Command Palette
Search for a command to run...
시청, 추론, 탐색: 에이전트형 비디오 추론을 위한 오픈 웹 기반 비디오 딥 리서치 벤치마크
시청, 추론, 탐색: 에이전트형 비디오 추론을 위한 오픈 웹 기반 비디오 딥 리서치 벤치마크
초록
실제 영상 질의응답 환경에서는 영상이 종종 국소적인 시각적 단서만 제공하지만, 검증 가능한 답변은 오픈 웹 전반에 분산되어 있다. 따라서 모델은 프레임 간 단서 추출, 반복적 검색, 다단계 추론 기반 검증을 종합적으로 수행할 수 있어야 한다. 이 격차를 메우기 위해 우리는 최초의 영상 기반 심층 탐색 벤치마크인 VideoDR을 구축하였다. VideoDR은 영상 조건부 오픈 도메인 영상 질의응답을 중심으로 하며, 프레임 간 시각적 앵커 추출, 상호작용식 웹 검색, 영상-웹 증거를 통합한 다단계 추론을 요구한다. 엄격한 인간 주석과 품질 관리 과정을 거쳐, 6개의 의미적 도메인을 아우르는 고품질의 영상 심층 탐색 샘플을 확보하였다. 우리는 워크플로우(WF) 및 에이전트(AG) 패러다임 하에서 여러 폐쇄형 및 개방형 멀티모달 대규모 언어 모델을 평가하였으며, 그 결과 AG가 WF보다 항상 우수한 것은 아님을 확인하였다. AG의 성능 향상은 모델이 긴 검색 체인에 걸쳐 초기 영상 앵커를 유지하는 능력에 따라 달라진다. 추가 분석을 통해 목표 편차(goal drift)와 장기 일관성(long-horizon consistency)이 핵심적 한계임이 드러났다. 결론적으로, VideoDR은 오픈 웹 환경에서 영상 에이전트를 체계적으로 연구할 수 있는 기반을 제공하며, 차세대 영상 심층 탐색 에이전트가 직면한 주요 과제를 명확히 드러낸다.
One-sentence Summary
The authors, from LZU, HKUST(GZ), UBC, FDU, PKU, USC, NUS, UCAS, HKUST, and QuantaAlpha, propose VideoDR, the first benchmark for video-conditioned open-domain question answering requiring cross-frame visual anchor extraction, interactive web retrieval, and multi-hop reasoning; it reveals that agentic models underperform workflows when failing to maintain long-horizon consistency, highlighting goal drift and evidence coherence as key challenges for next-generation video agents.
Key Contributions
- The paper introduces VideoDR, the first benchmark for video deep research, which formalizes open-domain video question answering that requires cross-frame visual anchor extraction, interactive web retrieval, and multi-hop reasoning over combined video–web evidence, addressing the gap between closed-context video understanding and real-world open-web fact verification.
- Through rigorous human annotation and quality control across six semantic domains, VideoDR ensures that answers depend on both dynamic visual cues from the video and verifiable evidence from the open web, making it a systematic testbed for evaluating multimodal agents in realistic research scenarios.
- Evaluation of leading multimodal large language models under Workflow and Agentic paradigms reveals that Agentic approaches are not consistently superior; performance hinges on maintaining initial video anchors over long retrieval chains, with goal drift and long-horizon consistency identified as the primary bottlenecks.
Introduction
The authors address a critical gap in multimodal AI evaluation by introducing VideoDR, the first benchmark for video deep research in open-web settings. In real-world scenarios, video content often provides only partial visual clues, while definitive answers reside in dynamic, external web sources—requiring models to jointly perform cross-frame visual anchoring, interactive web retrieval, and multi-hop reasoning over video-web evidence. Prior work falls short in this space: video benchmarks typically assume closed-evidence settings, while existing deep research benchmarks focus on text-based queries and treat visual input as secondary. The authors’ main contribution is the design of VideoDR, a rigorously annotated benchmark that enforces dependency on multi-frame video cues for evidence gathering, ensuring that answers cannot be derived from video or web alone. They evaluate both Workflow and Agentic paradigms across leading multimodal models, revealing that Agentic approaches do not consistently outperform Workflow, with performance heavily dependent on maintaining long-horizon consistency and avoiding goal drift—highlighting these as core challenges for future video reasoning agents.
Dataset

- The dataset, VideoDR, consists of 100 carefully curated video-question-answer triples created through a structured annotation process involving three expert annotators with experience in video understanding and web search.
- Video sources were drawn from diverse platforms, with stratified sampling across three dimensions: source, domain, and duration, to ensure broad real-world coverage.
