Command Palette
Search for a command to run...
TransitLM: マップフリーな交通経路生成のための大規模データセットとベンチマーク
TransitLM: マップフリーな交通経路生成のための大規模データセットとベンチマーク
Hanyu Guo Jiedong Yang Chao Chen Longfei Xu Kaikui Liu Xiangxiang Chu
概要
公共交通の経路計画は、従来、構造化された地図インフラと複雑なルーティングエンジンに依存しており、この依存関係を回避するためにモデルを訓練するための既存データセットは存在しませんでした。本研究では、中国の4都市における120,845の駅と13,666の路線をカバーする1,300万件以上の公共交通経路計画レコードからなる大規模データセット「TransitLM」を紹介します。TransitLMは、補完的な評価指標を用いた3つの評価タスクに対する継続的事前学習用コーパスおよびベンチマークデータとして公開されています。実験結果から、TransitLMで訓練された大規模言語モデル(LLM)は、構造的に有効な経路を高精度で生成し、明示的なマッピング処理なしに任意のGPS座標を適切な駅に暗黙的に対応付けることが示されました。これらの結果は、公共交通の経路計画がデータのみから完全に学習可能であることを示しており、起点・終点情報から直接、地図に依存しないエンドツーエンドの経路生成を可能にします。データセットとベンチマークは https://huggingface.co/datasets/GD-ML/TransitLM で、評価コードは https://github.com/HotTricker/TransitLM で公開されています。
One-sentence Summary
The authors propose TransitLM, a large-scale dataset and benchmark comprising over 13 million transit route planning records from four Chinese cities that enables end-to-end, map-free route generation by training language models to implicitly ground arbitrary GPS coordinates to stations without explicit mapping infrastructure and provides a benchmark for three complementary transit routing evaluation tasks.
Key Contributions
- Introduce TransitLM, a large-scale pre-training corpus and benchmark dataset comprising over 13 million transit route planning records across four Chinese cities, 120,845 stations, and 13,666 lines. This resource enables models to learn transit navigation entirely from data without relying on explicit map infrastructure or routing engines.
- Establish three standardized evaluation tasks for optimal route generation, preference-aware planning, and multi-route generation. Each task utilizes complementary metrics spanning connectivity, access feasibility, route overlap, and numeric field accuracy.
- Demonstrate that a language model trained on the dataset implicitly grounds arbitrary GPS coordinates to transit stations and produces structurally valid routes directly from origin-destination queries. The model generalizes across all planning objectives without negative transfer, confirming the feasibility of end-to-end, map-free route generation.
Introduction
Public transit route planning is critical for urban mobility, yet conventional systems depend heavily on structured map infrastructure and complex routing engines. While general-purpose large language models excel at reasoning, they consistently struggle with transit planning due to hallucinated stations, disconnected routes, and a lack of structural grounding. This limitation arises from fragmented training data, as existing trajectory datasets omit station structures while static network datasets ignore user behavior, leaving no comprehensive resource for learning end-to-end routing. To address this gap, the authors introduce TransitLM, a large-scale dataset containing over 13 million route planning records across four major Chinese cities. They release a continual pre-training corpus alongside a standardized benchmark for optimal routing, preference-aware planning, and multi-route generation. By training an LLM on this data, they demonstrate that models can produce structurally valid, map-free transit routes, implicitly learn spatial relationships from raw GPS coordinates, and generalize across diverse planning objectives without relying on external geographic databases.
Dataset
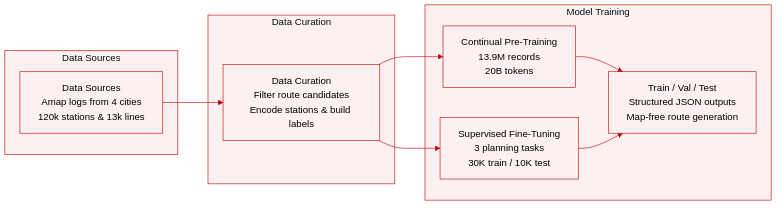
Dataset Composition and Sources
- The authors introduce TransitLM, a large-scale dataset derived from public transit route planning logs collected via Amap, a major Chinese navigation platform.
- The data spans four cities: Beijing, Shanghai, Shenzhen, and Chengdu, covering 120,845 stations and 13,666 bus and subway lines.
