning diversity while preventing the decline in mutual information that occurs with no filtering. Without filtering, task success drops sharply after an initial peak, retrieval accuracy declines, and reasoning entropy increases, indicating template collapse. In contrast, filtering maintains stable retrieval accuracy and low entropy throughout training. SNR-Aware Filtering prevents the decline in task performance and retrieval accuracy seen in the no-filter baseline. Without filtering, reasoning entropy increases significantly, signaling a loss of input-specific reasoning. Filtering maintains stable mutual information and reasoning diversity, avoiding the degradation observed in unfiltered training.
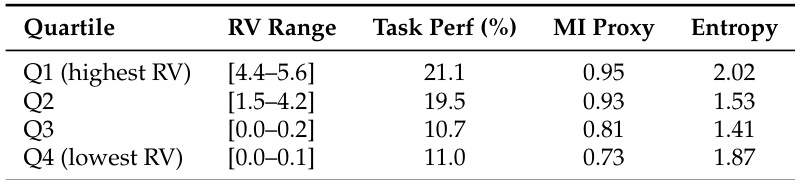
The experiment evaluates the impact of reward variance (RV) on model performance by grouping prompts into quartiles based on RV. Results show that task performance and mutual information (MI) proxy decrease monotonically as RV decreases, indicating that higher reward variance correlates with better learning outcomes. The lowest RV quartile exhibits the weakest task performance and MI, while the highest RV quartile achieves the best results. Task performance and MI proxy decline monotonically across quartiles as reward variance decreases. The highest reward variance quartile achieves the best task performance and MI proxy. The lowest reward variance quartile shows the weakest task performance and MI proxy.
The authors evaluate SNR-Aware Filtering across various RL algorithms, model scales, and input modalities. Results show that filtering consistently improves peak task success rates across different configurations, demonstrating its effectiveness as a general-purpose method to enhance learning