Command Palette
Search for a command to run...
GlimpRouter: 사고의 하나의 토큰을 스캔함으로써 효율적인 공동 추론 구현
GlimpRouter: 사고의 하나의 토큰을 스캔함으로써 효율적인 공동 추론 구현
Wenhao Zeng Xuteng Zhang Yuling Shi Chao Hu Yuting Chen Beijun Shen Xiaodong Gu
초록
대규모 추론 모델(LRMs)은 다단계 사고 체인을 명시적으로 생성함으로써 뛰어난 성능을 달성하지만, 이러한 능력은 상당한 추론 지연과 계산 비용을 수반한다. 공동 추론은 경량 모델과 대규모 모델 간에 작업을 선택적으로 분배함으로써 이 문제에 대한 유망한 해결책을 제시하지만, 근본적인 과제는 여전히 남아 있다. 즉, 어떤 추론 단계가 대규모 모델의 능력을 필요로 하는지, 아니면 경량 모델의 효율성을 활용할 수 있는지 판단하는 것이다. 기존의 라우팅 전략은 로컬 토큰 확률에 의존하거나 사후 검증(post-hoc verification)을 사용하는데, 이는 상당한 추론 오버헤드를 초래한다. 본 연구에서는 단계별 협업에 대한 새로운 관점을 제안한다. 추론 단계의 난이도는 그 첫 번째 토큰을 통해 추론할 수 있다. LRMs에서 관찰되는 '아하 순간'(Aha Moment) 현상에 착안하여, 우리는 초기 토큰의 엔트로피가 단계의 난이도를 강력한 예측자로 활용할 수 있음을 보여준다. 이러한 통찰을 기반으로, 학습이 필요 없는 단계별 협업 프레임워크인 GlimpRouter를 제안한다. GlimpRouter는 각 추론 단계의 첫 번째 토큰만 경량 모델이 생성하고, 초기 토큰의 엔트로피가 임계값을 초과할 경우에만 해당 단계를 대규모 모델로 라우팅한다. 다양한 벤치마크에서의 실험 결과, 본 방법은 정확도를 유지하면서 추론 지연을 크게 줄이는 것으로 나타났다. 예를 들어, AIME25 데이터셋에서 GlimpRouter는 독립적인 대규모 모델 대비 정확도는 10.7% 향상시키면서도 추론 지연을 25.9% 감소시켰다. 이러한 결과는 단순하면서도 효과적인 추론 메커니즘을 시사한다. 즉, 전체 단계를 평가하는 대신, 사고의 '한눈에 담는 순간'(glimpse of thought)을 기반으로 계산 자원을 할당하는 방식이 가능함을 보여준다.
One-sentence Summary
The authors from Shanghai Jiao Tong University propose GlimpRouter, a training-free framework that uses initial token entropy to predict reasoning step difficulty, enabling lightweight models to route complex steps to larger models with minimal overhead; this approach reduces inference latency by 25.9% while improving accuracy by 10.7% on AIME25, demonstrating efficient, glimpse-based collaboration for large reasoning models.
Key Contributions
- Large reasoning models (LRMs) achieve high accuracy through multi-step reasoning but suffer from high inference latency and computational cost, motivating the need for efficient collaborative inference strategies that intelligently allocate tasks between lightweight and large models.
- The authors introduce GlimpRouter, a training-free framework that predicts reasoning step difficulty by analyzing the entropy of the first token generated, leveraging the "Aha Moment" phenomenon to route steps to larger models only when initial uncertainty exceeds a threshold.
- Experiments on benchmarks including AIME25, GPQA, and LiveCodeBench show GlimpRouter reduces inference latency by 25.9% while improving accuracy by 10.7% over standalone large models, demonstrating a strong efficiency-accuracy trade-off.
