Command Palette
Search for a command to run...
HunyuanVideo: Large Video Generative Models를 위한 체계적 프레임워크
HunyuanVideo: Large Video Generative Models를 위한 체계적 프레임워크
Hunyuan Foundation Model Team
HunyuanVideo-1.5 비디오 생성 모델
초록
최근 비디오 생성 기술의 비약적인 발전은 개인의 일상뿐만 아니라 산업 전반에 걸쳐 심오한 변화를 가져왔습니다. 그러나 현재 선도적인 비디오 생성 모델들은 대부분 폐쇄형 소스(closed-source)로 유지되고 있어, 산업계와 오픈 소스 커뮤니티 간의 비디오 생성 성능 격차가 상당히 크게 나타나고 있습니다. 본 보고서에서는 선도적인 폐쇄형 모델과 대등하거나 혹은 이를 능가하는 성능을 보여주는 혁신적인 오픈 소스 비디오 파운데이션 모델(video foundation model)인 HunyuanVideo를 선보입니다. HunyuanVideo는 데이터 큐레이션(data curation), 고급 아키텍처 설계, 점진적인 모델 스케일링(model scaling) 및 학습, 그리고 대규모 모델 학습과 추론을 용이하게 하기 위해 설계된 효율적인 인프라를 포함하여 여러 핵심적인 기여를 통합한 포괄적인 프레임워크를 특징으로 합니다. 이러한 기술력을 바탕으로 당사는 130억 개 이상의 파라미터(parameters)를 보유한 비디오 생성 모델을 성공적으로 학습시켰으며, 이는 현재 모든 오픈 소스 모델 중 최대 규모입니다.당사는 높은 시각적 품질, 역동적인 움직임(motion dynamics), 텍스트-비디오 정렬(text-video alignment) 및 고급 촬영 기법을 보장하기 위해 광범위한 실험을 수행하고 일련의 타겟팅된 설계를 구현하였습니다. 전문적인 인간 평가(human evaluation) 결과에 따르면, HunyuanVideo는 Runway Gen-3, Luma 1.6 및 중국의 상위 3개 비디오 생성 모델을 포함한 기존의 최첨단(state-of-the-art) 모델들보다 뛰어난 성능을 발휘했습니다. 당사는 파운데이션 모델의 코드와 관련 애플리케이션을 공개함으로써 폐쇄형 커뮤니티와 오픈 소스 커뮤니티 간의 간극을 좁히고자 합니다. 이러한 시도는 커뮤니티 구성원 모두가 자신의 아이디어를 실험할 수 있도록 힘을 실어줄 것이며, 더욱 역동적이고 활기찬 비디오 생성 생태계를 조성하는 밑거름이 될 것입니다.
One-sentence Summary
The Hunyuan Foundation Model Team introduces HunyuanVideo, a 13 billion parameter open-source video foundation model that utilizes a systematic framework of data curation, advanced architecture, progressive scaling, and efficient infrastructure to achieve high visual quality and motion dynamics that outperform closed-source models such as Runway Gen-3 and Luma 1.6 in professional human evaluations.
Key Contributions
- This work introduces HunyuanVideo, an open-source video foundation model with over 13 billion parameters that utilizes a comprehensive framework of data curation, advanced architecture design, and progressive scaling. Professional human evaluations demonstrate that the model achieves performance comparable or superior to leading closed-source models such as Runway Gen-3 and Luma 1.6.
- The paper presents a text-guidance distillation method that condenses the combined outputs of conditional and unconditional inputs into a single student model. This approach addresses the high computational costs of classifier-free guidance and achieves approximately 1.9x acceleration during inference.
- The research develops a video-to-audio (V2A) module designed to autonomously generate cinematic-grade foley audio and background music synchronized with the input video. This module enables the synthesis of cohesive multimedia experiences by bridging the gap between visual generation and auditory realism.
Introduction
High-quality video generation is essential for transforming industries, yet a significant performance gap exists between proprietary closed-source models and available open-source alternatives. While diffusion models have advanced image generation, the video domain suffers from a lack of robust open-source foundation models, which limits community-driven algorithmic innovation. The authors introduce HunyuanVideo, a systematic framework and a 13 billion parameter open-source foundation model that rivals leading commercial systems. They leverage an optimized scaling strategy, advanced architecture design, and efficient training infrastructure to achieve superior visual quality, motion dynamics, and text-video alignment.
