Command Palette
Search for a command to run...
스케일러블 룩업을 통한 조건부 메모리: 대규모 언어 모델을 위한 새로운 희소성 축
스케일러블 룩업을 통한 조건부 메모리: 대규모 언어 모델을 위한 새로운 희소성 축
초록
Mixture-of-Experts(MoE)는 조건부 계산을 통해 확장성을 실현하지만, Transformer는 지식 검색을 위한 내재적 원시 기능을 갖추고 있지 않아, 계산을 통해 검색을 비효율적으로 시뮬레이션해야 한다. 이를 해결하기 위해 우리는 조건부 메모리(condition memory)를 도입하며, 이는 MoE의 스파스성과 보완되는 새로운 스파스 축으로서, O(1) 탐색이 가능한 Engram이라는 모듈을 통해 구현된다. Engram은 고전적인 N-gram 임베딩을 현대화한 것으로, 정적 메모리로서의 역할을 수행한다. 우리는 스파스성 할당 문제를 체계적으로 정의함으로써, 신경망 계산(MoE)과 정적 메모리(Engram) 사이의 트레이드오프를 최적화하는 U자형 규모 법칙을 발견하였다.이 법칙을 기반으로 Engram을 270억 파라미터 규모로 확장하였으며, 동일한 파라미터 수 및 동일한 FLOPs 기준의 순수 MoE 기준 모델보다 우수한 성능을 달성하였다. 특히, 메모리 모듈이 지식 검색에 기여할 것으로 예상되었지만(예: MMLU +3.4점, CMMLU +4.0점), 일반적 추론 능력에서는 더욱 큰 성과를 보였다(예: BBH +5.0점, ARC-Challenge +3.7점), 또한 코드 및 수학 영역에서도 뚜렷한 향상이 나타났다(예: HumanEval +3.0점, MATH +2.4점). 기계적 분석 결과, Engram은 백본의 초기 레이어가 정적 재구성 작업에서 해방되며, 복잡한 추론을 위한 네트워크의 깊이를 효과적으로 증가시킨다는 점이 밝혀졌다. 더불어 국소적 의존성을 탐색 연산으로 위임함으로써, 어텐션 메커니즘의 전역적 컨텍스트 처리 능력을 확보하여 장거리 컨텍스트 검색 성능을 크게 향상시켰다(예: Multi-Query NIAH: 84.2 → 97.0). 마지막으로, Engram은 인프라 인식 효율성(infrastructure-aware efficiency)을 구현한다. 결정론적 주소 지정 방식을 통해 호스트 메모리에서 런타임 시 프리페치(prefetching)가 가능하며, 이로 인한 오버헤드는 거의 무시할 수 있다. 우리는 조건부 메모리가 차세대 스파스 모델에 필수적인 모델링 원시 요소가 될 것이라고 기대한다. 코드는 다음에서 공개된다: https://github.com/deepseek-ai/Engram
One-Sentence Summary
Researchers from Peking University and DeepSeek-AI introduce Engram, a scalable conditional memory module with O(1) lookup that complements MoE by offloading static knowledge retrieval, freeing early Transformer layers for deeper reasoning and delivering consistent gains across reasoning (BBH +5.0, ARC-Challenge +3.7), code and math (HumanEval +3.0, MATH +2.4), and long-context tasks (Multi-Query NIAH: 84.2 → 97.0), while maintaining iso-parameter and iso-FLOPs efficiency.
Key Contributions
-
Conditional memory as a new sparsity axis. The paper introduces conditional memory as a complement to MoE, realized via Engram—a modernized N-gram embedding module enabling O(1) retrieval of static patterns and reducing reliance on neural computation for knowledge reconstruction.
-
Principled scaling via sparsity allocation. Guided by a U-shaped scaling law from the Sparsity Allocation problem, Engram is scaled to 27B parameters and surpasses iso-parameter and iso-FLOPs MoE baselines on MMLU (+3.4), BBH (+5.0), HumanEval (+3.0), and Multi-Query NIAH (84.2 → 97.0).
-
Mechanistic and systems insights. Analysis shows Engram increases effective network depth by offloading static reconstruction from early layers and reallocating attention to global context, improving long-context retrieval while enabling infrastructure-aware efficiency through decoupled storage and compute.
Introduction
Transformers often simulate knowledge retrieval through expensive computation, wasting early-layer capacity on reconstructing static patterns such as named entities or formulaic expressions. Prior approaches either treat N-gram lookups as external augmentations or embed them only at the input layer, limiting their usefulness in sparse, compute-optimized architectures like MoE.