Introduction
Large reasoning models (LRMs) achieve strong performance on complex tasks by generating multi-step chains of thought, but this comes at the cost of high inference latency and computational expense. Collaborative inference—where lightweight and large models work together—offers a way to reduce this cost, yet existing methods struggle with inefficiencies: token-level strategies rely on fine-grained, repetitive verification, while step-level approaches often require full-step evaluation or post-hoc validation, introducing significant overhead. The authors identify a key insight: the difficulty of a reasoning step can be predicted early, based on the entropy of its first token. Drawing from the "Aha Moment" phenomenon, they show that initial token uncertainty strongly correlates with step complexity—low entropy signals routine steps suitable for small models, while high entropy indicates a need for larger models. Building on this, they propose GlimpRouter, a training-free, step-wise collaboration framework that uses a lightweight model to generate only the first token of each step and routes the step to a large model only when the initial token’s entropy exceeds a threshold. This approach enables efficient, real-time decision-making with minimal overhead. Experiments show GlimpRouter reduces inference latency by 25.9% and improves accuracy by 10.7% on AIME25 compared to a standalone large model, demonstrating a practical, scalable path to efficient reasoning.
Method
The authors leverage a collaborative inference framework that orchestrates a large, high-capacity reasoning model (LLM) and a small, computationally efficient model (SLM) to accelerate reasoning while preserving solution quality. The framework operates on a step-wise basis, decomposing the reasoning process T={s1,…,sK} into individual steps, each conditioned on the preceding context ck. The core of the system, GlimpRouter, is a training-free, step-aware strategy that dynamically routes each reasoning step to either the SLM or the LLM based on a single, low-cost probe. This "Probe-then-Dispatch" mechanism is designed to minimize inference latency by offloading routine steps to the SLM while reserving the LLM for complex, high-uncertainty steps.
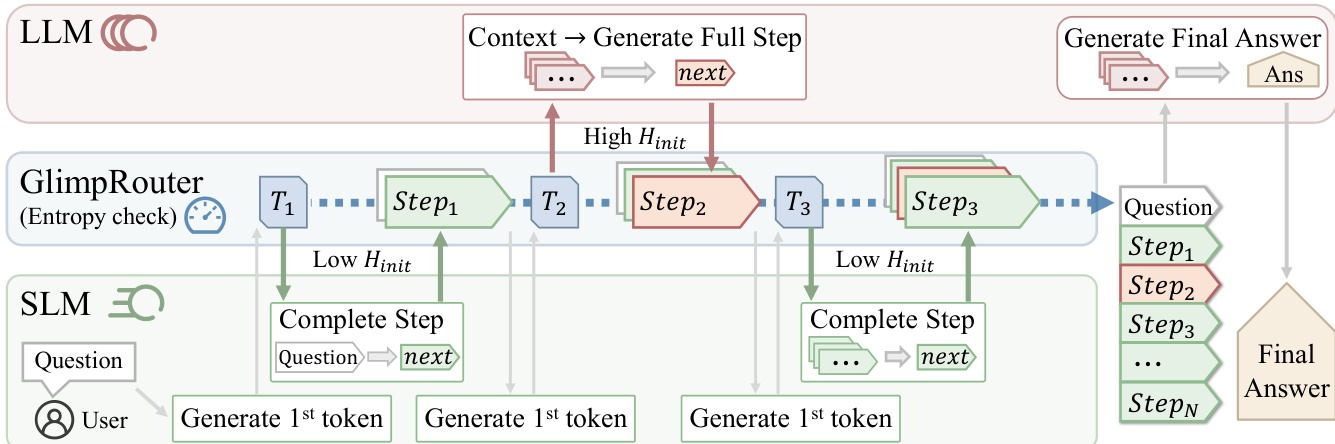
As shown in the figure below, the system begins with a user-provided question. At the start of each reasoning step k, the SLM is invoked to generate only the first token of the step, conditioned on the context ck. This initial token generation is a minimal operation, incurring a computational cost equivalent to decoding a single token. The probability distribution over the vocabulary for this first token is used to compute the initial token entropy, Hinit(sk), which serves as a proxy for the cognitive uncertainty or difficulty of the upcoming step. This entropy value is then evaluated against a predefined threshold τ to make a routing decision. If Hinit(sk)≤τ, the step is classified as routine, and the SLM is responsible for generating the remainder of the step tokens. Conversely, if Hinit(sk)>τ, the step is deemed complex, and the context is handed over to the LLM to generate the full step. The final answer is always generated by the LLM to ensure correctness. This design ensures that the high computational cost of the LLM is only incurred for steps that require its superior reasoning capabilities, while the SLM handles the majority of routine steps, leading to significant efficiency gains. The framework's step-level granularity allows it to be combined with other acceleration techniques, such as speculative decoding, for further performance improvements.