Dataset
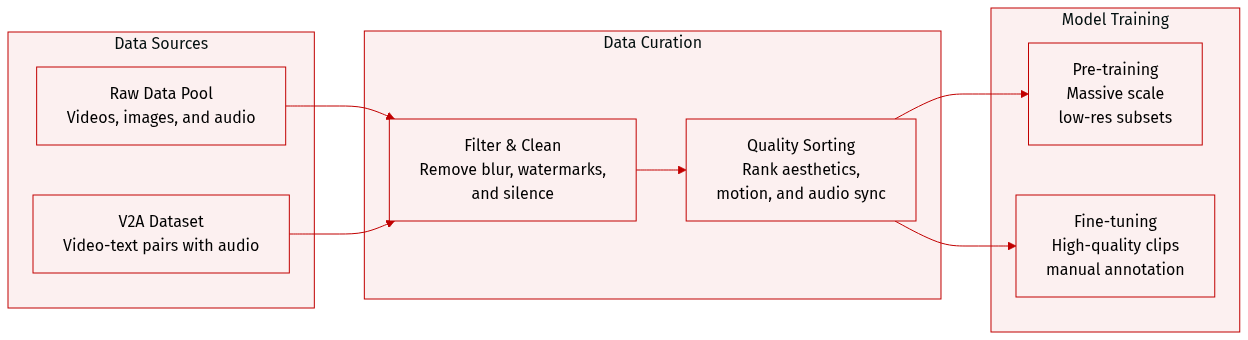
-
Dataset Composition and Sources The authors utilize a joint image and video training strategy. The raw video pool covers diverse domains such as people, animals, plants, landscapes, vehicles, objects, buildings, and animation. For image training, the authors start with a pool of billions of image-text pairs. A separate video-to-audio (V2A) dataset is also constructed, consisting of video-text pairs with corresponding audio streams.
-
Key Details for Each Subset
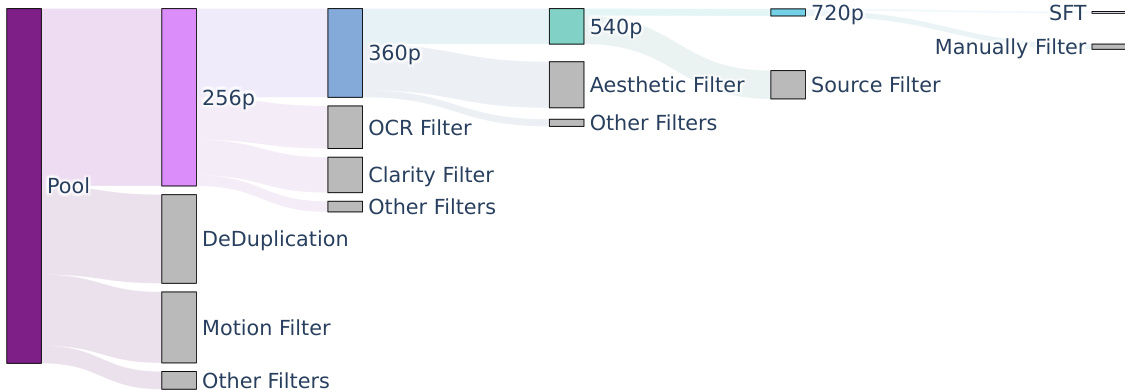
- Video Subsets: The authors create five distinct video training datasets through a hierarchical filtering pipeline. These subsets progressively increase in spatial resolution, ranging from 256p (256 x 256 x 65) to 720p (720 x 1280 x 129).
- Image Subsets: Two image datasets are constructed by increasing filtering thresholds. The first contains billions of samples for initial text-to-image pre-training, while the second contains hundreds of millions of samples for the second stage of pre-training.
- Fine-tuning Dataset: A specialized video fine-tuning dataset of approximately 1 million samples is built through manual annotation, focusing on high visual aesthetics and compelling motion.
- V2A Subsets: For audio training, the authors retain approximately 250,000 hours for pre-training and a refined subset of millions of high-quality clips (80,000 hours) for supervised fine-tuning.
-
Data Processing and Filtering
- Video Pre-processing: Raw videos are split into single-shot clips using PySceneDetect. The authors use the Laplacian operator to identify clear starting frames and an internal VideoCLIP model to calculate embeddings for deduplication and k-means concept resampling (targeting 10K centroids).
