Command Palette
Search for a command to run...
VLingNav: 적응형 추론 및 시각 보조 언어 메모리를 활용한 Embodied Navigation
VLingNav: 적응형 추론 및 시각 보조 언어 메모리를 활용한 Embodied Navigation
Shaoan Wang Yuanfei Luo Xingyu Chen Aocheng Luo Dongyue Li Chang Liu Sheng Chen Yangang Zhang Junzhi Yu
초록
Vision-Language-Action (VLA) 모델은 거대 Vision-Language Models (VLMs)의 강력한 일반화 능력을 계승하는 동시에 지각(perception)과 계획(planning)을 통합함으로써, Embodied Navigation 분야에서 유망한 잠재력을 보여주었습니다. 그러나 기존의 대부분 VLA 모델은 관측값(observation)에서 행동(action)으로 직접 연결되는 반응형 매핑(reactive mapping)에 의존하고 있어, 복잡하고 장기적인(long-horizon) 내비게이션 작업에 필수적인 명시적 추론 능력과 지속적인 메모리(persistent memory)가 부족하다는 한계가 있습니다.이러한 문제를 해결하기 위해, 본 논문에서는 언어 주도적 인지(linguistic-driven cognition)에 기반한 Embodied Navigation용 VLA 모델인 VLangNav를 제안합니다. 첫째, 인간 인지의 이중 프로세스 이론(dual-process theory)에서 영감을 받아 적응형 Chain-of-Thought (AdaCoT) 메커니즘을 도입하였습니다. 이 메커니즘은 필요한 경우에만 명시적 추론을 동적으로 트리거함으로써, 에이전트가 빠르고 직관적인 실행(fast, intuitive execution)과 느리고 신중한 계획(slow, deliberate planning) 사이를 유연하게 전환할 수 있도록 합니다. 둘째, 장기적인 공간적 의존성(long-horizon spatial dependencies)을 처리하기 위해 시각 보조 언어 메모리 모듈(VLangMem)을 개발하였습니다. 이 모듈은 지속적인 교차 모달(cross-modal) 시맨틱 메모리를 구축하여, 에이전트가 과거의 관측값을 회상함으로써 반복적인 탐색을 방지하고 동적 환경에 대한 이동 트렌드를 추론할 수 있도록 합니다. 모델 학습을 위해 본 연구에서는 Nav-AdaCoT-2 데이터셋을 구축하였습니다.
One-sentence Summary
The authors propose VLingNav, a Vision-Language-Action model for embodied navigation that utilizes an adaptive chain-of-thought mechanism to dynamically balance intuitive execution with deliberate reasoning and a visual-assisted linguistic memory module to manage long-horizon spatial dependencies and prevent repetitive exploration.
Key Contributions
- The paper introduces VLangNav, a Vision-Language-Action model that incorporates an adaptive chain-of-thought (AdaCoT) mechanism to dynamically switch between intuitive execution and deliberate planning.
- A visual-assisted linguistic memory module (VLangMem) is developed to construct a persistent, cross-modal semantic memory that enables the agent to recall past observations and handle long-horizon spatial dependencies.
- The research implements an expert-guided reinforcement learning post-training phase and the Nav-AdaCoT-2 dataset, which enables the model to achieve state-of-the-art performance across benchmarks and zero-shot transfer to real-world robot platforms.
Introduction
Embodied navigation is a critical component of robotics that requires agents to follow natural language instructions to perceive, reason, and plan within unseen environments. While Vision-Language-Action (VLA) models have improved generalization, most existing approaches rely on reactive mappings from observations to actions. This lack of explicit reasoning and persistent memory makes it difficult for current models to handle complex, long-horizon tasks or avoid repetitive exploration.
The authors leverage a linguistic-driven cognitive architecture to introduce VLangNav. They propose an adaptive chain-of-thought (AdaCoT) mechanism that dynamically switches between fast, intuitive execution and slow, deliberate planning based on environmental complexity. To manage long-term spatial dependencies, they develop a visual-assisted linguistic memory (VLangMem) module that distills visual observations into persistent semantic summaries. Finally, the authors utilize a large-scale reasoning dataset and an online expert-guided reinforcement learning stage to move beyond simple imitation learning, enabling the model to achieve state-of-the-art performance and zero-shot transfer to real-world robotic platforms.
