Command Palette
Search for a command to run...
DelTA: 検証可能な報酬からの強化学習における判別トークン信用割り当て
DelTA: 検証可能な報酬からの強化学習における判別トークン信用割り当て
Kaiyi Zhang Wei Wu Yankai Lin
概要
検証可能な報酬からの強化学習(RLVR)は、大規模言語モデルの推論能力を向上させるための中心的な手法として台頭している。その有効性は高いものの、応答レベルの報酬がトークンレベルの確率変化にどのように転換されるかについては、依然として十分に理解されていない。本研究では、RLVR更新の判別器ビューを導入し、方策勾配更新方向がトークン勾配ベクトルに対して暗黙的に線形判別器として作用し、学習中にどのトークン確率が増加または減少するかを決定することを示す。標準的なシーケンスレベルのRLVRでは、この判別器は、トークン勾配ベクトルのアドバンテージ重み付き平均によって形成される正側および負側の重心から構築される。しかし、このような重心の構築は、フォーマットトークンなどの共有された高頻度パターンに支配されやすく、高報酬応答と低報酬応答をよりよく区別する、希薄だが判別力のある方向性が希薄化される。この制限に対処するため、私たちはextbfDelTAを提案する。これは、判別トークン信用配分手法であり、側面固有のトークン勾配方向を増幅し、共有または弱判別性の方向性を低重み付けするためにトークン係数を推定する。これらの係数は自己正規化されたRLVRサロゲートに再重み付けを施し、効果的な側面ごとの重心をより対照的なものとし、それによってRLVR更新方向を再形成する。7つの数学的ベンチマークにおいて、DelTAはQwen3-8B-BaseおよびQwen3-14B-Baseそれぞれで、同規模の最強ベースラインよりも平均して3.26ポイントおよび2.62ポイント上回る性能を示した。コード生成、異なるバックボーン、およびドメイン外評価における追加結果は、DelTAの汎化能力をさらに実証している。
One-sentence Summary
The authors propose DelTA, a discriminative token credit assignment method for reinforcement learning from verifiable rewards that estimates token coefficients to amplify side-specific gradient directions while downweighting shared formatting patterns, thereby reweighting a self-normalized RLVR surrogate to generate more contrastive side-wise centroids and reshape the RLVR update direction.
Key Contributions
- This work establishes a discriminator view of sequence-level reinforcement learning from verifiable rewards, demonstrating that policy-gradient updates implicitly function as a linear discriminator over token-gradient vectors to determine local probability adjustments.
- The proposed DelTA method computes discriminative token coefficients to amplify side-specific gradient directions while downweighting shared high-frequency patterns, thereby reshaping the update direction within a self-normalized reinforcement learning from verifiable rewards surrogate.
- Empirical evaluations on seven mathematical reasoning benchmarks and code generation tasks demonstrate consistent improvements over strong baselines, with average gains of 3.26 points on Qwen3-8B-Base and 2.62 points on Qwen3-14B-Base across multiple architectures and out-of-domain settings.
Introduction
Reinforcement learning from verifiable rewards has become a foundational technique for enhancing the reasoning capabilities of large language models in mathematics and code generation. By optimizing response-level correctness without dense process annotations, it bypasses costly human labeling, but it introduces a critical granularity mismatch where a single scalar reward must be distributed across individual token updates. Standard approaches handle this by averaging token gradients from positive and negative responses to form reference centroids, yet these centroids are frequently dominated by shared high-frequency patterns like formatting tokens. This dilution weakens the training signal by obscuring the sparse, highly discriminative directions that actually separate correct reasoning from incorrect outputs. To address this gap, the authors introduce a discriminator perspective on RLVR updates, revealing that policy gradients implicitly function as linear classifiers over token gradients. They leverage this insight to propose DelTA, a method that estimates discriminative token coefficients to amplify side-specific gradient directions while suppressing shared or weak signals. These coefficients reweight the RLVR training objective, producing more contrastive update directions and consistently boosting performance across mathematical reasoning, code generation, and out-of-domain benchmarks.
Method
The authors leverage the DAPO framework as a concrete example to analyze and improve sequence-level reward-based value refinement (RLVR) through a discriminative lens. The core method, DelTA, reweights token-gradient contributions in the RLVR objective to enhance the discriminative power of the induced policy update direction. This is achieved by reshaping the effective side-wise centroids that define the implicit linear discriminator in token-gradient space.
