Command Palette
Search for a command to run...
카리카처GS: 가우시안 곡률을 이용한 3D 가우시안 스플래터링 얼굴의 과장
카리카처GS: 가우시안 곡률을 이용한 3D 가우시안 스플래터링 얼굴의 과장
Eldad Matmon Amit Bracha Noam Rotstein Ron Kimmel
초록
얼굴에 대한 사진처럼 사실감 있고 조작 가능한 3차원 카리커처화 프레임워크를 제안한다. 본 연구는 본질적인 가우시안 곡률 기반의 표면 왜곡 기법에서 시작하며, 이 기법은 텍스처와 결합될 경우 과도하게 매끄러운 렌더링을 유도하는 경향이 있다. 이를 해결하기 위해 최근 자유 시점 아바타 생성에 효과적인 3D 가우시안 스플래팅(3DGS) 기법을 활용한다. 다중 시점 영상 시퀀스를 기반으로 FLAME 메시를 추출하고, 곡률 가중 치르누스 방정식을 해결하여 왜곡된 형태를 도출한다. 그러나 가우시안을 직접 왜곡하면 불량한 결과가 발생하므로, 각 프레임을 지역적 아핀 변환을 통해 왜곡된 2차원 표현으로 왜곡함으로써 가짜 지표 카리커처 이미지를 합성한다. 이후 실제 데이터와 합성 데이터를 번갈아 사용하는 학습 전략을 제안하여, 하나의 가우시안 집합이 자연스러운 아바타와 왜곡된 아바타를 모두 표현할 수 있도록 한다. 이 학습 전략은 높은 정확도를 보장하고, 국소적 편집이 가능하며, 카리커처의 강도를 연속적으로 조절할 수 있는 장점을 제공한다. 실시간 왜곡을 달성하기 위해 원본과 왜곡된 표면 사이의 효율적인 보간 기법을 도입하였으며, 이 방법이 해석적 해(solution)로부터 유한한 편차를 갖는다는 점을 분석하고 입증하였다. 정량적 및 정성적 평가 모두에서 기존의 방법들을 능가하는 결과를 도출하며, 기하학적 제어가 가능한 사진처럼 사실감 있는 카리커처 아바타를 제공한다.
One-sentence Summary
The authors from Technion – Israel Institute of Technology propose a photorealistic 3D caricaturization framework using 3D Gaussian Splatting with a curvature-weighted Poisson deformation and alternating real-synthetic supervision, enabling controllable, high-fidelity caricature avatars with real-time interpolation and local editability, outperforming prior methods in both geometry control and visual realism.
Key Contributions
- The paper addresses the challenge of generating photorealistic 3D caricature avatars by combining intrinsic Gaussian curvature-based surface exaggeration with 3D Gaussian Splatting (3DGS), overcoming the over-smoothing issue that arises when applying traditional geometric exaggeration to textured 3D meshes.
- It introduces a novel training scheme that alternates between real multiview images and pseudo-ground-truth caricature images, synthesized via per-triangle local affine transformations, enabling a single Gaussian set to represent both natural and exaggerated facial appearances with high fidelity.
- The method supports real-time, continuous control over caricature intensity through efficient interpolation between original and exaggerated surfaces, and demonstrates superior performance in both quantitative metrics and qualitative evaluations compared to prior approaches.
Introduction
The authors leverage 3D Gaussian Splatting (3DGS) for creating photorealistic caricature avatars by combining curvature-driven geometric deformation with a mesh-rigged 3DGS representation. This approach addresses a key limitation in prior work—where most methods either focused on photorealistic rendering without exaggeration or applied caricature effects only to appearance, leaving geometry unchanged. By using per-triangle Local Affine Transforms (LAT) to warp a neutral FLAME mesh into a caricatured version, they generate pseudo-ground-truth image pairs that guide joint optimization of both neutral and exaggerated views. The main contribution is a unified framework where a single set of 3D Gaussians learns to render both natural and exaggerated appearances while preserving identity and expression, enabling controllable, geometry-aware caricatures that remain photorealistic under large deformations.
