Command Palette
Search for a command to run...
精神疾患診断のICD分類の自動化:古典的NLPから大規模言語モデルへ
精神疾患診断のICD分類の自動化:古典的NLPから大規模言語モデルへ
Fernando Ortega Raúl Lara-Cabrera Jorge Dueñas-Lerín Alejandro de la Torre-Luque Mercé Salvador Robert Enrique Baca-García
概要
メンタルヘルスは世界的な優先課題となっており、臨床診断のコーディングにおいて多大な行政負担を生み出している。本研究では、自然言語処理(NLP)および機械学習(ML)の手法を用いて、自由記述の記述を国際疾病分類(ICD)にマッピングすることで、精神医学的診断分析の自動化を提案する。145,513件のスペイン語による精神医学的記述からなる専門データセットを活用し、古典的な頻度ベースのモデル(BoW、TF-IDF)から、e5_large、BioLORD、Llama-3-8Bといった最先端の大規模言語モデル(LLM)に至るまで、さまざまなテキスト表現のパラダイムを評価した。結果は、トランスフォーマーベースの埋め込みが、暗黙的な意味的な手がかりや微妙な医学用語を捉えることで、従来の手法を一貫して上回ることを示している。エンドツーエンドのファインチューニングを通じて、e5_largeモデルはF1_microスコア0.866という最高性能を達成した。本研究は、LLMを特定の臨床用語体系に適応させることが、「ロングテール」ラベル分布および精神医学的談話に内在する曖昧さという課題を克服するために不可欠であることを実証している。
One-sentence Summary
By analyzing 145,513 Spanish psychiatric descriptions, this study demonstrates that end-to-end fine-tuning of the e5_large model achieves a 0.866 F1_micro score in automated ICD classification, consistently outperforming classical NLP approaches by capturing nuanced clinical semantics to address long-tail label distributions and diagnostic ambiguity.
Key Contributions
- This study evaluates multiple text representation paradigms, ranging from classical frequency-based models to state-of-the-art large language models, on a specialized dataset of 145,513 Spanish psychiatric descriptions.
- Transformer-based embeddings consistently outperform traditional methods by capturing implicit semantic cues and nuanced medical terminology, with the end-to-end fine-tuned e5_large model achieving a F1_micro score of 0.866.
- The findings demonstrate that adapting large language models to specific clinical nomenclature effectively resolves long-tail label distributions and the inherent ambiguity of psychiatric diagnostic discourse.
Introduction
Automated clinical coding translates free-text psychiatric notes into standardized ICD diagnoses, a critical workflow for healthcare analytics and research that currently relies on labor-intensive manual processes prone to inconsistency. Prior computational approaches, ranging from traditional frequency-based models to early neural architectures, struggle with the subjective nature of mental health documentation, the extreme multi-label structure of clinical coding, and the tendency of off-the-shelf language models to hallucinate or miss rare diagnoses. To address these limitations, the authors evaluate a broad spectrum of text representation techniques on a large Spanish psychiatric corpus, demonstrating that transformer-based embeddings consistently capture the implicit semantic cues required for accurate classification. By fine-tuning the e5_large model end-to-end, they achieve state-of-the-art performance and show that domain-adapted large language models are essential for managing long-tail label distributions and the inherent ambiguity of psychiatric discourse.
Dataset

- Dataset Composition and Sources: The authors leverage a large-scale Spanish clinical corpus consisting of more than 145,000 real-world mental health diagnostic descriptions.
- Subset Details: The collection functions as a single unified dataset without explicit subset breakdowns, predefined filtering rules, or train-validation-test splits in the provided text. All entries represent clinical diagnostic text focused on psychiatric conditions.
- Data Usage and Processing: The dataset drives a comparative classification pipeline evaluating classical bag-of-words and TF-IDF baselines against transformer-based embeddings from e5_large and BioLORD. The authors assign XGBoost as the primary classifier for dense contextual vectors and deploy Multi-Layer Perceptrons for high-dimensional sparse features. Peak performance is achieved through end-to-end fine-tuning of large language models, resulting in a 0.866 micro F1 score.
- Processing Considerations and Challenges: While explicit cropping or metadata construction steps are not detailed, the authors implement strategies to manage extreme class imbalance. The pipeline specifically targets low-prevalence psychiatric conditions, demonstrating that semantic depth must be paired with robust modeling techniques to address long-tail distribution challenges.
Method
The authors leverage a multi-stage framework for evaluating text representation techniques in the automated classification of mental health diagnostic descriptions into ICD codes. The pipeline begins with raw input data consisting of 145,513 free-text descriptions in Spanish, which undergo a preprocessing phase focused on text enrichment and standardization. This includes identifying and expanding abbreviated ICD codes using regular expressions, followed by rule-based normalization to remove non-informative characters and standardize formats. The processed text is then transformed into numerical features through a variety of representation strategies, which are categorized into conventional and embedding-based approaches.
