Command Palette
Search for a command to run...
フルアテンションが再び襲来:数百のトレーニングステップ内でフルアテンションをスパースに変換する
フルアテンションが再び襲来:数百のトレーニングステップ内でフルアテンションをスパースに変換する
Yanke Zhou Yiduo Li Hanlin Tang Maohua Li Kan Liu Lan Tao Lin Qu Yuan Yao Xiaoxing Ma
概要
タイトル:(タイトルなし)抄録:大規模言語モデルにおける長文脈推論は、フルアテンションの二次的な計算コストによってボトルネックが生じている。既存の効率的な代替手法は、主にネイティブスパース学習またはヒューリスティックなトークン削除に依存しており、効率性、学習コスト、精度の間に望ましくないトレードオフを生み出している。本研究では、フルアテンションの大規模言語モデルが本質的にスパース性を持っており、最小限の適応のみで高度にスパースなモデルに変換可能であることを示す。我々のアプローチは以下の3つの観察結果に基づいている:(1)アテンションヘッドのごく一部のみが真に長い文脈のフル処理を必要とする;(2)長距離の検索は主に低次元部分空間によって支配されており、関連するトークンを16次元のインデクサを用いて効率的に検索できる;(3)有用なトークンの予算はクエリに強く依存しており、固定されたtop-kスパース化よりも動的なtop-p選択の方が適している。これらの洞察に基づき、我々はRTPurboを提案する。RTPurboは、検索ヘッドに対してのみフルKVキャッシュを保持し、スパースアテンションのために軽量なトークンインデクサを導入する。モデルの本質的なスパース性を活用することで、RTPurboは数百ステップの学習のみでスパース化を実現する。長文脈ベンチマークおよび推論タスクにおける実験は、RTPurboがほぼ損失のない精度を維持しつつ、1M文脈において最大9.36倍のprefill速度向上、および約2.01倍のdecode速度向上といった大幅な効率向上をもたらすことを示している。これらの結果は、高価なネイティブスパース事前学習を行わずとも、標準的なフルアテンション学習から強力なスパース推論が得られることを示唆している。
One-sentence Summary
RTPURBO efficiently sparsifies full-attention language models for long-context inference by retaining full key-value caches exclusively for retrieval heads and employing a lightweight sixteen-dimensional indexer with query-dependent token selection, achieving near-lossless accuracy and substantial efficiency gains in only a few hundred training steps.
Key Contributions
- The paper introduces RTPURBO, a sparse inference framework that mitigates the quadratic cost of long-context LLMs by preserving full KV caches exclusively for retrieval-specialized attention heads while deploying a lightweight 16-dimensional token indexer for all other heads.
- The method achieves rapid sparsification through minimal adaptation requiring only a few hundred training steps, utilizing query-dependent dynamic top-p selection to replace expensive native sparse pretraining and static top-k eviction strategies.
- Evaluations across long-context benchmarks and reasoning tasks demonstrate that the framework maintains near-lossless accuracy while delivering up to a 9.36× prefill speedup at one million tokens and approximately a 2.01× decode speedup.
Introduction
Long-context inference is essential for deploying large language models on extended documents, yet it remains bottlenecked by the quadratic computational cost of full attention mechanisms. Prior efficiency methods typically require expensive native sparse pretraining or rely on rigid heuristic token eviction, forcing practitioners to compromise between inference speed, training overhead, and downstream accuracy. The authors leverage the intrinsic sparsity of pretrained models by identifying a small subset of retrieval heads that handle long-range context, while applying a lightweight 16-dimensional indexer and query-dependent dynamic top-p sparsification to the remaining attention heads. This strategy, formalized as RTPURBO, transforms standard full-attention models into highly sparse architectures within just a few hundred training steps, delivering substantial prefill and decode speedups while preserving near-lossless accuracy.
Method
The authors leverage a head-wise attention framework, RTPURBO, to achieve efficient sparse inference in large language models while preserving performance. The overall architecture is designed around the observation that full-attention models inherently exhibit sparsity, with certain heads functioning as retrieval mechanisms that attend to distant, semantically related tokens, while others focus on local context. This insight, supported by the behavior illustrated in the figure showing retrieval heads attending to semantically similar but spatially distant tokens, forms the foundation for a selective sparsification strategy.

