HyperAI
Command Palette
Search for a command to run...
Papers
최신 AI 트렌드를 파악할 수 있도록 매일 업데이트되는 최첨단 AI 연구 논문

DeepSeek-V4: 고효율 Million-Token 컨텍스트 인텔리전스를 향하여

생성적 관점에서의 공간 지능 탐구
















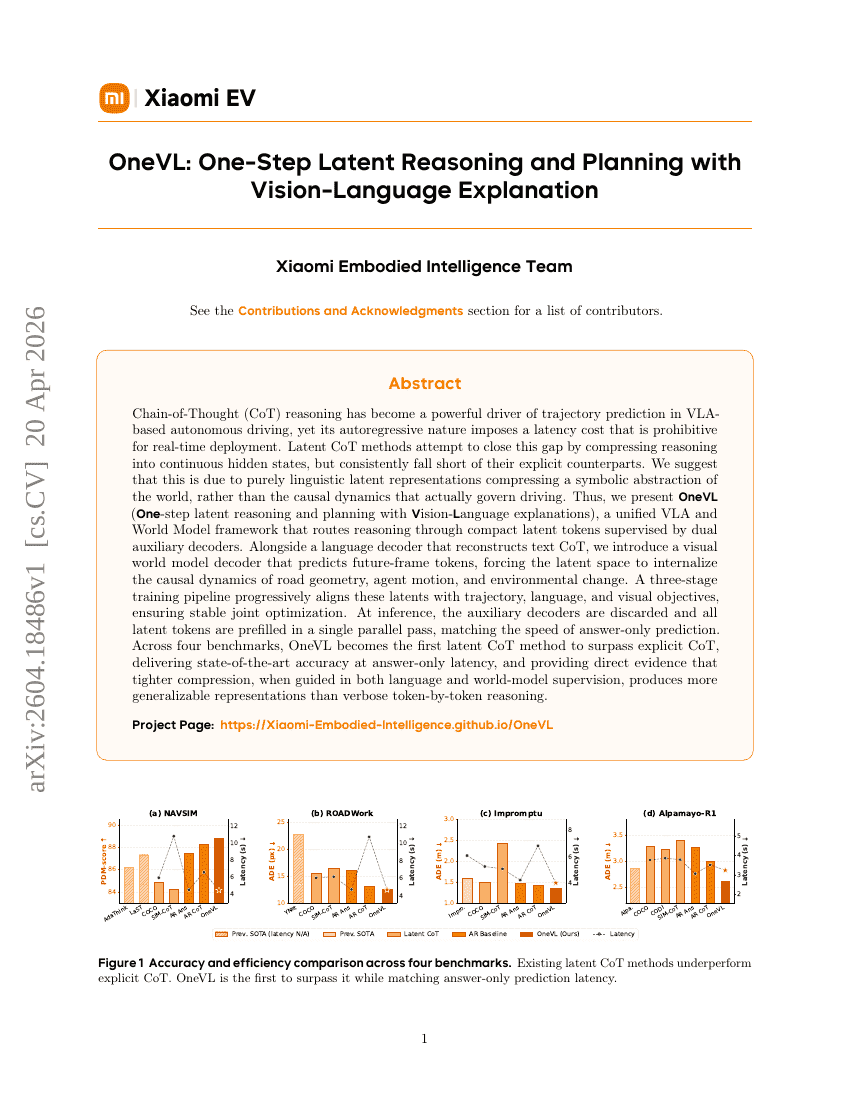









DeepSeek-V4: 고효율 Million-Token 컨텍스트 인텔리전스를 향하여
생성적 관점에서의 공간 지능 탐구
DeVI: 합성 비디오 모방을 통한 물리 기반의 숙련된 인간-객체 상호작용 (Physics-based Dexterous Human-Object Interaction via Synthetic Video Imitation)
대규모 모델 시대의 Reward Hacking: 메커니즘, 창발적 정렬 불일치(Emergent Misalignment), 그리고 과제
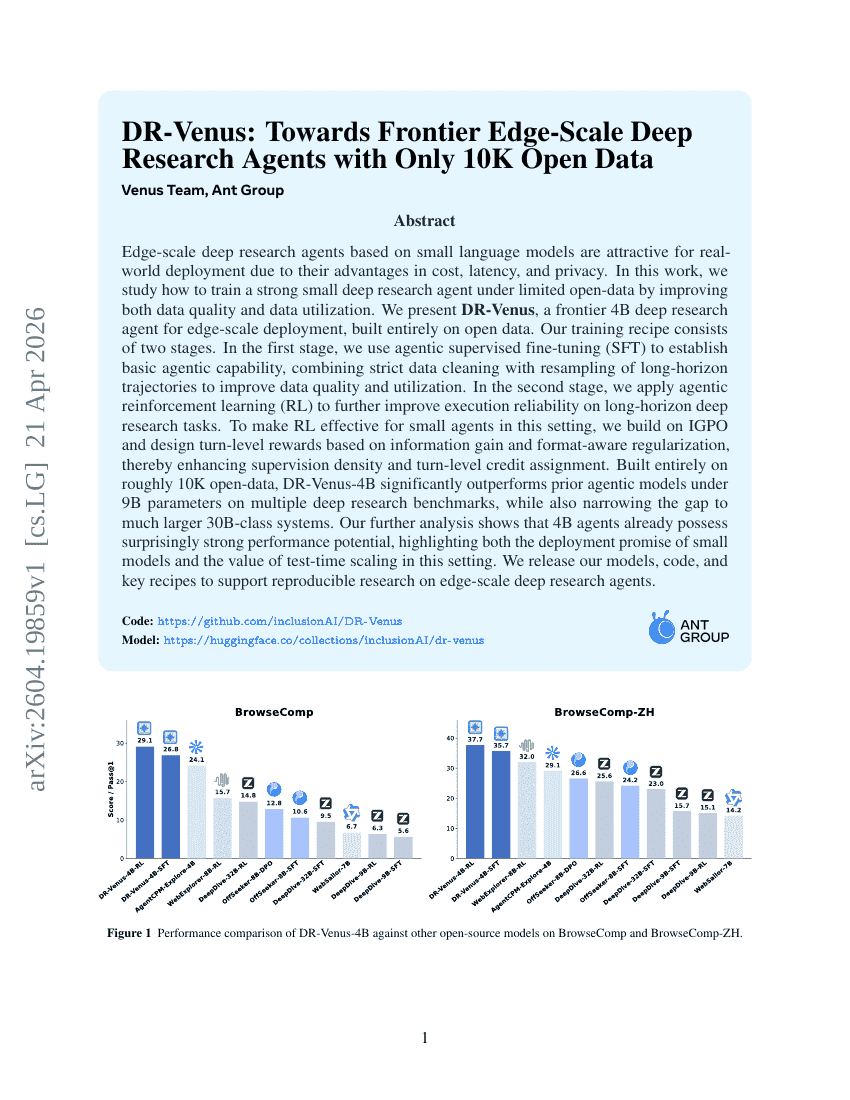
DR-Venus: 단 10K개의 오픈 데이터만으로 구현하는 프런티어 엣지 규모(Edge-Scale)의 딥 리서치 agent를 향하여
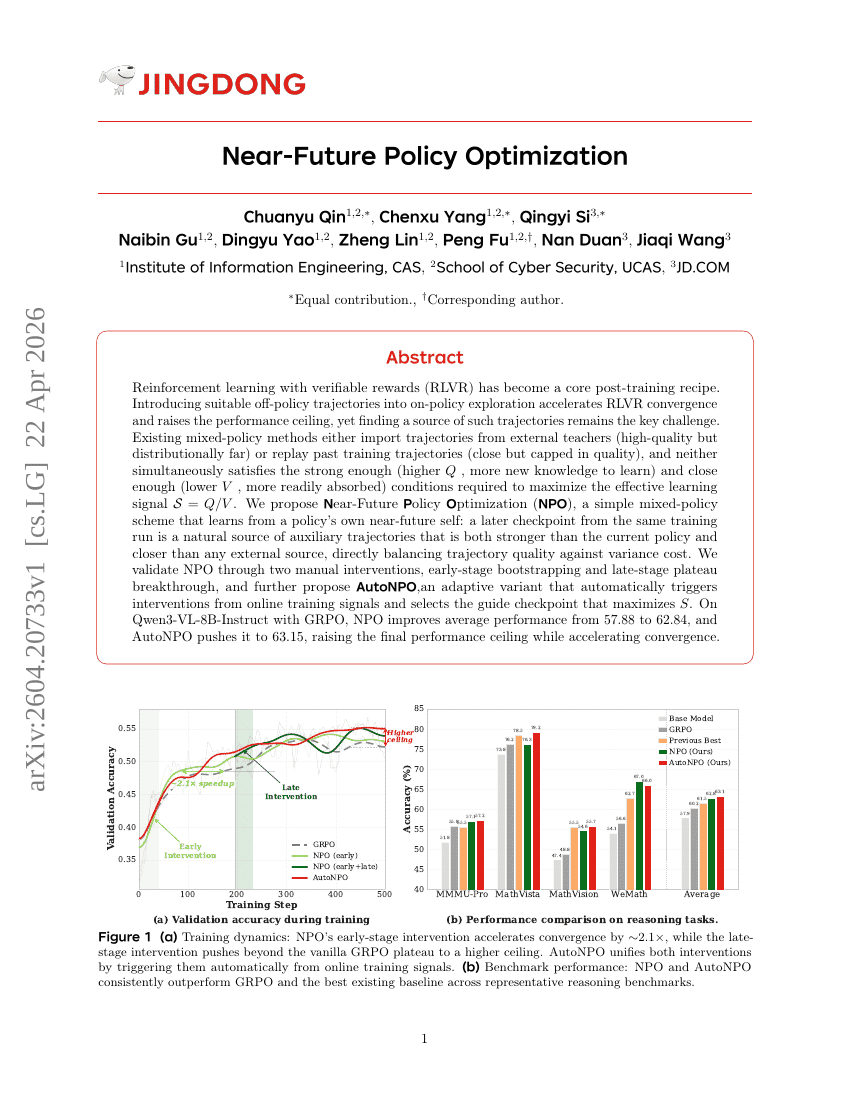
근미래 정책 최적화 (Near-Future Policy Optimization)
LLaDA2.0-Uni: Diffusion Large Language Model을 통한 멀티모달 이해 및 생성의 통합
BioInstruct: 생물 의학 자연어 처리(Biomedical Natural Language Processing)를 위한 Large Language Models의 Instruction Tuning