As shown in the figure below, the conventional methods include the Bag of Words (BoW) and Term Frequency-Inverse Document Frequency (TF-IDF) models, which represent clinical notes as high-dimensional sparse vectors based on term frequencies. These are followed by embedding approaches that aim to capture richer semantic information. Latent Semantic Analysis (LSA) and Latent Dirichlet Allocation (LDA) are employed to extract latent thematic structures, reducing dimensionality while preserving topical content. Doc2Vec is used to generate dense, fixed-length document vectors by training on the corpus of Spanish psychiatric notes, capturing contextual dependencies. Additionally, the authors utilize state-of-the-art large language models (LLMs) to obtain deep contextualized embeddings, where the clinical text is passed through the transformer architecture to extract final hidden-state representations, encoding complex semantic and syntactic relationships.
The resulting representations are fed into three distinct classification models, each designed to handle the multi-label nature of the task. The first category consists of traditional machine learning methods, specifically Random Forest and XGBoost, which are trained on the various feature sets derived from the text representations. These models operate in a multi-output configuration, allowing them to process all 85 labels simultaneously and potentially model dependencies between diagnoses. The second category employs deep learning, with a Multi-Layer Perceptron (MLP) designed to adapt to the diverse input features. The architecture of this network is dynamically optimized during hyperparameter tuning, with a fixed output layer of 85 neurons using sigmoid activation and binary cross-entropy loss to predict the presence of each ICD code. The final approach involves end-to-end fine-tuning of LLMs, where a task-specific classification head is appended to the transformer backbone, and the model's weights are updated using the specialized dataset. This strategy enables the model to adapt its internal representations to the clinical nomenclature and the long-tail distribution of the ICD codes, representing the most sophisticated and computationally intensive tier of the classification framework.
Experiment
The study evaluates automated psychiatric coding by systematically comparing traditional frequency-based text representations, classical embeddings, and modern large language model embeddings across multiple classifier architectures using a stratified clinical dataset. These experiments validate that transformer-based embeddings effectively capture the implicit semantic nuances of psychiatric documentation, while also demonstrating that