Experiment
- GlimpRouter validates that initial token entropy (Hinit) serves as a high-sensitivity discriminator for reasoning step difficulty, exhibiting a bimodal distribution that clearly separates routine and complex steps, unlike PPLstep, Hstep, and LLM-as-a-Judge, which suffer from signal dilution or saturation.
- On AIME24, AIME25, GPQA-Diamond, and LiveCodeBench, GlimpRouter achieves superior efficiency-performance trade-offs, with GlimpRouter using Qwen3-4B (SLM) and DeepSeek-R1-Distill-Qwen-32B (LLM) surpassing the standalone LLM in accuracy (e.g., 51.67% on AIME25 vs. 46.67%) while reducing latency by 25.2%–27.4%.
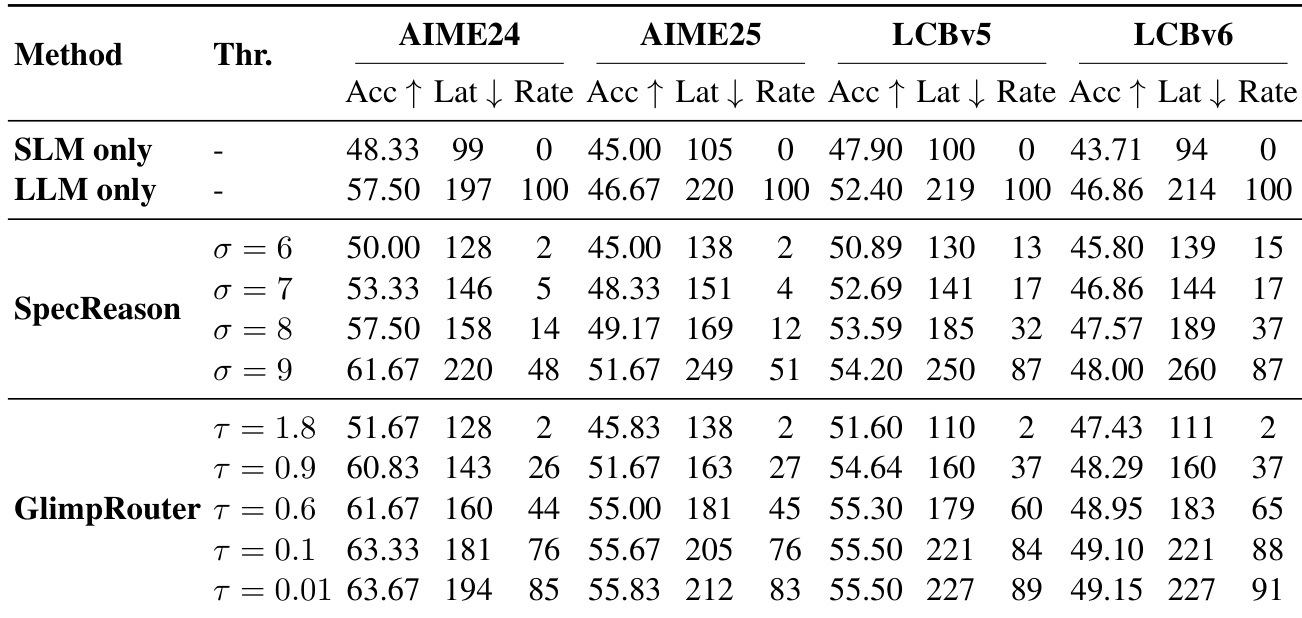
- GlimpRouter outperforms reactive baselines (RSD, SpecCoT, SpecReason) by leveraging a "Probe-then-Dispatch" mechanism based on Hinit, avoiding the sunk cost of full-step generation; for example, SpecReason’s latency exceeds the standalone LLM on GPQA (213s vs. 176s), while GlimpRouter maintains lower latency.