efficiency. SNR-Aware Filtering improves performance across multiple RL algorithms and model scales. The method consistently increases peak task success rates in most experimental settings. Gains are observed across different input modalities, including text and image-conditioned models.
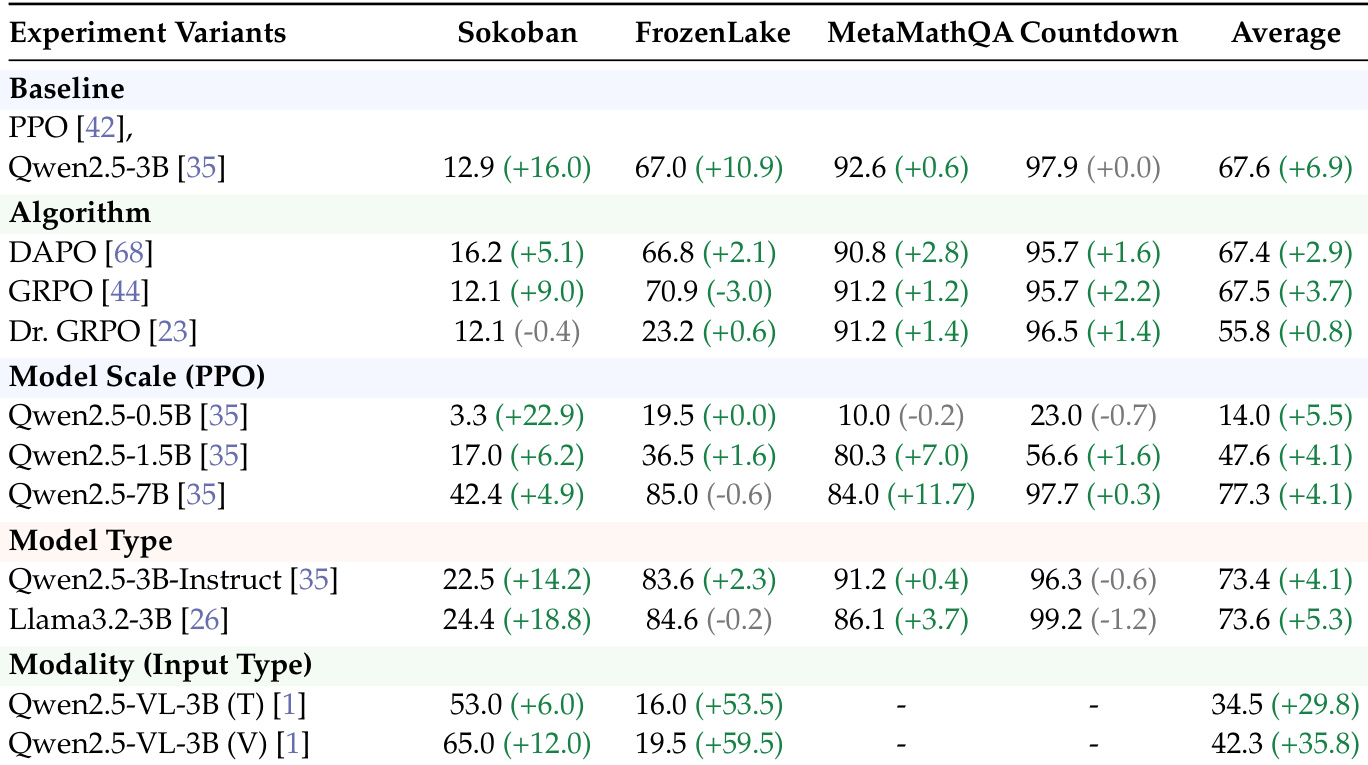
The the the table outlines different mutual information proxy metrics used to assess reasoning quality in agent training. These proxies vary in their formulation and computational approach, with some focusing on retrieval accuracy and others on normalized scores or entropy-based estimates. The metrics are designed to detect template collapse by measuring input dependence and reasoning diversity. The the the table lists multiple MI proxy metrics, including retrieval-based and normalized continuous scores, to evaluate reasoning quality. Different proxies use distinct formulas, such as argmax-based selection or marginal differences, to estimate mutual information. Some proxies, like MI-ZScore-EMA, incorporate smoothing and normalization to track MI dynamics more robustly during training.
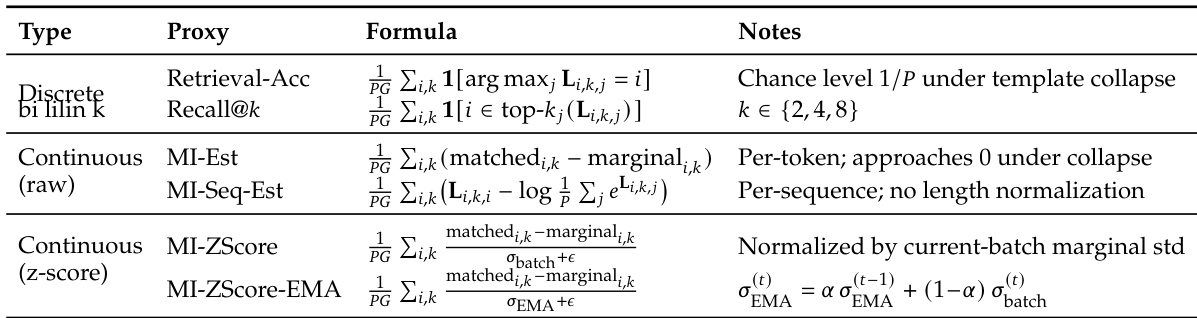
The experiments evaluate various reinforcement learning environments and intervention strategies to assess their impact on task performance and reasoning diversity. The results demonstrate that SNR-Aware Filtering prevents template collapse and maintains stable reasoning quality, whereas unfiltered training leads to a decline in mutual information and retrieval accuracy. Furthermore, the findings show that higher reward variance correlates with improved learning outcomes and that the filtering method consistently enhances peak success rates across different algorithms, model scales, and input modalities.