optimal performance requires aligning specific classifier architectures with their corresponding feature types. Qualitatively, the findings highlight that semantic depth significantly outperforms explicit keyword matching for complex diagnostic descriptions, yet severe class imbalance continues to hinder accurate coding for rare conditions regardless of model sophistication. Ultimately, the research establishes that task-specific adaptation of contextual embeddings provides the most robust foundation for clinical coding systems, though future work must prioritize addressing data scarcity and improving model interpretability for broader clinical adoption.
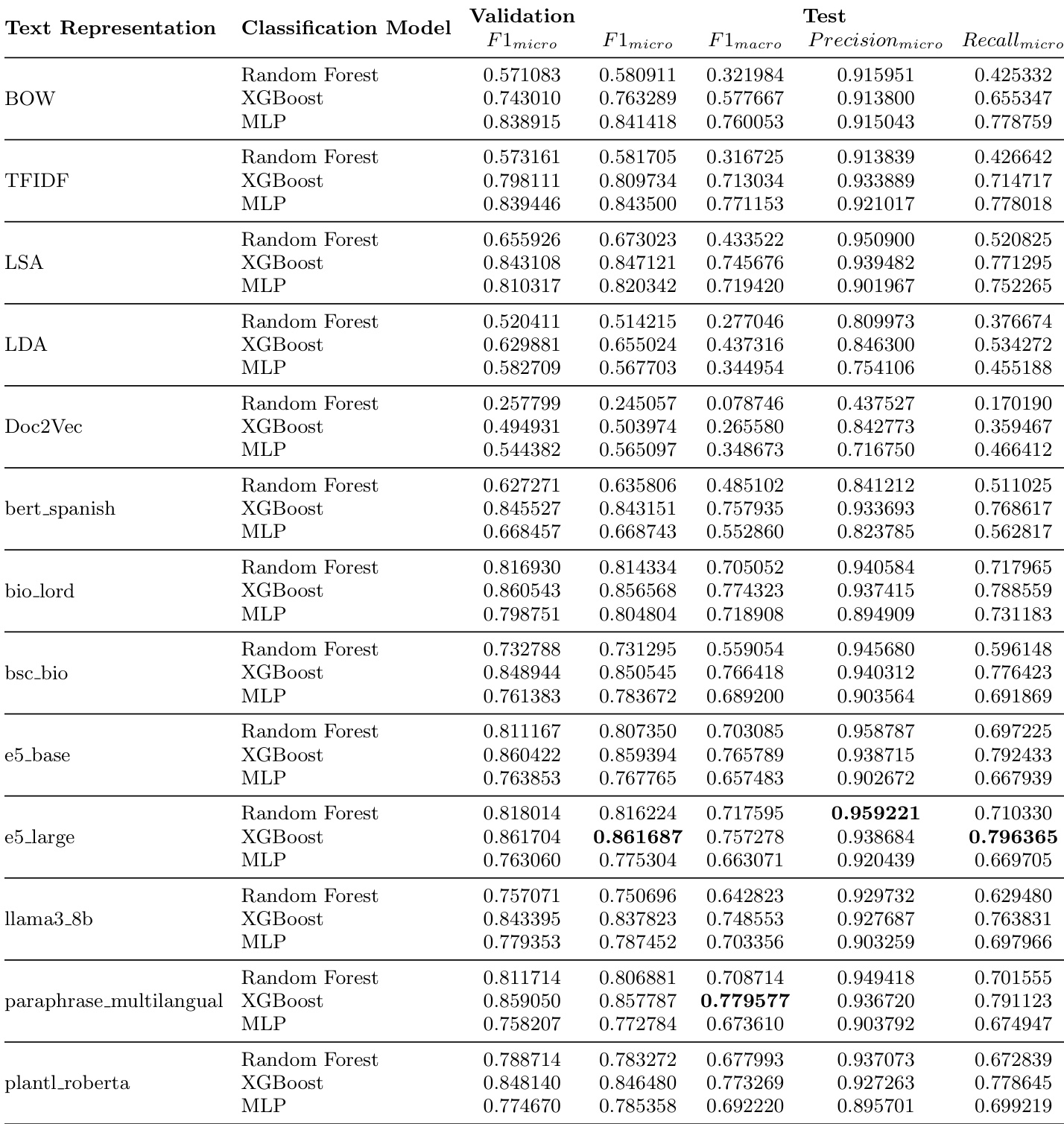
The authors present a comparative analysis of text representation and classification models for psychiatric diagnosis coding, focusing on the performance of transformer-based embeddings and various classifiers. Results show that fine-tuned large language model embeddings consistently outperform other methods, with XGBoost emerging as the most effective classifier for dense contextual features, while MLPs perform better with sparse keyword-based inputs. The study highlights the challenges of class imbalance and data scarcity, particularly for rare diagnoses, and demonstrates that model selection should be aligned with the representation type used. Fine-tuned large language model embeddings achieve the highest performance across all configurations. XGBoost is the most effective classifier for dense contextual embeddings, while MLPs excel with sparse keyword-based features. The performance gap between micro and macro F1 scores underscores the difficulty in classifying rare diagnostic codes due to data scarcity.
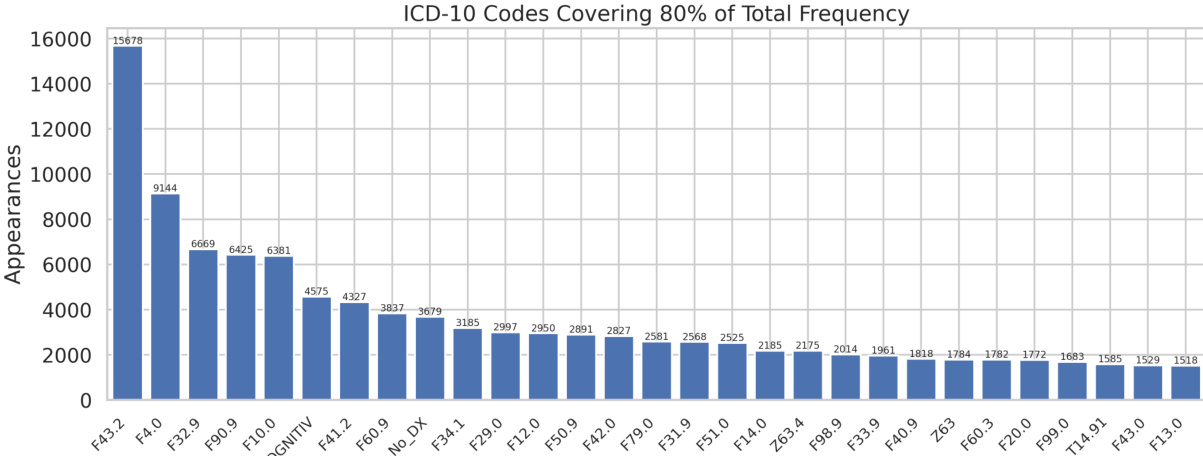
The authors analyze the distribution of ICD-10 codes in a psychiatric dataset, revealing a long-tail pattern where a small number of codes account for the majority of occurrences, while the vast majority have low frequency. This distribution presents a significant challenge for classification models, as the performance of the best-performing models varies considerably across different classes, with higher performance observed for more frequent codes and lower performance for rare ones. A small subset of ICD-10 codes accounts for the majority of occurrences in the dataset, while most codes have very low frequency. The long-tail distribution of codes leads to a significant disparity in model performance, with better results for more frequent classes and poorer results for rare ones. The performance of classification models is highly dependent on the frequency of the diagnostic code, with higher frequency codes achieving better precision and recall.