Dataset

- The dataset is NeRSemble [20], a multi-view facial performance dataset captured using 16 synchronized high-resolution cameras arranged spatially around the subject.
- It includes 10 scripted sequences: 4 emotion-driven (EMO) and 6 expression-driven (EXP), plus one additional free self-reenactment sequence.
- The authors adopt the same train/validation/test split as in [21], ensuring consistency for fair comparison, with a training schedule of 120,000 iterations.
- Data is processed to support multi-view rendering and facial animation modeling, with no explicit cropping mentioned, but the original high-resolution camera captures are used as input.
- Metadata for each sequence is constructed based on the script type (EMO or EXP) and performance context, enabling controlled training and evaluation.
- The dataset is used in a mixture of training ratios aligned with the original sequence types, with the full set of sequences contributing to model training and validation.
Method
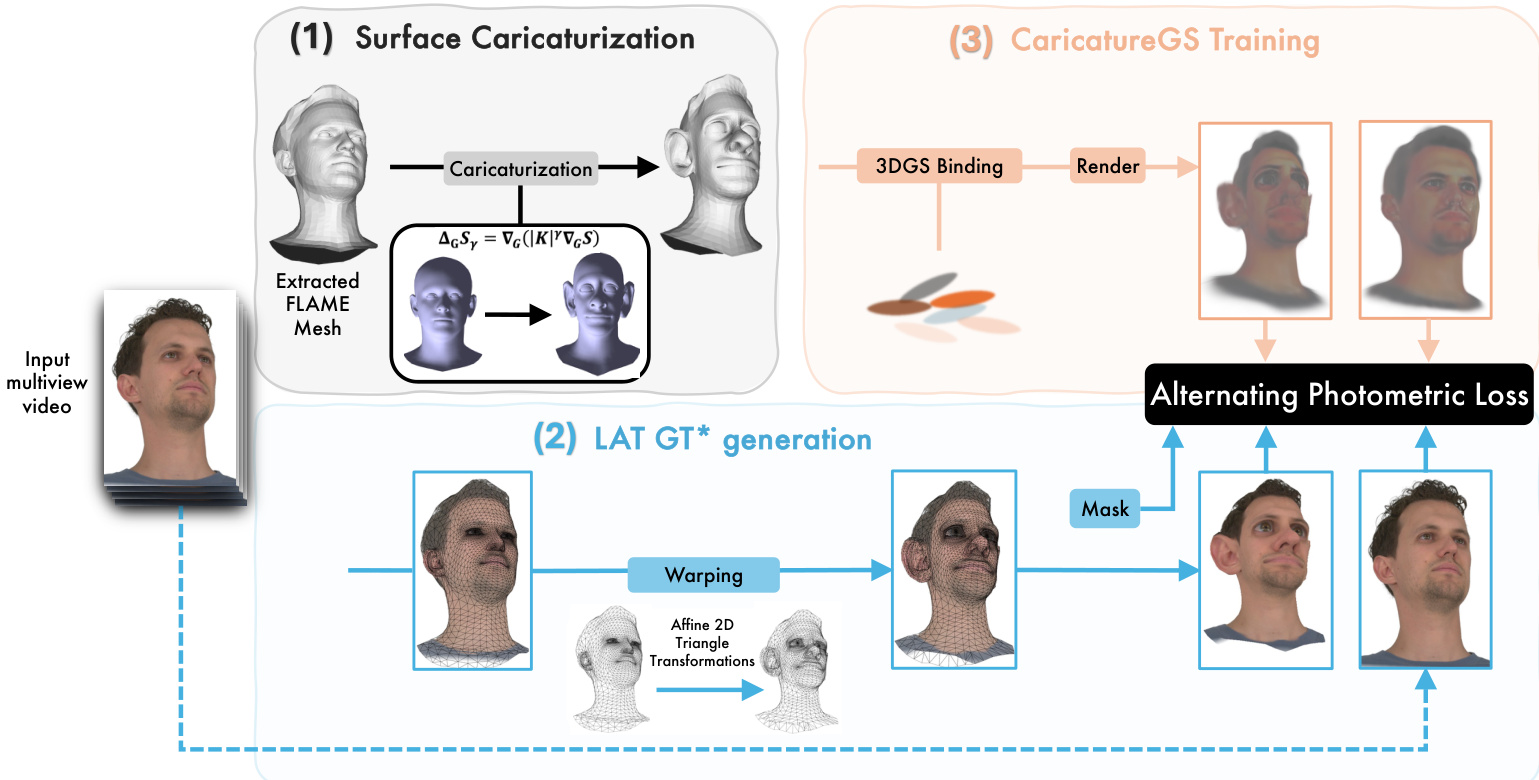
The proposed framework for photorealistic and controllable 3D caricaturization leverages a multi-stage pipeline that integrates geometric deformation, pseudo-ground-truth generation, and a specialized training scheme for 3D Gaussian Splatting (3DGS). The overall architecture, illustrated in the figure below, begins with an input multiview video, from which a temporally consistent FLAME mesh is extracted. This mesh serves as the foundation for the subsequent steps.