- A strict negative filtering strategy removed: (1) single-scene, highly redundant clips; (2) popular topics easily answerable via text search; and (3) isolated web content lacking verifiable evidence chains.
- Initial filtering retained only videos with coherent, multi-frame visual cues suitable for cross-frame association; longer videos were segmented into semantically focused parts for independent annotation.
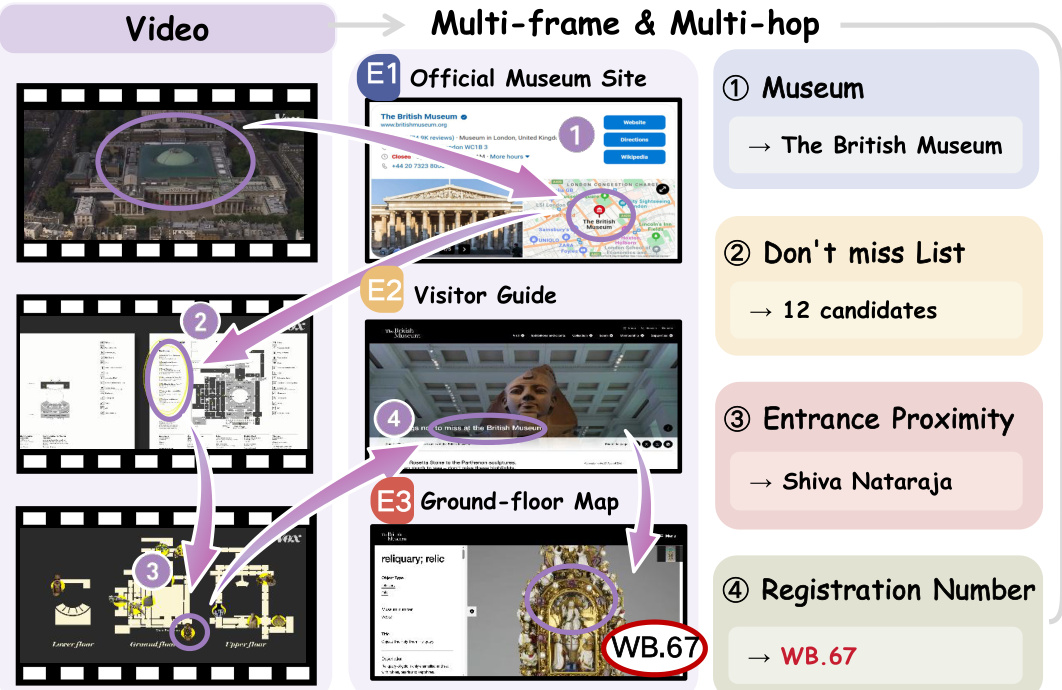
- Each question was designed under two key constraints: (1) multi-frame reasoning—requiring evidence from multiple frames, not a single screenshot; and (2) multi-hop reasoning—necessitating a decomposable reasoning path that links video perception to external web search.
- For verifiability, the web pages containing the key evidence supporting each answer were archived during annotation.
- The dataset spans six domains: Daily Life (33%), Economics (16%), Technology and Culture (15% each), History (11%), and Geography (10%), ensuring balanced coverage across open-domain topics.
- Question lengths average 25.54 tokens, with 95% of questions under 54 tokens, indicating concise yet information-rich phrasing that emphasizes reasoning over input complexity.
- Video durations follow a long-tailed distribution: most are short, but a small subset exceeds 10 minutes, enabling evaluation of both rapid cue detection and long-range cross-segment reasoning.
- The authors use the full dataset for training, with no explicit train/validation/test splits mentioned; the data is treated as a unified benchmark for evaluating multi-hop video reasoning.
- No cropping or frame sampling was applied during data construction—full video segments were used as-is, preserving temporal context.
- Metadata includes domain labels, video duration, question length, and evidence URLs, supporting stratified analysis and benchmark evaluation.
- While the final answers are objectively verifiable, the intermediate search queries and reasoning paths reflect the subjective strategies of the annotators, potentially limiting the diversity of real-world user behavior captured.
Method
The authors leverage a comprehensive data annotation pipeline designed to ensure high-quality, diverse, and semantically rich video-based reasoning samples. The process begins with the construction of a candidate video pool through stratified sampling across multiple domains, including Geography, History, Technology, Culture, Economy, and Daily Life. This ensures broad coverage of real-world scenarios. The initial candidate pool is then subjected to a preliminary filtering stage, where human annotators manually screen videos to retain only those suitable for further processing, discarding unsuitable ones based on relevance and quality.