- The dataset is fully de-identified, sampled from a single calendar day, and excludes timestamps and user identifiers to ensure privacy and prevent re-identification of mobility patterns.
Key Details for Each Subset
- Continual Pre-Training (CPT) Corpus: This subset comprises 13.9 million records, including 12,945,264 route planning sessions, 880,854 station descriptions, and 147,918 line descriptions.
- Route planning sessions record origin and destination GPS coordinates, POI names, segment-level travel metrics, route-type annotations, and user selection labels.
- The modality distribution is balanced, with bus-only routes at 33.0%, subway-only at 19.0%, combined bus and subway at 16.8%, and mixed routes involving taxi or cycling connections at 30.5%.
- Average sequence length is 2,377 Chinese characters, with the corpus totaling over 20 billion tokens.
- Benchmark Supervised Fine-Tuning (SFT) Data: The authors construct task-specific data for three evaluation tasks: optimal route generation, preference-aware planning, and multi-route generation.
- Each task provides 30,000 training and 10,000 test examples formatted as standardized prompt-label pairs.
- Labels are structured JSON objects encoding line sequences, station sequences, total distance, time, fare, and first/last-mile transfer details.
Usage and Processing
- Candidate Filtering: The authors apply diversity filtering to route planning sessions, retaining at most five candidate routes per session from an original average of 6.32 options.
- Preference Learning: During CPT corpus construction, the user-selected route is placed first among the candidates to enable the model to implicitly learn user preferences via next-token prediction.
- Station Encoding: Stations are represented by unique numeric IDs rather than natural language names, necessitating vocabulary expansion for the language model.
- SFT Construction: For fine-tuning, the authors select specific routes from the candidate set according to task-defined criteria to create structured ground-truth labels.
- Metadata: The dataset includes static descriptions of lines and stations with attributes such as stop sequences, operating hours, and connectivity, allowing the model to internalize network topology.
Method
The authors leverage a large language model (LLM)-based framework for transit route planning, designed to overcome limitations in traditional methods and general-purpose LLMs. The overall architecture, referred to as TransitLM, is structured around a two-stage training pipeline that combines continual pre-training (CPT) and supervised fine-tuning (SFT), enabling the model to generate accurate, diverse, and preference-aware transit routes. The framework is end-to-end and map-free, eliminating the need for explicit map data retrieval or station lookup during inference.
The system begins with a user query specifying origin, destination, and optional preferences. The input is processed through a model trained on a custom dataset, TransitData, which consists of 13 million records from real-world user sessions across four major cities, including detailed OD trajectories and user interactions. This data is used to train the model on three core tasks: Optimal Route Generation, Preference-Aware Planning, and Multi-Route Generation. Each task operates on the same structured input and output schema, ensuring consistency. The model outputs a transit route as a structured JSON containing line sequences, station IDs, transfer markers, distance, time, fare, and first/last-mile access details.
Refer to the framework diagram 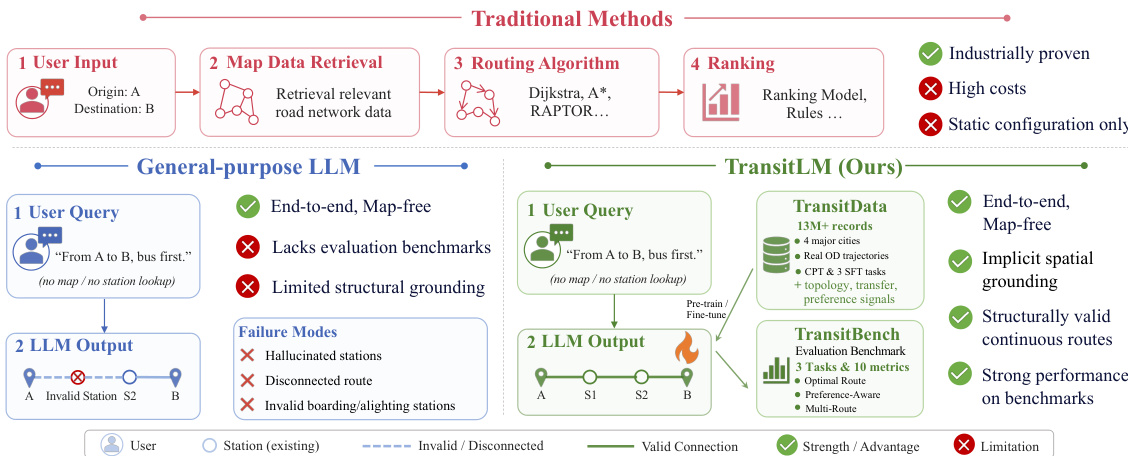 . The diagram illustrates the contrast between traditional methods and the proposed TransitLM approach. Traditional systems rely on a multi-step pipeline involving map data retrieval, routing algorithms like Dijkstra or RAPTOR, and a ranking model, which are industrially proven but suffer from high costs and static configurations. In contrast, TransitLM operates as a single, end-to-end model that processes the user query directly, producing a valid route without requiring intermediate map lookups or external algorithms. This design enables implicit spatial grounding and supports structurally valid continuous routes, addressing key limitations of general-purpose LLMs, such as hallucinated stations or disconnected routes.