The authors propose Engram, a conditional memory module that modernizes N-gram embeddings for constant-time lookup and injects them into deeper layers of the network to complement MoE. By formulating a Sparsity Allocation problem, they uncover a U-shaped scaling law that guides how parameters should be divided between computation (MoE) and memory (Engram). Scaling Engram to 27B parameters yields strong gains not only on knowledge benchmarks, but also on reasoning, coding, and math tasks.
Mechanistic analyses further show that Engram frees early layers for higher-level reasoning and substantially improves long-context modeling. Thanks to deterministic addressing, its memory can be offloaded to host storage with minimal overhead, making it practical at very large scales.
Method
Engram augments a Transformer by structurally decoupling static pattern storage from dynamic computation. It operates in two phases—retrieval and fusion—applied at every token position.
Engram is inserted between the token embedding layer and the attention block, and its output is added through a residual connection before MoE.
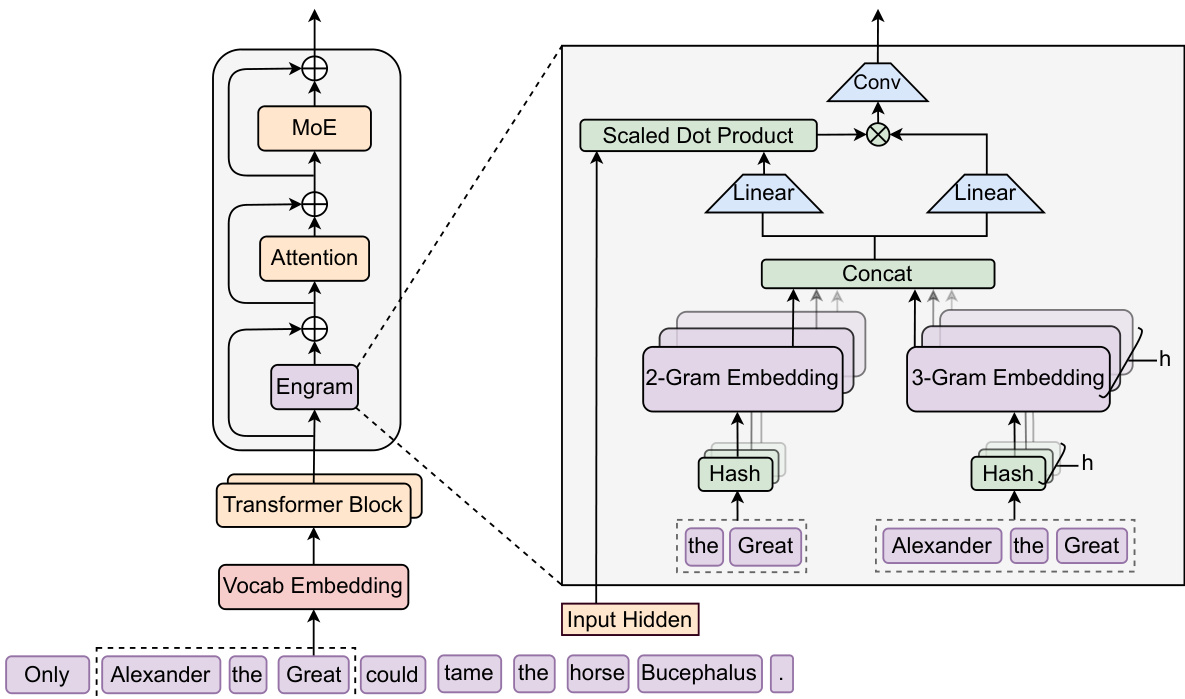
Retrieval Phase
-
Canonicalization.
Tokens are mapped to canonical IDs using a vocabulary projection layer P (e.g., NFKC normalization and lowercasing), reducing effective vocabulary size by 23% for a 128k tokenizer. -
N-gram construction.
For each position t, suffix N-grams gt,n are formed from canonical IDs. -
Multi-head hashing.
To avoid parameterizing the full combinatorial N-gram space, the model uses K hash functions varphin,k to map each N-gram into a prime-sized embedding table En,k, retrieving embeddings et,n,k. -
Concatenation.
The final memory vector is
Fusion Phase
The static memory vector et is modulated by the current hidden state ht:
kt=WKet,vt=WVet.A scalar gate controls the contribution:
αt=σ(dRMSNorm(ht)⊤RMSNorm(kt)).The gated value v~t=αt⋅vt is refined using a depthwise causal convolution:
Y=SiLU(Conv1D(RMSNorm(V~)))+V~.This output is added back to the hidden state before attention and MoE layers.
Multi-branch Parameter Sharing
For architectures with multiple branches:
- Embedding tables and WV are shared.
- Each branch (m) has its own WK(m):
Outputs are fused into a single dense FP8 matrix multiplication for GPU efficiency.