The method begins with an offline calibration process to identify retrieval heads. This is achieved by constructing a calibration sequence with a "needle" span at both the beginning and end of a long document. The retrieval capability of each head is quantified by measuring the attention mass from the later needle to the earlier one. This process, which is stable and input-agnostic, allows for a one-time partitioning of all heads into a retrieval set Hret and a local set Hloc.
During inference, the framework operates differently for the two head types. Local heads consistently apply a sliding window with attention sinks during both prefill and decode stages. In contrast, retrieval heads perform full dense attention during prefill to build a complete KV cache, but switch to a dynamic sparse selection during decoding. The core of the sparse mechanism for retrieval heads is a low-rank projection applied to the pre-RoPE query and key representations, qm,hpre and kn,hpre, using trainable weights WhQ and WhK. This projection, sh(m,n)=(WhQqm,hpre)⊤(WhKkn,hpre), efficiently computes a relevance score in a low-dimensional space. The selection of tokens is then performed using a dynamic Top-p rule, where the active set Sh(m) is defined as the set of tokens whose cumulative attention mass exceeds a threshold p. This approach is motivated by the observation that high-frequency RoPE components degrade long-range affinity, while low-frequency components better preserve retrieval signals, a phenomenon highlighted in the figure showing the dominance of low-rotation components for long-range recall.
To adapt the model to this sparse regime, a lightweight two-stage training pipeline is employed. The first stage freezes the backbone model and independently trains the low-dimension projection weights WhQ and WhK for each retrieval head. This is done by minimizing the Kullback-Leibler (KL) divergence between the original dense attention distribution and the distribution derived from the projected scores. The second stage involves a self-distillation process, where the sparse model acts as a student to match the next-token predictions of the original dense model. To reduce computational overhead, only the top-10 logits of the teacher are used for this alignment. The overall architecture, including the prefill and decode phases for both head types, is illustrated in the figure, showing the flow from offline calibration to the dynamic sparse selection in the decode phase.