- Hierarchical Filtering: A multi-stage pipeline filters data based on visual aesthetics (via Dover), clarity (to remove blur), motion speed (via optical flow), and content. The pipeline also uses OCR to remove excessive text or subtitles and YOLOX-like models to detect and remove watermarks, logos, or borders.
- Audio Filtering: For V2A, the authors remove videos without audio or those with a silence ratio exceeding 80%. They classify audio into four categories: pure sound, sound with speech, sound with music, and pure music. A visual-audio consistency score is used to ensure alignment between sight and sound.
-
Metadata and Feature Extraction
- Captioning: For V2A, sound and music captioning models are used to generate descriptions, which are then merged into a structured caption format.
- Visual Features: CLIP is used to extract visual features at a temporal resolution of 4 fps, which are then resampled to align with the audio frame rate.
Method
The HunyuanVideo framework is designed as a comprehensive pipeline that transitions from data pre-processing to large-scale model training and diverse downstream applications. The process begins with data pre-processing, where raw image and video pools undergo rigorous data filtering and structured captioning to ensure high-quality training signals.
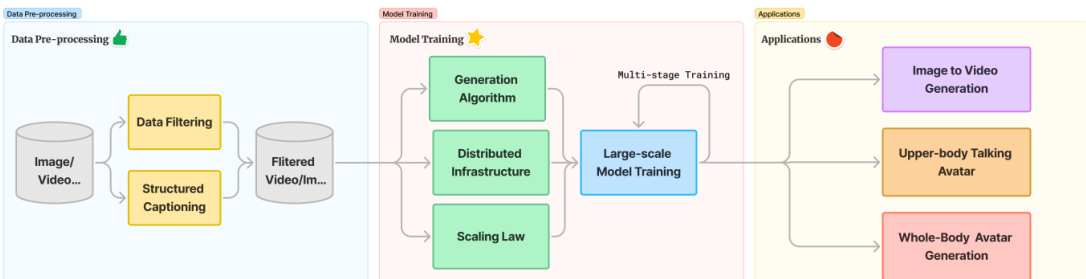
The model training stage utilizes a multi-stage approach, incorporating a generation algorithm, distributed infrastructure, and scaling law experiments to optimize performance. This stage feeds into various applications, such as image-to-video generation and avatar animation.
To facilitate efficient video processing, the authors implement a 3D Variational Auto-encoder (3DVAE). This component compresses pixel-space videos and images into a compact latent space using CausalConv3D. For a video with dimensions (T+1)×3×H×W, the 3DVAE produces latent features of shape (ctT+1)×C×(csH)×(csW), where ct=4, cs=8, and C=16. This compression allows the subsequent diffusion transformer to operate on a reduced number of tokens while maintaining high original resolutions.
The core of the generative process is the unified image and video generative architecture, which utilizes a Diffusion Transformer (DiT) backbone. The model employs a "Dual-stream to Single-stream" hybrid design. In the initial dual-stream phase, video and text tokens are processed independently through Transformer blocks to allow each modality to learn specific modulation mechanisms. Subsequently, in the single-stream phase, the tokens are concatenated for deep multimodal fusion. To support varying resolutions and aspect ratios, the authors implement a 3D Rotary Position Embedding (RoPE), which extends the standard RoPE to the temporal, height, and width dimensions by partitioning feature channels into segments dt, dh, and dw.
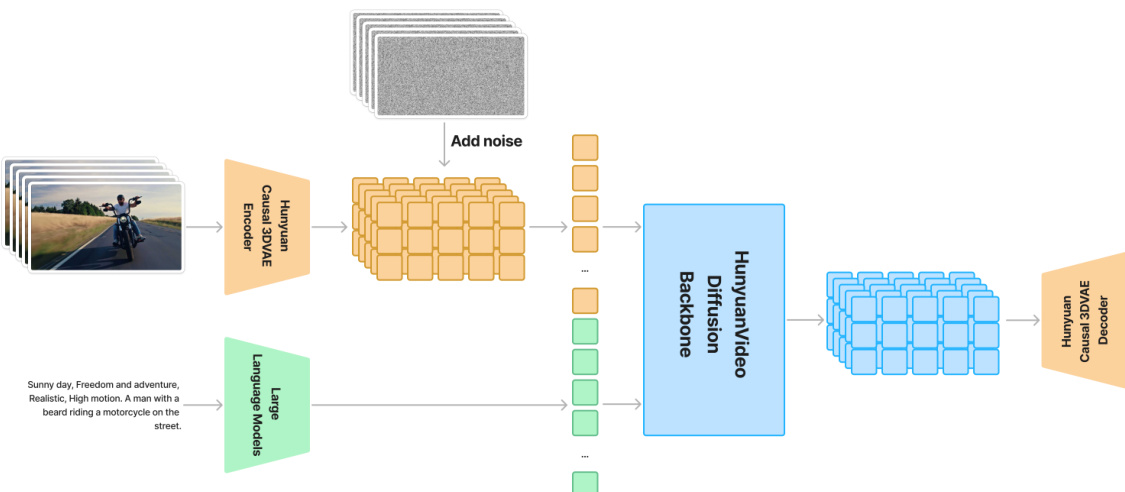
Textual guidance is provided by a pre-trained Multimodal Large Language Model (MLLM) acting as a text encoder. Unlike traditional bidirectional encoders, the MLLM uses a decoder-only structure, which the authors enhance with an additional bidirectional token refiner to improve text guidance. Additionally, global information is extracted from a CLIP model and integrated into the DiT blocks.