Dataset
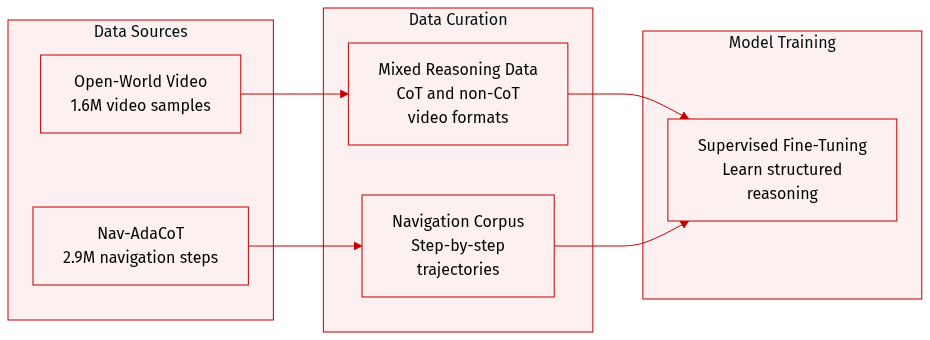
The authors construct a large-scale training corpus totaling 4.5 million samples, composed of two primary components:
- Nav-AdaCoT-2.9M (Embodied Navigation Data): This subset contains 2.9 million step-by-step adaptive Chain-of-Thought (CoT) trajectories designed to bridge perception, language, and action. It is built from several benchmarks:
- Object-Goal Navigation: Includes human demonstration data from HM3D ObjNav via Habitat-Web, as well as shortest-path trajectories from MP3D ObjNav and HM3D OVON.
- Visual Tracking: Utilizes EVT-Bench to provide multi-person indoor tracking data.
- Image-Goal Navigation: Derived from HM3D Instance ImageNav by generating shortest-path trajectories and step-by-step action labels.
- Open-World Video Data: To improve generalization and reduce the sim-to-real gap, the authors incorporate 1.6 million samples from LLaVA-Video-178K, Video-R1, and ScanQA. This subset is processed into two distinct formats:
- CoT-annotated subset: Consists of the challenging video QA pairs from Video-R1.
- Non-CoT subset: Comprises the remaining samples from the other two datasets.
Usage and Processing Details:
- Training Purpose: Nav-AdaCoT-2.9M serves as the cornerstone for the supervised fine-tuning phase, allowing the model to acquire structured reasoning before reinforcement learning post-training.
- Adaptive Reasoning Strategy: By mixing CoT-annotated video data with non-CoT data, the authors enable the model to learn when to autonomously decide if reasoning is required for a specific input.
- Annotation Style: Unlike traditional datasets that only provide instructions and actions, this data uses trajectory-based annotations to provide fine-grained supervision through structured reasoning aligned with observations.
Method
The VLingNav framework extends a video-based Vision-Language Model (VLM), specifically LLaVA-Video-7B, by integrating an action model to enable simultaneous text token generation and trajectory planning. The system is designed to handle complex embodied navigation tasks through a multi-stage process involving observation encoding, adaptive reasoning, and continuous action prediction.
Refer to the framework diagram:
The architecture begins with the observation encoding module. To manage the computational burden of increasing video frames during online inference, the authors propose a dynamic FPS sampling strategy inspired by the Ebbinghaus forgetting curve. Historical frames are sampled at a rate fs(i) that decreases as the time interval ΔT from the current frame increases: fs(i)=fsmaxe−sΔT where s represents the stability of memory. This ensures that recent frames, acting as short-term memory, are captured at a higher rate, while older frames, serving as long-term memory, are sampled more sparsely. To further reduce redundancy, a grid pooling strategy is applied to historical visual features. The downsampling ratio g(i) is also determined by the time interval: g(i)=⌊e−gΔT⌋Vti′=G(Vti,g(i)) To mitigate temporal inconsistency caused by dynamic sampling, a temporal-aware indicator token ET is introduced using Rotary Position Embedding (RoPE) to reflect the absolute time interval ΔT between historical observations and the current frame: ET(ΔT)=EbaseT+RoPE(ΔT) The encoded visual features are then projected into the VLM's latent space using a two-layer Multi-Layer Perceptron (MLP) projector P(⋅), resulting in projected visual tokens EtV=P(Vt′).
The core reasoning capability is driven by an adaptive Chain-of-Thought (CoT) mechanism. The model concatenates visual tokens EtV, language tokens EI, and temporal-aware tokens ET to form the input sequence. The VLM is trained to autonomously decide whether to perform reasoning by predicting a CoT indicator token, either ⟨think_on⟩ or ⟨think_off⟩. When ⟨think_on⟩ is selected, the model generates reasoning content within ⟨think⟩ tags and an environmental summary within ⟨summary⟩ tags. This summary is stored as linguistic memory to be incorporated into subsequent inputs.