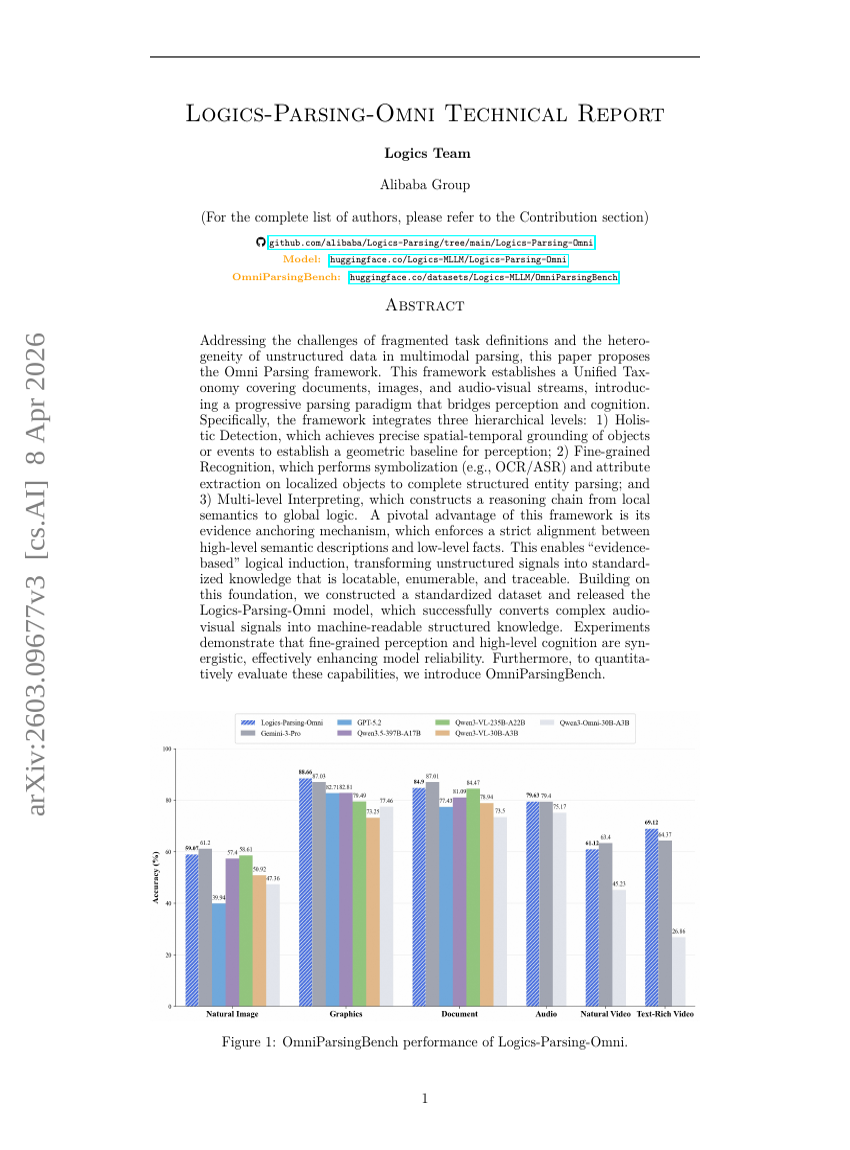
Logics-Parsing-Omni 기술 보고서
Task Tokens: 행동 파운데이션 모델(Behavior Foundation Models) 적응을 위한 유연한 접근 방식
PlayCoder: LLM 생성 GUI Code의 실행 가능성 확보
TEMPO: 대규모 추론 모델을 위한 Test-time Training의 확장
AnyRecon: Video Diffusion Model을 이용한 임의 시점 3D Reconstruction
AgentSPEX: An Agent SPecification and EXecution Language
CoInteract: 공간적으로 구조화된 공동 생성(Co-Generation)을 통한 물리적 일관성을 갖춘 인간-객체 상호작용 비디오 합성
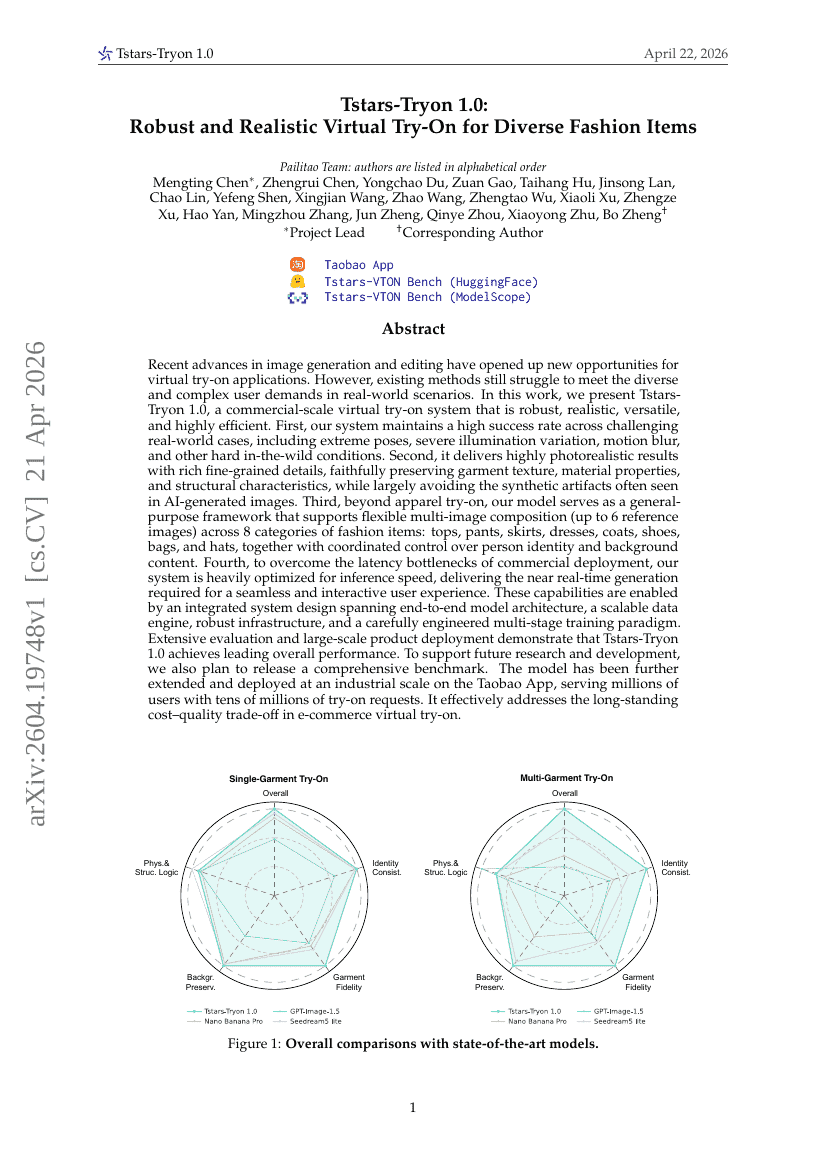
Tstars-Tryon 1.0: 다양한 패션 아이템을 위한 강건하고 사실적인 가상 Try-On
Large Language Model Inference를 위한 Fast NF4 Dequantization Kernels
EasyVideoR1: 비디오 이해를 위한 더욱 용이한 RL
MultiWorld: 확장 가능한 Multi-Agent Multi-View 비디오 월드 모델 (Scalable Multi-Agent Multi-View Video World Models)
OpenGame: 게임을 위한 Open Agentic Coding
Agent-World: 진화하는 범용 agent 지능을 위한 실세계 환경 합성의 스케일링