The authors compare various text representation techniques and classification models for psychiatric diagnosis coding, evaluating their performance using F1 scores and other metrics. Results show that transformer-based embeddings consistently outperform traditional methods, with XGBoost emerging as the best classifier for dense embeddings, while MLPs perform better with sparse features. Fine-tuning the best-performing model achieves the highest overall performance on test data. Transformer-based embeddings consistently outperform traditional text representation methods across all classification models. XGBoost achieves the highest performance with dense embeddings, while MLPs perform better with sparse keyword-based features. Fine-tuning the best-performing model leads to the highest test F1 scores, indicating improved performance through task-specific adaptation.
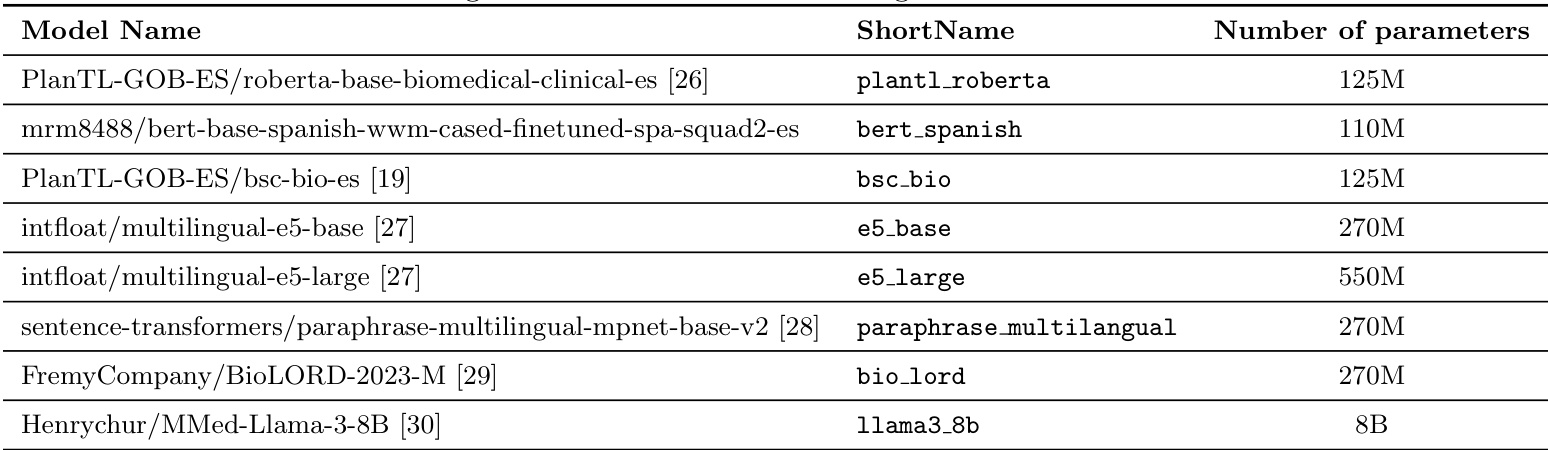
The authors compare various text representation models for psychiatric diagnosis coding, focusing on their parameter counts and suitability for clinical language. Results show that large language models with significantly more parameters consistently outperform smaller models and traditional methods, indicating that model scale is a key factor in capturing the semantic complexity of medical texts. Large language models with over 270 million parameters consistently outperform smaller models and traditional text representation techniques. The model with the highest parameter count achieves the best performance, suggesting that scale is critical for capturing complex clinical semantics. Models with fewer than 100 million parameters are less effective, highlighting the importance of model size in this domain.
The experiments evaluate various text representation techniques and classification algorithms for psychiatric diagnosis coding, demonstrating that fine-tuned large language models significantly outperform traditional methods by better capturing complex clinical semantics. Classifier effectiveness depends on embedding density, with XGBoost excelling on dense contextual features and neural networks performing better on sparse keyword inputs. Additionally, the analysis reveals that the long-tail distribution of diagnostic codes creates substantial performance disparities, highlighting data scarcity as a persistent challenge for rare conditions. Ultimately, the findings indicate that optimizing diagnostic coding accuracy requires aligning model scale and representation type with appropriate classifiers while accounting for inherent class imbalance.