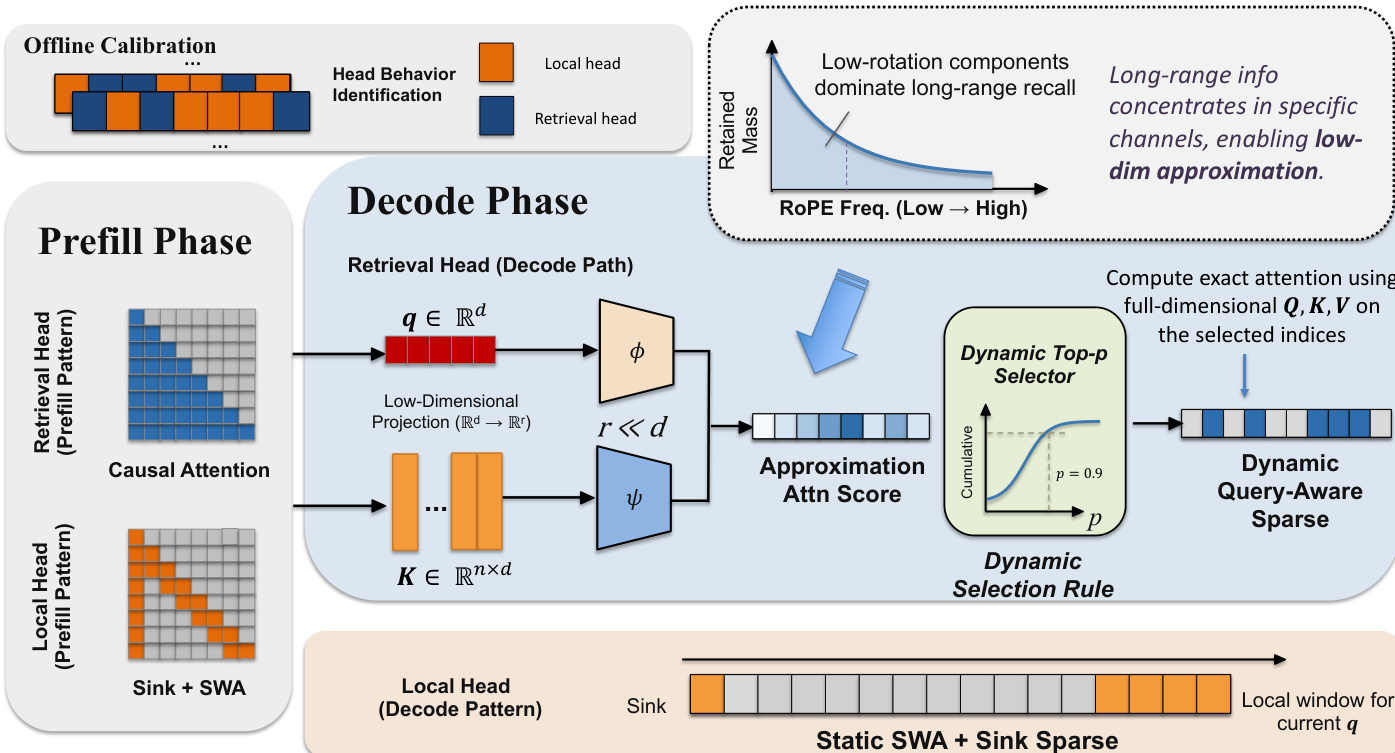
Finally, a hardware-aware decoding kernel is implemented to optimize the sparse computation. This kernel addresses two key challenges: fast top-p thresholding and memory-efficient decoding. The first kernel, Kernel 1, computes attention scores in parallel, uses a histogram to sort-free select the top-p tokens without expensive sorting, and fuses the scoring and selection into a single kernel launch. The second kernel, Kernel 2, handles the actual sparse attention computation. It is designed to be bandwidth-optimized by using a single-warp CTA with no shared memory, keeping all state in registers to maximize concurrent memory requests. The inner loop is 2-token unrolled, and vectorized half2 instructions are used to load K and V data, allowing score computation and online-softmax updates to overlap with in-flight memory loads. This architecture is depicted in the figure showing the parallel and sequential phases of the sparse decoding process.
Experiment
Evaluated on standard GPU infrastructure using a unified accuracy framework and dedicated efficiency profiling, the experimental setup establishes a baseline for assessing both architectural design and computational performance. The sparsity and accuracy experiments validate that retrieval head activity is fundamentally query-dependent, proving that dynamic thresholding effectively balances high attention recall with computational efficiency. Concurrently, runtime benchmarks validate that this adaptive mechanism consistently accelerates inference across ultra-long contexts without compromising model reliability.
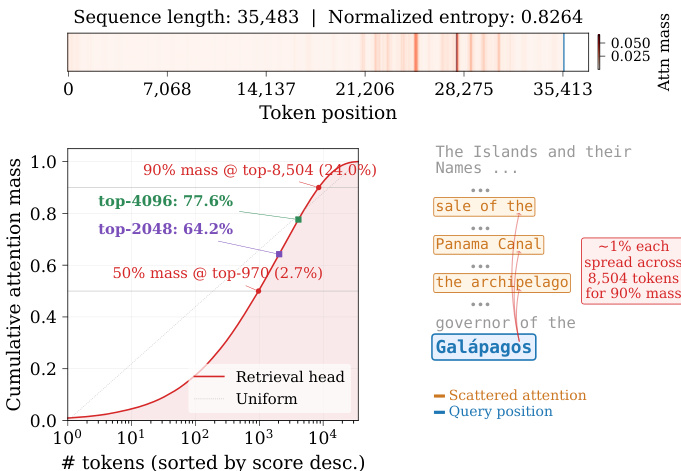
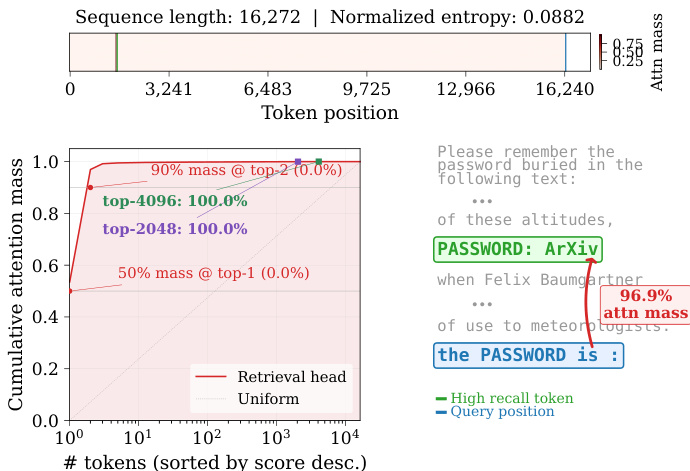