OneVL: 시각-언어 설명을 통한 단일 단계 잠재 추론 및 계획 (One-Step Latent Reasoning and Planning with Vision-Language Explanation)
변별적 텍스트 표현(Discriminative Text Representation)을 통한 클래스 레이블 기반의 원스텝 이미지 생성을 텍스트로 확장하기
ScribblePrompt: 모든 생의학 이미지를 위한 빠르고 유연한 상호작용형 Segmentation
Long-VITA: 선도적인 Short-Context 정확도를 유지하며 Large Multi-modal Models를 1 Million Tokens로 확장하기
UI-TARS: Native Agent를 통한 자동화된 GUI 상호작용의 선구적 접근
HunyuanVideo: Large Video Generative Models를 위한 체계적 프레임워크
MathNet: 수학적 추론 및 검색을 위한 글로벌 멀티모달 벤치마크
LLM Agent에서의 Externalization: Memory, Skills, Protocols 및 Harness Engineering에 관한 통합적 리뷰
Active Context Compression: LLM Agent에서의 자율적 메모리 관리
손실을 최소화하라! 효율적인 병렬 추론을 위한 조기 경로 Pruning 학습법
DeVI: 합성 비디오 모방을 통한 물리 기반의 숙련된 인간-객체 상호작용 (Physics-based Dexterous Human-Object Interaction via Synthetic Video Imitation)
대규모 모델 시대의 Reward Hacking: 메커니즘, 창발적 정렬 불일치(Emergent Misalignment), 그리고 과제