- Ablation studies confirm Hinit significantly outperforms step-wise metrics (Hstep, PPLstep), achieving 10.7% relative accuracy gain on AIME25 and lower latency due to proactive routing.
- GlimpRouter demonstrates orthogonality with speculative decoding, achieving the lowest end-to-end latency across benchmarks when combined, due to compound speedup from coarse-grained routing and fine-grained token-level acceleration.
- Case studies illustrate that high Hinit correlates with cognitive pivots (e.g., solution planning), and LLM intervention enables self-correction of logical errors, improving reasoning fidelity beyond mere text continuation.
Results show that GlimpRouter achieves a superior efficiency-performance trade-off compared to SpecReason across all benchmarks, consistently outperforming it in accuracy while reducing latency. The method's "Probe-then-Dispatch" mechanism, which routes steps based on initial token entropy, avoids the sunk cost of generating full steps before verification, leading to lower latency and higher accuracy than reactive baselines.
The authors use GlimpRouter to compare its performance against variants that employ step-wise entropy and step-wise perplexity for routing decisions. Results show that GlimpRouter consistently achieves higher accuracy and lower latency across all benchmarks, demonstrating the superiority of initial token entropy over metrics that average uncertainty over entire reasoning steps.
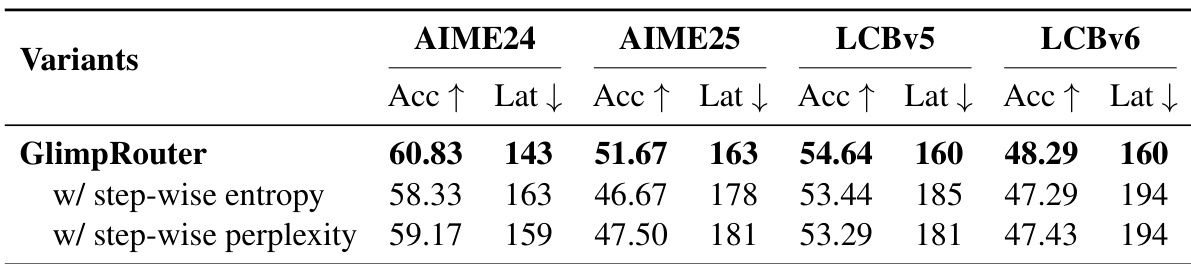
Results show that GlimpRouter using initial token entropy achieves the highest accuracy and lowest latency compared to variants using step-wise entropy or perplexity. The superior performance demonstrates that initial token entropy provides a more effective and efficient signal for routing decisions than metrics that average uncertainty over the entire reasoning step.

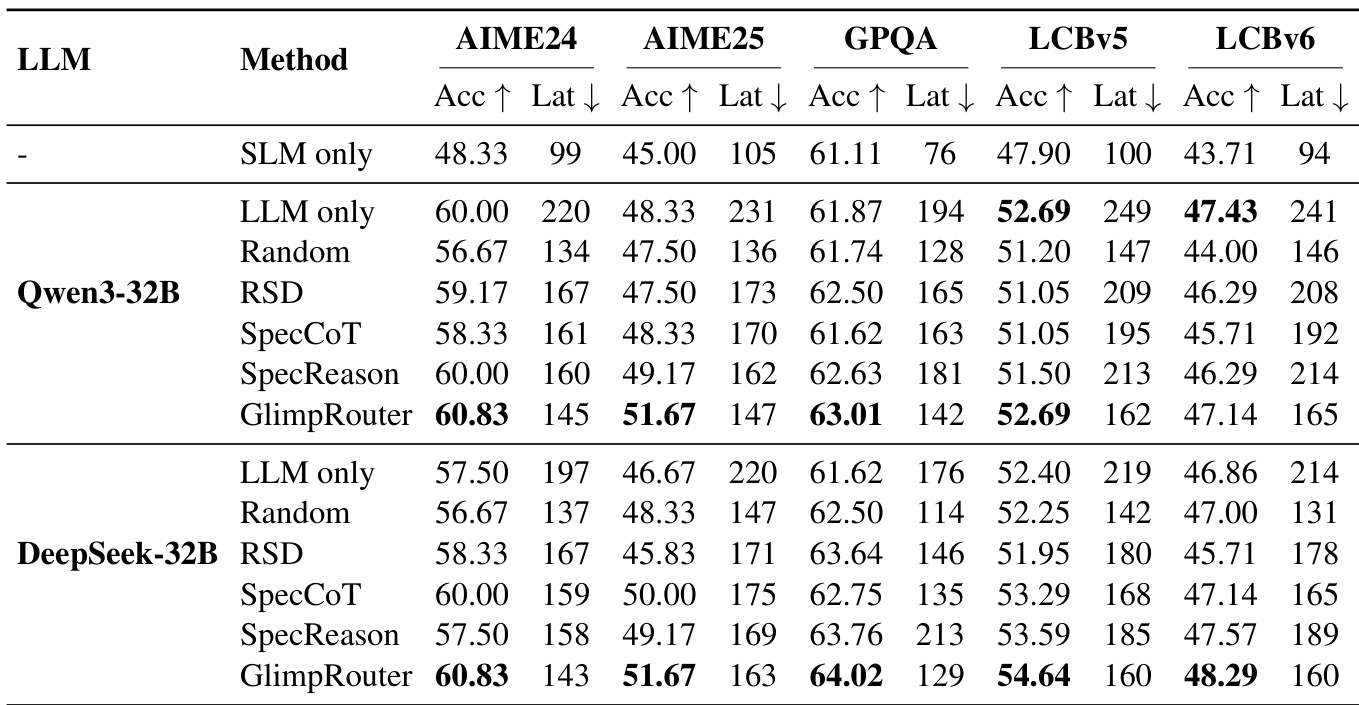
Results show that GlimpRouter achieves higher accuracy and lower latency compared to both standalone models and collaborative baselines across multiple benchmarks. When combined with speculative decoding, GlimpRouter further reduces latency while maintaining superior performance, demonstrating its efficiency and scalability.
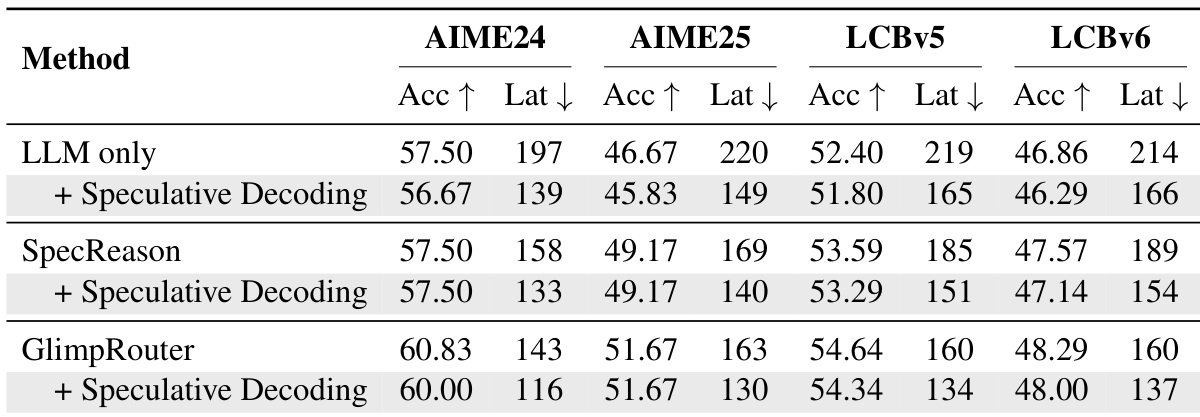
The authors use GlimpRouter to dynamically route reasoning steps between a small model (SLM) and a large model (LLM) based on the initial token entropy Hinit. Results show that GlimpRouter achieves the best trade-off between accuracy and latency across all benchmarks, outperforming both standalone models and existing collaborative methods by significantly reducing latency while maintaining or improving accuracy.