. The diagram illustrates the contrast between traditional methods and the proposed TransitLM approach. Traditional systems rely on a multi-step pipeline involving map data retrieval, routing algorithms like Dijkstra or RAPTOR, and a ranking model, which are industrially proven but suffer from high costs and static configurations. In contrast, TransitLM operates as a single, end-to-end model that processes the user query directly, producing a valid route without requiring intermediate map lookups or external algorithms. This design enables implicit spatial grounding and supports structurally valid continuous routes, addressing key limitations of general-purpose LLMs, such as hallucinated stations or disconnected routes.
The model architecture is built upon Qwen3-Base variants (0.6B, 1.7B, and 4B), with the vocabulary extended to include all 120,845 station IDs as dedicated tokens. This expansion ensures that stations are represented as single tokens, preventing the model from generating non-existent stations through character-level composition and allowing it to learn direct station-level relationships. The two-stage training process begins with continual pre-training (CPT), where sequences are packed to a fixed length and optimized using cosine learning rate scheduling. This stage is followed by supervised fine-tuning (SFT), where the model is fine-tuned for one epoch on each task-specific dataset, drawn from a separate time period to prevent data leakage. A joint variant, Qwen3-4B-Joint, is also trained on the combined SFT data of all three tasks to evaluate whether transit knowledge transfers across planning objectives, enabling unified deployment.
As shown in the figure below: 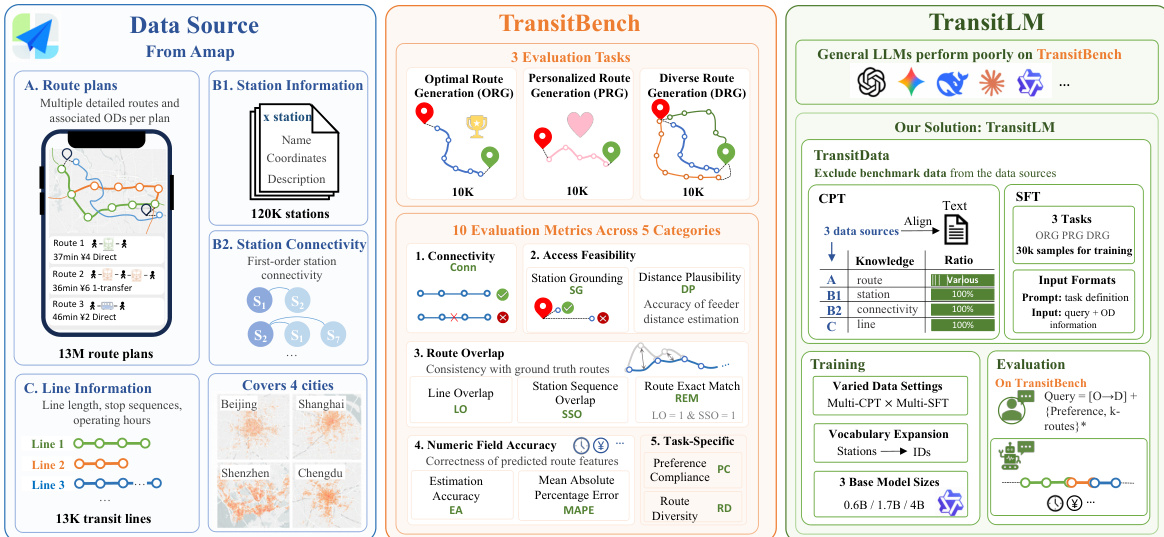 . The figure details the data sources, evaluation tasks, and training pipeline. The data is sourced from Amap and includes 13 million route plans, 120K stations, and 13K transit lines across four cities. The evaluation tasks are structured around 10 metrics across five categories: connectivity, access feasibility, route overlap, numeric field accuracy, and task-specific measures like preference compliance and route diversity. The training process involves CPT on text and structured data, followed by SFT on three distinct tasks. The model is evaluated on TransitBench, a benchmark that includes 30K samples for training and 10 metrics, ensuring strong performance across various planning objectives.