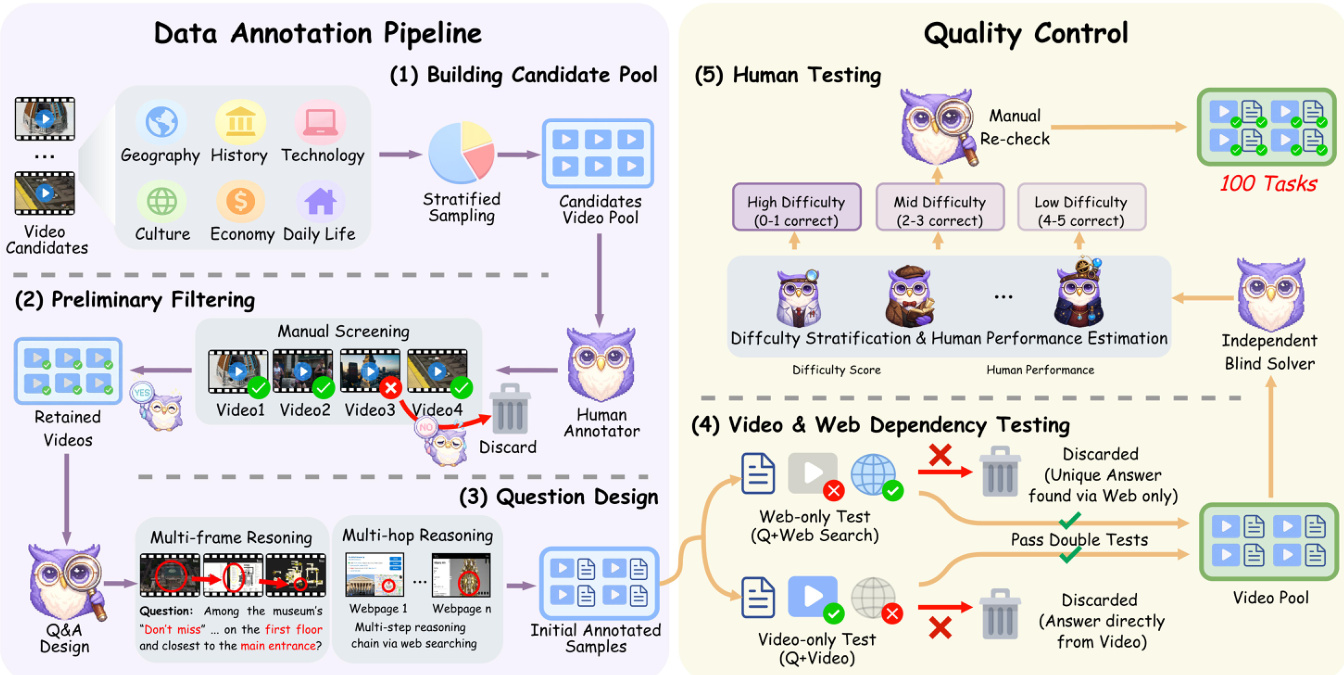
Following filtering, the pipeline proceeds to question design, where two distinct reasoning paradigms are employed: multi-frame reasoning and multi-hop reasoning. Multi-frame reasoning involves generating questions that require understanding temporal changes across multiple frames of a video, such as tracking an object’s movement or identifying a sequence of events. Multi-hop reasoning, on the other hand, requires integrating information from both the video and external web sources, such as official museum websites or visitor guides, to answer complex queries. This dual approach ensures that the resulting annotated samples support both video-centric and web-augmented reasoning.
To ensure the reliability and validity of the annotated data, a rigorous two-stage quality control process is applied. The first stage, Video & Web Dependency Testing, evaluates whether the answer to a question can be derived solely from the video or requires external web information. Videos that allow answers to be directly extracted without web assistance are discarded, while those requiring web-based reasoning are retained. This ensures that the dataset emphasizes multi-hop reasoning. The second stage, Human Testing, involves human annotators assessing the difficulty of each task and estimating human performance. Tasks are stratified into high, mid, and low difficulty levels based on the number of correct responses expected from human solvers, with thresholds of 0–1 correct, 2–3 correct, and 4–5 correct, respectively. This stratification enables the creation of a balanced dataset with varying levels of complexity. Additionally, a manual re-check is performed on a subset of 100 tasks to further validate the quality and consistency of annotations.
Experiment
- Video & Web Dependency Testing: Confirms that valid samples require both video and web evidence, with 100 samples retained after filtering out those solvable via video-only or web-only means.