The overall framework begins with a group of sampled responses {oi}i=1G for a prompt q, each receiving a sequence-level reward Ri. These rewards are normalized to compute a group-normalized advantage A^i, which is shared by all tokens within the same response. The token-level importance ratio ri,t(θ), defined as the ratio of the policy's current to old log-probability for token oi,t, serves as the primary object for the policy update. The standard DAPO surrogate objective, as shown in Eq. (1), optimizes a clipped version of the product of the ratio and the advantage. The local policy-gradient update, derived from this objective, is an advantage-weighted aggregation of token-gradient vectors vi,t. This aggregation is separated by the sign of the advantage, forming a positive side (A^i>0) and a negative side (A^i<0).
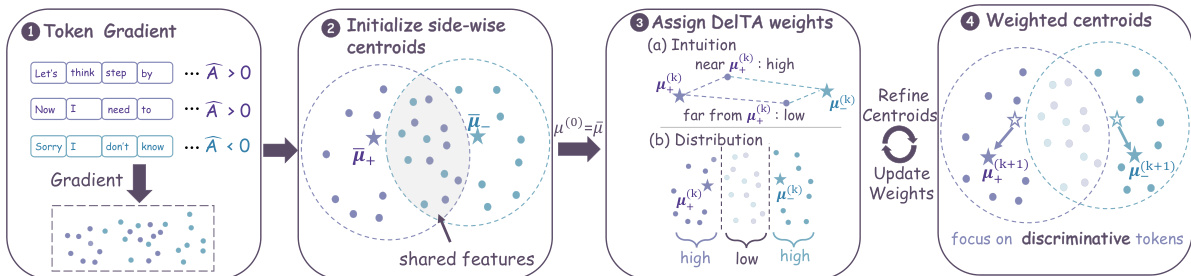
As shown in the figure above, the local update direction ΔθRLVR is proportional to the difference between the total mass and the normalized aggregate direction of the positive side and the negative side. The side-wise centroids μˉ+ and μˉ− are the advantage-weighted averages of the token-gradient vectors on each side, which act as reference directions for a discriminative decision. The authors argue that these centroids, being weighted least-squares summaries, are not necessarily optimal for distinguishing between the two advantage sides, as common token patterns can dominate and dilute more discriminative directions.
DelTA addresses this by introducing a discriminative signal-guided reweighting of tokens. The method first initializes the positive and negative centroids (μ+(0), μ−(0)) from the original advantage-weighted centroids. It then proceeds through K refinement iterations. In each iteration, DelTA estimates a soft discriminative score αi,t(k) for each token-gradient vector based on its proximity to its own side's centroid versus the opposite side's centroid. For a positive-advantage token, the score is maximized when the token-gradient vector is closer to the positive centroid than the negative one, and vice versa for a negative-advantage token. This is formalized as an entropy-regularized assignment problem, with the closed-form solution being a sigmoid function of the distance margin, as shown in Eq. (6).
Given these discriminative scores, DelTA updates the centroids by computing a score-weighted average of the token-gradient vectors on each side, as shown in Eq. (7). This refinement process amplifies the influence of token-gradient vectors that are more characteristic of their own advantage side. After the final refinement, the raw scores are mapped to bounded coefficients λi,t, which are then used to reweight the token contributions in a self-normalized version of the DAPO surrogate objective, as shown in Eq. (8). This reweighting reshapes the effective side-wise centroids, thereby modifying the induced discriminator and the local RLVR update direction to focus more on discriminative tokens. The entire coefficient estimation process is stop-gradient, meaning no gradients are backpropagated through it, and it is performed only once per rollout batch.
Experiment
The evaluation trains DelTA on Qwen3 and Olmo3 backbones across mathematical reasoning, code generation, and out-of-domain benchmarks, comparing it against state-of-the-art reinforcement learning baselines while isolating policy-update effects. Experiments validate that DelTA consistently outperforms all baselines by maintaining stable, confident long-reasoning trajectories, which stems from its discriminative token-level credit assignment that upweights contrastive gradient directions rather than relying on shared patterns. Ablation studies confirm that every design component, including the essential opposite-side comparison and single-step centroid refinement, is necessary for these gains, while hyperparameter sensitivity tests demonstrate robust performance across different configurations. Ultimately, the method generalizes effectively across diverse architectures and task domains without introducing significant computational overhead, establishing a reliable framework for sequence-level reinforcement learning.