The training process is governed by the Flow Matching framework. Given a latent representation x1, the model predicts a velocity vt to guide the sample xt toward the ground truth ut. The objective is to minimize the mean squared error:
Lgeneration=Et,x0,x1∥vt−ut∥2
To ensure convergence and high-quality outputs, the authors employ a progressive curriculum learning strategy. This begins with image pre-training at low resolutions (256px) and scales up to joint video-image training at higher resolutions and longer durations.
Experiment
The evaluation explores the performance and scalability of the HunyuanVideo framework through architectural validation, scaling law analysis, and downstream application testing. Experiments confirm that the proposed 3D VAE and spatial-temporal tiling strategies enable high-resolution video processing with superior reconstruction quality and minimal artifacts. Systematic scaling law studies for both image and video models allow for the optimization of model size and dataset configuration, while human evaluations demonstrate that the model excels in text alignment, motion dynamics, and concept generalization compared to state-of-the-art baselines. Furthermore, fine-tuning experiments show that the foundation model can be effectively adapted for specialized tasks such as portrait animation and fully controllable, multi-signal avatar generation.
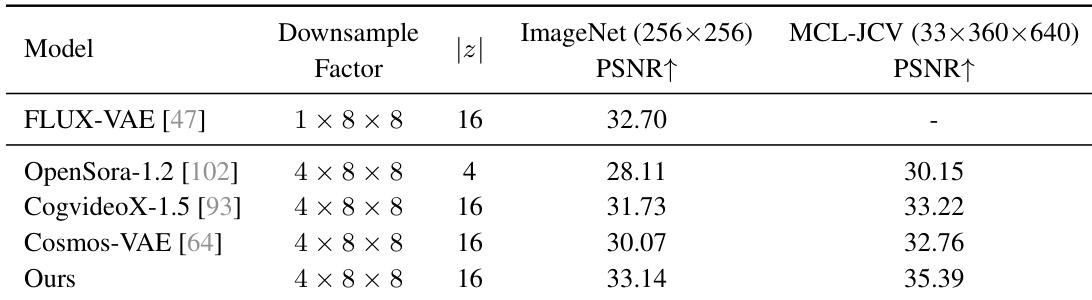
The authors compare their VAE against several open-source state-of-the-art models using ImageNet and MCL-JCV datasets. Results show that the proposed model achieves higher reconstruction quality across both image and video benchmarks. The proposed model outperforms existing video VAEs in terms of PSNR on video data The model demonstrates superior performance on image reconstruction compared to both video and image specific VAEs The proposed approach maintains a competitive downsample factor while achieving higher reconstruction metrics
The authors evaluate HunyuanVideo against five closed-source baseline models using professional evaluators across multiple criteria. The results show that the proposed model achieves the highest overall performance and the top ranking among the compared methods. HunyuanVideo achieves the highest ranking in overall performance compared to all baseline models The model demonstrates superior motion quality relative to the other evaluated video generation models The proposed method maintains competitive text alignment and visual quality scores

The authors evaluate the proposed VAE and HunyuanVideo model through reconstruction benchmarks on ImageNet and MCL-JCV datasets, as well as professional human evaluations against several state-of-the-art baselines. The VAE demonstrates superior reconstruction quality for both images and videos while maintaining competitive downsampling factors. Furthermore, HunyuanVideo achieves top overall performance, specifically excelling in motion quality, text alignment, and visual fidelity compared to existing models.