. The figure details the data sources, evaluation tasks, and training pipeline. The data is sourced from Amap and includes 13 million route plans, 120K stations, and 13K transit lines across four cities. The evaluation tasks are structured around 10 metrics across five categories: connectivity, access feasibility, route overlap, numeric field accuracy, and task-specific measures like preference compliance and route diversity. The training process involves CPT on text and structured data, followed by SFT on three distinct tasks. The model is evaluated on TransitBench, a benchmark that includes 30K samples for training and 10 metrics, ensuring strong performance across various planning objectives.
Experiment
The evaluation assesses transit route generation across optimal planning, preference-aware routing, and multi-route tasks using structural connectivity, access feasibility, route overlap, and numeric accuracy, benchmarking domain-specific models against general-purpose LLMs and tool-augmented baselines. Experimental results demonstrate that general-purpose models fundamentally lack transit topology knowledge and rely heavily on textual cues, whereas domain-specific models achieve robust spatial grounding and high route fidelity solely through continual pre-training on transit data. Ablation studies further confirm that this spatial understanding is independent of input modality, scales effectively with data volume, and generalizes seamlessly across multiple planning objectives without negative transfer, ultimately validating that end-to-end map-free routing can match external API performance without structural compromises.
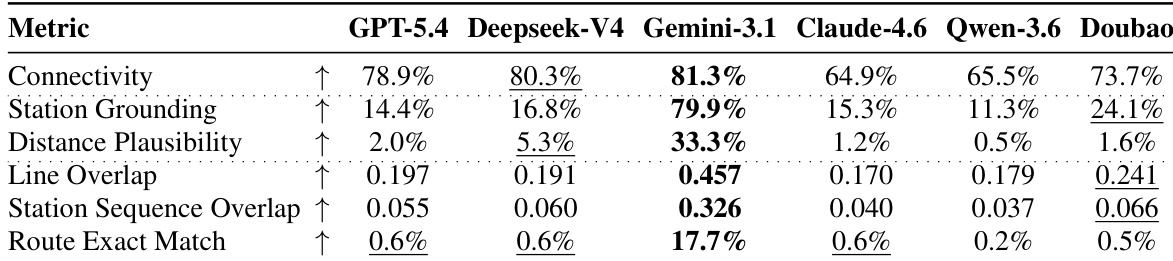
The authors compare several general-purpose large language models on optimal route generation, evaluating their performance across multiple dimensions including connectivity, access feasibility, route overlap, and numeric accuracy. Results show that these models struggle with structural validity and route correctness, with the best model achieving only moderate performance on key metrics like connectivity and route exact match. General-purpose LLMs exhibit low connectivity and route exact match, indicating limited ability to generate structurally valid transit routes. Among the evaluated models, Gemini-3.1 performs best in connectivity and station grounding, but still falls significantly short of domain-specific models. All general-purpose models show poor performance on route exact match and line overlap, highlighting a lack of transit network knowledge.