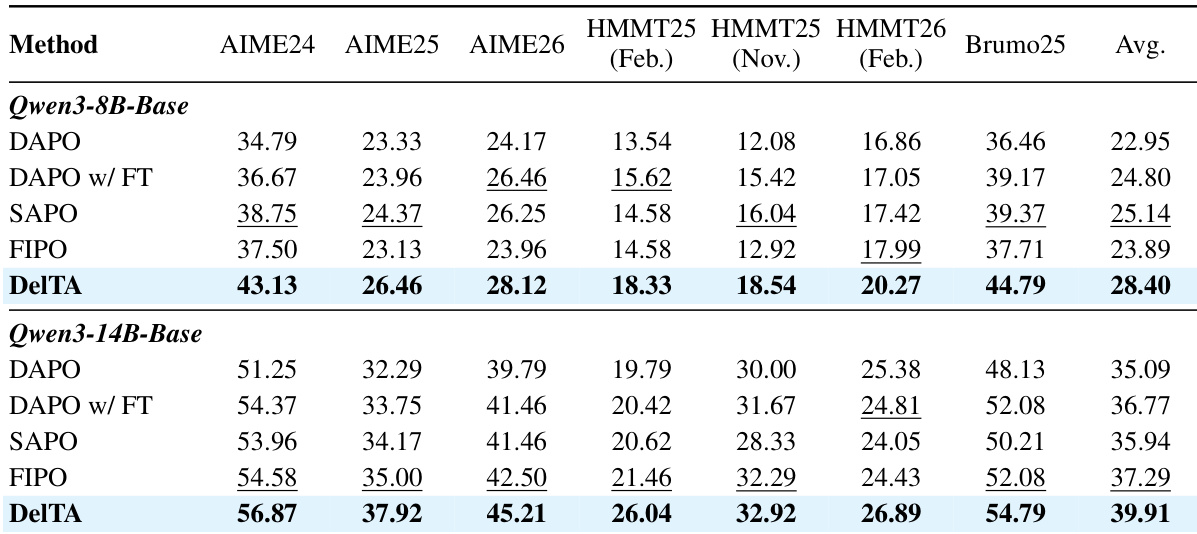
The authors compare DelTA against DAPO and a within-side-only variant on multiple mathematical reasoning benchmarks using two model backbones. Results show that DelTA consistently outperforms both baselines across all benchmarks and achieves the highest average score. The within-side-only variant underperforms both methods, indicating that opposite-side comparison is crucial for effective token-level credit assignment. DelTA consistently outperforms DAPO and a within-side-only variant on all mathematical reasoning benchmarks. The within-side-only variant performs worse than both DelTA and DAPO, highlighting the importance of opposite-side comparison. DelTA achieves the highest average score across all evaluated benchmarks on both model scales.
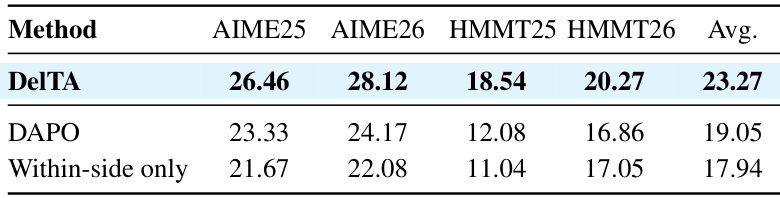
The authors conduct experiments on mathematical reasoning benchmarks using Qwen3-8B-Base and Qwen3-14B-Base models, comparing their proposed method DelTA against several RL baselines. Results show that DelTA consistently outperforms all same-scale baselines across all benchmarks and both model sizes, with improvements in average scores. The method demonstrates robustness across different model architectures and tasks, including code generation and out-of-domain evaluation, while maintaining a modest computational overhead. Training dynamics reveal that DelTA sustains higher rewards and more stable long-reasoning behavior compared to baseline methods. DelTA consistently outperforms all same-scale RL baselines on both model sizes across all mathematical reasoning benchmarks. DelTA maintains higher rewards and more stable long-reasoning behavior during training compared to baseline methods. DelTA shows consistent improvements over baselines in out-of-domain evaluation and on different model architectures, indicating broad applicability.