The first stage, surface caricaturization, applies a curvature-driven deformation to the extracted FLAME mesh. This process is formulated as a weighted Poisson equation on the surface, where the weights are defined by the Gaussian curvature K(p) raised to a power γ, i.e., w(γ)=∣K∣γ. This formulation allows for the exaggeration of facial features based on their intrinsic curvature, with higher curvature regions being amplified more. The solution to this equation, Sγ, is obtained by solving a discrete least-squares problem using the Laplace-Beltrami operator. To enable localized control, the method also supports constrained deformation by imposing boundary conditions on specific vertices, allowing for targeted exaggerations.
The second stage generates pseudo-ground-truth caricature images (GT*) to supervise the 3DGS training. Since real caricature images are unavailable, the authors synthesize GT* by warping the original input frames. This is achieved through Local Affine Transformations (LAT), which exploit the per-triangle correspondence between the original and deformed meshes. For each triangle in the deformed mesh, a unique affine map is computed to warp the corresponding pixels from the original image. To handle occlusions and ensure robustness, a 2D triangle-level mask is generated to identify unreliable regions, and a spatial mask is applied to freeze the parameters of Gaussians corresponding to areas like hair, which are difficult to warp reliably.
The third stage, CaricatureGS Training, involves optimizing a single set of 3D Gaussian primitives. These Gaussians are rigged to the original FLAME mesh, and their attributes (position, scale, rotation, opacity, and color) are updated based on a photometric loss. The key innovation is an alternating training scheme that stochastically switches between real input frames and the synthesized GT* images. This joint optimization allows the Gaussian set to learn both natural and caricatured appearances simultaneously. The use of masks during GT* steps prevents the propagation of artifacts from unreliable warping, while the real frames provide essential supervision to fill in occluded regions and preserve fine details like hair. This shared representation enables the model to generalize across a continuous range of caricature intensities.
Experiment
- Evaluated on NeRSemble dataset using photorealistic rendering and identity preservation as main axes, comparing against SurFHead baseline with unconstrained exaggeration (γ_f = 0.25).
- Achieved superior performance across all metrics: CLIP-I, CLIP-D, CLIP-C, DINO, and SD, demonstrating better caricature intent alignment, identity preservation, and multi-view consistency.
- Outperformed diffusion-based mesh-free editing (GaussianEditor) in geometry stability, specular consistency, and multi-view coherence.
- Ablation confirmed alternating supervision (original and GT* frames) is essential—training on either domain alone leads to overfitting and artifacts, while alternating enables smooth interpolation and high fidelity across caricature intensities.
- On NeRSemble dataset, achieved high-quality caricaturization with 256 test frames, 4 emotions, 6 expressions, and 10 subjects, using 120K training iterations on a single RTX 3090.
Results show that the proposed method outperforms SurFHead across all evaluated metrics, achieving higher CLIP-I, CLIP-D, CLIP-C, DINO, and SD scores. This indicates improved alignment with the intended caricature intent, better identity preservation, and greater consistency across views compared to the baseline.