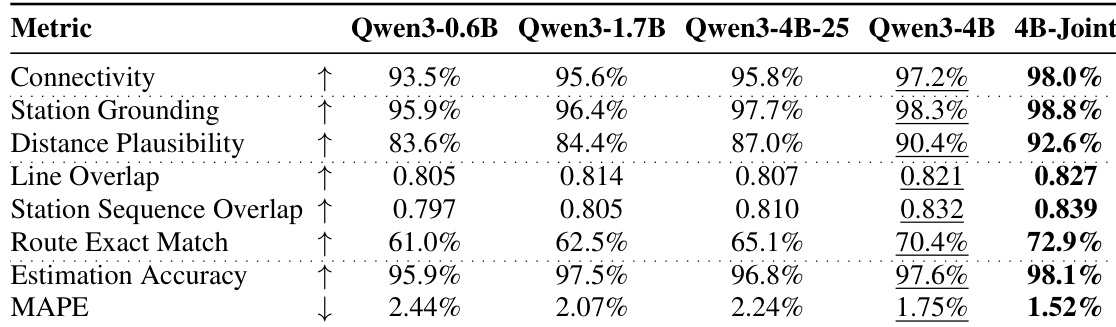
The authors evaluate the performance of different model configurations on transit route generation tasks, comparing standard text input with GPS-only input to assess the robustness of spatial grounding. Results show that models trained with continual pre-training (CPT) maintain high performance under GPS-only conditions, while SFT-only models degrade significantly, indicating that CPT enables the acquisition of transferable spatial knowledge independent of textual cues. The 4B-Joint model achieves the best overall performance across metrics and input modalities, demonstrating that joint training on multiple tasks enhances route quality and generalization. Models trained with continual pre-training maintain high performance under GPS-only input, indicating spatial knowledge is acquired independently of textual cues. The SFT-only baseline shows severe performance degradation when textual cues are removed, while CPT-based models exhibit minimal drop, highlighting the importance of pre-training for robust spatial reasoning. The 4B-Joint model outperforms other configurations across all metrics and input types, demonstrating that multi-task training strengthens the model's ability to handle diverse planning constraints.
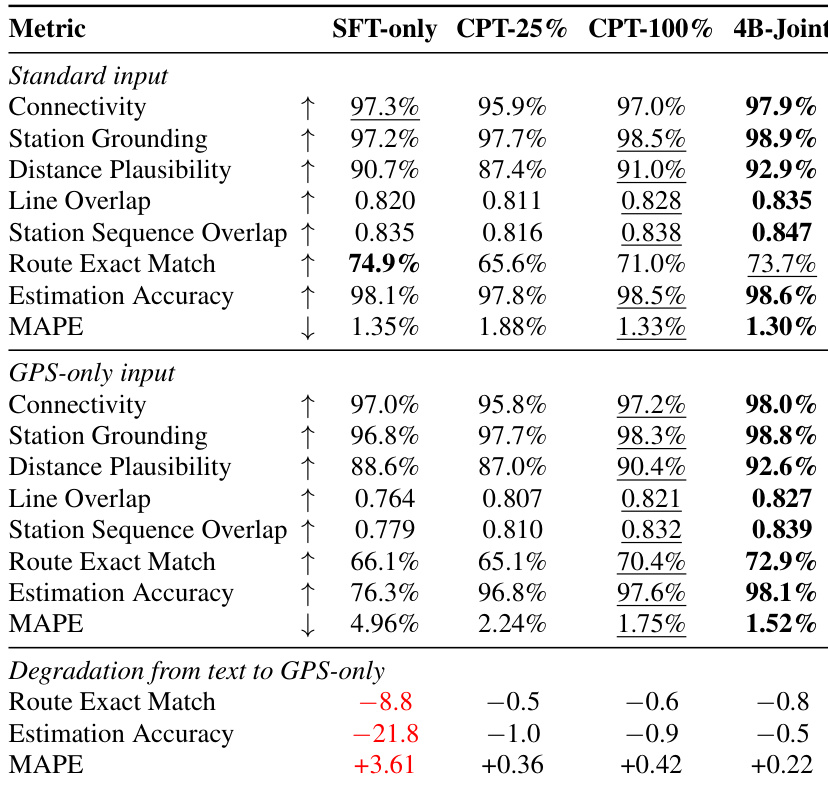
The authors evaluate the impact of continual pre-training (CPT) data volume on a domain-specific model's performance across multiple transit planning tasks. Results show that increasing the amount of CPT data leads to consistent improvements across all metrics, with basic connectivity and station grounding improving rapidly, while more complex tasks like route matching and numeric estimation require substantially more data. The model maintains strong performance even when textual cues are removed, indicating that spatial knowledge is learned through CPT rather than relying on input semantics. Performance improves monotonically with increased continual pre-training data volume across all evaluation metrics. Basic connectivity and station grounding metrics reach high levels even with minimal CPT data, while route matching and numeric accuracy require significantly more data. The model maintains high performance under GPS-only input, indicating that spatial grounding is learned through CPT rather than depending on textual cues.