System Design
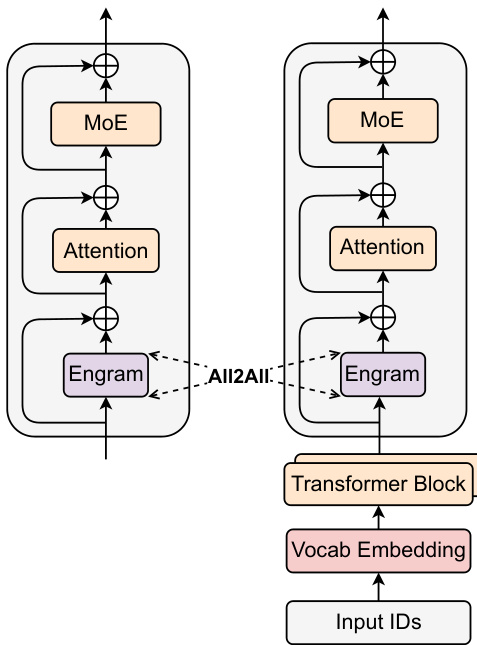
Training
Embedding tables are sharded across GPUs. Active rows are retrieved using All-to-All communication, enabling linear scaling of memory capacity with the number of accelerators.
Inference
Deterministic addressing allows embeddings to be offloaded to host memory:
- Asynchronous PCIe prefetch overlaps memory access with computation.
- A multi-level cache exploits the Zipfian distribution of N-grams.
- Frequent patterns remain on fast memory; rare ones reside on high-capacity storage.
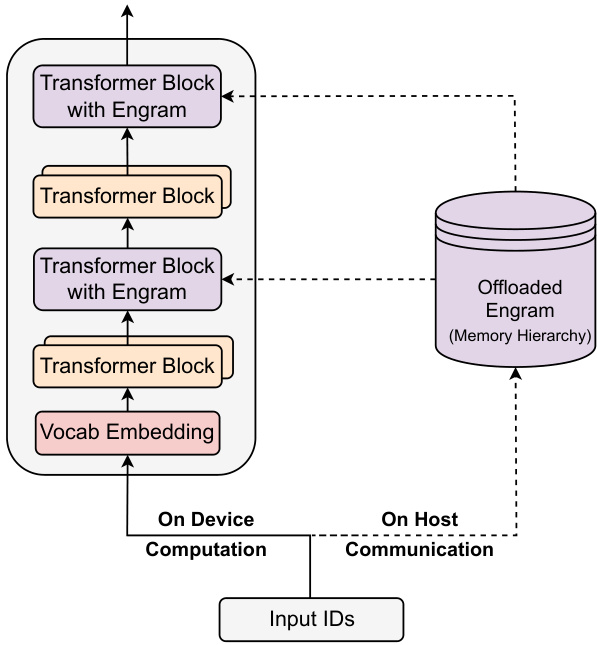
This design enables massive memory capacity with negligible impact on effective latency.
Experiments
Parameter Allocation
Under compute-matched settings, allocating 75–80% of sparse parameters to MoE and the remainder to Engram yields optimal results, outperforming pure MoE baselines:
- Validation loss at 10B scale: 1.7109 (Engram) vs. 1.7248 (MoE).
Scaling Engram’s memory under fixed compute produces consistent power-law improvements and outperforms OverEncoding.
Benchmark Performance
Engram-27B (26.7B parameters) surpasses MoE-27B under identical FLOPs:
- BBH: +5.0
- HumanEval: +3.0
- MMLU: +3.0
Scaling to Engram-40B further reduces pre-training loss to 1.610 and improves most benchmarks.
All sparse models (MoE and Engram) substantially outperform a dense 4B baseline under iso-FLOPs.

Long-Context Evaluation
Engram-27B consistently outperforms MoE-27B on LongPPL and RULER benchmarks:
- Best performance on Multi-Query NIAH and Variable Tracking.
- At 41k steps (82% of MoE FLOPs), Engram already matches or exceeds MoE.

Inference Throughput with Memory Offload
Offloading a 100B-parameter Engram layer to CPU memory incurs minimal slowdown:
- 4B model: 9,031 → 8,858 tok/s
- 8B model: 6,316 → 6,140 tok/s (2.8% drop)
Deterministic access enables effective prefetching, masking PCIe latency.

Conclusion
Engram introduces conditional memory as a first-class sparsity mechanism, complementing MoE by separating static knowledge storage from dynamic computation. It delivers:
- Strong gains in reasoning, coding, math, and long-context retrieval.
- Better utilization of early Transformer layers.
- Scalable, infrastructure-friendly memory via deterministic access and offloading.
Together, these results suggest that future large language models should treat memory and computation as independently scalable resources, rather than forcing all knowledge into neural weights.