As shown in the figure below:
To translate high-level reasoning into robot-specific motions, an MLP-based action model Aθ(⋅) is integrated. It takes the hidden state vector htpred from the final predicted token of the VLM as a condition to predict the motion trajectory τ^t: τ^t=Aθ(htpred) The action model is parameterized as a multivariate Gaussian distribution to provide high-precision continuous control: πθ(at∣st)=N(μθ(ht),diag(σθ(ht)2))
The training process follows a three-stage pipeline. First, the model undergoes pre-training on an open-world adaptive CoT video dataset using cross-entropy loss to establish foundational reasoning skills. Second, supervised fine-tuning (SFT) is performed using a combination of embodied navigation and open-world video data. The SFT objective balances Mean Squared Error (MSE) for trajectory prediction and cross-entropy (CE) for text generation: minθLSFT(θ)=αLMSE(τ^t,τtgt)+(1−α)LCE(Etpred,Etgt) Finally, an online post-training stage is implemented to align the model with closed-loop robot actions. This stage utilizes a hybrid rollout strategy, alternating between naive rollouts for on-policy data collection and expert-guided rollouts to provide corrective trajectories when the agent fails. The policy is updated using a composite objective that combines a PPO-style policy-gradient loss LRL with the SFT loss LSFT: minθLpost(θ)=λLRL(θ)+(1−λ)LSFT(θ)
Experiment
VLingNav is evaluated through extensive simulation benchmarks covering object goal navigation, embodied visual tracking, and image goal navigation, alongside zero-shot real-world deployments on a quadruped robot. Ablation studies validate that adaptive reasoning and cross-modal memory significantly improve navigation efficiency and prevent redundant exploration, while online reinforcement learning helps the agent surpass the limitations of imitation learning. The results demonstrate that multi-task training fosters emergent cross-task and cross-domain capabilities, allowing the model to generalize robustly to unseen environments and complex instructions.
The authors evaluate the performance of VLingNav on the EVT-Bench for embodied visual tracking tasks. The results show that the model achieves state-of-the-art performance in both single-target and distracted tracking scenarios. VLingNav achieves the highest success rate and tracking rate in the single-target tracking task. In the more challenging distracted tracking scenario, VLingNav reaches the highest success rate and tracking rate among the compared methods. The model demonstrates improved robustness in distracted settings compared to previous state-of-the-art baselines.
The authors evaluate the impact of co-training with open-world video data on various navigation tasks. Results show that incorporating co-training improves performance across object goal navigation, visual tracking, and image goal navigation. Co-training enhances success rates and path efficiency in both object goal and image goal navigation tasks. The inclusion of co-training data leads to improved tracking rates and a reduction in collision rates during visual tracking. Performance gains are consistent across multiple distinct navigation benchmarks when using the co-training strategy.

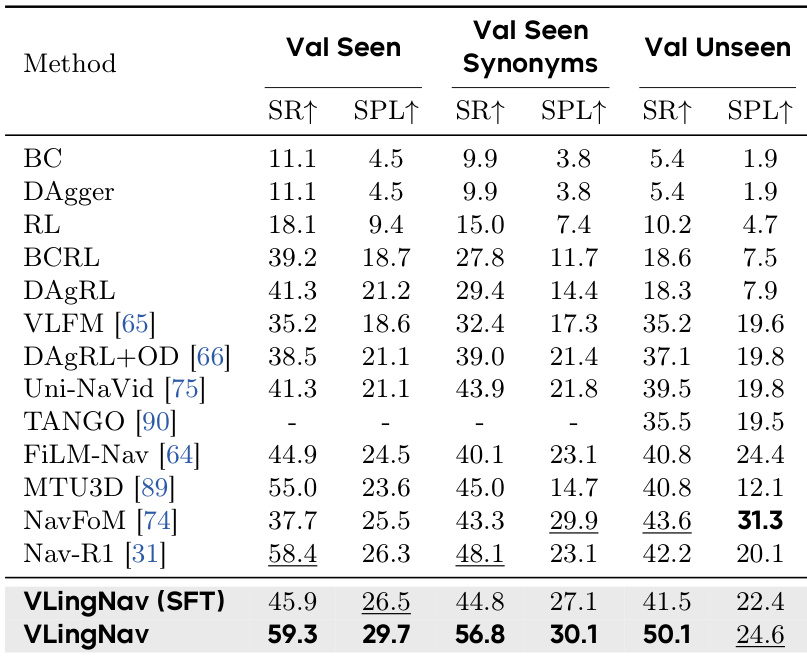
The authors evaluate the performance of VLingNav on the HM3D-OVON benchmark across three different test splits. Results show that the full VLingNav model achieves superior success rates and path efficiency compared to various imitation learning and VLA-based baselines. VLingNav outperforms all compared methods in success rate across seen, synonym, and unseen object categories. The model demonstrates improved path efficiency compared to previous state-of-the-art VLA models in the seen and synonym splits. The full model shows better generalization to unseen object categories than the SFT version of the same architecture.