The authors analyze the query-dependent nature of retrieval head sparsity, showing that the optimal number of tokens to retain varies significantly across different inputs. Results demonstrate that dynamic thresholding methods maintain high attention mass while achieving substantial sparsity, outperforming fixed-budget approaches across varying context lengths. Retrieval head sparsity is highly query-dependent, with different inputs requiring vastly different numbers of tokens to preserve attention mass. Dynamic thresholding achieves high sparsity and maintains attention mass, unlike fixed-budget methods that either under-retrieve or waste computation. The optimal token budget varies by query type, with some requiring significantly more tokens than others to retain effective attention.
The authors evaluate a dynamic sparsity method, RTPURBO, against fixed-top-k approaches and full attention across multiple benchmarks. Results show that RTPURBO achieves competitive or superior accuracy while maintaining significantly higher sparsity, especially in long-context scenarios. The method adapts to query complexity, preserving attention mass efficiently without fixed budget constraints. RTPURBO achieves higher sparsity than fixed-top-k methods while maintaining competitive accuracy across benchmarks. The method adapts to query complexity, dynamically adjusting the number of active tokens to maintain attention mass. RTPURBO sustains high accuracy and sparsity at ultra-long context lengths, outperforming baselines in efficiency and recall.
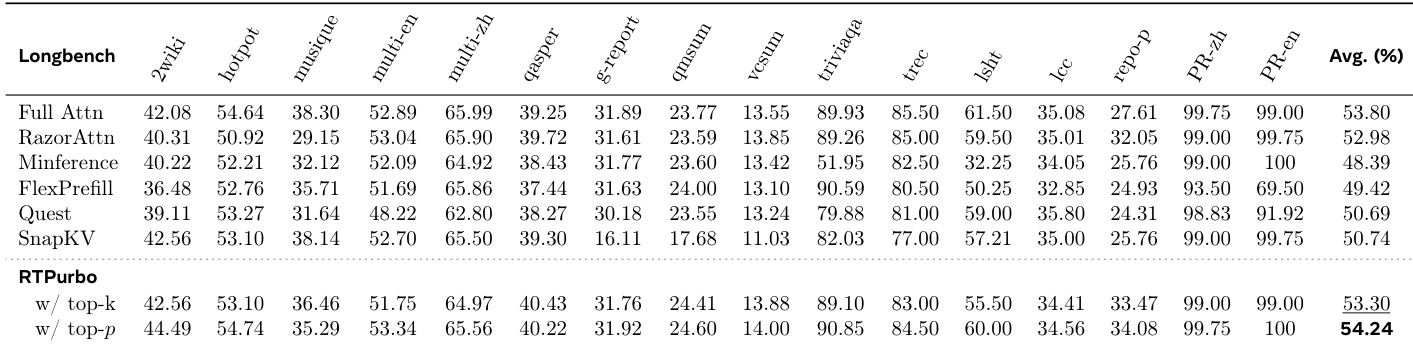
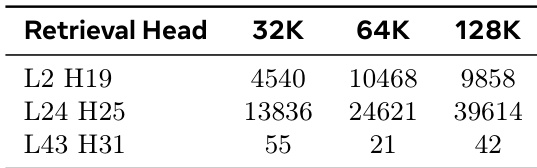
The authors evaluate the performance of different dimension settings on various benchmarks, showing that higher dimensions generally maintain or improve accuracy across tasks. The results indicate that the choice of dimension affects performance differently depending on the benchmark, with some tasks benefiting more from increased dimensionality than others. Higher dimensions tend to maintain or improve accuracy across most benchmarks compared to lower dimensions. Performance varies significantly across benchmarks, with some showing consistent results across dimension settings while others exhibit more variation. The impact of dimensionality is task-dependent, with certain benchmarks showing notable improvements at higher dimensions.