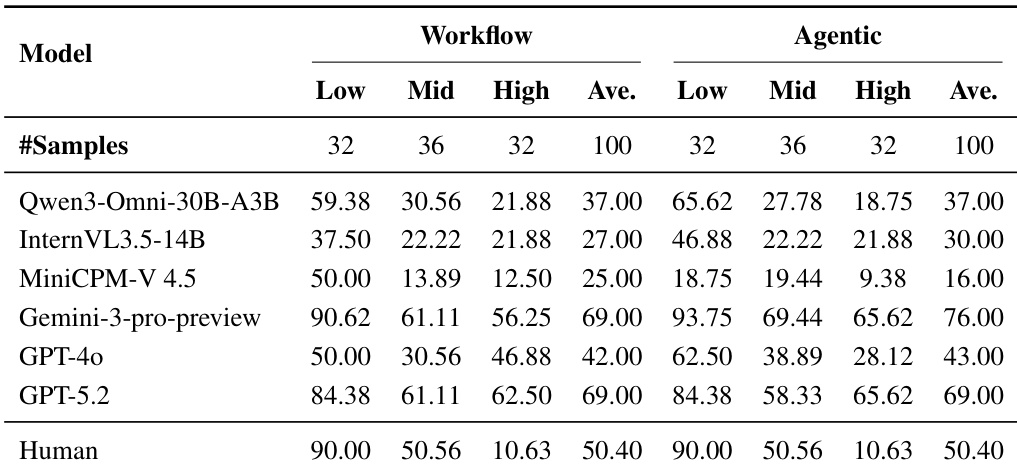
- Human Testing: Human participants achieve a mean success rate of 50.4% across all samples, with 90.0% on Low, 50.6% on Mid, and 10.6% on High difficulty, validating the difficulty stratification and annotation correctness.
- Main Results: Gemini-3-pro-preview leads under both Workflow (69%) and Agentic (76%) settings, with Agentic showing gains on Mid/High difficulty for strong models but causing degradation for mid-tier models like GPT-4o on High difficulty.
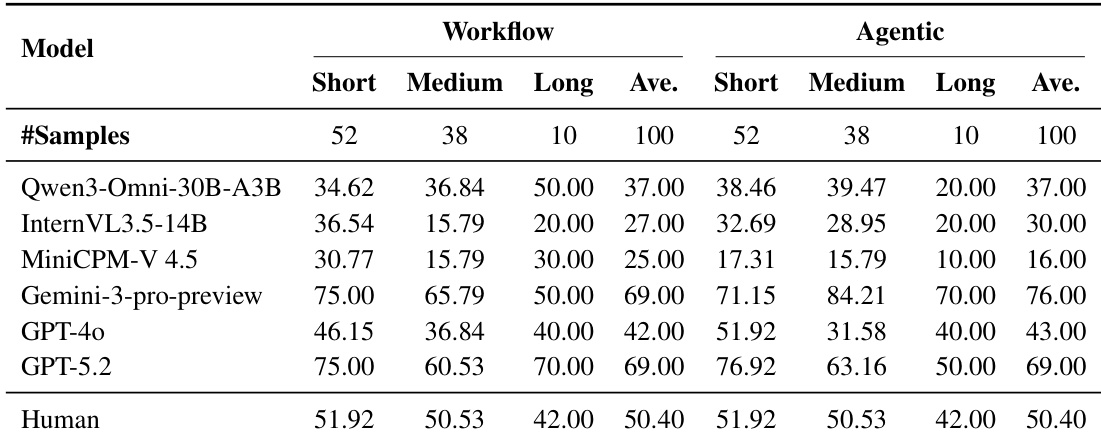
- Video-duration Stratification: Longer videos amplify the trade-off between paradigms—Agentic benefits strong models (e.g., Gemini-3-pro-preview improves from 50% to 70% on Long videos), while weaker models (e.g., Qwen3-Omni-30B-A3B) drop sharply (50% to 20%).
- Domain Stratification: Agentic outperforms Workflow in Technology (64.29% → 85.71%) but underperforms in Geography, indicating that stable visual anchors are critical for ambiguous domains.