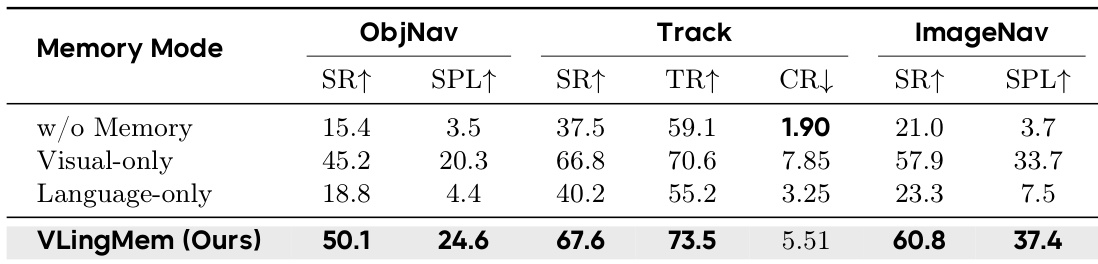
The authors conduct an ablation study to evaluate the impact of different memory modalities on navigation performance across three distinct tasks. Results show that the integrated visual-assisted linguistic memory approach outperforms standalone visual or linguistic memory, as well as configurations without any memory module. The proposed memory module achieves the highest success rates and efficiency across object navigation, tracking, and image goal navigation tasks. Removing the memory module entirely leads to the lowest performance levels across all evaluated metrics. Using only visual features or only linguistic information provides partial improvements but remains less effective than the full integrated memory system.
The authors conduct an ablation study to evaluate different Chain-of-Thought reasoning strategies across Object Goal Navigation, Visual Tracking, and Image Goal Navigation tasks. The results demonstrate that the proposed Adaptive CoT strategy achieves superior performance across most metrics compared to having no reasoning or using exhaustive reasoning at every step. Adaptive CoT outperforms both the absence of reasoning and dense per-step reasoning in terms of success rates and path efficiency. The adaptive approach maintains high performance while utilizing a significantly lower reasoning frequency compared to fixed-interval methods. While fixed-interval strategies show competitive results in certain tracking metrics, the adaptive method provides the most balanced performance across all tested navigation tasks.
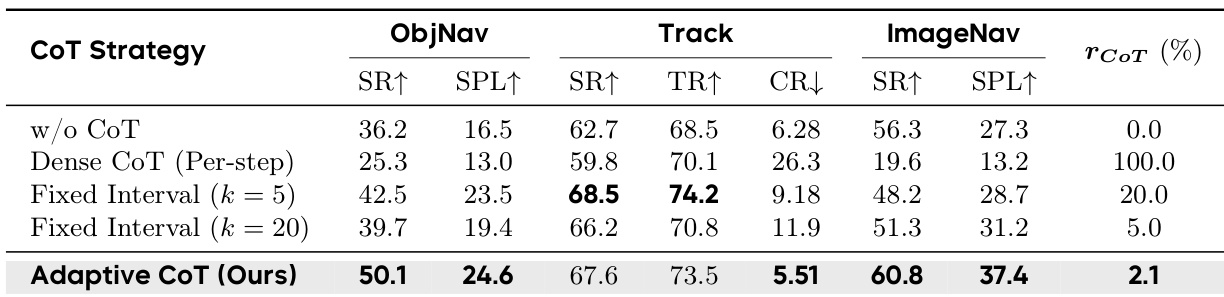
The authors evaluate VLingNav across various embodied navigation and tracking tasks to validate its performance, the benefits of co-training, and the effectiveness of its architectural components. The results demonstrate that VLingNav achieves state-of-the-art success and robustness in both single-target and distracted tracking scenarios while showing strong generalization to unseen object categories. Furthermore, the integration of open-world video co-training, a multimodal visual-linguistic memory system, and an adaptive Chain-of-Thought reasoning strategy significantly enhances navigation efficiency and task success rates.