DR-Venus: 단 10K개의 오픈 데이터만으로 구현하는 프런티어 엣지 규모(Edge-Scale)의 딥 리서치 agent를 향하여
근미래 정책 최적화 (Near-Future Policy Optimization)
LLaDA2.0-Uni: Diffusion Large Language Model을 통한 멀티모달 이해 및 생성의 통합
BioInstruct: 생물 의학 자연어 처리(Biomedical Natural Language Processing)를 위한 Large Language Models의 Instruction Tuning
Logics-Parsing-Omni 기술 보고서
Task Tokens: 행동 파운데이션 모델(Behavior Foundation Models) 적응을 위한 유연한 접근 방식
PlayCoder: LLM 생성 GUI Code의 실행 가능성 확보
TEMPO: 대규모 추론 모델을 위한 Test-time Training의 확장
AnyRecon: Video Diffusion Model을 이용한 임의 시점 3D Reconstruction
AgentSPEX: An Agent SPecification and EXecution Language
CoInteract: 공간적으로 구조화된 공동 생성(Co-Generation)을 통한 물리적 일관성을 갖춘 인간-객체 상호작용 비디오 합성
Tstars-Tryon 1.0: 다양한 패션 아이템을 위한 강건하고 사실적인 가상 Try-On
Large Language Model Inference를 위한 Fast NF4 Dequantization Kernels
EasyVideoR1: 비디오 이해를 위한 더욱 용이한 RL