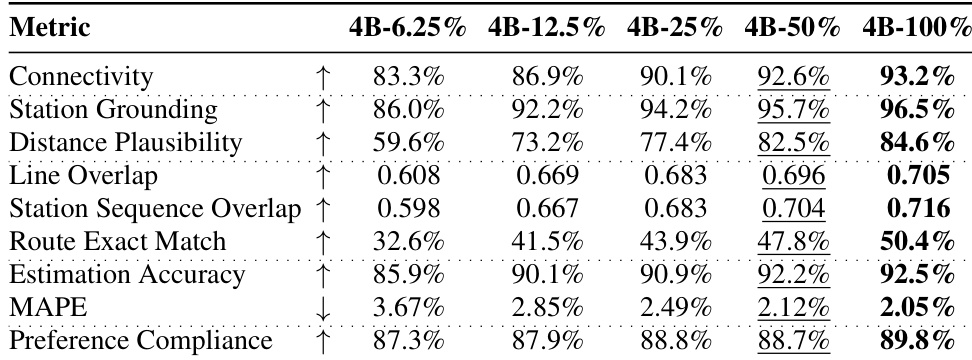
The authors evaluate multiple models on transit route generation tasks using a set of metrics that assess connectivity, access feasibility, route overlap, and numeric accuracy. Results show that domain-specific models significantly outperform general-purpose LLMs, with performance improving as model size increases, and that the learned spatial representations remain robust even when textual cues are removed. The best-performing model achieves high connectivity, accurate route matching, and strong performance across all evaluation dimensions. Domain-specific models achieve substantially higher connectivity and route exact match compared to general-purpose LLMs. Model performance improves with increasing size, and the largest model shows the best results across all metrics. The models maintain strong performance under GPS-only input, indicating that spatial knowledge is learned independently of textual cues.
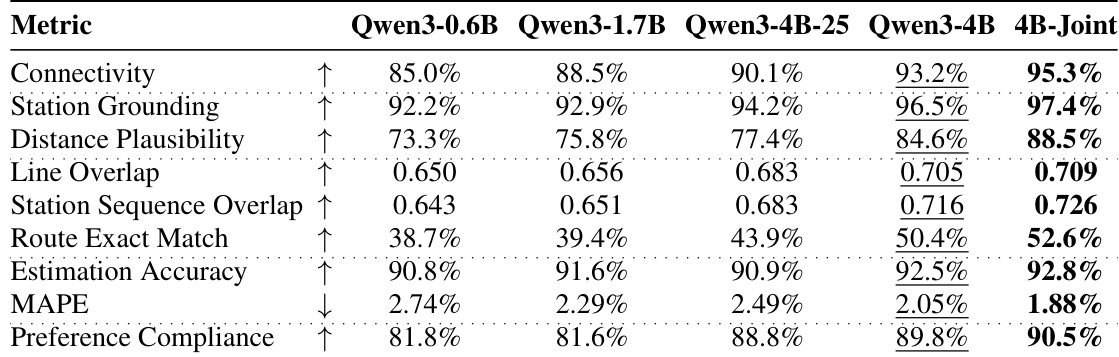
The authors compare multiple models on transit route generation tasks, evaluating performance across connectivity, access feasibility, route overlap, and numeric accuracy. Results show that larger models with continual pre-training achieve higher connectivity and route exact match, while domain-specific models maintain strong performance even under GPS-only input conditions. The best-performing model demonstrates high estimation accuracy and low error in predicted numeric fields. Larger models with continual pre-training achieve higher route exact match and connectivity compared to smaller models. Domain-specific models maintain strong performance under GPS-only input, indicating spatial grounding from training data rather than reliance on textual cues. The best model achieves high estimation accuracy and low error in numeric predictions, with minimal degradation when textual input is removed.
The experimental setup evaluates large language models on transit route generation by systematically testing architectural differences, training methodologies, and input modalities. Initial comparisons between general-purpose and domain-specific models validate that specialized training significantly improves structural connectivity and route correctness. Subsequent ablation studies on continual pre-training and multi-task learning validate that spatial reasoning can be acquired independently of textual cues, while scaling experiments confirm that larger data volumes and parameter counts consistently enhance complex planning accuracy.