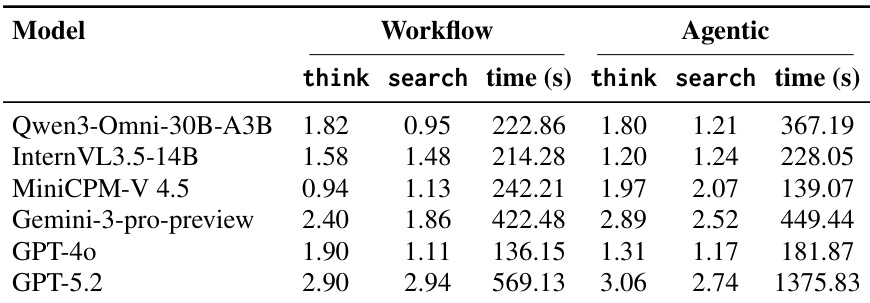
- Tool-use Analysis: Tool usage frequency does not correlate with accuracy; Gemini-3-pro-preview uses tools more effectively, while weaker models (e.g., MiniCPM-V 4.5) show increased tool use with reduced accuracy, indicating poor evidence filtering.
- Error Analysis: Categorical Error dominates across models, especially in Agentic, due to uncorrected early perception errors; numerical errors remain a persistent bottleneck across all models, with no significant improvement in Agentic.
The authors analyze error types across models and settings, showing that Categorical Error is the dominant failure mode, increasing for some models under the Agentic setting. This suggests that errors in initial visual perception propagate more easily when the model cannot revisit the video, leading to greater drift in downstream reasoning.
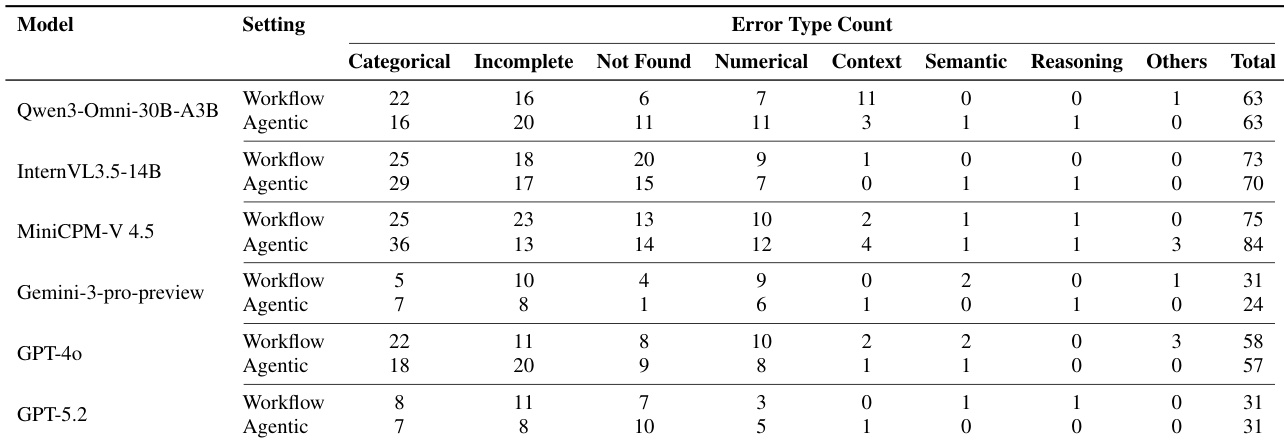
The authors analyze tool usage in the Workflow and Agentic paradigms, showing that higher numbers of tool calls do not necessarily lead to better performance. Gemini-3-pro-preview demonstrates more effective use of tools, achieving the highest accuracy with a balanced number of think and search calls, while other models either fail to improve or degrade in performance despite increased tool usage.
Results show that under the Workflow and Agentic paradigms, model performance varies significantly with video duration, with Gemini-3-pro-preview achieving the highest accuracy across all categories. The Agentic setting generally outperforms Workflow for longer videos, particularly for Gemini-3-pro-preview, which improves from 50.00% to 70.00% on Long videos, while open-source models like Qwen3-Omni-30B-A3B and MiniCPM-V 4.5 show substantial drops in accuracy on Long videos under Agentic.
The authors use a domain-specific performance comparison to evaluate models across different question categories under Workflow and Agentic settings. Results show that Gemini-3-pro-preview achieves the highest accuracy in most domains under both settings, with significant improvements in Technology (64.29%→85.71%) and consistent high performance across all domains, while other models exhibit varying strengths and weaknesses depending on the domain and paradigm.

Results show that the Agentic paradigm achieves higher performance than the Workflow paradigm for top models like Gemini-3-pro-preview and GPT-5.2, with accuracy improvements of 7% and 0% respectively, while lower-performing models such as Qwen3-Omni-30B-A3B and MiniCPM-V 4.5 show no gain or even degradation in the Agentic setting. Performance declines significantly with increasing difficulty across both paradigms, and human performance remains consistently higher than all models, especially on High-difficulty samples.