MultiWorld: 확장 가능한 Multi-Agent Multi-View 비디오 월드 모델 (Scalable Multi-Agent Multi-View Video World Models)
OpenGame: 게임을 위한 Open Agentic Coding
Agent-World: 진화하는 범용 agent 지능을 위한 실세계 환경 합성의 스케일링
OneVL: 시각-언어 설명을 통한 단일 단계 잠재 추론 및 계획 (One-Step Latent Reasoning and Planning with Vision-Language Explanation)
변별적 텍스트 표현(Discriminative Text Representation)을 통한 클래스 레이블 기반의 원스텝 이미지 생성을 텍스트로 확장하기
ScribblePrompt: 모든 생의학 이미지를 위한 빠르고 유연한 상호작용형 Segmentation
Long-VITA: 선도적인 Short-Context 정확도를 유지하며 Large Multi-modal Models를 1 Million Tokens로 확장하기
UI-TARS: Native Agent를 통한 자동화된 GUI 상호작용의 선구적 접근
HunyuanVideo: Large Video Generative Models를 위한 체계적 프레임워크
MathNet: 수학적 추론 및 검색을 위한 글로벌 멀티모달 벤치마크
LLM Agent에서의 Externalization: Memory, Skills, Protocols 및 Harness Engineering에 관한 통합적 리뷰
Active Context Compression: LLM Agent에서의 자율적 메모리 관리
손실을 최소화하라! 효율적인 병렬 추론을 위한 조기 경로 Pruning 학습법