The authors conduct an ablation study to evaluate the contribution of individual design components in DelTA. The results show that each component plays a role in the overall performance, with the removal of refinement leading to the most significant drop in average score. Other components, including adaptive temperature scaling, entropy regularization, and coefficient normalization, also contribute to the effectiveness of the method. The findings suggest that the full set of design choices in DelTA is necessary for optimal performance. Each component of DelTA contributes to its performance, with refinement having the largest impact. Removing adaptive temperature scaling, entropy regularization, or coefficient normalization reduces the average score. The ablation study confirms that the full DelTA design is necessary for optimal results.
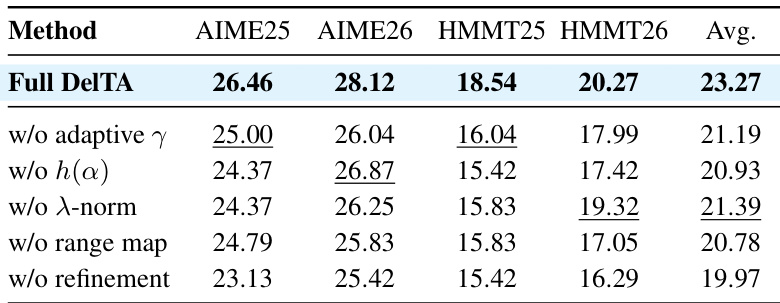
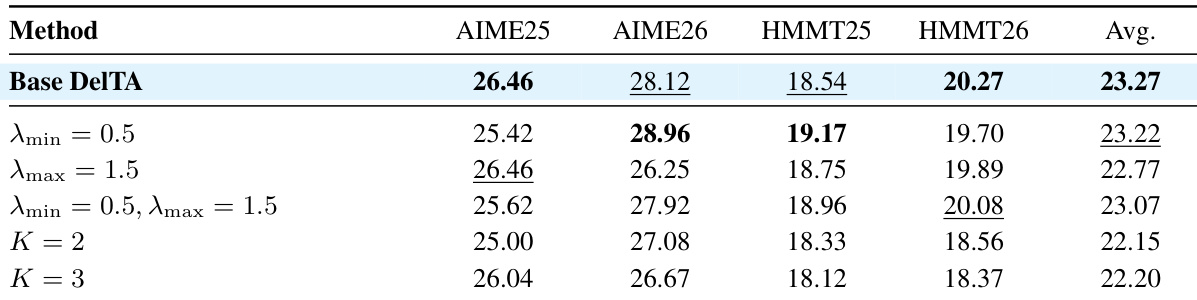
The the the table presents an ablation study of DelTA, showing how different hyperparameter settings affect performance across multiple mathematical reasoning benchmarks. The results indicate that the base configuration of DelTA achieves the highest average score, while variations in the coefficient range and refinement iterations lead to lower performance, suggesting that the chosen settings provide a stable and effective balance. The base DelTA configuration achieves the highest average score across all benchmarks. Increasing the refinement iterations beyond one leads to a consistent decrease in performance. Varying the coefficient range has a smaller impact on performance compared to changes in refinement iterations.
The authors evaluate DelTA against several reinforcement learning baselines on mathematical reasoning benchmarks using two model scales. Results show that DelTA consistently outperforms all same-scale baselines across both model sizes, achieving the highest scores on every benchmark and the best average performance. The gains are observed across multiple settings, including different model architectures and out-of-domain tasks, indicating robustness and generalization beyond the primary evaluation suite. DelTA consistently achieves the highest scores on all benchmarks and the best average performance compared to same-scale baselines. DelTA outperforms all baselines on both Qwen3-8B-Base and Qwen3-14B-Base, with significant gains on every individual benchmark. DelTA's improvements are robust across different model architectures and extend to out-of-domain reasoning tasks.
Evaluated on mathematical reasoning benchmarks using Qwen3 model variants, DelTA consistently surpasses reinforcement learning baselines and ablated variants in both performance and training stability. The experiments validate that opposite-side comparison is essential for effective token-level credit assignment, while component ablations confirm that each design choice, particularly the refinement module, is necessary for optimal results. Hyperparameter analysis further demonstrates that the base configuration provides the most effective balance, and cross-task evaluations highlight the method's robustness and strong generalization to out-of-domain scenarios. Collectively, these findings establish DelTA as a highly stable and broadly applicable approach that reliably enhances long-reasoning capabilities across diverse model scales.