The authors evaluate the performance of their method, RTPurbo, against baselines across multiple benchmarks, showing that it achieves competitive or superior accuracy while maintaining high sparsity. The results indicate that dynamic thresholding in retrieval heads enables efficient attention computation without significant accuracy loss, particularly in long-context scenarios. RTPurbo achieves competitive accuracy compared to baselines across multiple reasoning tasks, with improvements on several benchmarks. The method maintains high sparsity while preserving attention mass, enabling efficient computation in long-context settings. Dynamic thresholding in retrieval heads allows for query-dependent sparsity, outperforming fixed-budget approaches like top-k.

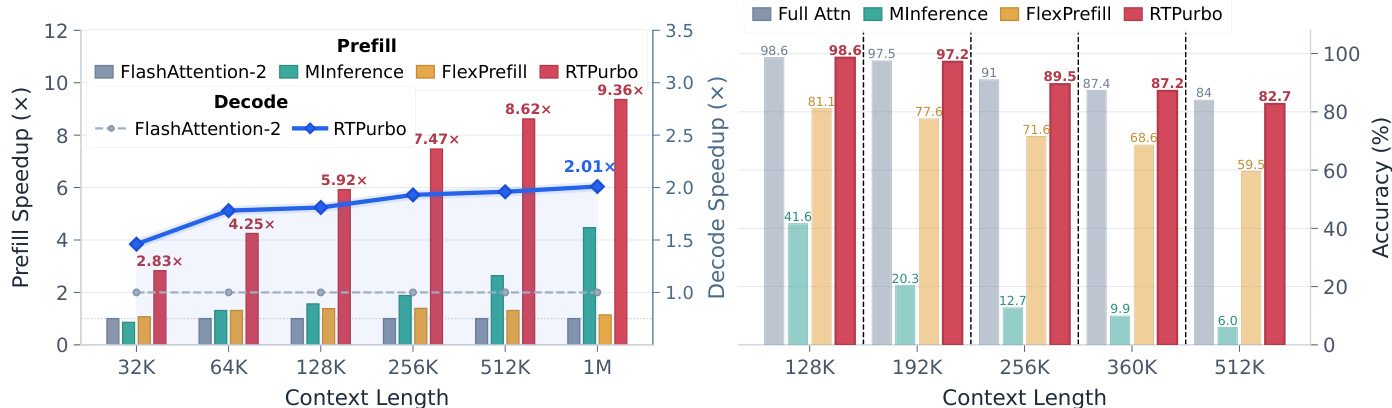
The authors evaluate the efficiency of their method, RTPurbo, in comparison to baseline approaches across different context lengths. Results show that RTPurbo achieves significant speedups over FlashAttention-2 in both prefill and decode phases, with performance improving as context length increases. The method maintains high accuracy while achieving substantial sparsity, particularly in ultra-long context scenarios. RTPurbo achieves higher speedups than FlashAttention-2 across all context lengths in both prefill and decode phases. RTPurbo maintains high accuracy while achieving high sparsity, especially at longer context lengths. The speedup of RTPurbo increases with context length, demonstrating better scalability compared to baselines.
The experiments evaluate a dynamic sparsity framework for retrieval heads across multiple benchmarks, varying context lengths, and different dimension settings to validate its adaptability and computational efficiency. Results demonstrate that query-dependent thresholding consistently preserves attention mass and maintains competitive accuracy while achieving substantially higher sparsity than fixed-budget or full attention baselines. The approach scales effectively with longer contexts, delivering notable speedups without performance degradation. Overall, the findings confirm that dynamically allocating tokens based on input complexity provides a robust and efficient alternative to static selection strategies.